paper:Patches Are All You Need?
official implementation:https://github.com/locuslab/convmixer
精度上去了,推理速度只有卷积和ViTs的四分之一!
出发点
文章讨论了卷积神经网络(CNN)在视觉任务中的主导地位,以及近期基于Transformer模型的架构(特别是Vision Transformer,ViT)在某些情况下可能超越了CNN的性能。ViT由于自注意力层的二次运行时间复杂度,需要使用patch embeddings来处理更大的图像尺寸。
作者探讨了ViT的高性能是否源于Transformer架构本身的强大能力,还是部分归因于使用patches作为输入表示。
创新点
文章提出了一个新的模型——ConvMixer,这是一个非常简单的模型,它直接在patches上操作输入,分离空间和通道维度的混合,并在整个网络中保持相同的尺寸和分辨率。ConvMixer使用标准的卷积来实现混合步骤,而不是Transformer架构。
- 模型设计:ConvMixer的设计灵感来自于ViT和MLP-Mixer,但它只使用标准的卷积操作来处理输入patches。
- 简化架构:与ViT和MLP-Mixer相比,ConvMixer通过简化架构,减少了模型的复杂性。
- 性能与效率:尽管ConvMixer的实现非常简单,但作者展示了它在相似参数计数和数据集大小下,性能超过了ViT、MLP-Mixer以及传统的视觉模型如ResNet。
通过ConvMixer的性能表现,作者认为patch embeddings(图像分块嵌入)可能是导致新型架构(如Vision Transformers)性能提升的一个关键因素。通过在网络的初始阶段一次性完成所有的下采样,即减小内部分辨率并增加有效感受野大小,有助于混合远距离的空间信息。
此外,ConvMixer提供了一个强大的“等距”(isotropic)架构模板,该架构通过简单的patch embeddings stem实现,这为深度学习提供了一个有效的框架
方法介绍
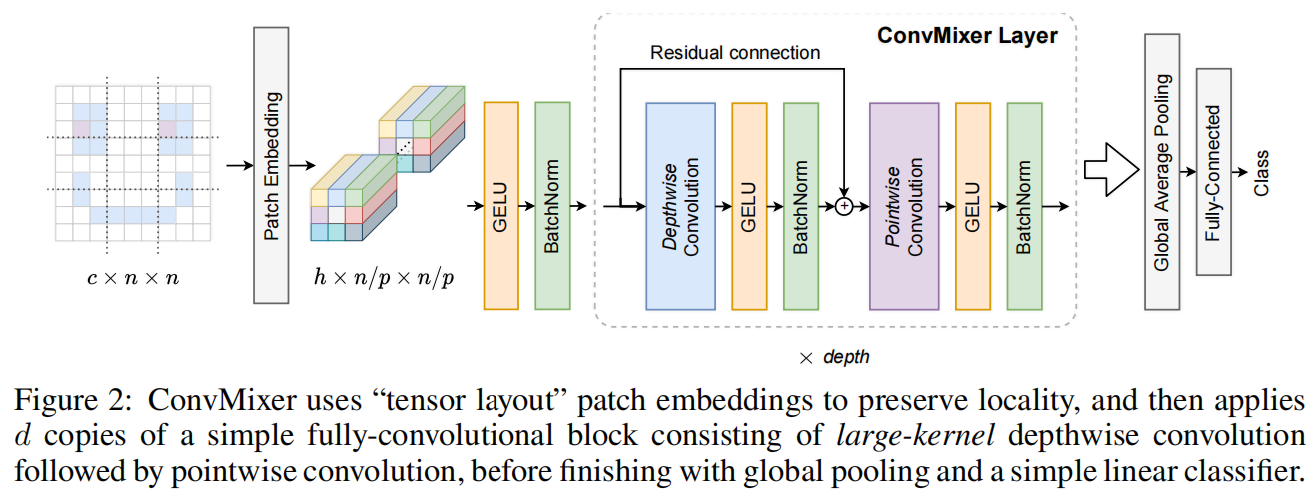
如图2所示,ConvMixer的结构非常简单,包括一个patch embedding层,然后重复堆叠一个简单的全卷积block。在patch embedding后保持空间分辨率一直到网络结束,对于patch size为 \(p\) embdding维度为 \(h\) 的patch embedding层可以通过一个输入通道数为 \(c_{in}\),输出通道数为 \(h\),kernel size为 \(p\),stride为 \(p\) 的卷积实现

ConvMixer block由一个depthwise convolution和一个pointwise convolution组成。MLP和self-attention可以mix distance spatial locations,即具有很大或者全局的感受野从而可以捕获长距离依赖关系,受此启发,ConvMixer中的深度卷积采用了非常大的卷积核,比如7或 9。在每个卷积后都有一个激活函数和一个post-activation BatchNorm

最后通过一个global average pooling和一个softmax classifier得到最终的分类预测结果。
实验结果
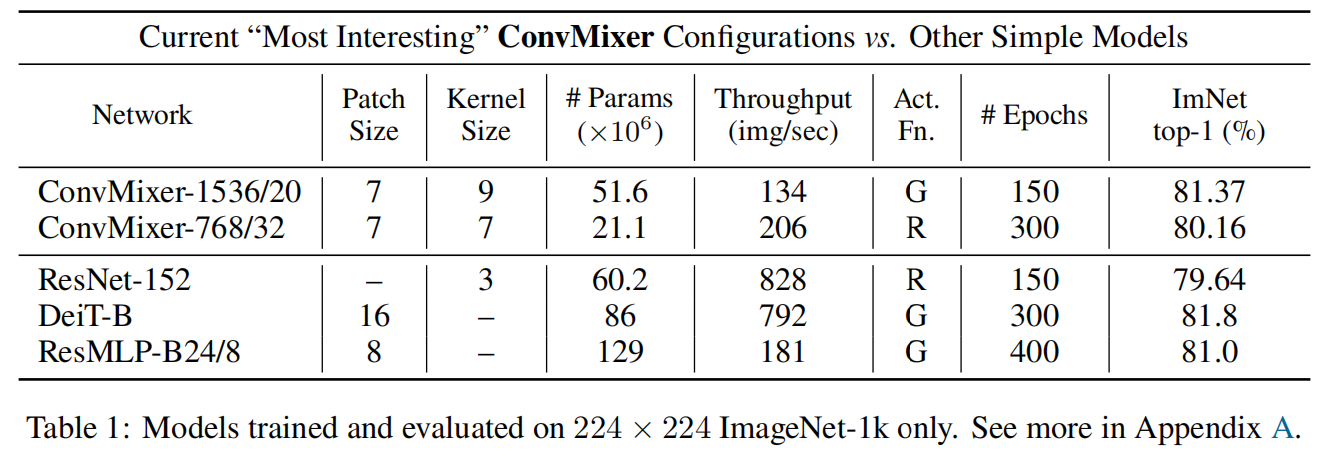
ConvMixer不同大小的模型通过ConvMixer-h/d来命名,其中h表示hidden dimension即patch embedding的维度,d表示网络深度即图2中ConvMixer Layer的数量。和三种不同架构的代表性网络在ImageNet上的性能对比如表1所示,注意这里ConvMixer没有经过专门的调参,训练配置都是直接采用ResNet和DeiT中的一些常规设置,并且训练Epoch也更短。可以看到ConvMixer取得了几句竞争力的结果,同时参数量也很少,但存在一个非常大的缺点,吞吐很小或者说推理速度很慢。
但这里有一个问题就是ConvMixer的patch size非常小只有DeiT的一半,比ResMLP-B24/8还小1,这种情况下比较是不公平的。如果增大patch size,就达不到卷积网络或ViTs的精度,减小的patch size精度上去了延迟只有卷积和ViTs的四分之一,表明ConvMixer和MLP类的网络还存在局限。
代码解析
这里以timm中的实现为例,输入大小为(1, 3, 224, 224),模型选择"convmixer_768_32",具体配置如下
model_args = dict(dim=768, depth=32, kernel_size=7, patch_size=7, act_layer=nn.ReLU, **kwargs)其中核心部分block的实现非常简单,如下,每层就是7x7 depthwise conv + ReLU + BN + 1x1 conv + ReLU + BN,此外还是用了residual connection。
class Residual(nn.Module):def __init__(self, fn):super().__init__()self.fn = fndef forward(self, x):return self.fn(x) + xself.blocks = nn.Sequential(*[nn.Sequential(Residual(nn.Sequential(nn.Conv2d(dim, dim, kernel_size, groups=dim, padding="same"),act_layer(),nn.BatchNorm2d(dim))),nn.Conv2d(dim, dim, kernel_size=1),act_layer(),nn.BatchNorm2d(dim)) for i in range(depth)])