第1关:Jieba 在关键词提取中的应用
任务描述
本关任务:根据本关所学有关使用 Jieba 库进行关键词提取的知识,编写使用 Jieba 模块进行关键词提取的程序,并通过所有测试用例。
相关知识
为了完成本关任务,你需要掌握:
-
Jieba 模块的使用;
-
Jieba 提取关键词的方法。
Jieba 关键词提取
jieba 库是一款优秀的 Python 第三方自然语言处理库,在我们的实际开发过程中,jieba 库是我们的好帮手,本实训将介绍 jieba 在关键词提取方面的应用。再利用 jieba 进行关键词提取时,有两种方式,一种是基于 TF-IDF 算法,一种是基于 TextRank 算法。接下来我们具体介绍这两种方式。
基于 TF-IDF 算法的关键词抽取
TF-IDF 算法是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的一份文件的重要程度,即一个词语在一篇文章中出现次数越多,同时在所有文档中出现次数越少,越能够代表该文章。
示例:使用 jieba 中的 TF-IDF
import jieba.analysejieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
函数中各个参数的具体含义为:
-
sentence 为待提取的文本;
-
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为20;
-
withWeight 为是否一并返回关键词权重值,默认值为 False ;
-
allowPOS 仅包括指定词性的词,默认值为空,即不筛选。
在使用 jieba 的 TF-IDF 算法时,需要注意的是,idf 的值是通过语料库统计得到的,所以,实际使用时,可能需要依据使用环境,替换为对应的语料库统计所得 idf 值;需要从分词结果中去除停用词;如果指定了仅提取指定词性的关键词,则词性分割非常重要,词性分割中准确程度,影响关键字的提取。
基于 TextRank 算法的关键词抽取
TextRank 采用图的思想,将文档中的词表示成一张无向有权图,词为图的节点,词之间的联系紧密程度体现为图的边的权值;计算词的权重等价于计算图中节点的权重;提取关键字,等价于找出图中权重排名 TopK 的节点。
示例:使用 jieba 中的 TextRank
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=("ns","n","vn","v")) # 直接使用,接口相同,注意默认过滤词性。jieba.analyse.TextRank() # 新建自定义 TextRank 实例
函数中各个参数的具体含义为:
-
sentence 为待提取的文本;
-
topK 为返回几个 TextRank 权重最大的关键词,默认值为20;
-
withWeight 为是否一并返回关键词权重值,默认值为 False ;
-
allowPOS 仅包括指定词性的词,默认值非空。
其基本思想为:将待抽取关键词的文本进行分词;以固定窗口大小(默认为5,通过 span 属性调整)、词之间的共现关系构建图;计算图中节点的 PageRank ,注意是无向带权图。
编程要求
在右侧编辑器中的 Begin-End 之间补充 Python 代码,使用 jieba 模块对所输入文本进行关键词提取,并输出前三个关键词。其中文本内容通过 input 从后台获取。
测试说明
测试输入: 以上信息提示,武汉疫情快速上升态势得到控制,湖北除武汉外,局部爆发的态势也得到控制,湖北以外省份疫情形势积极向好。下一步要从统筹推进疫情防控和经济社会发展出发,紧紧围绕社区防控和医疗救治两个重点,由全面防控向群专结合,精准防控转变。
预期输出:
Building prefix dict from the default dictionary ...Dumping model to file cache /tmp/jieba.cacheLoading model cost 1.309 seconds.Prefix dict has been built successfully. # 接口调用附加信息疫情 武汉 湖北
import jieba.analyse
import warnings
warnings.filterwarnings("ignore")
sentence = input()# 任务:基于jieba中的TF-IDF算法完成对sentence的关键词提取,提取前三个关键词并以一行输出
# ********** Begin *********#kw = jieba.analyse.extract_tags(sentence,topK=3,withWeight=False,allowPOS=())
ans = ''
for w in kw:ans += w + ' 'print(ans)
# ********** End **********#第2关:TextRank 算法
任务描述
本关任务:根据所学有关 TextRank 算法的知识,完成 TextRank 算法程序的编写并通过所有测试用例。
相关知识
为了完成本关任务,你需要掌握:
-
PageRank 算法的思想;
-
TextRank 算法的步骤与特点。
PageRank 算法
TextRank 算法的基本思想来源于 Google 的 PageRank 算法。因此在介绍TextRank 算法之前,我们先了解一下 PageRank 算法。PageRank 算法主要用于对在线搜索结果中的网页进行排序。让我们通过一个例子快速理解这个算法的基础。
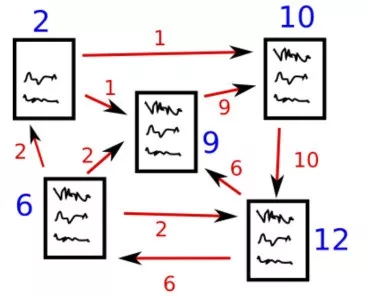
图1
假设我们有4个网页——w1,w2,w3,w4。这些页面包含指向彼此的链接。有些页面可能没有链接,这些页面被称为悬空页面。
| webpage | links |
|---|---|
| w1 | [w4,w2] |
| w2 | [w3,w1] |
| w3 | [ ] |
| w4 | [w1] |
如上表所示,各个网页之间的关系有:
-
w1 有指向 w2、w4 的链接;
-
w2 有指向 w3 和 w1 的链接;
-
w4 仅指向 w1 ;
-
w3 没有指向的链接,因此为悬空页面。
为了对这些页面进行排名,我们必须计算一个称为 PageRank 的分数。这个分数是用户访问该页面的概率。
为了获得用户从一个页面跳转到另一个页面的概率,我们将创建一个正方形矩阵 M,如图2所示,它有 n 行和 n 列,其中 n 是网页的数量。

图 2 正方形矩阵
矩阵中的每个元素表示从一个页面链接进另一个页面的可能性。如图3所示,高亮的方格包含的是从 w1跳转到 w2 的概率。
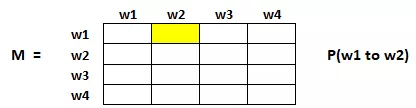
图 3 概率正方形矩阵
如下是概率初始化的步骤:
-
从页面 i 连接到页面 j 的概率,也就是 M[i][j] ,初始化为
1/页面i的出链接总数wi; -
如果页面 i 没有到页面 j 的链接,那么 M[i][j] 初始化为 0 ;
-
如果一个页面是悬空页面,那么假设它链接到其他页面的概率为等可能的,因此 M[i][j] 初始化为
1/页面总数。
因此在本例中,矩阵 M 初始化后如图4所示:
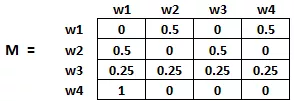
图 4 初始化后的矩阵
最后,这个矩阵中的值将以迭代的方式更新,以获得网页排名。
TextRank 算法
掌握了 PageRank 算法后,让我们理解 TextRank 算法。两种算法的相似之处列举如下:
-
用句子代替网页;
-
任意两个句子的相似性等价于网页转换概率;
-
相似性得分存储在一个方形矩阵中,类似于 PageRank 的矩阵 M 。

图 5 TextRank 算法
TextRank 算法是一种抽取式的无监督的文本摘要方法。其步骤如下:
-
把所有文章整合成文本数据;
-
把文本分割成单个句子;
-
为每个句子找到向量表示(词向量);
-
计算句子向量间的相似性并存放在矩阵中;
-
将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子 TextRank 计算;
-
一定数量的排名最高的句子构成最后的摘要。
编程要求
在右侧编辑器中的 Begin-End 之间补充 Python 代码,实现 TextRank 算法,完成对所输入文本的关键词提取,输出前三个关键词。其中文本内容通过 input 从后台获取。
测试说明
平台将使用测试集运行你编写的程序代码,若全部的运行结果正确,则通关。
测试输入: 在抗击新型冠状病毒的特殊时期,有这样一群人,面对疫情,他们逆向而行,穿梭在辖区的街头巷尾。一只口罩、一双手套,简单的防护措施,就是他们为自己武装的勇气。作为抗击疫情战场上不可或缺的组成部分,社区工作者们用爱筑起了疫情防控的第一道防线。
预期输出:
Building prefix dict from the default dictionary ...Dumping model to file cache /tmp/jieba.cacheLoading model cost 1.259 seconds.Prefix dict has been built successfully.# 接口调用的附加信息疫情 防护 手套
from jieba import analyse
text = input() # 原始文本
# 任务:使用jieba模块中有关TextRank算法的模块完成对text中前三个关键字的提取并输出
# ********** Begin *********#kws = analyse.textrank(text)
ans = ''
i = 0
for w in kws:ans+=w+' 'i+=1if i > 2:breakprint(ans)