目录
一、编程环境-使用jupyter notebook
1.下载homebrew包管理工具
2.安装Python环境
3.安装jupyter
4.下载Anaconda使用conda
5.使用conda设置虚拟环境
二、学习Python基础
1.快排的Python实现
(1)列表推导-一种创建列表的简洁方式
(2)列表相加
2.基本数据类型及运算符操作
(1)整数与浮点数
(2)逻辑运算
(3)字符串
3.容器
(1)列表
①切片
②遍历list
(2)字典
①遍历字典
②使用列表推导式很方便地构造字典
(3)集合Set
①遍历集合
②构建集合
(4)元组
4.函数
5.类class
三、学习Numpy
1.Arrays
(1)访问元素
(2)创建arrays
(3)切片
(4)混合使用整型索引和切片索引
(5)使用子数组视图构建新数组
(6)boolean数组索引
2.数据类型
3.向量的数学运算
(1)逐元素基本运算
(2)向量内积、向量与矩阵、矩阵与矩阵乘积
(3)sum函数
(4)矩阵转置
(5)广播Broadcasting
(6)广播的一些应用
四、学习Scipy
1.图像操作
2.数学运算:欧几里得距离
五、学习Matplotlib
1.Plotting绘制二维图
2.Subplots 绘制子图
(1)Subplots同一幅图绘制不同图形
(2)对图片进行绘制,横纵坐标范围根据像素设置
六、总结
一、编程环境-使用jupyter notebook
MAC系统安装教程:https://wenku.csdn.net/column/and2yb9ip2
1.下载homebrew包管理工具
(教程中的安装命令可能会出现连接错误,可以使用下面的命令):
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"2.安装Python环境
brew install python3
3.安装jupyter
pip3 install jupyter设置环境变量:
【Mac】终端使用pip3 install jupyter命令安装jupyter noteboo时,提示zsh: command not found: jupyter-CSDN博客文章浏览阅读1.6k次。解决办法:1、找到jupyter的安装位置pip3 show jupyter根据location可以找到jupyter的位置/Users/wangyajing/Library/Python/3.8/bin2、vim编写vim ~/.zshrc export PATH=/Users/wangyajing/Library/Python/3.8/bin/:$PATH结束后输入:wq并回车退出编辑3、载入命令并启动jupyter notebooksource .zshrcjupyte.._command not found: jupyterhttps://blog.csdn.net/qq_35443700/article/details/122645657
安装效果:
mac终端配置环境变量,如果只是配置 .bash_profile 的话环境变量只对当前终端会话有效,可以配置 .zshrc 文件,可以参考下面:
Mac终端配置环境变量(Mac、Linux操作系统通用)_mac zshrc 环境变量配置-CSDN博客文章浏览阅读5k次,点赞5次,收藏14次。关于终端环境变量设置_mac zshrc 环境变量配置https://blog.csdn.net/StoryZX/article/details/118684079
4.下载Anaconda使用conda
为了更好的使用jupyter notebook,将环境资源隔离,可以下载Anaconda使用conda:
Download Anaconda Distribution | Anaconda
下载安装完成后,软件会把环境变量自动写入系统文件
这样我们就可以使用conda,实现包的安装管理和环境资源管理了。
5.使用conda设置虚拟环境
这样可以根据需要去下载依赖包,避免冲突,在这门课创建虚拟环境 cs231n
conda create -n cs231n
source activate cs231n
//下载python3.8,官网推荐的版本3.7下不到
conda install python=3.8运行虚拟环境
source activate cs231n安装numpy等包
pip install numpy
pip install matplotlib二、学习Python基础
之前对Python的基础语法进行了总结:
Python常用语法看这些就够了(上篇)_截取 当第三个参数为负数时-CSDN博客文章浏览阅读792次,点赞13次,收藏65次。参考教程:菜鸟教程https://www.runoob.com/python3/python3-tutorial.html使用的开发工具是Jupyter Notebook(Anaconda)下面我主要是介绍一些需要注意的点和练习过程:说在前面:动手很重要一、python基本语法1.标识符规则:在 Python 里,标识符由字母、数字、下划线组成。在 Python 中..._截取 当第三个参数为负数时
https://blog.csdn.net/hehe_soft_engineer/article/details/102821470Python常用语法看这些就够了(下篇)_用format求立方-CSDN博客文章浏览阅读1.5k次,点赞11次,收藏75次。Python常用语法看这些就够了(下篇)九、Python 模块(Module)模块是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。模块让你能够有逻辑地组织你的 Python 代码段。1.import语句引入模块导入方式:import模块名在使用模块内的函数时,需要使用模块名.函数名 的方式调用例:一个..._用format求立方
1.快排的Python实现
这里通过一个例子来入门解析一下Python的语法
def quicksort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quicksort(left) + middle + quicksort(right)print(quicksort([3,6,8,10,1,2,1]))
# Prints "[1, 1, 2, 3, 6, 8, 10]"(1)列表推导-一种创建列表的简洁方式
在Python中,[x for x in arr if x < pivot] 是一个列表推导(list comprehension)的示例。列表推导是一种创建列表的简洁方式,它从一个或多个迭代器(如列表、元组、集合、字典等)中构建列表。
这里的列表推导做了以下几件事:
①for x in arr:对于arr中的每一个元素x。
②if x < pivot:检查元素x是否小于pivot。
③如果x小于pivot,则x会被添加到新列表中。
left变量将存储这个新列表,其中包含所有小于pivot的arr中的元素。
举一个简单的例子来解释这个列表推导:
arr = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
pivot = 3
left = [x for x in arr if x < pivot]
print(left) # 输出: [1, 1, 2](2)列表相加
list1 = [1, 2, 3]
list2 = [4, 5, 6]
# 使用加号操作符相加两个列表
list3 = list1 + list2
print(list3) # 输出: [1, 2, 3, 4, 5, 6]注意,这种方法会创建一个新的列表,而不会修改原始的 list1 或 list2。如果你想要修改一个列表并添加另一个列表的所有元素,你可以使用 extend() 方法:
list1 = [1, 2, 3]
list2 = [4, 5, 6]# 使用 extend() 方法将 list2 的元素添加到 list1 中
list1.extend(list2)print(list1) # 输出: [1, 2, 3, 4, 5, 6]
print(list2) # 输出: [4, 5, 6](list2 没有改变)在这个例子中,extend() 方法将 list2 的所有元素添加到了 list1 的末尾,而不会创建一个新的列表。
2.基本数据类型及运算符操作
与大多数语言一样,Python有许多基本类型,包括整数、浮点数、布尔值和字符串。这些数据类型的行为方式与其他编程语言相似。
(1)整数与浮点数
注意:与许多语言不同,Python没有一元递增(x++)或递减(x--)操作符。
Python也有处理复数的内置类型:
x = 3
print(type(x)) # Prints "<class 'int'>"
print(x) # Prints "3"
print(x + 1) # Addition; prints "4"
print(x - 1) # Subtraction; prints "2"
print(x * 2) # Multiplication; prints "6"
print(x ** 2) # Exponentiation; prints "9"
x += 1
print(x) # Prints "4"
x *= 2
print(x) # Prints "8"
y = 2.5
print(type(y)) # Prints "<class 'float'>"
print(y, y + 1, y * 2, y ** 2) # Prints "2.5 3.5 5.0 6.25"
更多方法与细节:
https://docs.python.org/3.8/library/stdtypes.html#numeric-types-int-float-complex
(2)逻辑运算
Python实现了布尔逻辑的所有常见操作符,但使用了英语单词而不是符号(&&,||等)
t = True
f = False
print(type(t)) # Prints "<class 'bool'>"
print(t and f) # Logical AND; prints "False"
print(t or f) # Logical OR; prints "True"
print(not t) # Logical NOT; prints "False"
print(t != f) # Logical XOR; prints "True"
(3)字符串
hello = 'hello' # String literals can use single quotes
world = "world" # or double quotes; it does not matter.
print(hello) # Prints "hello"
print(len(hello)) # String length; prints "5"
hw = hello + ' ' + world # String concatenation
print(hw) # prints "hello world"
hw12 = '%s %s %d' % (hello, world, 12) # sprintf style string formatting
print(hw12) # prints "hello world 12"
字符串常用函数
s = "hello"
print(s.capitalize()) # Capitalize a string; prints "Hello"
print(s.upper()) # Convert a string to uppercase; prints "HELLO"
print(s.rjust(7)) # Right-justify a string, padding with spaces; prints " hello"
print(s.center(7)) # Center a string, padding with spaces; prints " hello "
print(s.replace('l', '(ell)')) # Replace all instances of one substring with another;# prints "he(ell)(ell)o"
print(' world '.strip()) # Strip leading and trailing whitespace; prints "world"
更多方法:
Built-in Types — Python 3.8.19 documentation
3.容器
Python包含几个内置的容器类型:列表、字典、集合和元组。
(1)列表
在Python中,列表相当于数组,但可以重新调整大小,包含不同类型的元素:
xs = [3, 1, 2] # Create a list
print(xs, xs[2]) # Prints "[3, 1, 2] 2"
print(xs[-1]) # Negative indices count from the end of the list; prints "2"
xs[2] = 'foo' # Lists can contain elements of different types
print(xs) # Prints "[3, 1, 'foo']"
xs.append('bar') # Add a new element to the end of the list
print(xs) # Prints "[3, 1, 'foo', 'bar']"
x = xs.pop() # Remove and return the last element of the list
print(x, xs) # Prints "bar [3, 1, 'foo']"
更多方法及细节:
5. Data Structures — Python 3.8.19 documentation![]() https://docs.python.org/3.8/tutorial/datastructures.html#more-on-lists
https://docs.python.org/3.8/tutorial/datastructures.html#more-on-lists
①切片
除了每次访问一个链表元素外,Python还提供了访问子链表的简洁语法;这就是所谓的切片:
nums = list(range(5)) # range is a built-in function that creates a list of integers
print(nums) # Prints "[0, 1, 2, 3, 4]"
print(nums[2:4]) # Get a slice from index 2 to 4 (exclusive); prints "[2, 3]"
print(nums[2:]) # Get a slice from index 2 to the end; prints "[2, 3, 4]"
print(nums[:2]) # Get a slice from the start to index 2 (exclusive); prints "[0, 1]"
print(nums[:]) # Get a slice of the whole list; prints "[0, 1, 2, 3, 4]"
print(nums[:-1]) # Slice indices can be negative; prints "[0, 1, 2, 3]"
nums[2:4] = [8, 9] # Assign a new sublist to a slice
print(nums) # Prints "[0, 1, 8, 9, 4]"
②遍历list
animals = ['cat', 'dog', 'monkey']
for animal in animals:print(animal)
# Prints "cat", "dog", "monkey", each on its own line.使用enumerate内置函数,将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
animals = ['cat', 'dog', 'monkey']
for idx, animal in enumerate(animals):print('#%d: %s' % (idx + 1, animal))
# Prints "#1: cat", "#2: dog", "#3: monkey", each on its own line使用列表推导式完成对列表数据的处理,产生新的列表
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares) # Prints [0, 1, 4, 9, 16]列表推导式也可以包含条件筛选
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print(even_squares) # Prints "[0, 4, 16]"
(2)字典
字典存储(键、值)对,类似于Java中的Map或Javascript中的对象。你可以像这样使用它:
d = {'cat': 'cute', 'dog': 'furry'} # Create a new dictionary with some data
print(d['cat']) # Get an entry from a dictionary; prints "cute"
print('cat' in d) # Check if a dictionary has a given key; prints "True"
d['fish'] = 'wet' # Set an entry in a dictionary
print(d['fish']) # Prints "wet"
# print(d['monkey']) # KeyError: 'monkey' not a key of d
print(d.get('monkey', 'N/A')) # Get an element with a default; prints "N/A"
print(d.get('fish', 'N/A')) # Get an element with a default; prints "wet"
del d['fish'] # Remove an element from a dictionary
print(d.get('fish', 'N/A')) # "fish" is no longer a key; prints "N/A"
更多字典相关方法和细节:
Built-in Types — Python 3.8.19 documentation![]() https://docs.python.org/3.8/library/stdtypes.html#dict
https://docs.python.org/3.8/library/stdtypes.html#dict
①遍历字典
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:legs = d[animal]print('A %s has %d legs' % (animal, legs))
# Prints "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"
如果想要接收键、值需要使用items()方法获取:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal, legs in d.items():print('A %s has %d legs' % (animal, legs))
# Prints "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"
②使用列表推导式很方便地构造字典
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print(even_num_to_square) # Prints "{0: 0, 2: 4, 4: 16}"
(3)集合Set
集合是不同元素的无序集合
animals = {'cat', 'dog'}
print('cat' in animals) # Check if an element is in a set; prints "True"
print('fish' in animals) # prints "False"
animals.add('fish') # Add an element to a set
print('fish' in animals) # Prints "True"
print(len(animals)) # Number of elements in a set; prints "3"
animals.add('cat') # Adding an element that is already in the set does nothing
print(len(animals)) # Prints "3"
animals.remove('cat') # Remove an element from a set
print(len(animals)) # Prints "2"
更多方法细节:
https://docs.python.org/3.8/library/stdtypes.html#set![]() https://docs.python.org/3.5/library/stdtypes.html#set
https://docs.python.org/3.5/library/stdtypes.html#set
①遍历集合
遍历集合与遍历列表的语法相同;然而,由于集合是无序的,你无法把集合中元素的访问顺序作为元素间顺序。
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):print('#%d: %s' % (idx + 1, animal))
# Prints "#1: fish", "#2: dog", "#3: cat"
②构建集合
from math import sqrt
nums = {int(sqrt(x)) for x in range(30)}
print(nums) # Prints "{0, 1, 2, 3, 4, 5}"(4)元组
元组是一个(不可变的)有序值列表。元组在很多方面与列表相似;其中一个最重要的区别是,元组可以用作字典的键,也可以用作集合的元素,而列表不能。下面是一个简单的例子:
d = {(x, x + 1): x for x in range(6)} # Create a dictionary with tuple keys
t = (5, 6) # Create a tuple
print(type(t)) # Prints "<class 'tuple'>"
print(d[t]) # Prints "5"
print(d[(1, 2)]) # Prints "1"
print(d)
更多元素相关内容:
https://docs.python.org/3.8/tutorial/datastructures.html#tuples-and-sequences
4.函数
使用def关键字
def sign(x):if x > 0:return 'positive'elif x < 0:return 'negative'else:return 'zero'for x in [-1, 0, 1]:print(sign(x))
# Prints "negative", "zero", "positive"
通常会定义接收可选关键字参数的函数:
def hello(name, loud=False):if loud:print('HELLO, %s!' % name.upper())else:print('Hello, %s' % name)hello('Bob') # Prints "Hello, Bob"
hello('Fred', loud=True) # Prints "HELLO, FRED!"
更多函数相关细节:
https://docs.python.org/3.8/tutorial/controlflow.html#defining-functions![]() https://docs.python.org/3.5/tutorial/controlflow.html#defining-functions
https://docs.python.org/3.5/tutorial/controlflow.html#defining-functions
5.类class
类举例,注意构造函数的命名方式:
class Greeter(object):# Constructordef __init__(self, name):self.name = name # Create an instance variable# Instance methoddef greet(self, loud=False):if loud:print('HELLO, %s!' % self.name.upper())else:print('Hello, %s' % self.name)g = Greeter('Fred') # Construct an instance of the Greeter class
g.greet() # Call an instance method; prints "Hello, Fred"
g.greet(loud=True) # Call an instance method; prints "HELLO, FRED!"
更多类相关细节:
9. Classes — Python 3.12.4 documentationClasses provide a means of bundling data and functionality together. Creating a new class creates a new type of object, allowing new instances of that type to be made. Each class instance can have ...![]() https://docs.python.org/3/tutorial/classes.html#
https://docs.python.org/3/tutorial/classes.html#
三、学习Numpy
Numpy是Python科学计算的核心库。它提供了一个高性能的多维数组对象,以及用于处理这些数组的工具。
NumPy reference — NumPy v2.0 Manual
https://numpy.org/doc/stable/reference/index.html#reference
1.Arrays
numpy数组是由相同类型的值组成的网格,数组的索引为一个非负整数元组。维数是数组的秩;数组的形状是一个整数元组,给出了数组在每个维度上的大小。
(1)访问元素
我们可以从嵌套的Python列表中初始化numpy数组,并使用方括号访问元素:
import numpy as np
a = np.array([1, 2, 3]) # Create a rank 1 array
print(type(a)) # Prints "<class 'numpy.ndarray'>"
print(a.shape) # Prints "(3,)"
print(a[0], a[1], a[2]) # Prints "1 2 3"
a[0] = 5 # Change an element of the array
print(a) # Prints "[5, 2, 3]”b = np.array([[1,2,3],[4,5,6]]) # Create a rank 2 array
print(b.shape) # Prints "(2, 3)"
print(b[0, 0], b[0, 1], b[1, 0]) # Prints "1 2 4"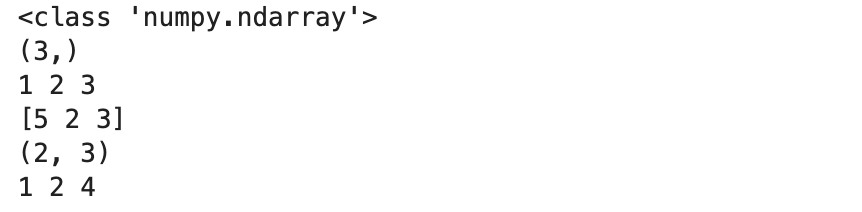
(2)创建arrays
a = np.zeros((2,2)) # Create an array of all zeros
print(a) # Prints "[[ 0. 0.]# [ 0. 0.]]"
b = np.ones((1,2)) # Create an array of all ones
print(b) # Prints "[[ 1. 1.]]"
c = np.full((2,2), 7) # Create a constant array
print(c) # Prints "[[ 7. 7.]# [ 7. 7.]]"
d = np.eye(2) # Create a 2x2 identity matrix
print(d) # Prints "[[ 1. 0.]# [ 0. 1.]]"
e = np.random.random((2,2)) # Create an array filled with random values
print(e) # Might print "[[ 0.91940167 0.08143941]# [ 0.68744134 0.87236687]]"
更多array创建的内容: Array creation — NumPy v2.0 Manual
(3)切片
与Python列表类似,numpy数组也可以被切片。由于数组可能是多维的,因此必须为数组的每个维度指定切片:[row1:row2,col1:col2]操作符切片,下标从0开始,不包括结束位置下标
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Use slicing to pull out the subarray consisting of the first 2 rows
# and columns 1 and 2; b is the following array of shape (2, 2):
# [[2 3]
# [6 7]]
b = a[:2, 1:3]
# A slice of an array is a view into the same data, so modifying it
# will modify the original array.
print(a[0, 1]) # Prints "2"
b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1]
print(a[0, 1]) # Prints "77"注意:数组的切片是相同数据的视图,所以修改它也会修改原始数组。
(4)混合使用整型索引和切片索引
你也可以混合使用整型索引和切片索引。然而,这样做将得到一个比原始数组低的数组。
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])# Two ways of accessing the data in the middle row of the array.
# Mixing integer indexing with slices yields an array of lower rank,
# while using only slices yields an array of the same rank as the
# original array:
row_r1 = a[1, :] # Rank 1 view of the second row of a
row_r2 = a[1:2, :] # Rank 2 view of the second row of a
print(row_r1, row_r1.shape) # Prints "[5 6 7 8] (4,)"
print(row_r2, row_r2.shape) # Prints "[[5 6 7 8]] (1, 4)”# We can make the same distinction when accessing columns of an array:
col_r1 = a[:, 1]
col_r2 = a[:, 1:2]
print(col_r1, col_r1.shape) # Prints "[ 2 6 10] (3,)"
print(col_r2, col_r2.shape) # Prints "[[ 2]# [ 6]# [10]] (3, 1)"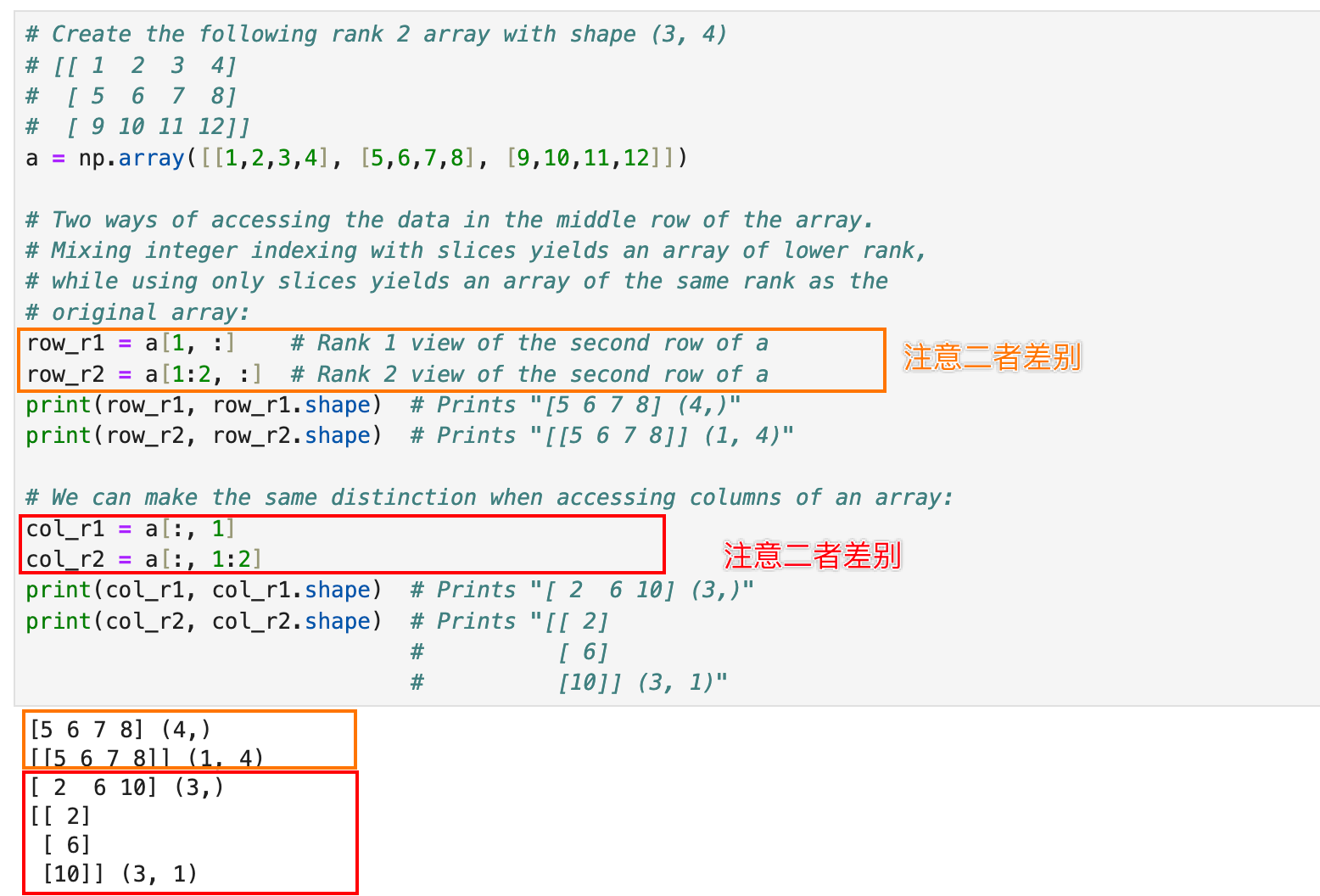
整数数组索引的一个有用技巧是从矩阵的每一行中选择或改变一个元素:
# Create a new array from which we will select elements
a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])print(a) # prints "array([[ 1, 2, 3],# [ 4, 5, 6],# [ 7, 8, 9],# [10, 11, 12]])"
print("------------------")
# Create an array of indices
b = np.array([0, 2, 0, 1])# 使用b中的下标从a的每一行中选择一个元素
print(a[np.arange(4), b]) # Prints "[ 1 6 7 11]"
print("------------------")
# Mutate one element from each row of a using the indices in b
a[np.arange(4), b] += 10
print(a) # prints "array([[11, 2, 3],# [ 4, 5, 16],# [17, 8, 9],# [10, 21, 12]])
(5)使用子数组视图构建新数组
使用切片对numpy数组进行索引时,得到的数组视图始终是原始数组的子数组。相比之下,整数数组索引允许你使用另一个数组中的数据来构建任意数组。下面是一个例子:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
# An example of integer array indexing.
# The returned array will have shape (3,) and
print(a[[0, 1, 2], [0, 1, 0]]) # Prints "[1 4 5]”# The above example of integer array indexing is equivalent to this:
print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # Prints "[1 4 5]”# When using integer array indexing, you can reuse the same
# element from the source array:
print(a[[0, 0], [1, 1]]) # Prints "[2 2]”# Equivalent to the previous integer array indexing example
print(np.array([a[0, 1], a[0, 1]])) # Prints "[2 2]"
(6)boolean数组索引
布尔数组索引允许你从数组中挑选任意元素。这种类型的索引通常用于选择满足某种条件的数组元素。下面是一个例子:
a = np.array([[1,2], [3, 4], [5, 6]])bool_idx = (a > 2) # Find the elements of a that are bigger than 2;# this returns a numpy array of Booleans of the same# shape as a, where each slot of bool_idx tells# whether that element of a is > 2.print(bool_idx) # Prints "[[False False]# [ True True]# [ True True]]”# We use boolean array indexing to construct a rank 1 array
# consisting of the elements of a corresponding to the True values
# of bool_idx
print(a[bool_idx]) # Prints "[3 4 5 6]”# We can do all of the above in a single concise statement:
print(a[a > 2]) # Prints "[3 4 5 6]"
更多numpy数组索引的细节:Indexing on ndarrays — NumPy v2.0 Manual
2.数据类型
每个numpy数组都是由相同类型的元素组成的网格。Numpy提供了大量的数值数据类型,可用于构造数组。Numpy在创建数组时尝试猜测数据类型,但构造数组的函数通常还包含一个可选的参数来显式指定数据类型。下面是一个例子:
x = np.array([1, 2]) # Let numpy choose the datatype
print(x.dtype) # Prints "int64"
x = np.array([1.0, 2.0]) # Let numpy choose the datatype
print(x.dtype) # Prints "float64"
x = np.array([1, 2], dtype=np.int64) # Force a particular datatype
print(x.dtype) # Prints "int64"更多细节:Data type objects (dtype) — NumPy v2.0 Manual
3.向量的数学运算
(1)逐元素基本运算
numpy模块提供了操作数组逐元素的基本数学函数,既可以作为运算符重载,也可以作为函数使用:
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)# Elementwise sum; both produce the array
# [[ 6.0 8.0]
# [10.0 12.0]]
print(x + y)
print(np.add(x, y))
print("-----------------")# Elementwise difference; both produce the array
# [[-4.0 -4.0]
# [-4.0 -4.0]]
print(x - y)
print(np.subtract(x, y))
print("-----------------")# Elementwise product; both produce the array
# [[ 5.0 12.0]
# [21.0 32.0]]
print(x * y)
print(np.multiply(x, y))
print("-----------------")# Elementwise division; both produce the array
# [[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]]
print(x / y)
print(np.divide(x, y))
print("————————")# Elementwise square root; produces the array
# [[ 1. 1.41421356]
# [ 1.73205081 2. ]]
print(np.sqrt(x))
(2)向量内积、向量与矩阵、矩阵与矩阵乘积
请注意,与MATLAB不同,*是逐元素乘法,而不是矩阵乘法。相反,我们使用dot函数来计算向量的内积、向量与矩阵的乘积以及矩阵的乘积。dot既可以作为numpy模块中的函数使用,也可以作为数组对象的实例方法使用:
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])v = np.array([9,10])
w = np.array([11, 12])# Inner product of vectors; both produce 219
print(v.dot(w))
print(np.dot(v, w))
print("-----------------")# Matrix / vector product; both produce the rank 1 array [29 67]
print(x.dot(v))
print(np.dot(x, v))
print("-----------------")# Matrix / matrix product; both produce the rank 2 array
# [[19 22]
# [43 50]]
print(x.dot(y))
print(np.dot(x, y))
(3)sum函数
Numpy提供了许多有用的数组计算函数,比如sum
x = np.array([[1,2],[3,4]])print(np.sum(x)) # Compute sum of all elements; prints "10"
print(np.sum(x, axis=0)) # Compute sum of each column; prints "[4 6]"
print(np.sum(x, axis=1)) # Compute sum of each row; prints "[3 7]"更多的数学计算函数:Mathematical functions — NumPy v2.0 Manual
(4)矩阵转置
除了使用数组计算数学函数外,我们经常需要对数组中的数据进行重塑或操作。这种类型的操作最简单的例子是矩阵转置;要转置矩阵,只需使用数组对象的T属性:

更多数组操作链接:Array manipulation routines — NumPy v2.0 Manual
(5)广播Broadcasting
广播是一种强大的机制,numpy可以对不同形状的数组进行算术运算。通常,我们有一个较小的数组和一个较大的数组,我们希望多次使用较小的数组对较大的数组执行某些操作。
假设我们想给矩阵的每一行添加一个常量向量。我们可以这样做:
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = np.empty_like(x) # Create an empty matrix with the same shape as x# Add the vector v to each row of the matrix x with an explicit loop
for i in range(4):y[i, :] = x[i, :] + v# Now y is the following
# [[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]
print(y)
上面的方法可行,然而,当矩阵x非常大时,在Python中计算显式循环可能会很慢。
注意,将向量v与矩阵x的每一行相加,等价于将vv的多个副本垂直堆叠,然后对x和v进行逐元素求和,从而形成一个矩阵vv。举个例子直观展示:
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
vv = np.tile(v, (4, 1)) # Stack 4 copies of v on top of each other
print(vv) # Prints "[[1 0 1]# [1 0 1]# [1 0 1]# [1 0 1]]"
y = x + vv # Add x and vv elementwise
print(y) # Prints "[[ 2 2 4# [ 5 5 7]# [ 8 8 10]# [11 11 13]]"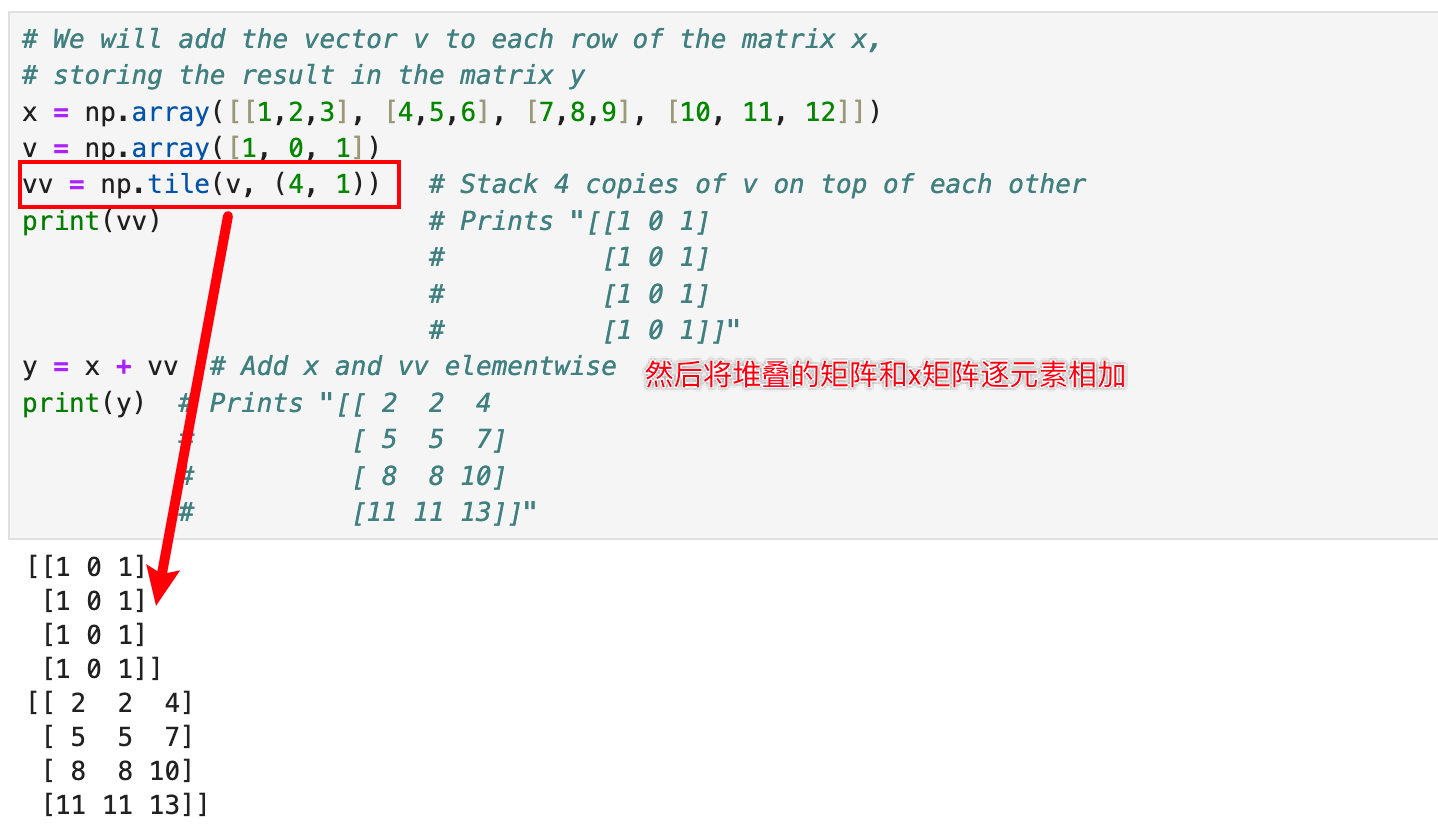
Numpy中的广播允许我们在不创建v的多个副本的情况下进行计算,直接相加(体现广播特性):
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = x + v # Add v to each row of x using broadcasting
print(y) # Prints "[[ 2 2 4]# [ 5 5 7]# [ 8 8 10]# [11 11 13]]"
即使x的形状为(4,3),而v的形状为(3,),但直线y = x + v仍然有效;这行代码就好像v的形状是(4,3)一样,其中每一行都是v的一个副本,并且求和是逐元素进行的。
同时广播两个数组需要遵循以下规则:
①如果两个数组的秩不相同,则在低秩数组的形状前加1,直到两个形状的长度相同。
②如果这两个数组在某个维度上的大小相同,或者其中一个数组的大小为1,则称这两个数组在该维度上是兼容的。
③如果数组在所有维度上都兼容,则可以将它们广播在一起。
④在广播之后,每个数组的形状等于两个输入数组最大形状。
⑤在任意维度中,如果一个数组的大小为1,而另一个数组的大小大于1,则第一个数组的行为就像沿着第二个数组维度复制的一样

(6)广播的一些应用
# Compute outer product of vectors
v = np.array([1,2,3]) # v has shape (3,)
w = np.array([4,5]) # w has shape (2,)
# To compute an outer product, we first reshape v to be a column
# vector of shape (3, 1); we can then broadcast it against w to yield
# an output of shape (3, 2), which is the outer product of v and w:
# [[ 4 5]
# [ 8 10]
# [12 15]]
print(np.reshape(v, (3, 1)) * w)# Add a vector to each row of a matrix
x = np.array([[1,2,3], [4,5,6]])
# x has shape (2, 3) and v has shape (3,) so they broadcast to (2, 3),
# giving the following matrix:
# [[2 4 6]
# [5 7 9]]
print(x + v)# Add a vector to each column of a matrix
# x has shape (2, 3) and w has shape (2,).
# If we transpose x then it has shape (3, 2) and can be broadcast
# against w to yield a result of shape (3, 2); transposing this result
# yields the final result of shape (2, 3) which is the matrix x with
# the vector w added to each column. Gives the following matrix:
# [[ 5 6 7]
# [ 9 10 11]]
print((x.T + w).T)
# Another solution is to reshape w to be a column vector of shape (2, 1);
# we can then broadcast it directly against x to produce the same
# output.
print(x + np.reshape(w, (2, 1)))# Multiply a matrix by a constant:
# x has shape (2, 3). Numpy treats scalars as arrays of shape ();
# these can be broadcast together to shape (2, 3), producing the
# following array:
# [[ 2 4 6]
# [ 8 10 12]]
print(x * 2)
四、学习Scipy
Numpy提供了高性能多维数组以及基本的计算和操作这些数组的工具。SciPy在此基础上提供了大量numpy数组操作函数,适用于不同类型的科学和工程应用。
SciPy API — SciPy v1.14.0 Manual
要想熟悉SciPy,最好的方法是浏览它的文档。我们将重点介绍SciPy中对这门课可能有用的部分。
1.图像操作
SciPy提供了一些处理图像的基本函数。例如,它有函数将图像从磁盘读入numpy数组,将numpy数组作为图像写入磁盘,以及调整图像的大小。下面是展示这些函数的一个简单示例:
注意:原来代码中的scipy.misc已经被弃用,要使用Pillow来代替
#原代码
from scipy.misc import imread, imsave, imresize# Read an JPEG image into a numpy array
img = imread('assets/cat.jpg')
print(img.dtype, img.shape) # Prints "uint8 (400, 248, 3)"
# We can tint the image by scaling each of the color channels
# by a different scalar constant. The image has shape (400, 248, 3);
# we multiply it by the array [1, 0.95, 0.9] of shape (3,);
# numpy broadcasting means that this leaves the red channel unchanged,
# and multiplies the green and blue channels by 0.95 and 0.9
# respectively.
img_tinted = img * [1, 0.95, 0.9]# Resize the tinted image to be 300 by 300 pixels.
img_tinted = imresize(img_tinted, (300, 300))# Write the tinted image back to disk
imsave('assets/cat_tinted.jpg', img_tinted)#替换可用代码
from PIL import Image
import imageio as iio
import numpy as np#读取一张图片到PIL Image对象中
img = Image.open('flower.png')
print("img:",img.mode, img.size)img_array = np.asarray(img)#给图片上色,通过缩放每个color channel(red, green, blue)
#将红色通道缩放1倍,绿色通道缩放0.95倍,蓝色通道缩放0.9倍
#最后将浮点数组转换回uint8类型
img_tinted = (img_array * [1, 0.95, 0.9]).astype(np.uint8)print("img_tinted:",img_tinted.dtype, img_tinted.shape)#将numpy array 转为PIL image对象
img_tinted_pil = Image.fromarray(img_tinted)#对img_tinted_pil对象进行resize操作
img_tinted_resized = img_tinted_pil.resize((300, 300)) #将上色并调整大小后的图片保存回磁盘
img_tinted_resized.save('flower_tinted2.png')原图:

上色+大小调整后效果图:

2.数学运算:欧几里得距离
from scipy.spatial.distance import pdist, squareform# Create the following array where each row is a point in 2D space:
# [[0 1]
# [1 0]
# [2 0]]
x = np.array([[0, 1], [1, 0], [2, 0]])
print(x)# Compute the Euclidean distance between all rows of x.
# d[i, j] is the Euclidean distance between x[i, :] and x[j, :],
# and d is the following array:
# [[ 0. 1.41421356 2.23606798]
# [ 1.41421356 0. 1. ]
# [ 2.23606798 1. 0. ]]
d = squareform(pdist(x, 'euclidean'))
print(d)
更多细节:cdist — SciPy v1.14.0 Manual
五、学习Matplotlib
1.Plotting绘制二维图
matplotlib中最重要的函数是plot,它允许你绘制二维数据。下面是一个简单的例子:
import matplotlib.pyplot as plt# Compute the x and y coordinates for points on a sine curve
x = np.arange(0, 3 * np.pi, 0.1)
y = np.sin(x)# Plot the points using matplotlib
plt.plot(x, y)
plt.show() # You must call plt.show() to make graphics appear.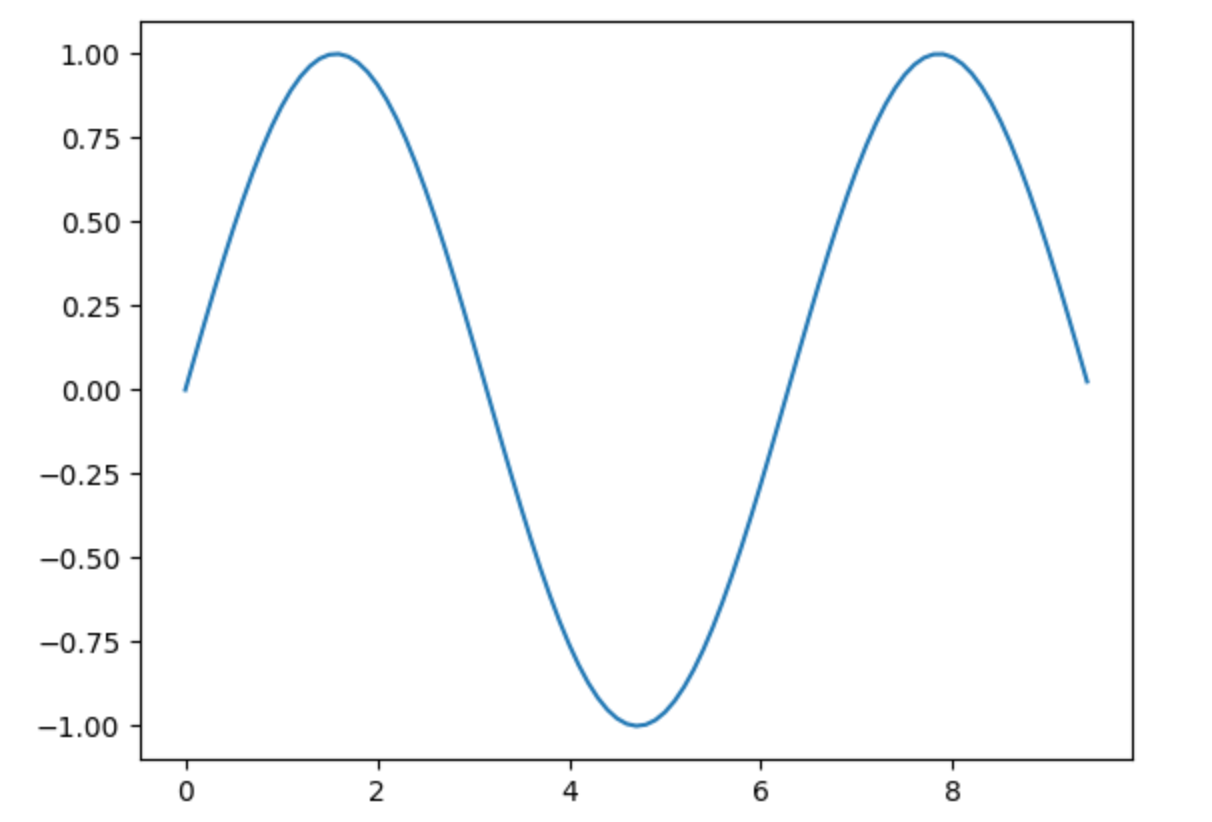
只需要做一点点额外的工作,就可以轻松地一次绘制多条线,并添加标题、图例和坐标轴标签:
# Compute the x and y coordinates for points on sine and cosine curves
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)# Plot the points using matplotlib
plt.plot(x, y_sin)
plt.plot(x, y_cos)
plt.xlabel('x axis label')
plt.ylabel('y axis label')
plt.title('Sine and Cosine')
plt.legend(['Sine', 'Cosine'])
plt.show()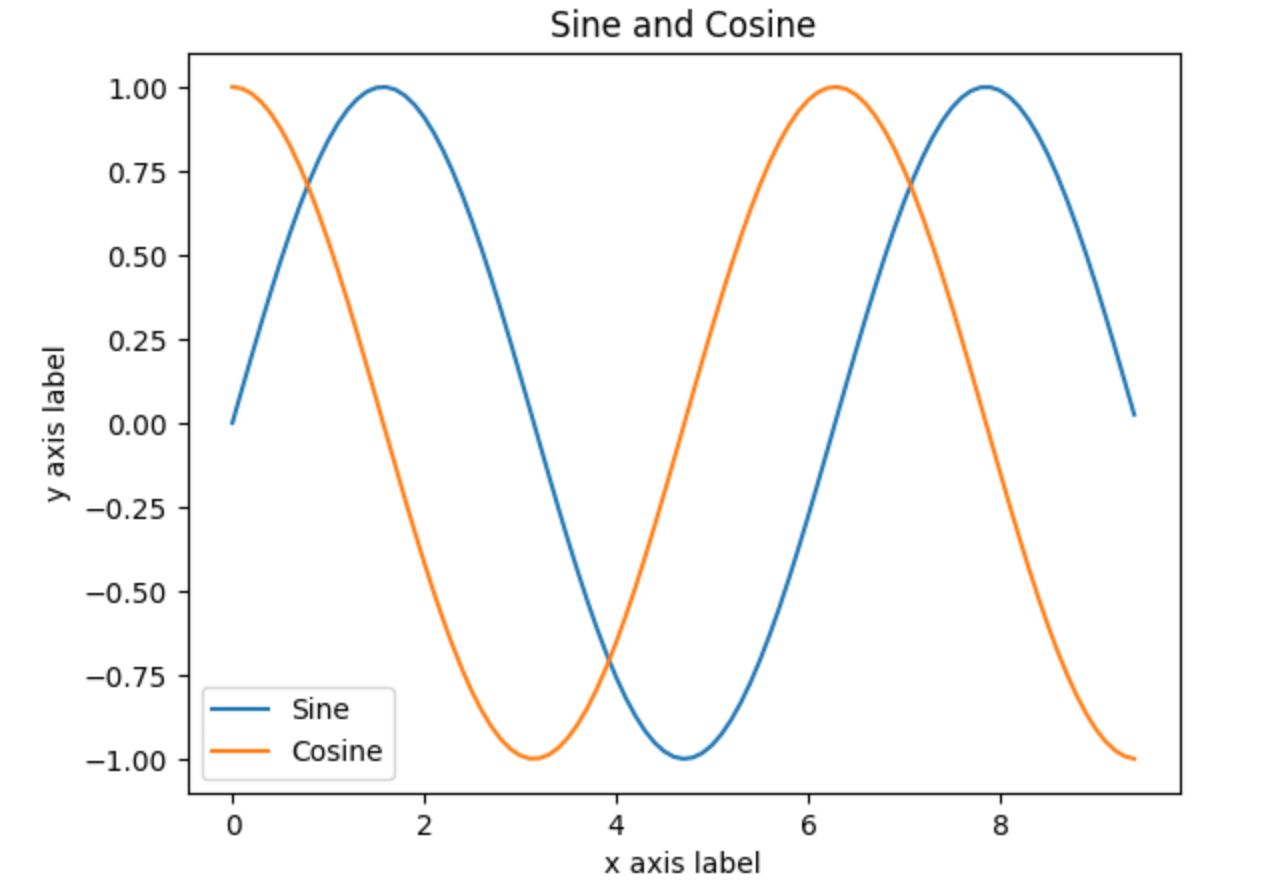
2.Subplots 绘制子图
(1)Subplots同一幅图绘制不同图形
你可以使用subplot函数在同一幅图中绘制不同的图形。举个例子:
# Compute the x and y coordinates for points on sine and cosine curves
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)# Set up a subplot grid that has height 2 and width 1,
# and set the first such subplot as active.
plt.subplot(2, 1, 1)# Make the first plot
plt.plot(x, y_sin)
plt.title('Sine')# Set the second subplot as active, and make the second plot.
plt.subplot(2, 1, 2)
plt.plot(x, y_cos)
plt.title('Cosine')# Show the figure.
plt.show()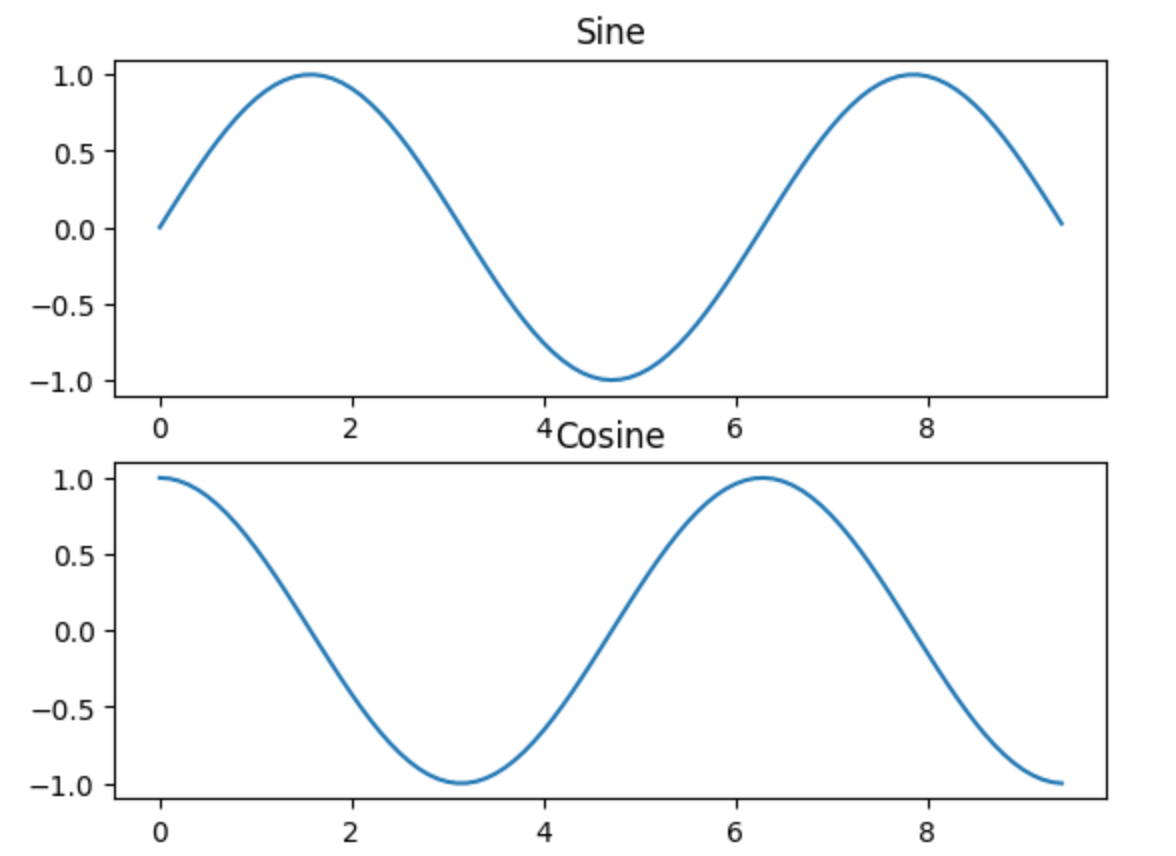
更多细节:pyplot — Matplotlib 2.0.2 documentation
(2)对图片进行绘制,横纵坐标范围根据像素设置
plt.subplot(1, 2, 1)
#子图1绘制图片上色后的图,注意数据类型必须是uint8,所以这里使用array矩阵,img_tinted前面四、1出现过
plt.imshow(img_tinted)
# Show the tinted image
plt.subplot(1, 2, 2)
#子图2绘制resize后的图,这里的img_tinted_resized是Image对象,所以需要转化为矩阵形式
plt.imshow(np.asarray(img_tinted_resized))
plt.show()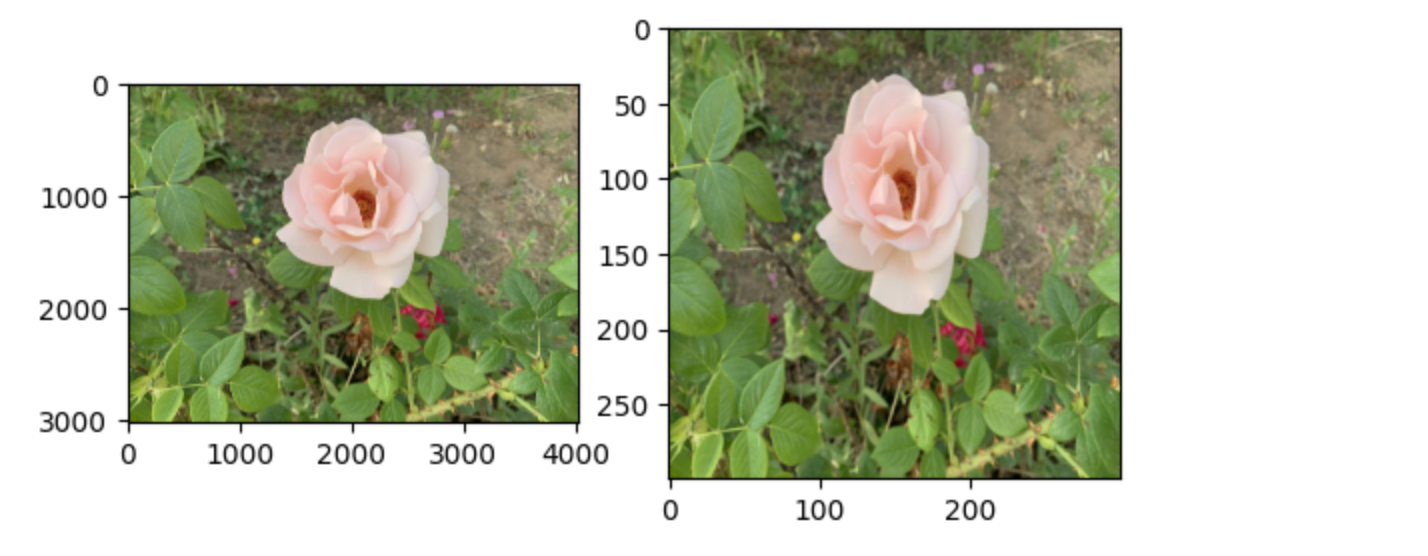
六、总结
本节将作为一个关于Python编程语言及其在科学计算中的使用的速成课程。介绍了Jupyter notebook,这是一种非常方便的编程Python代码的方式。介绍了Python的常用语法、数据类型、运算符、容器等内容。介绍了Numpy库、Scipy库以及Matplotlib库的作用以及常见的API用法,对我们科学计算、图片操作和绘图有很大的帮助。