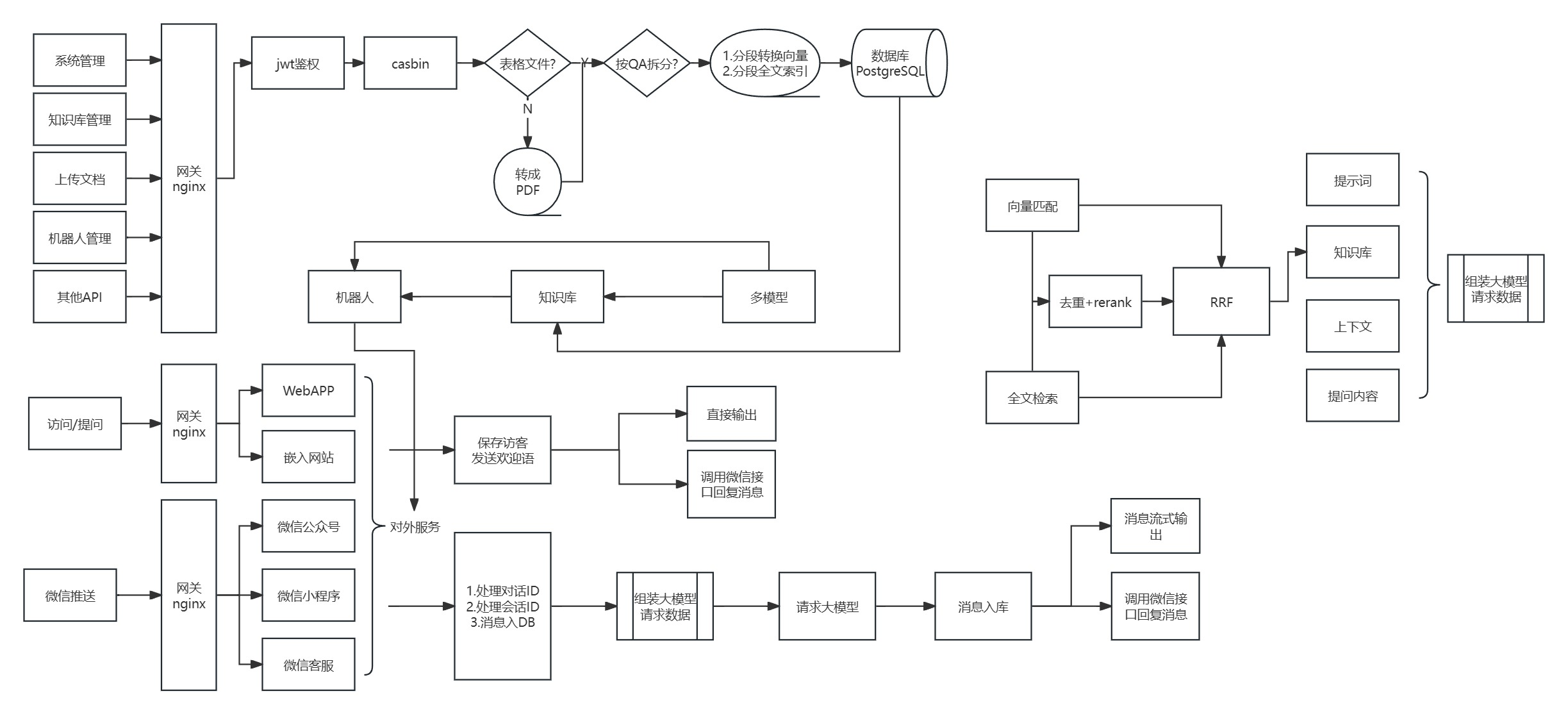
AIM — 图像领域中 LLM 的对应物。尽管 iGPT 已经存在 2 年多了,但自回归尚未得到充分探索。在本文中,作者表明,当使用 AIM 对网络进行预训练时,一组图像数据集上的下游任务的平均准确率会随着数据和参数的增加而线性增加。
要运行下面的代码,请使用我的 Jupyter 笔记本
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
AIM 引入了两个概念:
- 对于预训练:AIM 引入了一种称为 PrefixLM 的东西,它允许在下游任务期间进行双向 attn 并进行预训练而无需改变架构。
- 对于下游:Attentive Probing
在这篇博客中,我们将了解自注意力中的 Casual Masking 是什么,然后看看 PrefixLM 是如何设计的。
在阅读这篇博客之前,我强烈建议你先观看这个 nanoGPT 视频教程 。
让我们先加载所需的库。
import math
import numpy as np
import torch
import torch.nn as nn
import fastcore.all as fc
from PIL import Image
from functools import partial
from torchvision.transforms import RandomResizedCrop, RandomHorizontalFlip, Compose, ToTensor, ToPILImageimport matplotlib.pyplot as plt
plt.style.use("bmh")
%matplotlib inline让我们创建一个大小为 224x224 的图像,其中补丁大小为 32
img_size = 224
patch_size = 321、加载并可视化图像
我们加载并使用 coco val 数据。为了这个博客的目的,你可以从互联网上挑选任何图像。
imgs = fc.L(fc.Path("../coco/val2017/").glob("*.jpg"))
imgs(#5000) [Path('../coco/val2017/000000182611.jpg'),Path('../coco/val2017/000000335177.jpg'),Path('../coco/val2017/000000278705.jpg'),Path('../coco/val2017/000000463618.jpg'),Path('../coco/val2017/000000568981.jpg'),Path('../coco/val2017/000000092416.jpg'),Path('../coco/val2017/000000173830.jpg'),Path('../coco/val2017/000000476215.jpg'),Path('../coco/val2017/000000479126.jpg'),Path('../coco/val2017/000000570664.jpg')...]以下是论文中提到的标准变换:
def transforms():return Compose([RandomResizedCrop(size=224, scale=[0.4, 1], ratio=[0.75, 1.33], interpolation=2), RandomHorizontalFlip(p=0.5), ToTensor()])def load_img(img_loc, transforms):img = Image.open(img_loc)return transforms(img)load_img = partial(load_img, transforms=transforms())img = load_img(imgs[1])
img.shape #torch.Size([3, 224, 224])
coco val image
2、如何设置用于自动回归的输入数据?
图像被分割成 K 个不重叠的块网格,这些块共同形成一个标记序列。由于图像大小为 (224, 224),块大小为 (32, 32),我们将获得总共 7x7 =49 个块。
imgp = img.unfold(1, patch_size, patch_size).unfold(2, patch_size, patch_size).permute((0, 3, 4, 1, 2)).flatten(3).permute((3, 0, 1, 2))
imgp.shape #torch.Size([49, 3, 32, 32])fig, ax = plt.subplots(figsize=(4, 4), nrows=7, ncols=7)
for n, i in enumerate(imgp):ax.flat[n].imshow(ToPILImage()(i))ax.flat[n].axis("off")
plt.show()
image to tokens
自回归的设置方式如下:
- 对于 token 1 -> token 2 是预测
- 对于 token 1, 2 -> token 3 是预测
- 对于 token 1, 2, 3 -> token 4 是预测
- 对于 token 1, 2, 3, … n-1 -> token n 是预测。
因此输入 token 将达到 [0, n-1],输出 token 将达到 [1, n]
x = imgp[:-1]
y = imgp[1:]
x.shape, y.shape
#(torch.Size([48, 3, 32, 32]), torch.Size([48, 3, 32, 32]))例如,如果我们有 [0, 24] 以内的标记,则第 25 个标记是预测。在下图中,RGB 图像是输入标记,用红色边框突出显示的标记是该组输入标记的预测标记。
prediction = 25
fig, ax = plt.subplots(figsize=(4, 4), nrows=7, ncols=7)
for n, i in enumerate(imgp):token = ToPILImage()(i)if n <prediction:ax.flat[n].imshow(token)elif n == prediction:new_size = (48, 48)new_im=np.zeros((48, 48, 3))new_im[:, :, 0] = 255new_im = Image.fromarray(np.uint8(new_im))box = tuple((n - o) // 2 for n, o in zip(new_size, token.size))new_im.paste(token, box)ax.flat[n].imshow(new_im, cmap="hsv")else:ax.flat[n].imshow(token.convert("L"), cmap="gray")ax.flat[n].axis("off")
plt.show()
前 N 个token和 GT token
3、如何将自注意力应用于输入token
注意力不过是两个矩阵之间的余弦相似度。但是在进行token级别预测时,网络应该只看到那些到那时为止的标记,而不是那些之后的标记。例如,对于标记 25 的预测,我们应该只使用从 1 到 24 的标记,并丢弃从 26 到 49 的标记(在我们采用的示例中,我们有 49 个标记)。接下来我们将看看如何实现这一点。
在上面,我们得到 x 形状为 (48, 3, 32, 32),y 形状为 (48, 3, 32, 32)。y 是我们需要的输出或基本事实,但我们将直接使用 PatchEmbed 将原始图像转换为标记,然后丢弃最终的标记。
首先执行 pip install git+https://git@github.com/apple/ml-aim.git 并导入必要的函数。
from aim.torch.layers import PatchEmbed, LayerNorm, SinCosPosEmbed, MLPpe = PatchEmbed(img_size=img_size, patch_size=patch_size, norm_layer=LayerNorm)
pePatchEmbed((proj): Conv2d(3, 768, kernel_size=(32, 32), stride=(32, 32))(norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
)tokens = pe(img.unsqueeze(0))
tokens.shape #torch.Size([1, 49, 768])在 AIM 中,他们没有使用类token。我们将添加 sincos 位置嵌入
scpe = SinCosPosEmbed(cls_token=False)pe = scpe(h=7, w=7, embed_dim=768)
pe.shape #torch.Size([49, 768])将这些位置嵌入添加到输入token中
tokens = tokens+pe[None]
tokens.shape #torch.Size([1, 49, 768])我们现在将删除最后一个标记,因为它没有任何 Gt
tokens = tokens[:, :48, :]
tokens.shape #torch.Size([1, 48, 768])4、自注意力
Transformer 块内会发生很多事情。但简单来说,我们首先
- 规范化输入
- 应用注意
- 应用 MLP
4.1 规范化
在 transformer 块中,我们需要层规范化。层规范化通常在 token 级别完成,因此 token 之间没有信息交换。
token_norms = LayerNorm(768)(tokens)
token_norms.mean((0, 2)),token_norms.var((0, 2))(tensor([ 0.0000e+00, -1.7385e-08, -2.1110e-08, -2.4835e-09, 1.8626e-09,1.2418e-09, 3.7253e-08, 2.3594e-08, 1.0555e-08, -9.9341e-09,1.2418e-08, -2.0800e-08, 1.9247e-08, -1.1797e-08, 6.7055e-08,1.1176e-08, 3.6632e-08, -3.6632e-08, -5.2465e-08, -2.4835e-08,-1.0245e-08, -1.5212e-08, 1.7385e-08, -3.3528e-08, -2.1110e-08,-2.2352e-08, 1.3039e-08, 1.8626e-08, -6.5193e-09, -2.7319e-08,-1.4280e-08, 2.1110e-08, -1.5522e-08, 3.1044e-09, 2.2041e-08,-9.3132e-10, 9.3132e-09, -2.8871e-08, -1.8626e-08, 3.1044e-09,2.6077e-08, 1.4901e-08, 1.1797e-08, -8.0715e-09, 4.8429e-08,-1.5522e-09, -4.1910e-08, -1.8316e-08], grad_fn=<MeanBackward1>),tensor([1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013,1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013,1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013,1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013,1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013, 1.0013,1.0013, 1.0013, 1.0013], grad_fn=<VarBackward0>))4.2 MLP
在 MLP 中,每个 token [行] 也与 MLP 权重矩阵的每个 [列] 相乘。因此 token 之间没有交互,这实际上意味着我们可以使用该网络分别处理每个 token
mlp = MLP(in_features=768,hidden_features=768*4,act_layer=nn.GELU,drop=0.2,use_bias=False
)
mlpMLP((fc1): Linear(in_features=768, out_features=3072, bias=False)(act): GELU(approximate='none')(fc2): Linear(in_features=3072, out_features=768, bias=False)(drop): Dropout(p=0.2, inplace=False)
)mlp(token_norms).shape #torch.Size([1, 48, 768])4.3 因果注意力
注意力是我们使用查询、键和值计算标记之间交互的唯一地方。但对于自回归,过去的token不应该从未来学习。例如,如果我们预测token 5,我们应该只使用token 1、2、3、4 并丢弃来自 5 的所有token。在 Transformers 中,这是使用一种称为因果注意力的东西实现的。我们将在本节中学习和理解它是什么。为了简化理解,我们将只使用单个头,而不是使用多个头。
在注意力中,发生以下步骤
- 使用 mlp,获取键、查询和值。
- 在查询和键之间应用自注意力(本质上是点积)。我们得到一个 qk 矩阵(49x49)。缩放值
- 应用 softmax
- qk 和 v 之间的自注意力。
# lets see a single head perform self-attention
B, T, C = token_norms.shape
head_size = 768
key = nn.Linear(C, head_size, bias=False)
query = nn.Linear(C, head_size, bias=False)
value = nn.Linear(C, head_size, bias=False)
k = key(token_norms)
q = query(token_norms)
v = value(token_norms)
scale_factor = 1 / math.sqrt(q.size(-1))
qk = q@k.transpose(-2, -1) * scale_factor #(B, T, 16) @ (B, 16, T) --. B, T, T
qk.shape #torch.Size([1, 48, 48])这个矩阵本质上会告诉你每个 token 之间的相互作用强度。
值会汇总来自所有其他 token 的每个 token 的信息。qk 的行 1 与值的所有列相乘,但 token1 应该只包含来自 token1 的信息,并丢弃所有其他信息。类似地,token2 应该只包含来自 token1 和 token2 的 qk 值,并丢弃所有其他值。如果你按照这个思路操作,我们理想情况下希望从矩阵的上三角中删除所有值。
在注意力论文中,他们不是删除,而是用 -inf 替换它。这是因为当应用 softmax 时,这些极小的值将变为零,因此不会产生任何影响。
tril = torch.tril(torch.ones(T,T))
plt.figure(figsize=(4, 4))
plt.imshow(tril.numpy())
plt.show()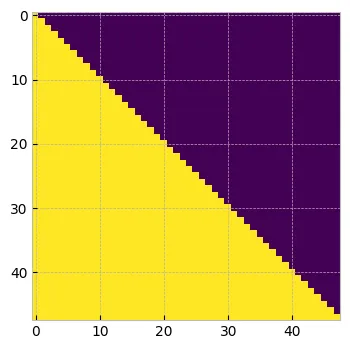
因果掩码
qk = qk.masked_fill(tril==0, float("-inf"))
qk[0]tensor([[0.3354, -inf, -inf, ..., -inf, -inf, -inf],[0.3412, 0.3489, -inf, ..., -inf, -inf, -inf],[0.3663, 0.3698, 0.3422, ..., -inf, -inf, -inf],...,[0.9337, 0.9750, 0.9633, ..., 0.8890, -inf, -inf],[0.8462, 0.8887, 0.8814, ..., 0.8392, 0.7537, -inf],[0.6571, 0.6705, 0.6382, ..., 0.5844, 0.5688, 0.6007]],grad_fn=<SelectBackward0>)qk = torch.softmax(qk, dim=-1)
qk[0]tensor([[1.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.4981, 0.5019, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.3356, 0.3368, 0.3276, ..., 0.0000, 0.0000, 0.0000],...,[0.0216, 0.0225, 0.0222, ..., 0.0206, 0.0000, 0.0000],[0.0211, 0.0220, 0.0219, ..., 0.0210, 0.0192, 0.0000],[0.0211, 0.0214, 0.0207, ..., 0.0196, 0.0193, 0.0199]],grad_fn=<SelectBackward0>)plt.figure(figsize=(4, 4))
plt.imshow(qk.detach().numpy()[0])
plt.show()
使用因果掩码的注意力矩阵
现在,当我们用值进行相乘时,只有到那时为止的token才会共享信息。
attn = qk@v
attn.shape #torch.Size([1, 48, 768])这个注意力通过线性和 dropout 层传播。
proj = nn.Linear(768, 768, bias=False)
tokens = proj(attn)
tokens.shape #torch.Size([1, 48, 768])Transformers 内部有一些跳跃连接和其他 MLP 块用于稳定训练,但这本质上是 Transformer 块中发生的事情
5、PrefixLM
从上面我们可以看出,在自回归预训练时,我们应用了因果掩码,而在微调时,如果我们删除因果掩码,我们正在进行双向自我注意。这种差异导致微调时的性能低于标准。
为了解决这个问题,论文中的作者建议将序列的初始标记(称为前缀)视为预测剩余补丁的上下文。因此,对初始 K 个标记应用双向自我注意,并且不考虑对这些标记的预测。对于剩余的标记,我们将执行如上所述的因果掩码。让我们看看这是如何做到的。
假设我们考虑 k=25。我们将获得 N 个补丁的掩码
K = 25
mask = torch.ones(B, tokens.shape[1]).to(torch.bool)
mask[:, :K] = 0
print(mask.shape) #torch.Size([1, 48])
masktensor([[False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True]])prefix_mask = (~mask).unsqueeze(1).expand(-1, tokens.shape[1], -1).bool()
print(prefix_mask.shape)
prefix_mask[0] #torch.Size([1, 48, 48])tensor([[ True, True, True, ..., False, False, False],[ True, True, True, ..., False, False, False],[ True, True, True, ..., False, False, False],...,[ True, True, True, ..., False, False, False],[ True, True, True, ..., False, False, False],[ True, True, True, ..., False, False, False]])plt.figure(figsize=(4, 4))
plt.imshow(prefix_mask.numpy()[0])
plt.show()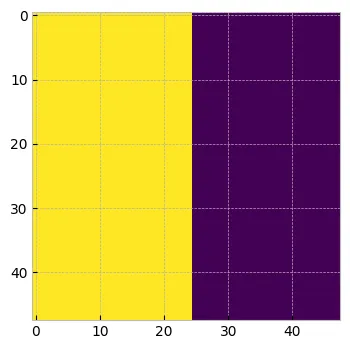
PrefixLM
我们现在将定义 attn_mask,其上限训练值为零
attn_mask = torch.ones(1, tokens.shape[1], tokens.shape[1], dtype=torch.bool).tril(diagonal=0)
print(attn_mask.shape) #torch.Size([1, 48, 48])
plt.figure(figsize=(4, 4))
plt.imshow(attn_mask.numpy()[0])
plt.show()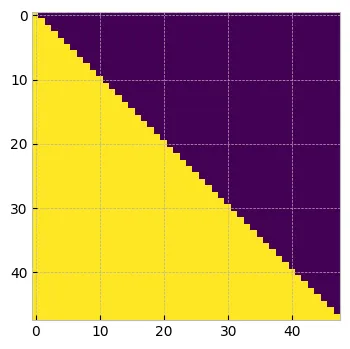
attn_mask = torch.logical_or(attn_mask, prefix_mask)
print(attn_mask.shape) #torch.Size([1, 48, 48])
plt.figure(figsize=(4, 4))
plt.imshow(attn_mask.numpy()[0])
plt.show()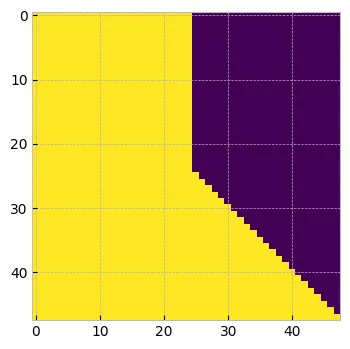
最终的因果掩码
上述 attn_mask 将确保对于前 25 个标记我们将进行双向自注意,并且对于剩余的标记应用 causual_masking。
qk = qk.masked_fill(attn_mask==0, float("-inf"))
print(qk.shape) #torch.Size([1, 48, 48])
qk[0]tensor([[1.0000, 0.0000, 0.0000, ..., -inf, -inf, -inf],[0.4981, 0.5019, 0.0000, ..., -inf, -inf, -inf],[0.3356, 0.3368, 0.3276, ..., -inf, -inf, -inf],...,[0.0216, 0.0225, 0.0222, ..., 0.0206, -inf, -inf],[0.0211, 0.0220, 0.0219, ..., 0.0210, 0.0192, -inf],[0.0211, 0.0214, 0.0207, ..., 0.0196, 0.0193, 0.0199]],grad_fn=<SelectBackward0>)qk = torch.softmax(qk, dim=-1)
qk[0]tensor([[0.1017, 0.0374, 0.0374, ..., 0.0000, 0.0000, 0.0000],[0.0626, 0.0628, 0.0380, ..., 0.0000, 0.0000, 0.0000],[0.0534, 0.0535, 0.0530, ..., 0.0000, 0.0000, 0.0000],...,[0.0217, 0.0218, 0.0217, ..., 0.0217, 0.0000, 0.0000],[0.0213, 0.0213, 0.0213, ..., 0.0213, 0.0212, 0.0000],[0.0208, 0.0208, 0.0208, ..., 0.0208, 0.0208, 0.0208]],grad_fn=<SelectBackward0>)plt.figure(figsize=(4, 4))
plt.imshow(qk.detach().numpy()[0])
plt.show()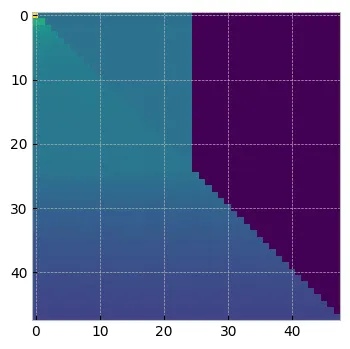
使用 PrefixLM 的最终 attn 矩阵
attn = qk@vtensor([[ 0.9102, 0.2899, -0.4562, ..., -0.0554, 0.2982, 1.4015],[ 0.9125, 0.2941, -0.4578, ..., -0.0558, 0.2949, 1.4056],[ 0.9135, 0.2954, -0.4594, ..., -0.0551, 0.2924, 1.4080],...,[ 0.8787, 0.3149, -0.5150, ..., -0.0829, 0.1735, 1.3375],[ 0.8820, 0.3152, -0.5220, ..., -0.0798, 0.1744, 1.3371],[ 0.8860, 0.3186, -0.5214, ..., -0.0759, 0.1729, 1.3319]],grad_fn=<SelectBackward0>)在 AIM 的背景下,他们没有提到要使用什么 K 值。但我正在考虑我们可以在每次迭代中选择一个随机数。
在下一篇博客中,我们将看到如何使用 CIFAR 数据对 AIM 进行预训练。
原文链接:AIM注意力和因果掩码 - BimAnt