系列文章目录
一、结构化流介绍(了解)
二、结构化流的编程模型(掌握)
三、Spark 和 Kafka 整合,流处理,批处理演示(掌握)
四、物联网数据分析案例(熟悉)
文章目录
- 系列文章目录
- 前言
- Structured Steaming
- 一、结构化流介绍(了解)
- 1、有界和无界数据
- 2、基本介绍
- 3、使用三大步骤(掌握)
- 4、回顾sparkSQL的词频统计案例
- 二、结构化流的编程模型(掌握)
- 1、数据结构
- 2、读取数据源
- 2.1 File Source
- 2.2 Socket Source
- 2.3 Rate Source
- 3、数据处理
- 4、数据输出
- 4.1 输出模式
- 4.1.1 append 模式
- 4.1.2 complete模式
- 4.1.3 update模式
- 4.2 输出终端/位置
- 5、设置触发器Trigger
- 6、CheckPoint检查点目录设置
- 7、综合案例(练习)
- 7.1 词频统计_读取文件方式
- 7.2 词频统计_Socket方式
- 7.3 自动生成数据_Rate方式
- 三、Spark 和 Kafka 整合(掌握)
- 1、整合Kafka准备工作
- 2、从kafka中读取数据
- 2.1 流式处理
- 官方示例:
- 练习示例
- 2.2 批处理
- 官方示例:
- 演示示例
- 3、数据写入Kafka中
- 3.1 流式处理
- 官方示例:
- 练习示例
- 3.2 批处理
- 官方示例:
- 演示示例
- 四、物联网数据分析案例(熟悉)
- 1、数据模拟器代码
- 2、需求说明
- 3、代码实现
前言
本文主要通过案例解析的方式详解Structured Steaming,“Spark 与 Kafka 整合”流处理和批处理演示。
Structured Steaming
一、结构化流介绍(了解)
1、有界和无界数据
- 有界数据:
有界数据: 指的数据有固定的开始和固定的结束,数据大小是固定。我们称之为有界数据。对于有界数据,一般采用批处理方案(离线计算)特点:1-数据大小是固定2-程序处理有界数据,程序最终一定会停止
- 无界数据:
无界数据: 指的数据有固定的开始,但是没有固定的结束。我们称之为无界数据
注意: 对于无界数据,我们一般采用流式处理方案(实时计算)特点:1-数据没有明确的结束,也就是数据大小不固定2-数据是源源不断的过来3-程序处理无界数据,程序会一直运行不会结束
2、基本介绍
结构化流是构建在Spark SQL处理引擎之上的一个流式的处理引擎,主要是针对无界数据的处理操作。对于结构化流同样也支持多种语言操作的API:比如 Python Java Scala SQL …
Spark的核心是RDD。RDD出现主要的目的就是提供更加高效的离线的迭代计算操作,RDD是针对的有界的数据集,但是为了能够兼容实时计算的处理场景,提供微批处理模型,本质上还是批处理,只不过批与批之间的处理间隔时间变短了,让我们感觉是在进行流式的计算操作,目前默认的微批可以达到100毫秒一次
真正的流处理引擎: Storm(早期流式处理引擎)、Flink、Flume(流式数据采集)
3、使用三大步骤(掌握)
StructuredStreaming在进行数据流开发时的三个步骤
- 1、读取数据流数据 : 指定数据源模式
- saprksession对象.readStream.format(指定读取的数据源).option(指定读取的参数).load()
- 2、数据处理: 使用dsl或者sql方式计算数据和SparkSQL操作一样
- 3、将计算的结果保存 : 指定输出模式,指定位置
- writeStream.
outputMode(输出模式).option(输出的参数配置).format(指定输出位置).start().awaitTermination()
- writeStream.
4、回顾sparkSQL的词频统计案例
# 导包
import os
from pyspark.sql import SparkSession,functions as F# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()# 2.数据输入df = spark.read\.format('text')\.load('file:///export/data/spark_project/structured_Streaming/data/w1.txt')# 查看数据类型print(type(df))# 3.数据处理(切分,转换,分组聚合)# SQL方式df.createTempView('tb')sql_df = spark.sql("""select words,count(1) as cntfrom (select explode(split(value,' ')) as words from tb) t group by words""")# DSL方式dsl_df = df.select(F.explode(F.split('value',' ')).alias('words')).groupBy('words').agg(F.count('words').alias('cnt'))# 4.数据输出sql_df.show()dsl_df.show()# 5.关闭资源spark.stop()二、结构化流的编程模型(掌握)
1、数据结构
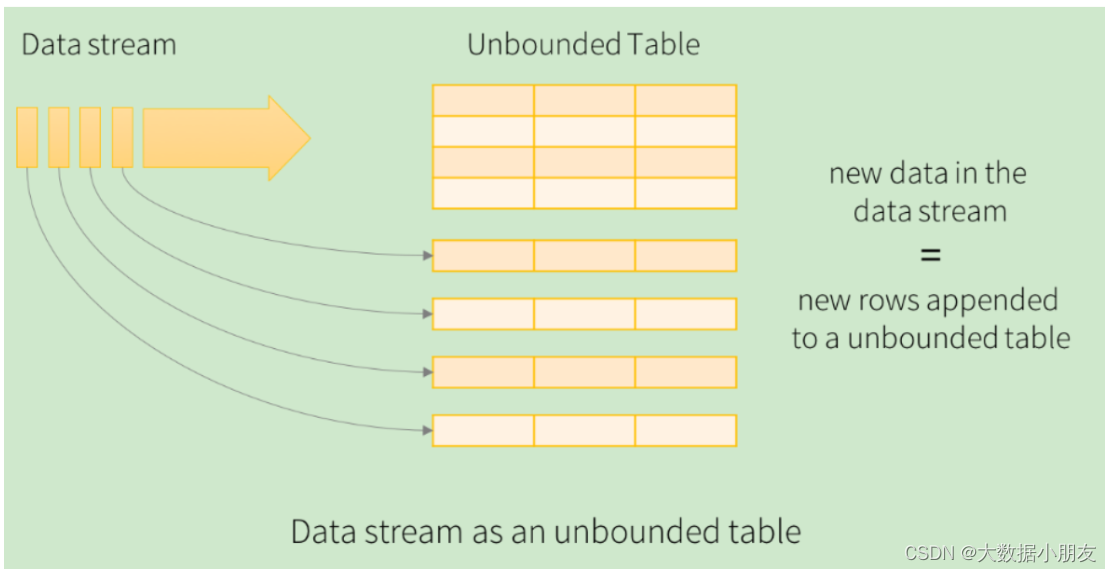
在结构化流中,我们可以将DataFrame称为无界的DataFrame或者无界的二维表
2、读取数据源
对应官网文档内容:
https://spark.apache.org/docs/3.1.2/structured-streaming-programming-guide.html#input-sources
结构化流默认提供了多种数据源,从而可以支持不同的数据源的处理工作。目前提供了如下数据源:
-
File Source:文件数据源。读取文件系统,一般用于测试。如果文件夹下发生变化,有新文件产生,那么就会触发程序的运行
-
Socket Source:网络套接字数据源,一般用于测试。也就是从网络上消费/读取数据
-
Rate Source:速率数据源。了解即可,一般用于基准测试。通过配置参数,由结构化流自动生成测试数据。
-
Kafka Source:Kafka数据源。也就是作为消费者来读取Kafka中的数据。一般用于生产环境。
2.1 File Source
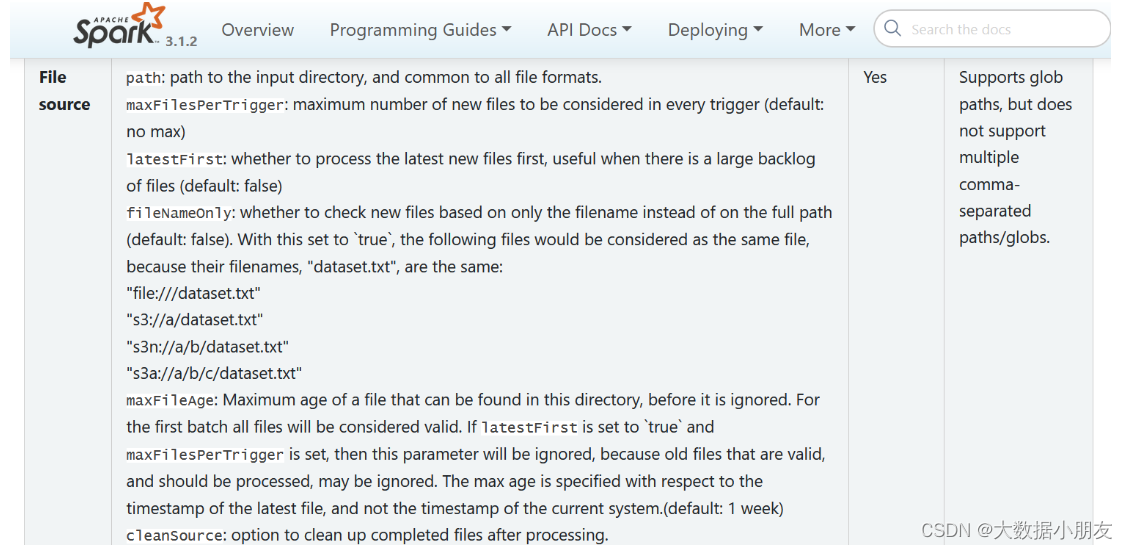
相关的参数:
| option参数 | 描述说明 |
|---|---|
| maxFilesPerTrigger | 每次触发时要考虑的最大新文件数 (默认: no max) |
| latestFirst | 是否先处理最新的新文件, 当有大量文件积压时有用 (默认: false) |
| fileNameOnly | 是否检查新文件只有文件名而不是完整路径(默认值:false)将此设置为 true 时,以下文件将被视为同一个文件,因为它们的文件名“dataset.txt”相同: “file:///dataset.txt” “s3://a/dataset.txt " “s3n://a/b/dataset.txt” “s3a://a/b/c/dataset.txt” |
将目录中写入的文件作为数据流读取,支持的文件格式为:text、csv、json、orc、parquet。。。。
文件数据源特点:
1- 只能监听目录,不能监听具体的文件
2- 可以通过*通配符的形式监听目录中满足条件的文件
3- 如果监听目录中有子目录,那么无法监听到子目录的变化情况
读取代码通用格式:
# 原生API
sparksession.readStream.format('CSV|JSON|Text|Parquet|ORC...').option('参数名1','参数值1').option('参数名2','参数值2').option('参数名N','参数值N').schema(元数据信息).load('需要监听的目录地址')# 简化API
针对具体数据格式,还有对应的简写API格式,例如:sparksession.readStream.csv(path='需要监听的目录地址',schema=元数据信息。。。)
可能遇到的错误一:

原因: 如果是文件数据源,需要手动指定schema信息
可能遇到的错误二:

原因: File source只能监听目录,不能监听具体文件
2.2 Socket Source

首先: 先下载一个 nc(netcat) 命令. 通过此命令打开一个端口号, 并且可以向这个端口写入数据下载命令: yum -y install nc执行nc命令, 开启端口号, 写入数据: nc -lk 端口号查看端口号是否被使用命令: netstat -nlp | grep 要查询的端口
注意: 要先启动nc,再启动我们的程序
代码格式:df = spark.readStream \.format('socket') \.option('host', '主机地址') \.option('port', '端口号') \.load()
2.3 Rate Source
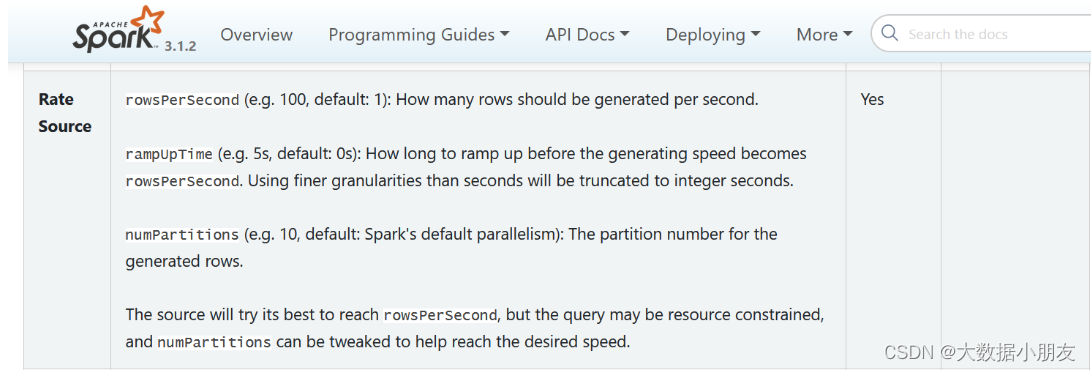
此数据源的提供, 主要是用于进行基准测试
| option参数 | 描述说明 |
|---|---|
| rowsPerSecond | 每秒应该生成多少行 : (例如 100,默认值:1) |
| rampUpTime | 在生成速度变为rowsPerSecond之前应该经过多久的加速时间(例如5 s,默认0) |
| numPartitions | 生成行的分区: (例如 10,默认值:Spark 的默认并行度) |
3、数据处理
指的是数据处理部分,该操作和Spark SQL中是完全一致。可以使用SQL方式进行处理,也可以使用DSL方式进行处理。
4、数据输出
在结构化流中定义好DataFrame或者处理好DataFrame之后,调用**writeStream()**方法完成数据的输出操作。在输出的过程中,我们可以设置一些相关的属性,然后启动结构化流程序运行。
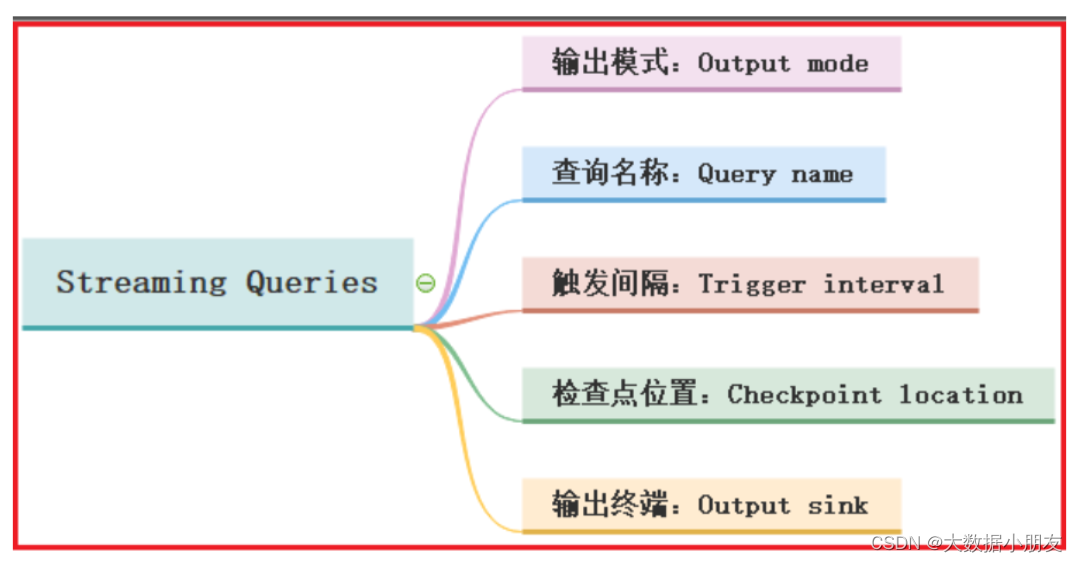
4.1 输出模式
可能遇到的错误:
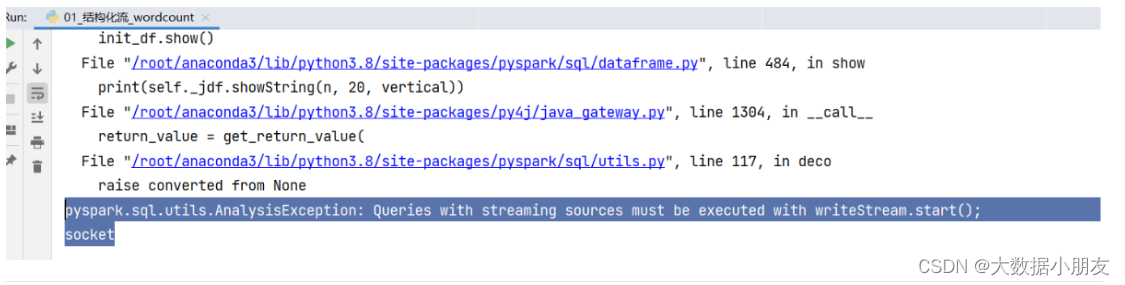
原因: 在结构化流中不能调用show()方法
解决办法: 需要使用writeStream().start()进行结果数据的输出
在进行数据输出的时候,必须通过outputMode来设置输出模式。输出模式提供了3种不同的模式:
-
1- append模式:增量模式 (默认)
特点:当结构化程序处理数据的时候,如果有了新数据,才会触发执行。而且该模式只支持追加。不支持数据处理阶段有聚合的操作。如果有了聚合操作,直接报错。而且也不支持排序操作。如果有了排序,直接报错。
-
2- complete模式:完全(全量)模式
特点:当结构化程序处理数据的时候,每一次都是针对全量的数据进行处理。由于数据越来越多,所以在数据处理阶段,必须要有聚合操作。如果没有聚合操作,直接报错。另外还支持排序,但是不是强制要求。
-
3- update模式:更新模式
特点:支持聚合操作。当结构化程序处理数据的时候,如果处理阶段没有聚合操作,该模式效果和append模式是一致。如果有了聚合操作,只会输出有变化和新增的内容。但是不支持排序操作,如果有了排序,直接报错。
4.1.1 append 模式
1- append模式:增量模式
特点:当结构化程序处理数据的时候,如果有了新数据,才会触发执行。而且该模式只支持追加。不支持数据处理阶段有聚合的操作。如果有了聚合操作,直接报错。而且也不支持排序操作。如果有了排序,直接报错。
如果有了聚合操作,会报如下错误:
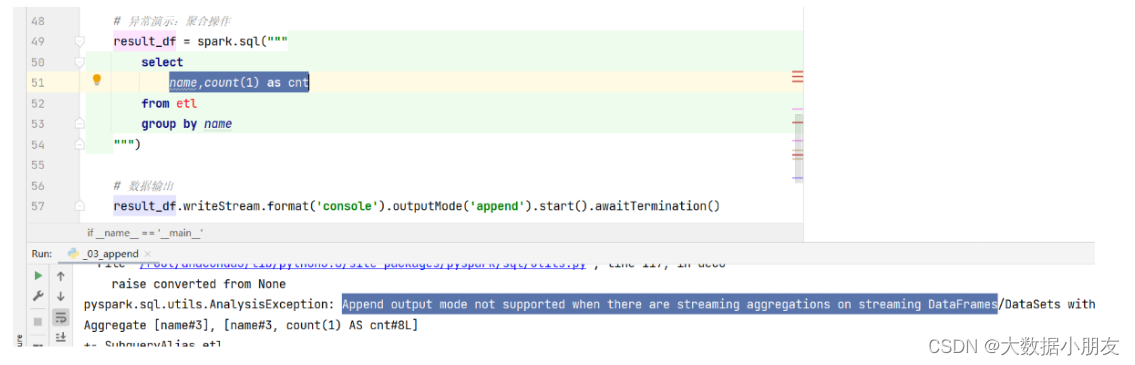
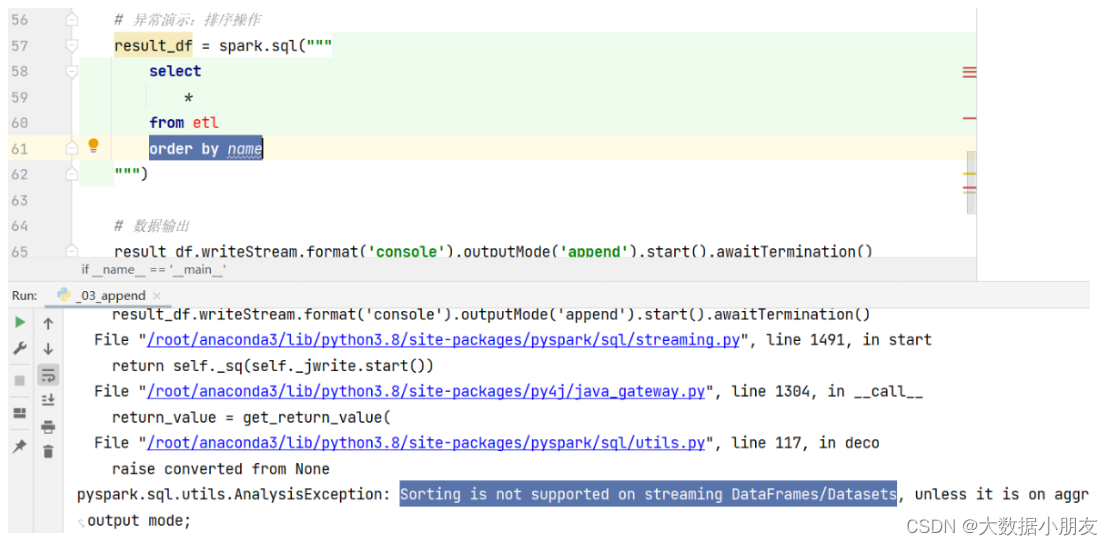
如果有了排序操作,会报如下错误:
4.1.2 complete模式
2- complete模式:完全(全量)模式
特点:当结构化程序处理数据的时候,每一次都是针对全量的数据进行处理。由于数据越来越多,所以在数据处理阶段,必须要有聚合操作。如果没有聚合操作,直接报错。另外还支持排序,但是不是强制要求。
如果没有聚合操作,会报如下错误:
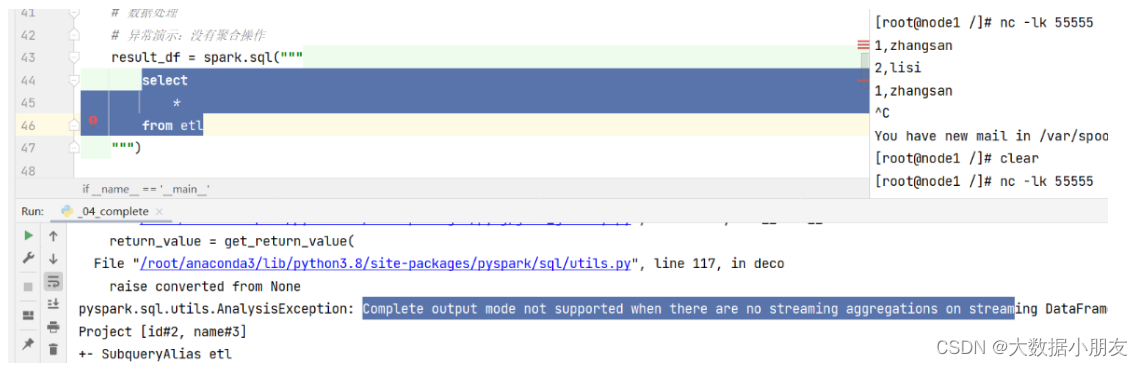
4.1.3 update模式
3- update模式:更新模式
特点:支持聚合操作。当结构化程序处理数据的时候,如果处理阶段没有聚合操作,该模式效果和append模式是一致。如果有了聚合操作,只会输出有变化和新增的内容。但是不支持排序操作,如果有了排序,直接报错。
如果有了排序操作,会报如下错误:
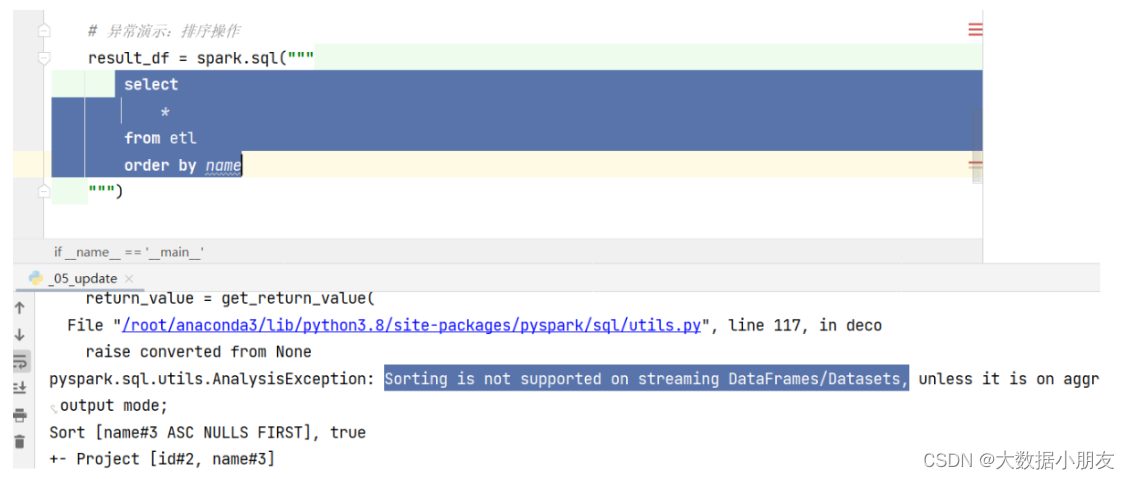
4.2 输出终端/位置
默认情况下,Spark的结构化流支持多种输出方案:
1- console sink: 将结果数据输出到控制台。主要是用在测试中,并且支持3种输出模式2- File sink: 输出到文件。将结果数据输出到某个目录下,形成文件数据。只支持append模式3- foreach sink 和 foreachBatch sink: 将数据进行遍历处理。遍历后输出到哪里,取决于自定义函数。并且支持3种输出模式4- memory sink: 将结果数据输出到内存中。主要目的是进行再次的迭代处理。数据大小不能过大。支持append模式和complete模式5- Kafka sink: 将结果数据输出到Kafka中。类似于Kafka中的生产者角色。并且支持3种输出模式
5、设置触发器Trigger
触发器Trigger:决定多久执行一次操作并且输出结果。也就是在结构化流中,处理完一批数据以后,等待一会,再处理下一批数据
主要提供如下几种触发器:
-
1- 默认方案:也就是不使用触发器的情况。如果没有明确指定,那么结构化流会自动进行决策每一个批次的大小。在运行过程中,会尽可能让每一个批次间的间隔时间变得更短
result_df.writeStream\.outputMode('append')\.start()\.awaitTermination() -
2- 配置固定的时间间隔:在结构化流运行的过程中,当一批数据处理完以后,下一批数据需要等待一定的时间间隔才会进行处理**(常用,推荐使用)**
result_df.writeStream\.outputMode('append')\.trigger(processingTime='5 seconds')\.start()\.awaitTermination()情形说明: 1- 上一批次的数据在时间间隔内处理完成了,那么会等待我们配置触发器固定的时间间隔结束,才会开始处理下一批数据 2- 上一批次的数据在固定时间间隔结束的时候才处理完成,那么下一批次会立即被处理,不会等待 3- 上一批次的数据在固定时间间隔内没有处理完成,那么下一批次会等待上一批次处理完成以后立即开始处理,不会等待 -
3- 仅此一次:在运行的过程中,程序只需要执行一次,然后就退出。这种方式适用于进行初始化操作,以及关闭资源等
result_df.writeStream.foreachBatch(func)\.outputMode('append')\.trigger(once=True)\.start()\.awaitTermination()
6、CheckPoint检查点目录设置
设置检查点,目的是为了提供容错性。当程序出现失败了,可以从检查点的位置,直接恢复处理即可。避免出现重复处理的问题
如何设置检查点:
1- SparkSession.conf.set("spark.sql.streaming.checkpointLocation", "检查点路径")
2- option("checkpointLocation", "检查点路径")推荐: 检查点路径支持本地和HDFS。推荐使用HDFS路径
检查点目录主要包含以下几个目录位置:
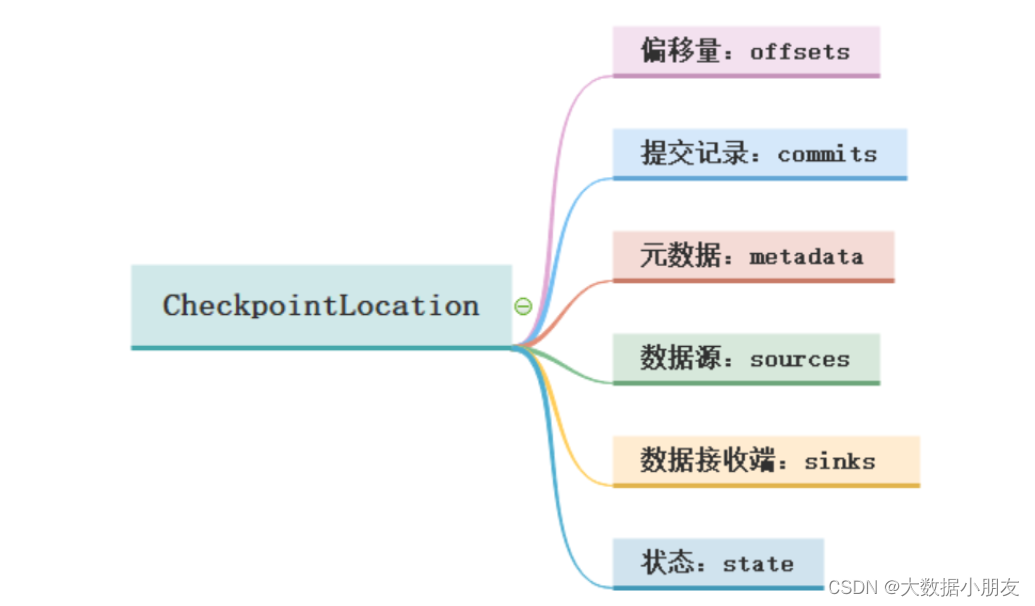
1-偏移量offsets: 记录每个批次中的偏移量。为了保证给定的批次始终包含相同的数据。在处理数据之前会将offset信息写入到该目录2-提交记录commits: 记录已经处理完成的批次。重启任务的时候会检查完成的批次和offsets目录中批次的记录进行对比。确定接下来要处理的批次3-元数据文件metadata: 和整个查询关联的元数据信息,目前只保留当前的job id4-数据源sources: 是数据源(Source)各个批次的读取的详情5-数据接收端sinks: 是数据接收端各个批次的写出的详情6-状态state: 当有状态操作的时候,例如:累加、聚合、去重等操作场景,这个目录会用来记录这些状态数据。根据配置周期性的生成。snapshot文件用于记录状态
7、综合案例(练习)
需求: 已知文件中存储了多个单词,要求计算统计出现的次数
7.1 词频统计_读取文件方式
# 导包
import os
from pyspark.sql import SparkSession,functions as F# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder\.config('spark.sql.shuffle.partitions',1)\.appName('pyspark_demo')\.master('local[*]')\.getOrCreate()# 2.数据输入# 注意: 路径必须是目录路径,因为readStream会自动读取此目录下的所有文件,有新增会触发接着读df = spark.readStream\.format('text')\.load('file:///export/data/spark_project/structured_Streaming/data/')# 查看数据类型print(type(df))# 3.数据处理(切分,转换,分组聚合)# 和SparkSQL操作一模一样,支持sql和dsl两种风格# SQL方式df.createTempView('tb')sql_df = spark.sql("""select words,count(1) as cntfrom (select explode(split(value,' ')) as words from tb) t group by words""")# DSL方式dsl_df = df.select(F.explode(F.split('value',' ')).alias('words')).groupBy('words').agg(F.count('words').alias('cnt'))# 4.数据输出# 注意: 输出不能使用原来sparksql的show()# 注意: 如果需要多开启多个输出,.awaitTermination()只需要在最后一个出现即可sql_df.writeStream.format('console').outputMode('complete').start()dsl_df.writeStream.format('console').outputMode('complete').start().awaitTermination()# 5.关闭资源spark.stop()
7.2 词频统计_Socket方式
# 导包
import os
from pyspark.sql import SparkSession,functions as F# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象spark = SparkSession.builder\.config('spark.sql.shuffle.partitions',1)\.appName('pyspark_demo')\.master('local[*]')\.getOrCreate()# 2.数据输入# 注意: 路径必须是目录路径,因为readStream会自动读取此目录下的所有文件,有新增会触发接着读df = spark.readStream\.format('socket')\.option('host',"192.168.88.161")\.option('port',"55555")\.load()# 查看数据类型print(type(df))# 3.数据处理(切分,转换,分组聚合)# 和SparkSQL操作一模一样,支持sql和dsl两种风格# SQL方式df.createTempView('tb')sql_df = spark.sql("""select words,count(1) as cntfrom (select explode(split(value,' ')) as words from tb) t group by words""")# DSL方式dsl_df = df.select(F.explode(F.split('value',' ')).alias('words')).groupBy('words').agg(F.count('words').alias('cnt'))# 4.数据输出# 注意: 输出不能使用原来sparksql的show()# 注意: 如果需要多开启多个输出,.awaitTermination()只需要在最后一个出现即可sql_df.writeStream.format('console').outputMode('complete').start()dsl_df.writeStream.format('console').outputMode('complete').start().awaitTermination()# 5.关闭资源spark.stop()7.3 自动生成数据_Rate方式
from pyspark.sql import SparkSession
import osos.environ["SPARK_HOME"] = "/export/server/spark"
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"if __name__ == '__main__':# 1.创建SparkSession对象spark = SparkSession.builder \.appName("StructuredStream_rate") \.master('local[*]') \.getOrCreate()# 2。读取数据df = spark.readStream \.format('rate') \.option("rowsPerSecond", "5") \.option('numPartitions', 1) \.load()# 3.数据处理# 略# 4.数据输出:df.writeStream \.format('console') \.outputMode('update') \.option('truncate', 'false') \.start() \.awaitTermination()# 5.关闭资源spark.stop()
三、Spark 和 Kafka 整合(掌握)
Spark天然支持集成Kafka, 基于Spark读取Kafka中的数据, 同时可以实施精准一次(仅且只会处理一次)的语义, 作为程序员, 仅需要关心如何处理消息数据即可, 结构化流会将数据读取过来, 转换为一个DataFrame的对象, DataFrame就是一个无界的DataFrame, 是一个无限增大的表
1、整合Kafka准备工作
说明: Jar包上传的位置说明
如何放置相关的Jar包? 1- 放置位置一: 当spark-submit提交的运行环境为Spark集群环境的时候,以及运行模式为local, 默认从 spark的jars目录下加载相关的jar包,目录位置: /export/server/spark/jars2- 放置位置二: 当我们使用pycharm运行代码的时候, 基于python的环境来运行的, 需要在python的环境中可以加载到此jar包目录位置: /root/anaconda3/lib/python3.8/site-packages/pyspark/jars/3- 放置位置三: 当我们提交选择的on yarn模式 需要保证此jar包在HDFS上对应目录下hdfs的spark的jars目录下: hdfs://node1:8020/spark/jars请注意: 以上三个位置, 主要是用于放置一些 spark可能会经常使用的jar包, 对于一些不经常使用的jar包, 在后续spark-submit 提交运行的时候, 会有专门的处理方案: spark-submit --jars jar包路径jar包下载地址: https://mvnrepository.com/
2、从kafka中读取数据
spark和kafka集成官网文档:
https://spark.apache.org/docs/3.1.2/structured-streaming-kafka-integration.html
2.1 流式处理
官方示例:
# 订阅Kafka的一个Topic,从最新的消息数据开始消费
df = spark \.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \.option("subscribe", "topic1") \.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")# 订阅Kafka的多个Topic,多个Topic间使用英文逗号进行分隔。从最新的消息数据开始消费
df = spark \.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \.option("subscribe", "topic1,topic2") \.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")# 订阅一个Topic,并且指定header信息
df = spark \.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \.option("subscribe", "topic1") \.option("includeHeaders", "true") \.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "headers")# 订阅符合规则的Topic,从最新的数据开始消费
df = spark \.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \.option("subscribePattern", "topic.*") \.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
练习示例
对接kafka后,返回的结果数据内容:
key: 发送数据的key值。如果没有,就为null value: 最重要的字段。发送数据的value值,也就是消息内容。如果没有,就为null topic: 表示消息是从哪个Topic中消费出来 partition: 分区编号。表示消费到的该条数据来源于Topic的哪个分区 offset: 表示消息偏移量timestamp: 接收的时间戳 timestampType: 时间戳类型(无意义)类型的说明:
列名 类型 key binary value binary topic string partition int offset long timestamp timestamp timestampType int headers (optional) array
从某一个Topic中读取消息数据
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1- 创建SparkSession对象spark = SparkSession.builder\.config("spark.sql.shuffle.partitions",1)\.appName('ss_read_kafka_1_topic')\.master('local[*]')\.getOrCreate()# 2- 数据输入# 默认从最新的地方开始消费df = spark.readStream\.format("kafka")\.option("kafka.bootstrap.servers","node1:9092")\.option("subscribe","itheima")\.load()# 查看类型print(type(df))# 注意: 字符串需要解码!!!etl_df = df.select(F.expr("cast(key as string) as key"),F.decode(df.key,'utf8'),F.expr("cast(value as string) as value"),F.decode(df.value, 'utf8'),df.topic,df.partition,df.offset)# 获取数据etl_df.writeStream.format("console").outputMode("append").start().awaitTermination()# 3- 数据处理# result_df1 = init_df.select(F.expr("cast(value as string) as value"))# # selectExpr = select + F.expr# result_df2 = init_df.selectExpr("cast(value as string) as value")# result_df3 = init_df.withColumn("value",F.expr("cast(value as string)"))# 4- 数据输出# 5- 启动流式任务"""如果有多个输出,那么只能在最后一个start的后面写awaitTermination()"""# result_df1.writeStream.queryName("result_df1").format("console").outputMode("append").start()# result_df2.writeStream.queryName("result_df2").format("console").outputMode("append").start()# result_df3.writeStream.queryName("result_df3").format("console").outputMode("append").start().awaitTermination()2.2 批处理
官方示例:
# 订阅一个Topic主题, 默认从最早到最晚的偏移量范围
df = spark \.read \.format("kafka") \.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \.option("subscribe", "topic1") \.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")# 批处理订阅Kafka的多个Topic数据。并且可以通过startingOffsets和endingOffsets指定要消费的消息偏移
# 量(offset)范围。"topic1":{"0":23,"1":-2} 含义是:topic1,"0":23从分区编号为0的分区的
# offset=23地方开始消费,"1":-2 从分区编号为1的分区的最开始的地方开始消费df = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1,topic2") \
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""") \
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")# 通过正则匹配多个Topic, 默认从最早到最晚的偏移量范围
df = spark \.read \.format("kafka") \.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \.option("subscribePattern", "topic.*") \.option("startingOffsets", "earliest") \.option("endingOffsets", "latest") \.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
演示示例
参数说明:
选项 值 说明 assign 通过一个Json 字符串的方式来表示: {“topicA”:[0,1],“topicB”:[2,4]} 设置使用特定的TopicPartitions subscribe 以逗号分隔的Topic主题列表 要订阅的主题列表 subscribePattern 正则表达式字符串 订阅匹配符合条件的Topic。assign、subscribe、subscribePattern任意指定一个。 kafka.bootstrap.servers 以英文逗号分隔的host:port列表 指定kafka服务的地址
订阅一个Topic
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1- 创建SparkSession对象spark = SparkSession.builder\.config("spark.sql.shuffle.partitions",1)\.appName('sparksql_read_kafka_1_topic')\.master('local[*]')\.getOrCreate()# 2- 数据输入# 默认从Topic开头一直消费到结尾df = spark.read\.format("kafka")\.option("kafka.bootstrap.servers","node1.itcast.cn:9092,node2.itcast.cn:9092")\.option("subscribe","itheima")\.load()# 查看类型print(type(df))# 注意: 字符串需要解码!!!etl_df = df.select(F.expr("cast(key as string) as key"),F.decode(df.key,'utf8'),F.expr("cast(value as string) as value"),F.decode(df.value, 'utf8'),df.topic,df.partition,df.offset)# 获取数据etl_df.show()# # 3- 数据处理# result_df1 = init_df.select(F.expr("cast(value as string) as value"))# # selectExpr = select + F.expr# result_df2 = init_df.selectExpr("cast(value as string) as value")# result_df3 = init_df.withColumn("value",F.expr("cast(value as string)"))# # 4- 数据输出# print("result_df1")# result_df1.show()# print("result_df2")# result_df2.show()# print("result_df3")# result_df3.show()# # 5- 释放资源# spark.stop()
3、数据写入Kafka中
3.1 流式处理
官方示例:
# 将Key和Value的数据都写入到Kafka当中
ds = df \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.start()# 将Key和Value的数据都写入到Kafka当中。使用DataFrame数据中的Topic字段来指定要将数据写入到Kafka集群
# 的哪个Topic中。这种方式适用于消费多个Topic的情况
ds = df \
.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.start()
练习示例
备注 Column 数据类型 可选字段 key string or binary 必填字段 value string or binary 可选字段 headers array 必填字段 topic string 可选字段 partition int
写出到指定Topic
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1- 创建SparkSession对象spark = SparkSession.builder\.config("spark.sql.shuffle.partitions",1)\.appName('ss_read_kafka_1_topic')\.master('local[*]')\.getOrCreate()# 2- 数据输入# 默认从最新的地方开始消费init_df = spark.readStream\.format("kafka")\.option("kafka.bootstrap.servers","node1:9092,node2:9092")\.option("subscribe","itheima")\.load()# 3- 数据处理result_df = init_df.select(F.expr("concat(cast(value as string),'_itheima') as value"))# 4- 数据输出# 注意: 咱们修改完直接保存到kafka的itcast主题中,所以控制台没有数据,这是正常的哦!!!# 5- 启动流式任务result_df.writeStream\.format("kafka")\.option("kafka.bootstrap.servers","node1:9092,node2:9092")\.option("topic","itcast")\.option("checkpointLocation", "hdfs://node1:8020/ck")\.start()\.awaitTermination()
3.2 批处理
官方示例:
# 从DataFrame中写入key-value数据到一个选项中指定的特定Kafka topic中
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \.write \.format("kafka") \.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \.option("topic", "topic1") \.save()# 使用数据中指定的主题将key-value数据从DataFrame写入Kafka
df.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)") \.write \.format("kafka") \.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \.save()
演示示例
备注 Column 数据类型 可选字段 key string or binary 必填字段 value string or binary 可选字段 headers array 必填字段 topic string 可选字段 partition int
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1- 创建SparkSession对象spark = SparkSession.builder\.config("spark.sql.shuffle.partitions",1)\.appName('ss_read_kafka_1_topic')\.master('local[*]')\.getOrCreate()# 2- 数据输入# 默认从最新的地方开始消费init_df = spark.read\.format("kafka")\.option("kafka.bootstrap.servers","node1:9092,node2:9092")\.option("subscribe","itheima")\.load()# 3- 数据处理result_df = init_df.select(F.expr("concat(cast(value as string),'_666') as value"))# 4- 数据输出# 5- 启动流式任务result_df.write.format("kafka")\.option("kafka.bootstrap.servers","node1:9092,node2:9092")\.option("topic","itcast")\.option("checkpointLocation", "hdfs://node1:8020/ck")\.save()
四、物联网数据分析案例(熟悉)
1、数据模拟器代码
- 1- 创建一个topic, 放置后续物联网的数据 search-log-topic
./kafka-topics.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --create --topic search-log-topic --partitions 3 --replication-factor 2
- 2- 将代码放置到项目中:
import json
import random
import sys
import time
import os
from kafka import KafkaProducer
from kafka.errors import KafkaError# 锁定远端操作环境, 避免存在多个版本环境的问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"# 快捷键: main 回车
if __name__ == '__main__':print("模拟物联网数据")# 1- 构建一个kafka的生产者:producer = KafkaProducer(bootstrap_servers=['node1:9092', 'node2:9092', 'node3:9092'],acks='all',value_serializer=lambda m: json.dumps(m).encode("utf-8"))# 2- 物联网设备类型deviceTypes = ["洗衣机", "油烟机", "空调", "窗帘", "灯", "窗户", "煤气报警器", "水表", "燃气表"]while True:index = random.choice(range(0, len(deviceTypes)))deviceID = f'device_{index}_{random.randrange(1, 20)}' # 设备IDdeviceType = deviceTypes[index] # 设备类型deviceSignal = random.choice(range(10, 100)) # 设备信号# 组装数据集print({'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,'time': time.strftime('%s')})# 发送数据producer.send(topic='search-log-topic',value={'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,'time': time.strftime('%s')})# 间隔时间 5s内随机time.sleep(random.choice(range(1, 5)))
- 测试, 观察是否可以正常生成:
./kafka-topics.sh --bootstrap-server node1.itcast.cn:9092,node2.itcast.cn:9092 --describe --topic search-log-topic
2、需求说明
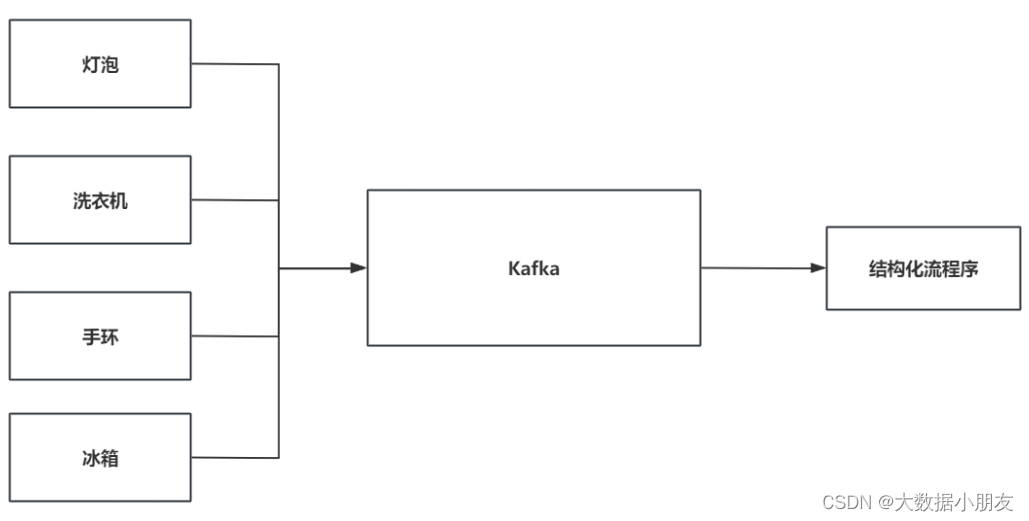
目前咱们有一个模拟器程序, 可以向Kafka不断的写入数据
要做的是, 用Spark的结构化流接收数据, 并且对数据进行统计分析操作:
- 求: 各种信号强度>30各种类型的设备数量 和 它们的平均信号强度
需求分析:
1- 需要按照设备类型进行分组,也就是维度是设备类型deviceType
2- 指标
设备数量:deviceID
平均信号强度:deviceSignal
示例数据:
{‘deviceID’: ‘device_1_1’, ‘deviceType’: ‘油烟机’, ‘deviceSignal’: 23, ‘time’: ‘1668848417’}
{‘deviceID’: ‘device_0_4’, ‘deviceType’: ‘洗衣机’, ‘deviceSignal’: 55, ‘time’: ‘1668848418’}
deviceID: 设备ID
deviceType: 设备类型
deviceSignal: 设备信号
time : 设备发送时间戳
3、代码实现
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'def sql():# SQL# 3.2- 拆解数据结构。将json解析得到单个的字段"""get_json_object(参数1,参数2):用来解析json串。一次只能得到一个字段的值参数1:要解析的json字段名称参数2:字段的解析路径 $.字段路径"""etl_df = spark.sql("""selectget_json_object(value,'$.deviceID') as deviceID,get_json_object(value,'$.deviceType') as deviceType,get_json_object(value,'$.deviceSignal') as deviceSignal,get_json_object(value,'$.time') as timefrom iot""")etl_df.createTempView("etl")# 3.3- 各种信号强度>30各种类型的设备数量 和 它们的平均信号强度result_df = spark.sql("""selectdeviceType,count(deviceID) as cnt_deviceID,round(avg(deviceSignal),2) as avg_deviceSignalfrom etlwhere deviceSignal>30group by deviceType""")# 4- 数据输出# 5- 启动流式任务result_df.writeStream.format('console').outputMode('complete').start().awaitTermination()def dsl():result_df = etl_tmp_df.select(F.get_json_object('value', '$.deviceID').alias('deviceID'),F.get_json_object('value', '$.deviceType').alias('deviceType'),F.get_json_object('value', '$.deviceSignal').alias('deviceSignal'),F.get_json_object('value', '$.time').alias('time')).where('deviceSignal>30').groupBy('deviceType').agg(F.count('deviceID').alias('cnt_deviceID'),F.round(F.avg('deviceSignal'), 2).alias('avg_deviceSignal'))# 4- 数据输出# 5- 启动流式任务result_df.writeStream.format('console').outputMode('complete').start().awaitTermination()if __name__ == '__main__':# 1- 创建SparkSession对象spark = SparkSession.builder\.config("spark.sql.shuffle.partitions",2)\.appName('iot')\.master('local[*]')\.getOrCreate()# 2- 数据输入init_df = spark.readStream\.format("kafka") \.option("kafka.bootstrap.servers", "node1.itcast.cn:9092,node2.itcast.cn:9092") \.option("subscribe", "search-log-topic") \.load()# 3- 数据处理# 3.1- 数据ETL:进行数据类型转换,将value字段bytes->字符串etl_tmp_df = init_df.selectExpr("cast(value as string) as value")etl_tmp_df.createTempView('iot')# SQL# sql()# DSLdsl()
运行结果截图:

注意事项:
结构化流不支持的操作:
- 多个流同时聚合
- limit和take不能使用
- 不能使用去重操作
- Few types of outer joins on streaming Datasets are not supported. See the support matrix in the Join Operations section for more details.