目录
1.定义
2.工作流程
3.Fiddler
3.1 使用
3.2 工作原理
4.URL
5.请求和响应
5.1 请求
5.2 响应
6.GET和POST
6.1 经典面试题:GET和POST的区别
6.2 GET
6.3 POST
7.请求报头(Header)
7.1 HOST
7.2 Content-Length
7.3 Content-Type
7.4 User-Agent(UA)
7.5 Referer
7.6 Cookie
8.HTTP响应
8.1 总结
8.2 详解
1.定义
HTTP(全称为"超文本传输协议")是⼀种应用非常广泛的应用层协议。
HTTP往往是基于传输层的TCP协议实现的。
使用HTTP协议的场景:
1.浏览器打开网站(基本上)
2.手机APP访问对应的服务器(大概率)
HTTP协议,是一种“一问一答”结构模型的协议
(一问一答(访问网站)多问一答(上传文件) 一问多答(下载文件) 多问多答(串流/远程桌面))
2.工作流程
当我们在浏览器中输⼊⼀个"网址",此时浏览器就会给对应的服务器发送⼀个HTTP请求。对方服务器收到这个请求之后,经过计算处理,就会返回⼀个HTTP响应。
事实上,当我们访问⼀个网站的时候,可能涉及不止一次的HTTP请求/响应的交互过程。
3.Fiddler
3.1 使用
如何查看到HTTP请求和响应的格式呢?
抓包工具-Fiddler
把网卡上经过的数据,获取到,并显示出来(程序员必备技能,分析调试程序的重要手段)

左侧有一个列表,列出来抓到的包有哪些,右侧是包的详情,点击某个包
右侧上方,是请求详情
右侧下方,是响应详情

Fiddler本质上是一个“代理”,可能会和其他的软件代理冲突
使用Fiddler不能抓包,一定要检查关闭之前的代理软件(也有可能是一个浏览器插件),还可以尝试不同的浏览器。
postman是构造请求
fiddler抓取/显示已有的请求
3.2 工作原理
Fiddler相当于⼀个"代理"。
浏览器访问sogou.com时,就会把HTTP请求先发给Fiddler,Fiddler再把请求转发给sogou的服务器.当sogou服务器返回数据时,Fiddler拿到返回数据,再把数据交给浏览器。
因此Fiddler对于浏览器和sogou服务器之间交互的数据细节,都是非常清楚的。

4.URL
(计算机中非常重要的一个概念,不仅仅是在HTTP中涉及到),描述了某个资源在网络上的所属位置

http://魔仙堡大学:18/熏肉大饼/猪肉熏肉大饼?葱=少放&辣椒=微辣&香菜=不要
5.请求和响应
5.1 请求
1.首行

http请求的第一行,有三个部分的信息,三个部分使用空格分割
a. GET , HTTP 请求的“方法”(method)
GET请求,通常会把要传给服务器的数据,加到url的query string中
POST请求,通常会把要传给服务器的数据,加到body中
b.URL 唯一资源定位符 描述了一个资源在网络上的位置
c.版本号
![]()
2.请求头(header)
是一个键值对结构的数据(有很多键值对),每个键值对独占一行
键和值之间,使用:空格来区分
这里的键值对都是属于“标准规定的”
![]()
3.空行
请求头的结束标记
4.正文(body)
5.2 响应
1.首行

版本号:HTTP/1.1
状态码(200) 描述了请求的结果
状态码描述(OK)
2.响应头

也是键值对结构(有多个键值对),每个键值对独占一行,键和值之间使用:空格来区分,键值对也是“标准规定”的
3.空行
响应头结束的标记
4.正文(body)
正文里的内容可能比较长,可能是多种格式,HTML,CSS,JSON,XML,图片,字体,视频,音频…..
6.GET和POST
6.1 经典面试题:GET和POST的区别
开篇,先盖棺定论,GET和POST没有本质区别(双方可以替换对方的场景)
虽然没有本质区别,但是在使用习惯上,还是存在一些差异的
1.GET经常把传递给服务器的数据放到query string中,POST则是经常放到body中(使用习惯上最大的差别)
(上述情况并非绝对,GET也可以使用body,POST也可以使用query string,使用的前提是客户端/服务器都得按照一样的方式来处理代码)一般还是建议大家要遵守上述的约定俗称的习惯
2.语义上的差异(虽然语义上HTTP的使用是比较混乱的,但是相比之下,GET和POST还是比较明确的)
GET大多数还是用来获取数据的
POST大多数还是用来提交数据的(登录+上传)
GET和POST之间的差别,需要注意:
1.GET请求能传递的数据量有上限,POST传递的数据量没有上限 (错误的说法)
早期版本的浏览器,硬件资源比较匮乏,针对GET请求的URL的长度做出了限制,现在的浏览器和服务器的实现过程中,URL可以是非常长的
2.GET请求传递的数据不安全,POST请求传递数据更安全(错误的说法)
3.GET只能给服务器传输文本数据,而POST可以给服务器传输文本和二进制数据 (错误的说法 )
1)GET也不是不能使用body(body中是直接可以放二进制的)
2)GET也可以把二进制的数据进行base64转码,放到url的query string中
4.GET请求是幂等的,POST请求不是幂等的(这个说法不够准确,但是也不是完全错)
幂等是数学的一个概念,输入相同的内容,输出是稳定的,就是幂等
GET和POST具体是否幂等,取决于代码的实现
建议GET请求实现成幂等的
5.GET请求可以被浏览器缓存,POST不可以被缓存(幂等性的延续,如果请求是幂等,自然就可以缓存)
6.GET请求可以被浏览器收藏夹收藏,POST不能(收藏的时候可能会丢失body)(暂且认为是对的)
6.2 GET
GET是最常⽤的HTTP⽅法.常⽤于获取服务器上的某个资源.在浏览器中直接输⼊URL,此时浏览器就会发送出⼀个GET请求.另外,HTML中的link,img,script等标签,也会触发GET请求。

首行的第⼀部分为GET
URL的query string可以为空,也可以不为空.
header部分有若干个键值对结构.
body部分为空.
6.3 POST
POST方法也是⼀种常见的方法.多用于提交输入用户的数据给服务器(例如登陆页面).
通过HTML中的form标签可以构造POST请求,或者使用JavaScript的ajax也可以构造POST请求.

首行的第⼀部分为POST
URL的query string⼀般为空(也可以不为空)
header部分有若干个键值对结构。
body部分⼀般不为空。body内的数据格式通过header中的Content-Type指定.body的长度
由header中的Content-Length指定。
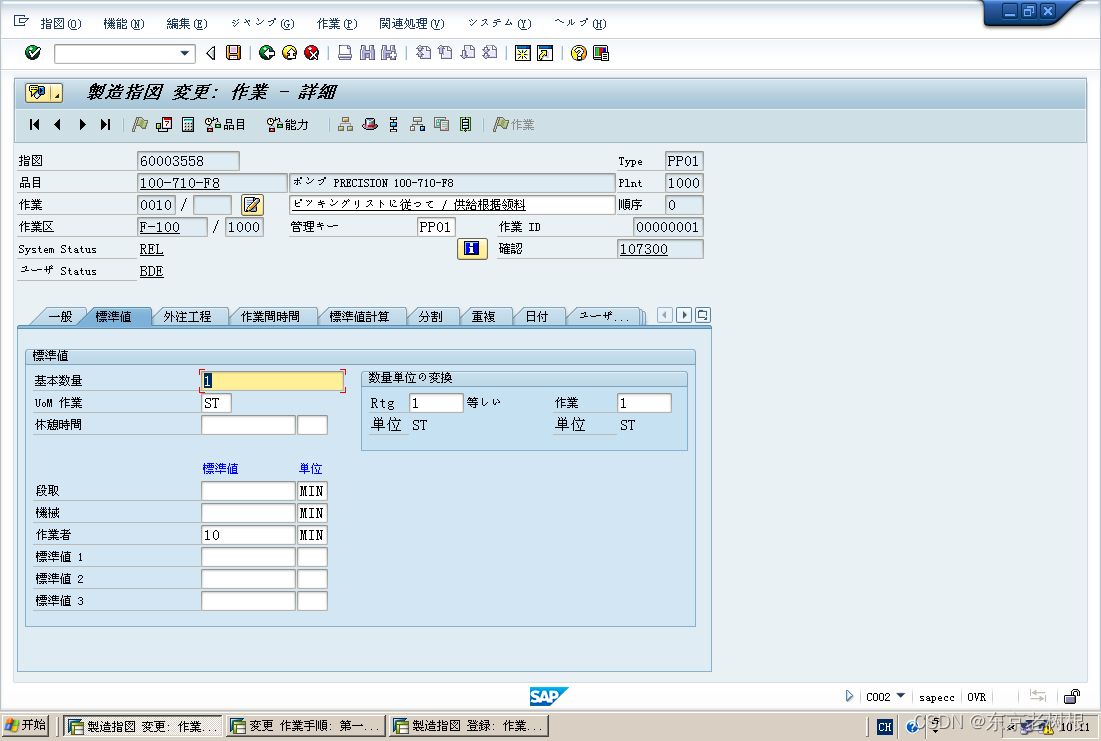
7.请求报头(Header)
header的整体的格式也是"键值对"结构.每个键值对占一行.键和值之间使用分号分割.
7.1 HOST
表示服务器主机的地址和端口号
![]()
这个信息是在url中也是存在的
7.2 Content-Length
表示body中的数据长度
7.3 Content-Type
表示body中的数据格式
请求里面有body,才会有这两个属性,通常情况下GET请求没有body,POST请求有body
TCP涉及到粘包问题,HTTP在传输层就是基于TCP的
使用同一个TCP连接,传输多个HTTP数据包,此时,就会使多个HTTP数据包在TCP接收缓冲区中挨在一起,接收方解析的时候,就需要能够清楚HTTP数据包之间的边界
对于GET这样没有body的请求,直接使用空行(分隔符)
对于POAT这样有body的请求,就结合空行和Content-Length
body中的格式,可以选择的方式是非常多的~
请求:
1.json
2.form表单的格式
3.from-data的格式
响应:
1.html
2.css
3.js 绿色的
4.json
5.图片…..
后续给服务器提交给请求,不同的Content-Type,服务器处理数据的逻辑是不同的
服务器返回数据给浏览器,也需要设置合适的Content-Type,浏览器也会根据不同的Content-Type做出不同的处理
7.4 User-Agent(UA)
![]()
描述操作系统和浏览器的版本,即使用什么设备上网
现在UA主要是用来区分PC端还是移动端
7.5 Referer
描述了当前页面是从哪个页面跳转出来的
如果是直接在地址栏输入url(或者点击收藏夹中的按钮)

现在,网络上网站都是HTTPS为主了,很少见HTTP
7.6 Cookie
Cookie 可以认为是浏览器在本地存储的一种机制
浏览器的数据来自于服务器
浏览器后续的操作也是要提交给服务器的
服务器这边管理了一个网站的各种核心数据
但是程序运行过程中,也会有一些数据,需要在浏览器这边存储的,并且在后续请求的时候数据可能需要再发给服务器
(上次登录的时间,上次访问的时间,用户的身份信息,累计的访问次数…….)临时性的数据,存储在浏览器比较合适
为了保证安全性,又能进行存储数据,于是就引入了Cookie(网页只能往cookie中存储 键值对)
Cookie往往是从服务器返回的数据(也可以是页面自己生成的),
Cookie存储到浏览器所在主机的硬盘上,并且是按照域名为维度来存储的(每个域名下可以存储自己的Cookie,彼此之间不影响)
Cookie是按照键值对的形式来组织的,这里的键值对也都是程序员自定义的(和query string差不多)
后续再请求这个服务器的时候,就会把Cookie中的内容自动带入到请求中,发给服务器,服务器通过Cookie的内容做一些逻辑上的处理
![]()
键值对之间,使用;分割,键和值使用=分割
这些内容就是浏览器本地存储的cookie,都会在后续请求服务器的时候,把这些内容给带入到请求中,传给服务器
8.HTTP响应
8.1 总结

8.2 详解
2xx都表示成功
3xx表示重定向
重定向:请求访问的是A这样的地址 响应返回了一个重定向报文,告诉你应该要访问B的地址
很多时候,页面跳转,就可以通过重定向来实现,还有时候,某个网站,服务器迁移了,就可以给旧的地址挂一个重定向响应,访问旧地址
301 Moved Permanently 永久重定向
302 Move Temporarily 临时重定向
重定向的响应报文中,会带有Location字段,描述出当前要跳转到哪个新地址
4xx表示客户端错误
404 NOT FOUND
特殊的状态码:418 I am a teapot!(杯具)
418状态码是HTTP RFC文档中专门规定的一个状态码
这个状态码并没有实际的意义,只是开个玩笑,称为彩蛋
5xx表示服务器错误