一、引言
Xinference,也称为Xorbits Inference,是一个性能强大且功能全面的分布式推理框架,专为各种模型的推理而设计。无论是研究者、开发者还是数据科学家,都可以通过Xinference轻松部署自己的模型或内置的前沿开源模型。Xinference的特点包括部署快捷、使用简单、推理高效,并支持多种形式的开源模型。此外,Xinference还提供了WebGUI界面和API接口,方便用户进行模型部署和推理。

二、部署前准备
Xinference官方说明
1. 硬件要求:
- 确保服务器或本地机器具有足够的计算资源,包括CPU、GPU和内存。
- 确保网络连接稳定,以便从远程仓库下载模型和依赖项。
2. 软件要求:
- 安装Python 3.10版本(建议)。虽然Xinference可能支持其他Python版本,但3.10版本已被广泛测试并推荐使用。
- 安装conda,用于创建和管理Python环境。
- Ubuntu系统下,可以不用安装conda。
三、部署步骤
1. 创建Python环境
- 使用conda创建一个名为Xinference的Python 3.10环境。这有助于隔离项目依赖项,避免与其他项目冲突。
conda create -n Xinference python=3.10
conda activate Xinference
2. 安装依赖项
- 在Xinference环境中安装必要的依赖项,包括chatglm和pytorch等。注意,由于某些依赖项可能与Python 3.11版本不兼容,因此建议使用Python 3.10。
- 对于chatglm,你可以从官方渠道下载相应的wheel文件(如chatglm_cpp-0.3.1-cp310-cp310-win_amd64.whl),并使用pip进行安装。
pip install chatglm_cpp-0.3.1-cp310-cp310-win_amd64.whl
- 对于pytorch,确保安装与你的GPU兼容的版本。你可以从PyTorch官方网站下载预构建的wheel文件或使用pip命令进行安装。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
- 检查CUDA版本的Pytorch是否安装成功:
python -c "import torch; print(torch.cuda.is_available())"
如果输出为True,则表示CUDA版本的Pytorch已成功安装。
3. 安装Xinference
- 使用pip安装Xinference及其所有依赖项。请注意,安装过程可能需要一些时间,具体取决于你的网络连接速度和计算机性能。
pip install "xinference[all]"
4. 启动Xinference服务
- 在本地或服务器上启动Xinference服务。你可以使用命令行工具或Web UI界面来启动和管理模型。
- 命令行启动示例:
xinference-local -H 0.0.0.0
这将在本地启动Xinference服务,并允许非本地客户端通过机器的IP地址访问。
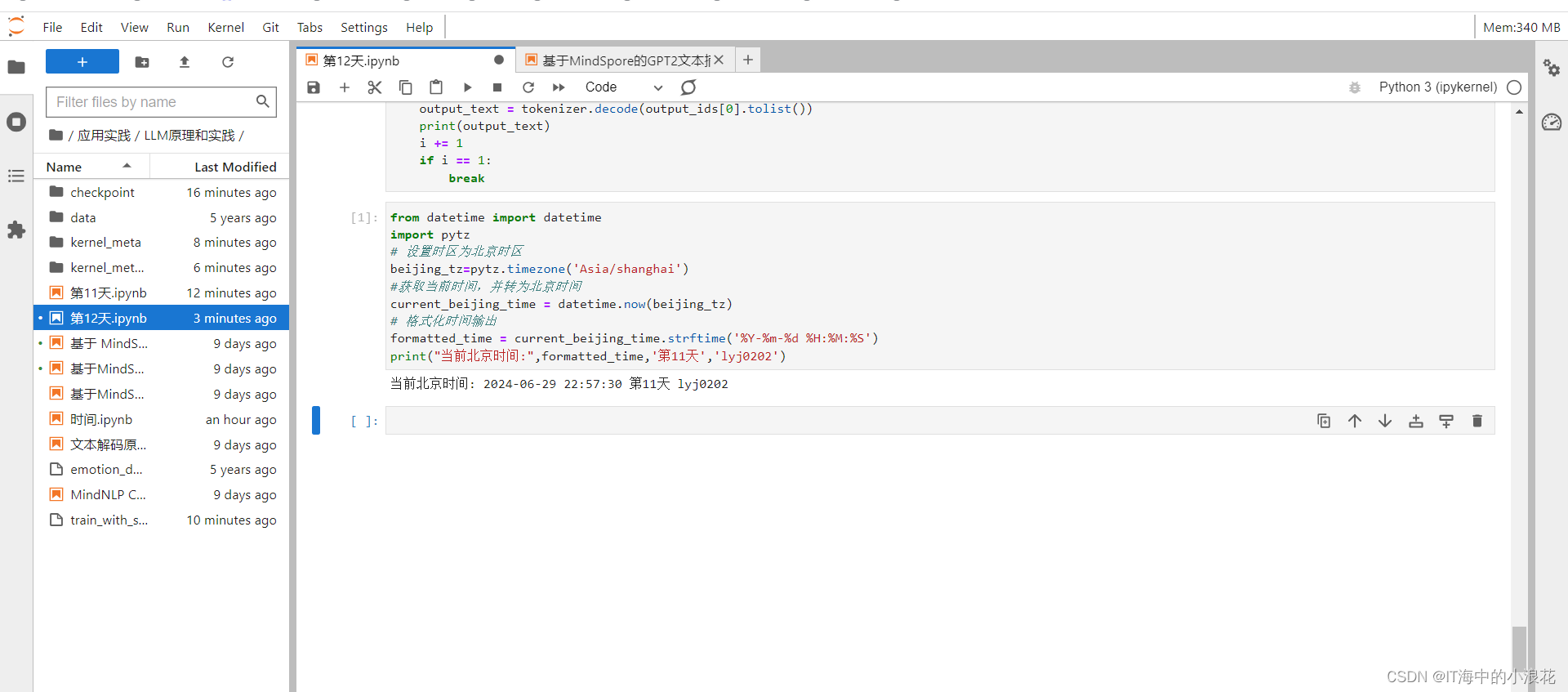
- Web UI启动:在浏览器中访问http://localhost:9997(或相应的IP地址和端口),你将看到Xinference的Web UI界面。你可以在此界面中搜索和管理模型。
5. 部署模型
- 使用Xinference的Web UI界面或命令行工具来部署模型。你可以选择已内置的开源模型或上传自己的模型文件。
- 在Web UI界面中,你可以搜索模型、选择相关参数,并点击模型卡片上的按钮来启动模型。
- 在命令行工具中,你可以使用类似xinference launch -u my_model -n my_model_name -s 14 -f pytorch的命令来启动模型。这里的参数可以根据你的需求进行调整。
6. 使用Xinference
- 一旦模型被成功部署到Xinference中,你就可以通过Web UI界面、API接口或Python SDK来与模型进行交互了。
- 你可以使用Xinference提供的API接口来发送请求并获取模型的推理结果。这可以通过RESTful API、GraphQL或其他协议来实现。
- 你还可以使用Xinference的Python SDK来更方便地集成模型到你的项目中。通过SDK,你可以轻松地将模型推理功能添加到你的应用程序或服务中。
四、部署后的优化与扩展
1. 性能优化
- GPU加速:如果你已经安装了CUDA和与GPU兼容的PyTorch版本,Xinference将自动利用GPU进行模型推理,以加速计算过程。你可以通过监控GPU使用情况来确保模型正在充分利用GPU资源。
- 分布式部署:对于大型模型或高并发场景,你可以考虑使用Xinference的分布式部署功能。这允许你在多个设备或机器间高效分配模型推理任务,提高整体性能和吞吐量。
- 模型压缩与量化:通过模型压缩和量化技术,你可以减小模型的大小并提高推理速度。这通常涉及对模型进行微调或优化,以牺牲一定的精度为代价换取更高的性能。
2. 扩展功能
- 集成第三方工具:Xinference集成了多个第三方开发者工具,如LangChain、LlamaIndex和Dify.AI等。这些工具可以帮助你更方便地进行模型集成、开发和应用。
- 支持多种模型格式:Xinference支持多种模型格式,包括Hugging Face的Transformers、vLLM和GGML等。这使得你可以轻松地将各种模型部署到Xinference中,而无需进行繁琐的格式转换。
- 扩展API接口:除了提供与OpenAI API兼容的RESTful API外,Xinference还支持其他协议和接口,如GraphQL和gRPC等。这使得你可以根据自己的需求选择合适的接口与模型进行交互。
3. 监控与日志
- 实时监控:使用GreptimeAI等监控工具,你可以实时了解Xinference服务的运行状态、性能指标和安全性情况。这有助于你及时发现并解决潜在问题,确保服务的稳定性和可靠性。
- 日志记录:Xinference提供了详细的日志记录功能,包括请求日志、错误日志和性能指标日志等。通过查看和分析这些日志,你可以深入了解服务的运行情况和性能瓶颈,为优化和扩展提供依据。
4. 安全性与权限管理
- 访问控制:通过设置访问控制策略,你可以限制对Xinference服务的访问权限,确保只有授权用户才能访问和使用服务。
- 加密传输:通过启用HTTPS和TLS/SSL加密传输,你可以保护在传输过程中的数据安全性,防止数据泄露和篡改。
5. 自定义与扩展
- 自定义镜像:你可以根据自己的需求构建自定义的Xinference Docker镜像,包括安装特定的依赖项、配置环境变量等。这有助于你更灵活地部署和管理Xinference服务。
- 扩展API接口:如果你需要实现自定义的API接口或扩展现有接口的功能,你可以使用Xinference提供的Python SDK或RESTful API接口进行开发。这允许你根据自己的业务需求定制服务的功能和性能。

![[OtterCTF 2018]Graphic‘s For The Weak](https://img-blog.csdnimg.cn/img_convert/c0a13197becf2dd5b17b407afdd28634.png)