个人博客地址
基于源码详解ThreadPoolExecutor实现原理 | iwts’s blog
内容拆分
这里算是一个总集,内容太多,拆分成几个比较重要的小的模块:
ThreadPoolExecutor基于ctl变量的声明周期管理 | iwts’s blog
ThreadPoolExecutor 工作线程Worker自身锁设计 | iwts’s blog
ThreadPoolExecutor 线程回收时机详解 | iwts’s blog
Java ThreadPoolExecutor
线程池,Thread Pool,是一种基于池化思想管理线程的工具,一般是多线程服务器中使用很多,例如MySQL。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。
线程池维护多个线程,等待监督管理者分配可并发执行的任务。从而避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
- 降低资源消耗:重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,允许任务延期执行或定期执行。
ThreadPoolExecutor核心设计

线程池顶级接口Executor
顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。

简单粗暴,执行就完了。
线程池扩充服务接口ExecutorService
ExecutorService接口增加了一些能力:
-
扩充执行任务的能力,例如
submit(),可以为一个或一批异步任务生成Future。 -
提供了管控线程池的方法,例如
shutdown(),停止线程池的运行。a. 包括状态监控,例如
isShutdown()。 -
执行流程方法,例如
invokeAll()。
线程池抽象类AbstractExecutorService
将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。
ThreadPoolExecutor实现
最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
ThreadPoolExecutor运行流程
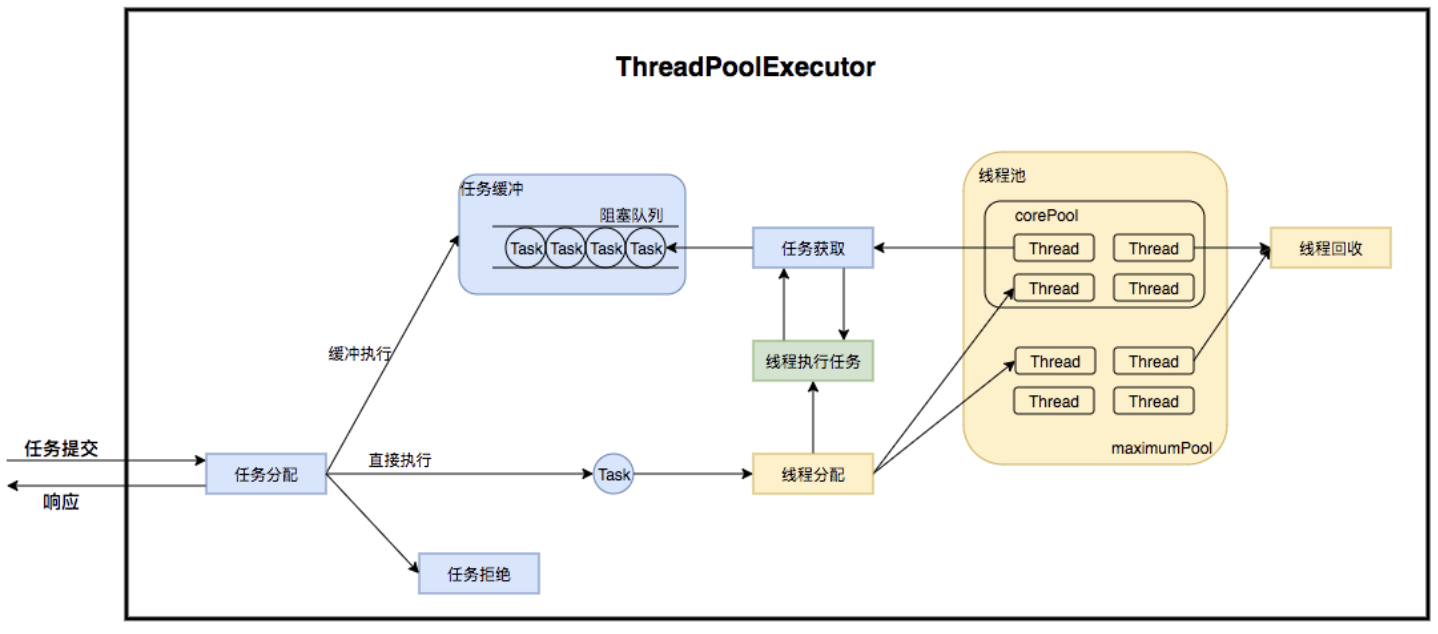
线程池在内部构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。
线程池的运行主要分成两部分:
- 任务管理。
- 线程管理。
任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:
- 直接申请线程执行该任务。
- 缓冲到队列中等待线程执行。
- 拒绝该任务。
线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
线程池生命周期管理-ctl字段的应用
线程池内部使用一个变量ctl维护两个值:
- 运行状态(runState)
- 线程数量 (workerCount)

在具体实现中,就是进行位运算:
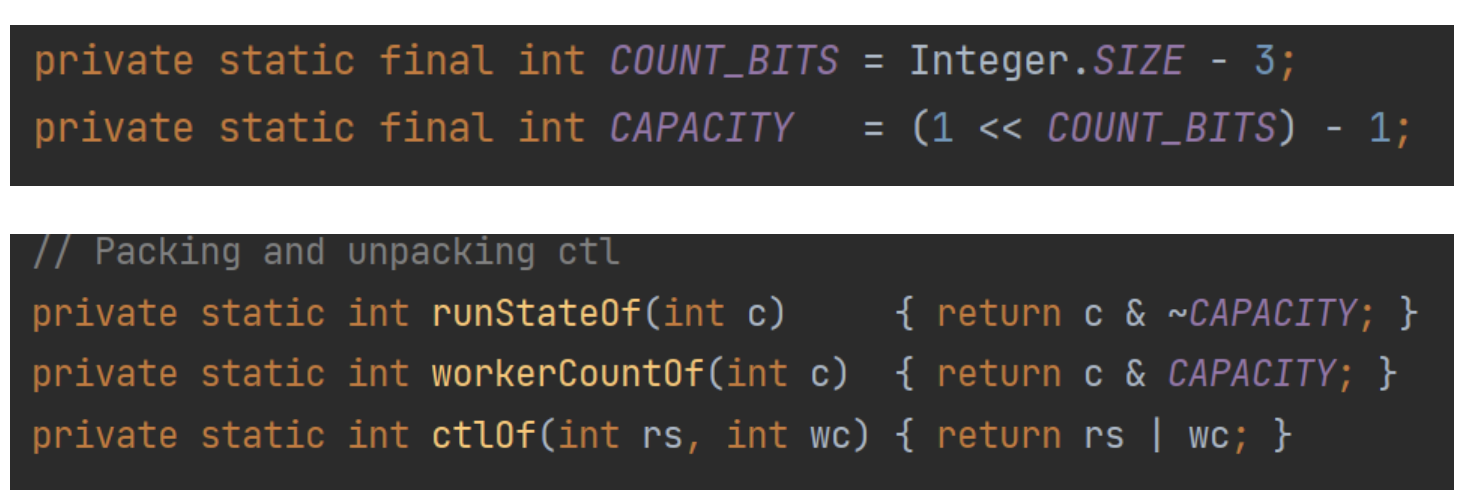
COUNT_BITS如果是32位的话,那么结合下面的一套左移、与、非的位运算,可以总结为:
- ctl的高3位保存runState,即运行状态。
- ctl的低29位保存workerCount,即有效线程数量。
除了ctl解析方法,还提供ctl计算方法,即根据runState和workerCount,计算出ctl值。
这样合并的好处是,操作的时候单锁就可以处理了(CAS也非常方便),位运算速度也快。
线程池运行状态
| 运行状态 | 运行状态 | desc |
|---|---|---|
| running | 运行 | 能接收新任务,能处理队列任务 |
| shutdown | 关闭 | 不接受新任务,能处理队列任务 |
| stop | 停止 | 不接受新任务,不处理队列任务,中断处理任务的线程 |
| tidying | 整理 | 所有任务已结束,workerCount=0 |
| terminated | terminated()方法执行后进入该状态 |

线程池工作流程
任务提交-submit()
就是一个入口方法,但是分为阻塞和非阻塞:
- submit:返回Future对象,底层仍然是execute,Future操作时可能会阻塞。
- execute:常规非阻塞方法,提交后正常执行。
submit是异步编程时可能会用到:
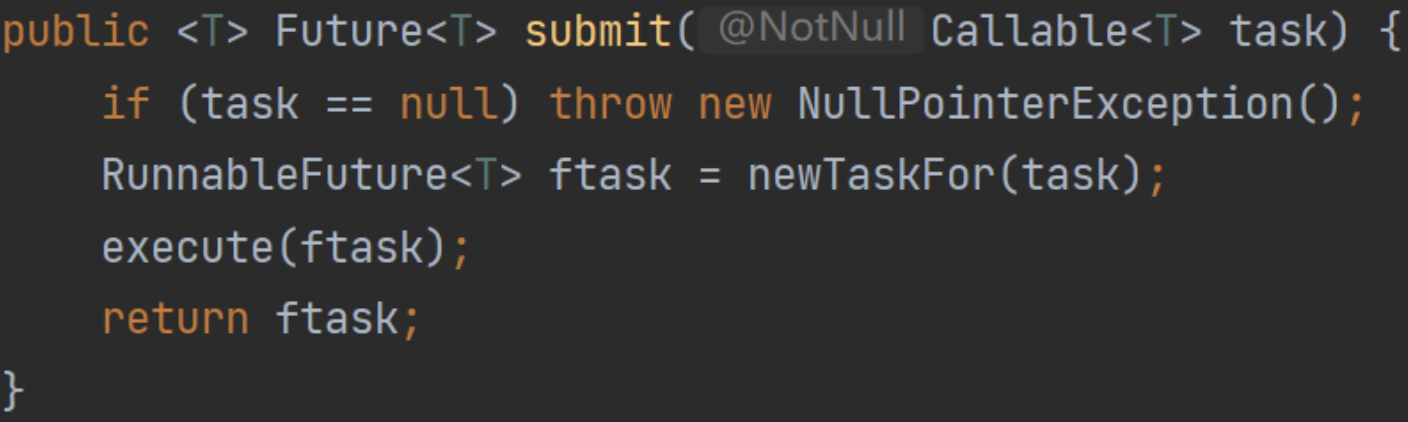
本质上是利用Future,还是普通的调用execute执行,对外透出Future对象。
任务调度-execute()
任务调度是线程池的核心,当用户提交了一个任务,接下来这个任务将如何执行都是由任务调度来决定。核心入口方法:java.util.concurrent.ThreadPoolExecutor#execute
代码也并不难:
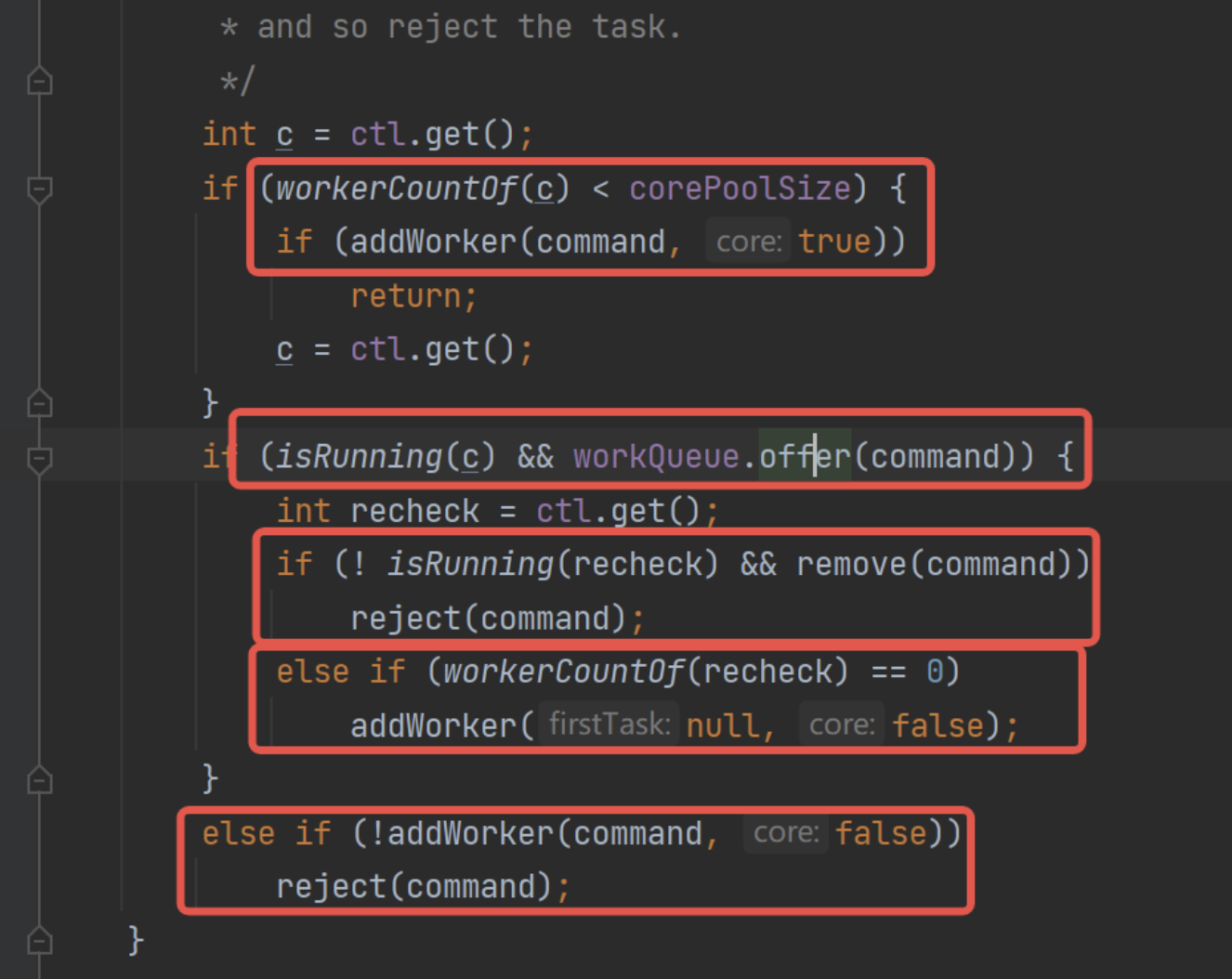
其中reject()方法是拒绝策略,具体参考下面的内容,addWorker()下面工作线程部分详讲,目前需要知道是创建了一个工作线程,入参有Runable对象则说明创建后就用这个线程来执行该对象的任务方法,没有就说明只是创建线程。
总的流程可以参考:
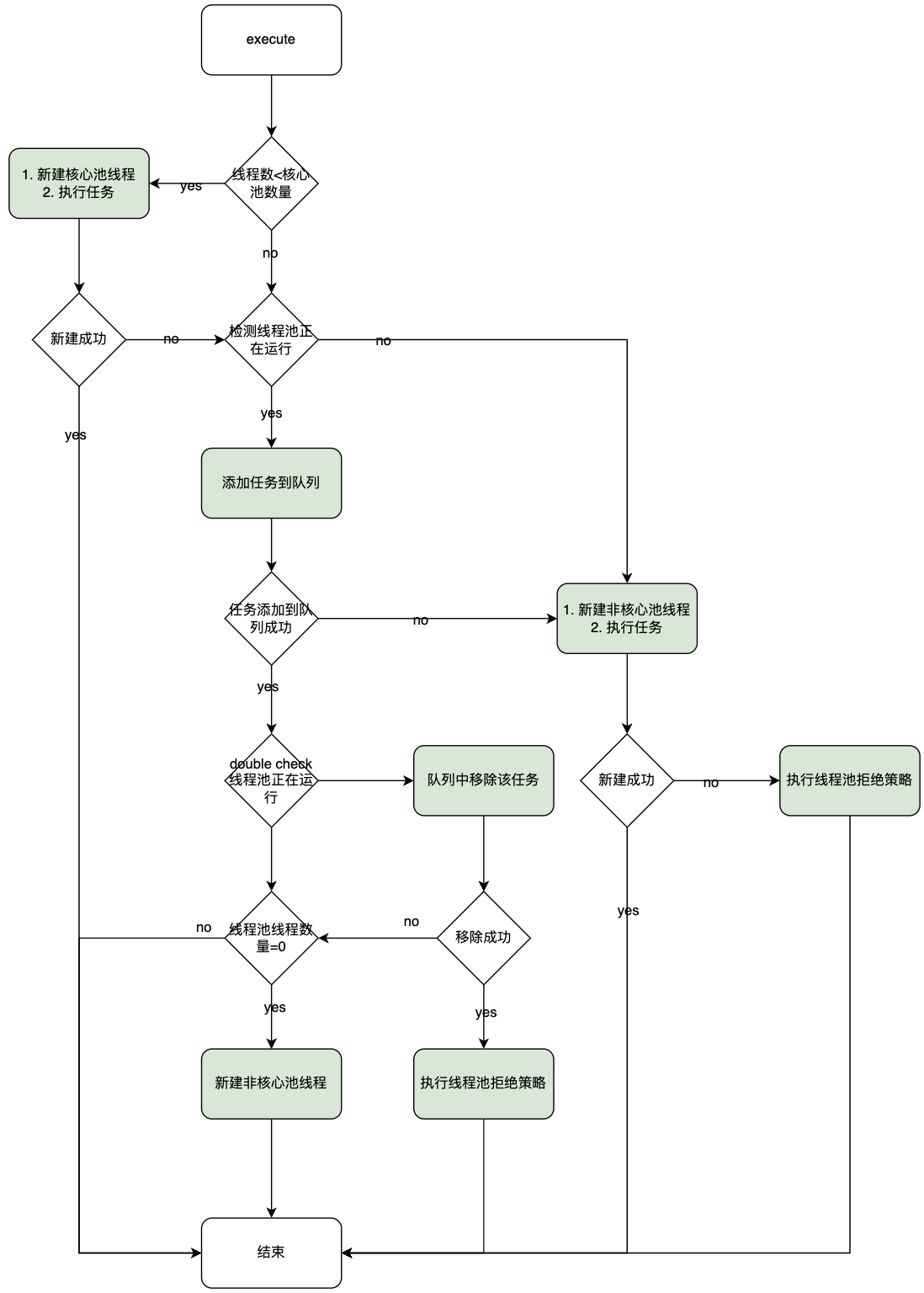
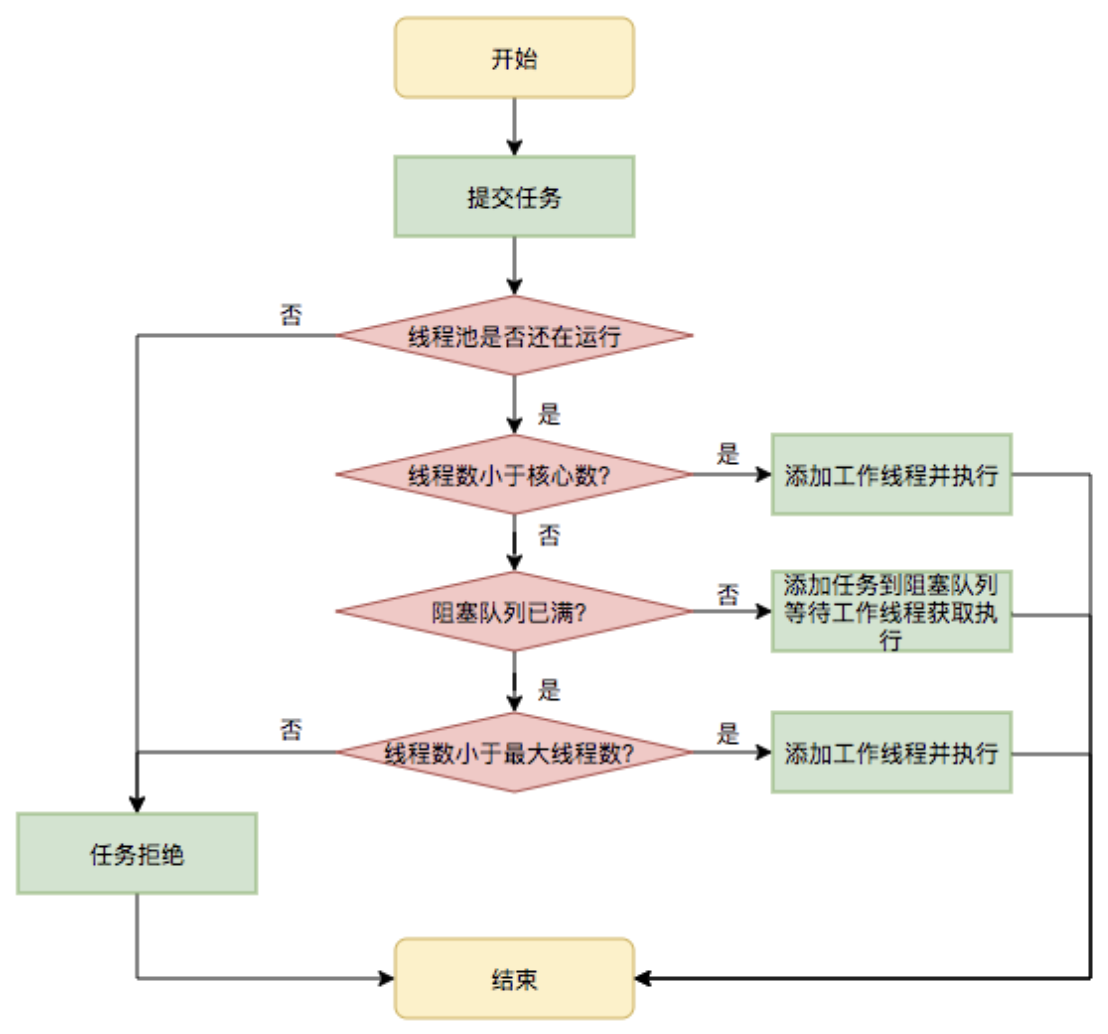
如果从大的方向看,整个execute的调度工作为:
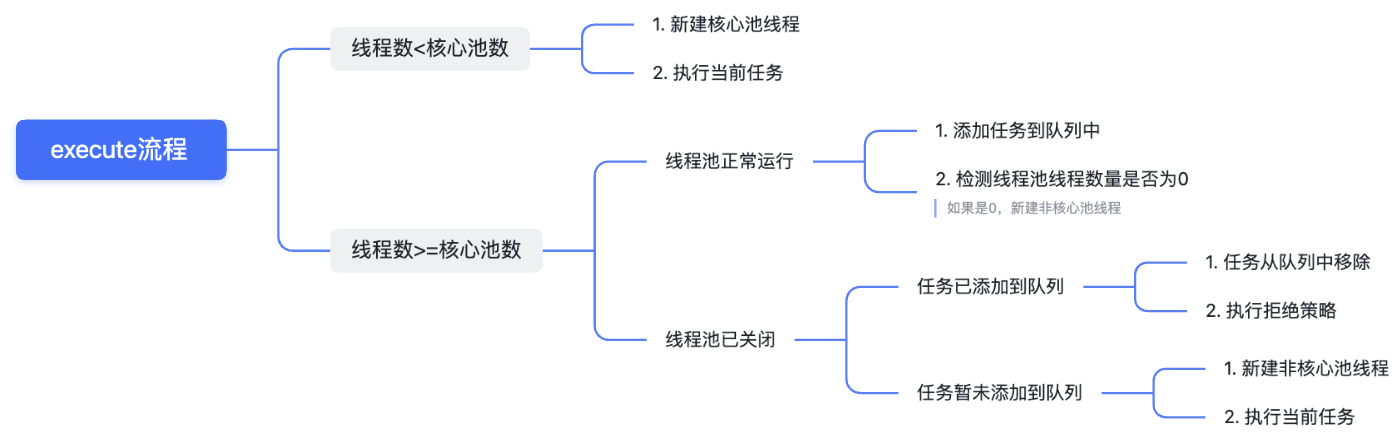
简而言之:
- 当前线程数量小于核心池数量,创建线程并执行。
- 当前线程数量大于核心池数量,且任务队列不满,加入任务队列。
- 如果任务队列已经满了,但是线程池数量小于线程池设定的最大数量,创建一个线程来执行任务。
- 如果比最大数量都大,只能拒绝服务。
任务缓冲模块设计
任务缓冲模块是线程池能够管理任务的核心。
线程池的本质是对任务和线程的管理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才可以做后续的分配工作。
线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。
阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
任务阻塞队列
缓冲模块的核心设计了,JUC提供了阻塞队列框架:BlockingQueue,设计思想如下:

而具体的实现则交给使用者自行选择,比较简单的,直接从JUC包的实现中选择阻塞队列实现类就可以了。
JUC原生阻塞队列类型对比
不同阻塞队列的具体实现类有不同的特性,简单总结如下:
| 名称 | 描述 |
|---|---|
| ArrayBlockingQueue | 底层数据结构为数组,队列大小要主动设置,FIFO。 |
| LinkedBlockingQueue | 底层数据结构为单向链表,队列大小为int最大位,FIFO。 |
| PriorityBlockingQueue | 底层数据结构为数组,无界,按存放对象compareTo指定优先级进出。 |
| DelayQueue | 基于PriorityBlockingQueue,指定延期时间,延期时间到后从队列中获取数据。 |
| SynchronousQueue | 不存储数据,只有在执行take的时候,才会执行put。 |
| LinkedTransferQueue | 跟LinkedBlockingQueue类似,多了transfer相关方法。 |
| LinkedBlockingDeque | 跟LinkedBlockingQueue类似,底层改成双向链表,组成双向阻塞队列,高并发时,锁竞争最多减少一半。 |
任务申请-getTask()
注意不是任务提交。
根据上面任务调度的内容,正常情况下,任务提交后的执行有两种方式:
- 直接创建新的线程,并去执行任务。
- 线程从任务队列中获取任务然后执行,执行完任务的空闲线程会再次去从队列中申请任务。
一般来说,对于业务请求量较大的系统,大部分情况下都是2,不会额外创建线程。都是丢入队列就完事。
1的执行时机其实是业务请求的时候,调用submit()或者execute()。那2的执行时机是由线程池保证的。这一块下面工作线程部分会讲到。
那么从任务队列中挑选一个任务并执行。
这个申请的核心代码为:getTask()
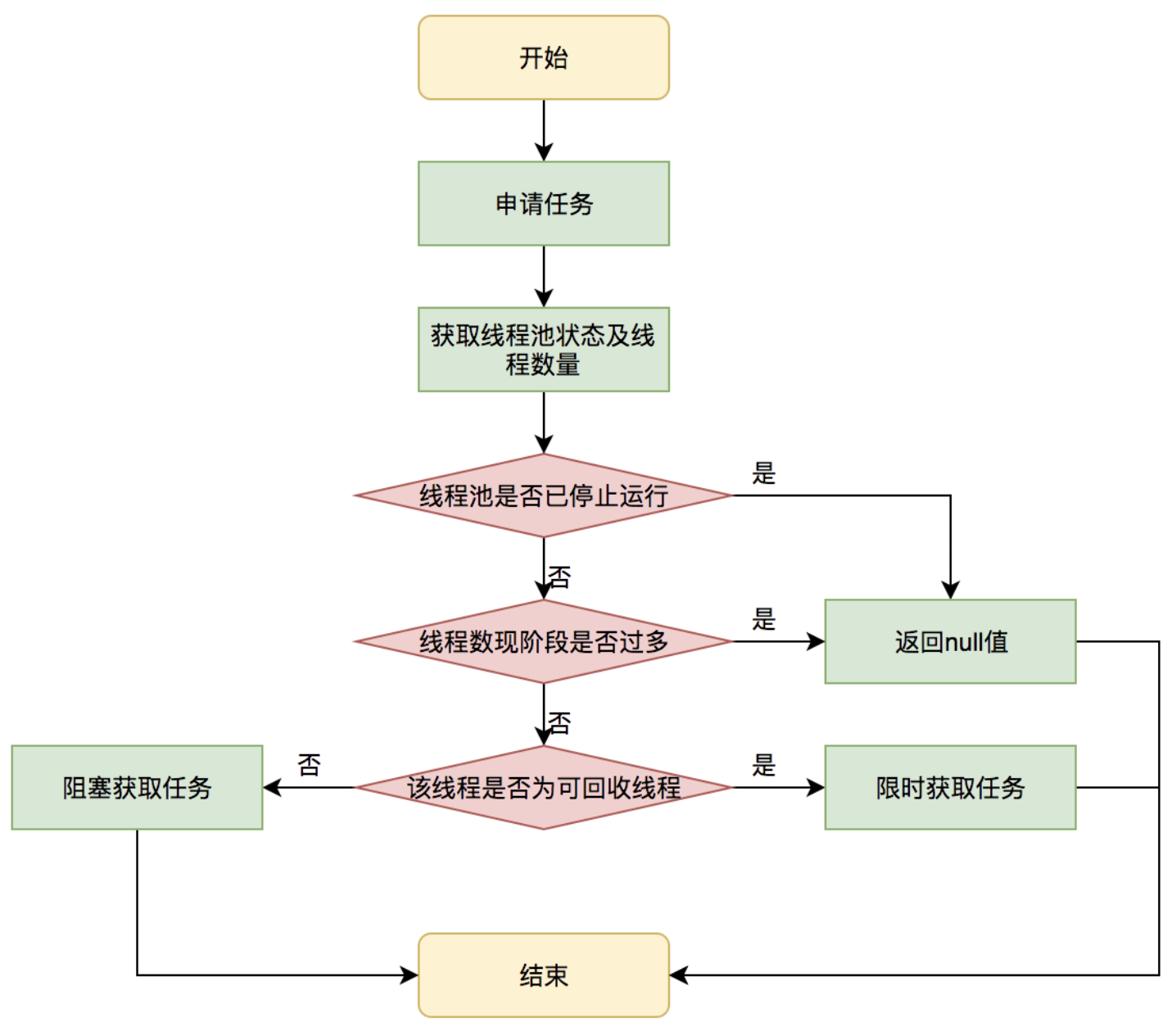
代码稍微有点长,分成两批解析:

常规队列维护,通过take()/poll()方法,阻塞/限时阻塞来获取任务。
任务拒绝-reject()
任务拒绝模块是线程池的保护部分,参考上面的代码,当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,可以采取任务拒绝策略,以保护线程池。
核心执行方法为:reject()

所以拒绝策略需要实现一个接口RejectedExecutionHandler,其设计如下:

核心是要实现rejectedExecution()方法。
除了我们自定义,JUC也提供了一些常用拒绝策略实现类,对比参考为:
| 对象 | 名称 | 描述 |
|---|---|---|
| AbortPolicy | 丢弃策略 | 丢弃任务 & 抛出异常。线程池默认拒绝策略。 |
| DiscardPolicy | 丢弃策略 | 丢弃任务,但是不抛出异常。 |
| DiscardOldestPolicy | 丢弃最老任务策略 | 丢弃队列最前面的任务(最老),然后重新提交被拒绝的任务。 |
| CallerRunsPolicy | 由调用线程来执行任务 | 直接阻塞,由提交任务的线程自己来执行该任务。 |
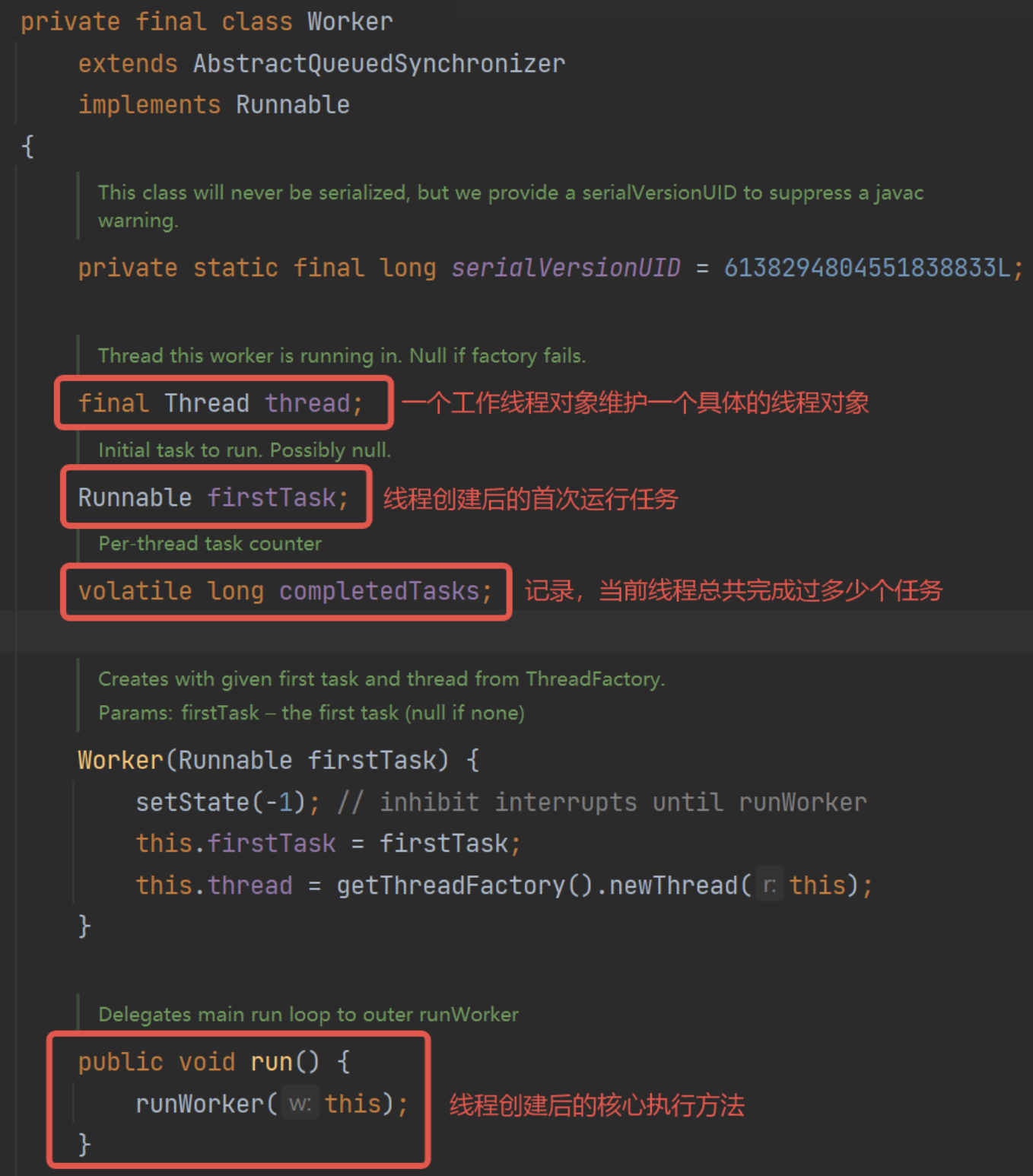
Worker-工作线程管理
线程池设计了内部类Worker,主要是用来管理新建的线程,除了监控,核心的方法是:
- 执行。
- 申请任务。
此外还包括回收等线程监控类型方法。
由于一个工作线程对象,其中有一个具体的线程,那么本质上是不需要加锁的。竞争资源是任务队列,而任务队列由阻塞队列来实现。
可以看Worker的设计:
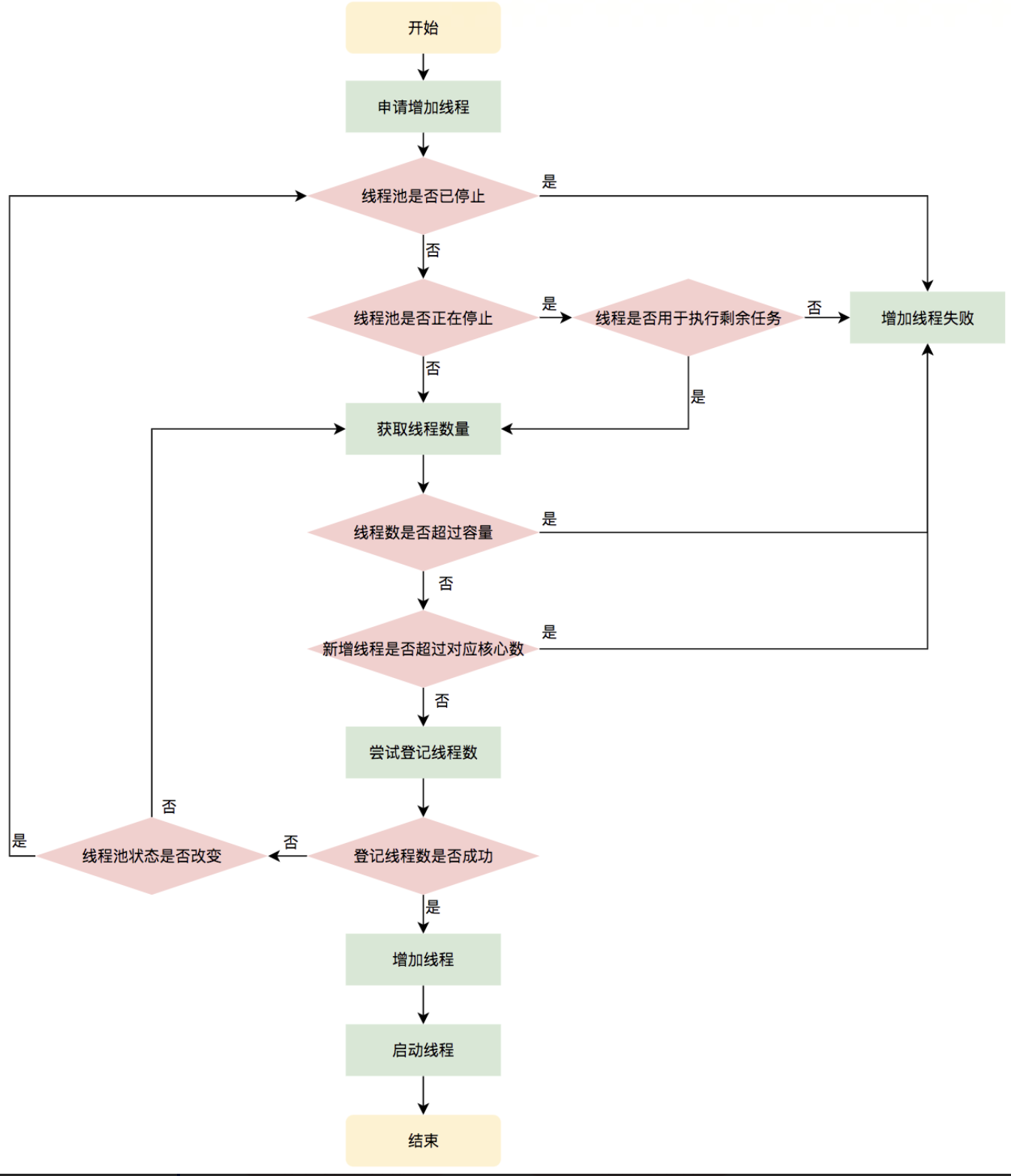
线程的创建-addWorker()
结合上面内容,任务在提交的时候,就是线程创建的时机,即核心方法:addWorker()
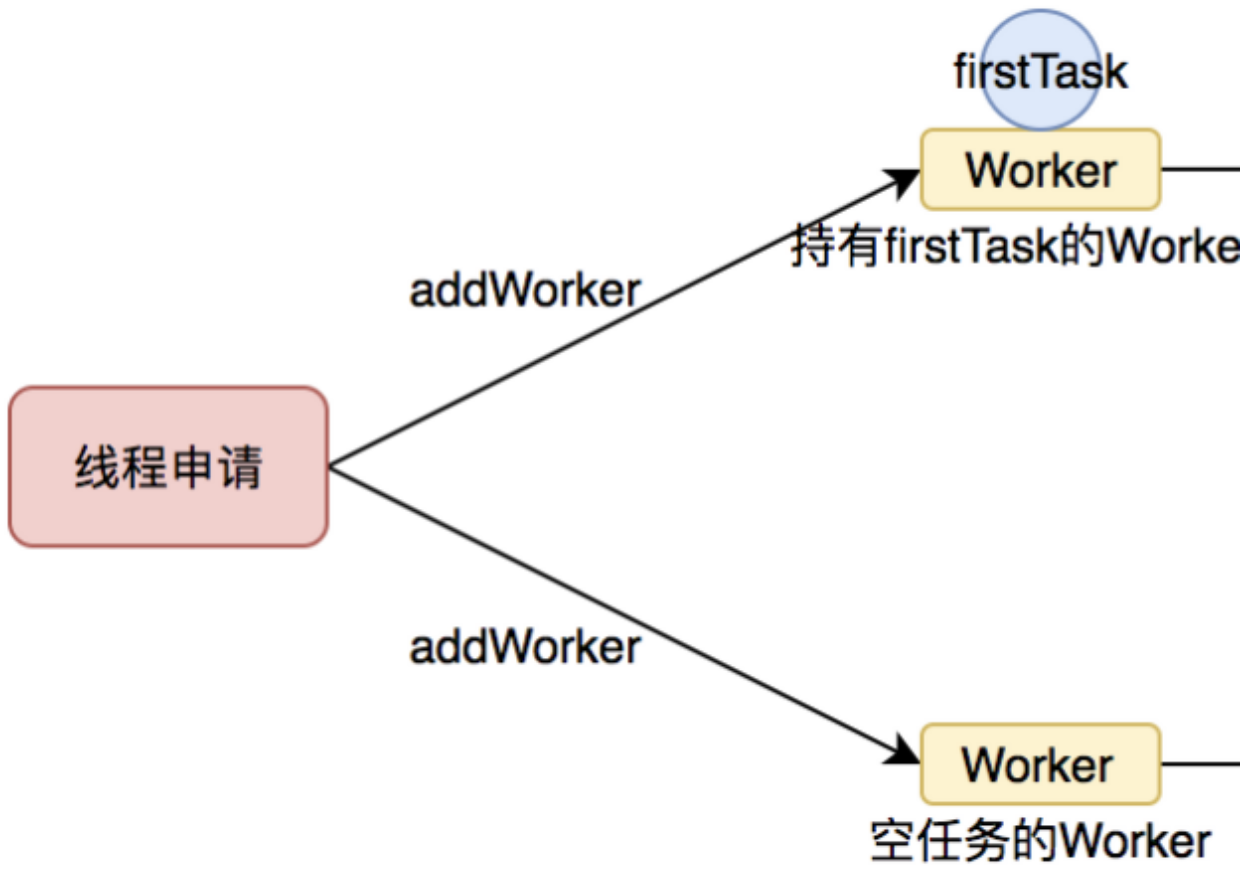
代码就不放了,主要是工作队列的维护。
需要注意的一点:addWorker()本身是不处理任何任务的。上面的流程图也可以看到,只截了一半,因为addWorker()本身只是新建一个工作线程,并不执行任何任务。
但是,其中的线程被创建后,会在addWorker()方法中start,开启Worker的真正的执行方法:run方法。
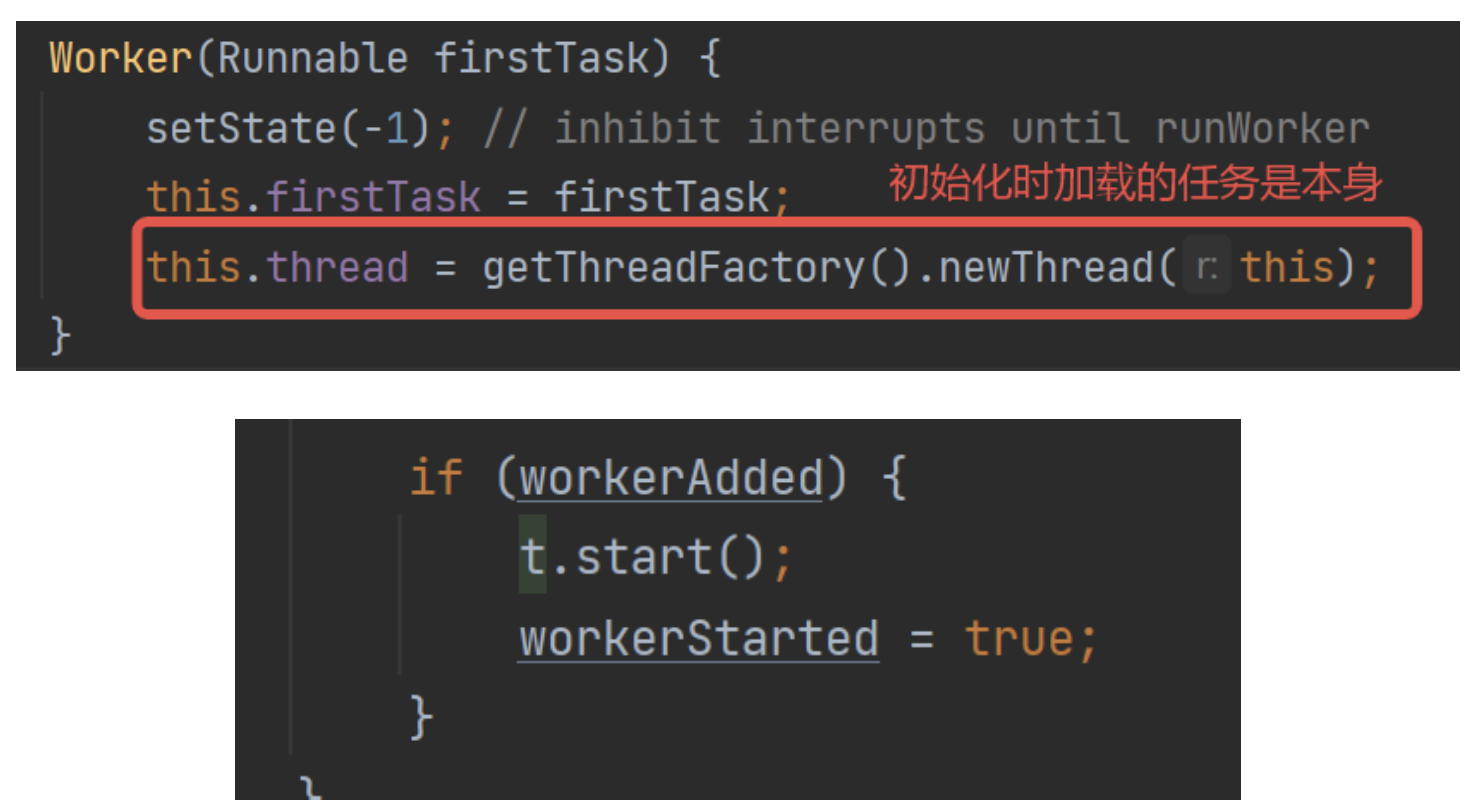
在工作队列全部维护结束后,start()方法开启任务,workerStarted=true,宣告工作线程真正执行起来。
线程工厂ThreadFactory
这里也是ThreadPoolExecutor的构造方法了,也可以看到上面的代码,一个线程的创建都是要走线程工厂的。
可以设定线程大量的数据。
一般是默认,可以看默认配置:

自定义的话,一般是设置一下daemon、线程name,或者有一些特殊操作。
目前个人用的不多。
工作线程的执行-runWorker()
上面可以知道,工作线程在创建之后,就直接开启任务开始执行了,那么Worker的run()方法就是工作线程核心执行方法,实际上就是:runWorker():
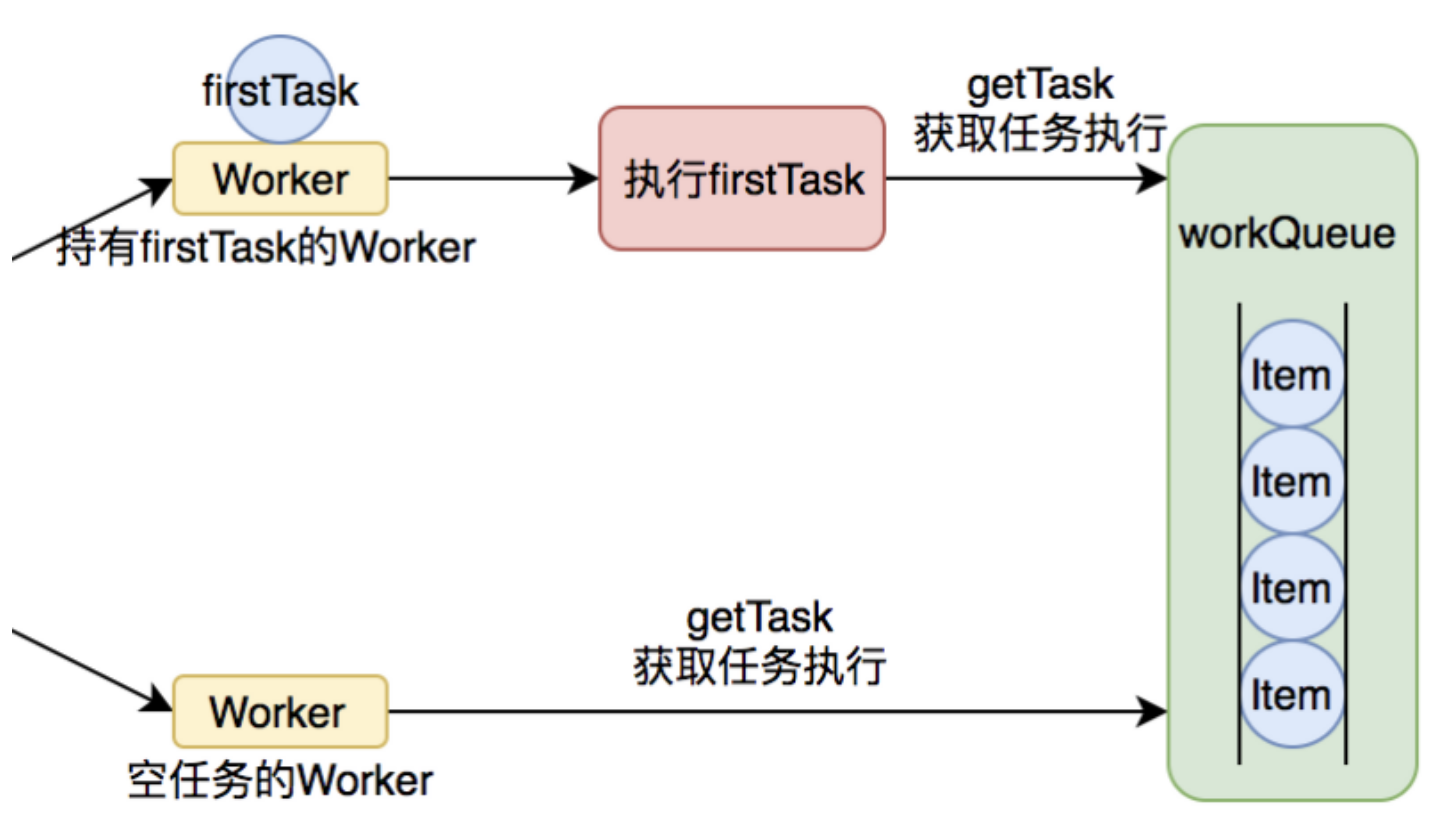
截图的后半部分,真正的执行。
核心方法是利用getTask()方法从工作队列中获取任务并执行。
那么这里看代码可以了解到firstTask的真正的意义:
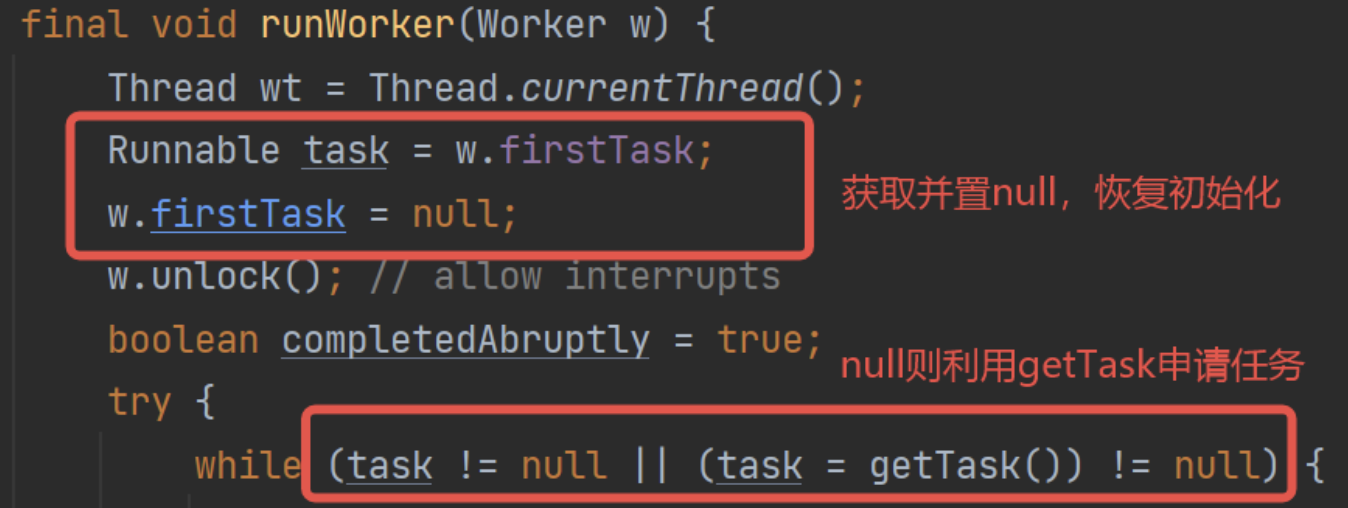
等于说firstTask,就是当前工作线程的待执行任务。如果待执行任务为null,就执行任务申请方法获取任务,反之则正常执行。
支持提前设置,从而实现:先执行这个任务,再从任务队列中获取。
这个设计猜测是例如定时任务线程池,会获取任务后设置到firstTask,但是不执行,等待时间到了才执行。
后面的执行没啥好说的。细节一点的图:
线程生命周期管理
线程池需要管理线程的生命周期,需要在线程长时间不运行的时候进行回收。
线程池使用一张Hash表去持有线程的引用,这样可以通过添加引用、移除引用这样的操作来控制线程的生命周期。

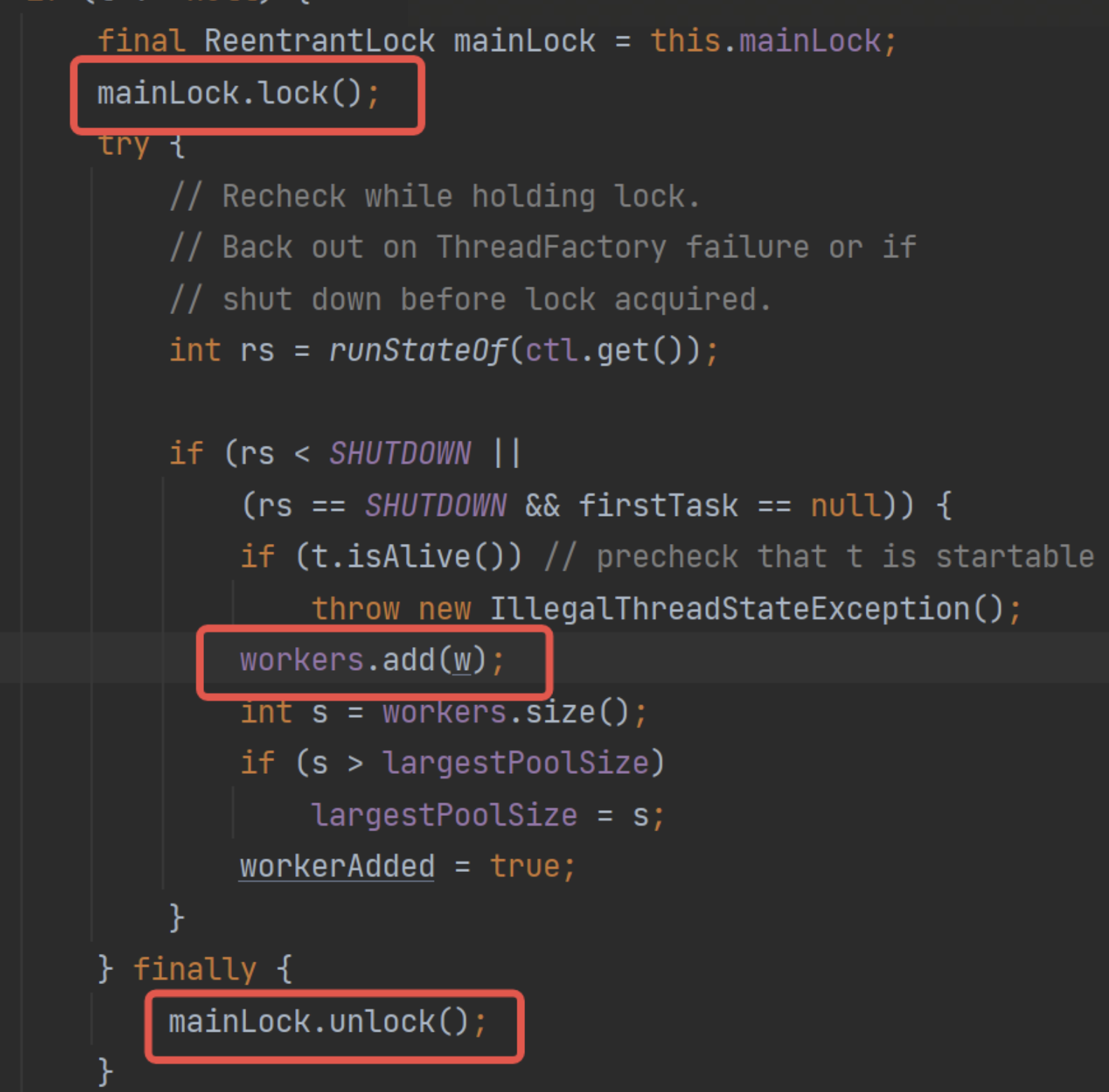
可以看到,workers是HashSet,那么问题来了,线程池有大量的工作线程,频繁创建/清除线程的时候,用线程不安全的HashSet必然是有并发安全问题的。
所以线程池要求在操作workers的时候,都需要获锁,根据该锁对workers进行操作:

也就是说,在工作线程的创建/销毁,都要加上这个锁,例如工作线程的创建:
工作线程的回收
这里比较复杂,慢慢聊。
工作线程自身锁
Worker对象其实本身就是一把锁。这是个细节,Worker本身是实现了AQS的:
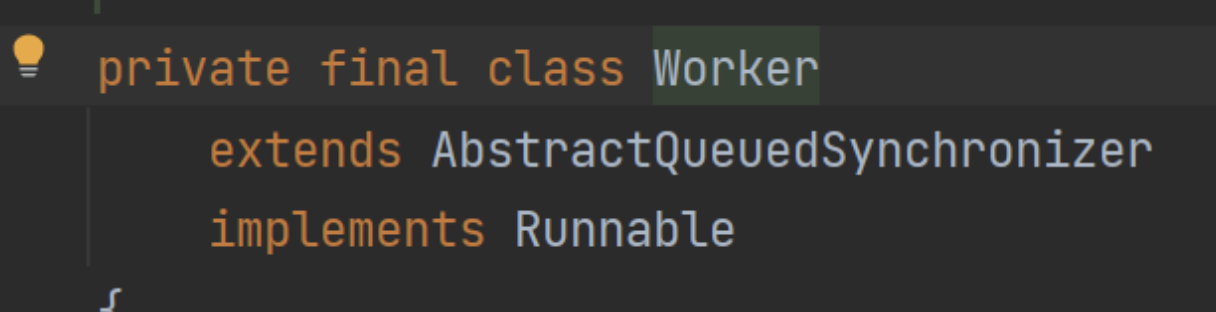
这里其实最主要的作用是工作线程的回收。虽然可以通过维护workers来完成对工作线程生命周期的管理,新建线程比较好理解,但是删除线程的时候,工作线程本身就是一种竞争资源了。回收的时候是可能恰好碰到调用的。
这里选择AQS的原因,其实可以看注释,这边简单翻译一部分:
Worker类存在的主要意义就是为了维护线程的中断状态。因为正在执行任务的线程是不应该被中断的。在线程真正开始运行任务之前,为了抑制中断。所以把 Worker 的状态初始化为负数-1。
完全看不懂,这里从其他角度慢慢绕过来解释一下。
线程的中断与回收
解释这个问题,首先看下Worker自身是从哪里调用锁的:
- 工作线程处理前后加锁。
- 工作线程尝试中断时尝试获锁。
第一个看代码runWorker():
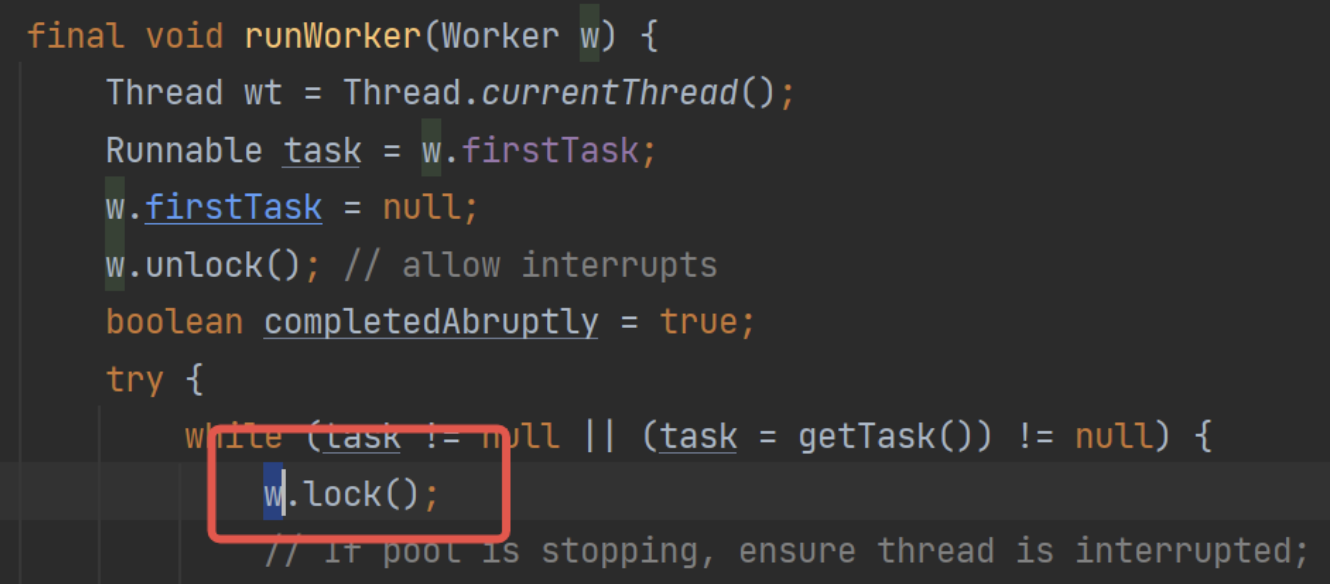
也就是说,当前线程如果在处理,那么本身是给自己加锁的。
第二个看代码interruptIdleWorkers():

这里是不是就有点恍然大悟的意思了。
工作线程本身实现AQS,将自身当作竞争对象。
那么工作线程工作的时候,加锁,锁住自己,那么interruptIdleWorkers()方法在执行的时候,如果能获取锁,就说明一个问题:此时当前线程是没有在工作的。那么就会被中断掉。
为了实现这个功能,就只能选择不可重入锁,所以自己实现了AQS来实现这个特性。具体可以看代码实现。
基本可以推测到,interruptIdleWorkers()这个方法就是回收方法,那么其调用时机是什么?
线程回收时机
一个重要的回收时机-keepAliveTime
这里单独拉出来聊了,比较经典。
八股文一般说:keepAliveTime是线程存活时间,如果当前线程池线程数量大于核心池的时候,如果一个线程超过keepAliveTime没有获取到任务,则会触发线程回收。
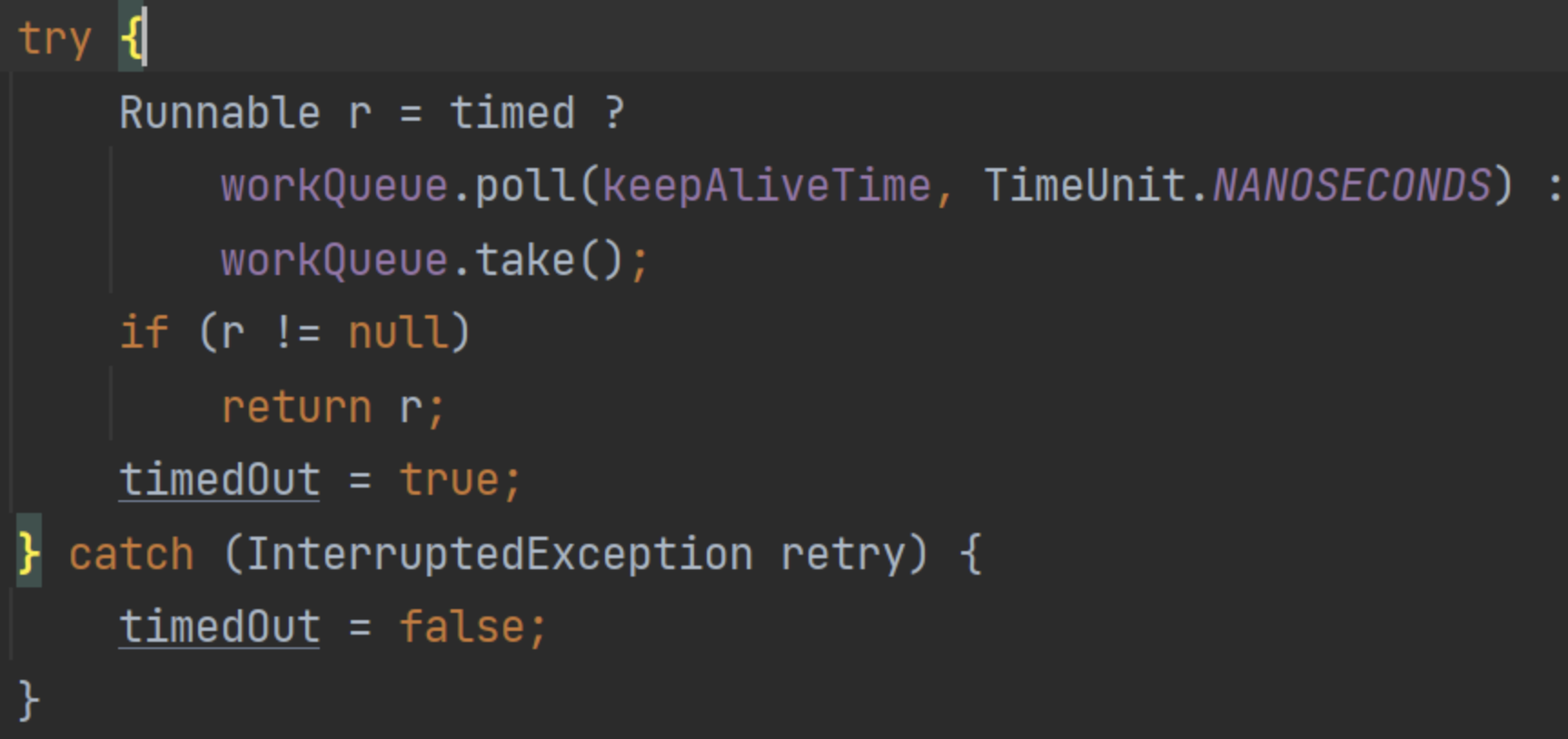
这里聊聊相关源码。首先看基础的任务申请:
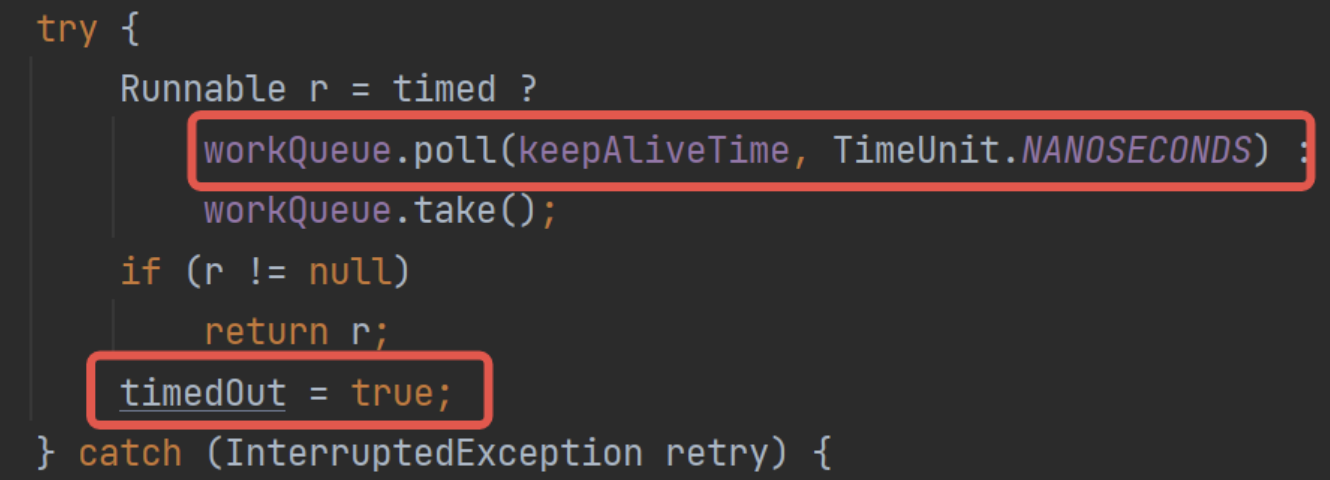
这里如果设置了超时时间的情况下,请求任务队列是调用的poll()方法,并指定了keepAliveTime。那么这个方法的意思就是,阻塞这么长时间,超过时间后直接返回null。
所以这里就对应到八股文了,如果此时poll()返回空,那么就是说当前队列里什么数据都没有,那么这里其实就是说明:该线程等待了keepAliveTime都没有获取到数据,也就是说这段时间全部是空闲。可以回收了。
而这里只是设置了timedOut标记,留给上层来处理:

这里判定之后返回个null。

直接跳出线程执行run()方法,在finally块中触发线程回收。processWorderExit()方法的底层就是下面的tryTerminate()了,会直接进行回收。
tryTerminate()

核心回收方法,根据其调用可以梳理出正常运行中的回收时机:
-
工作线程创建失败时:
addWorkerFailed()。 -
runWorker()方法退出时。正常来说runWorker()方法是一个自旋,只有在任务申请失败时才会退出自旋。那么这个时机就是指任务队列已经清空了:
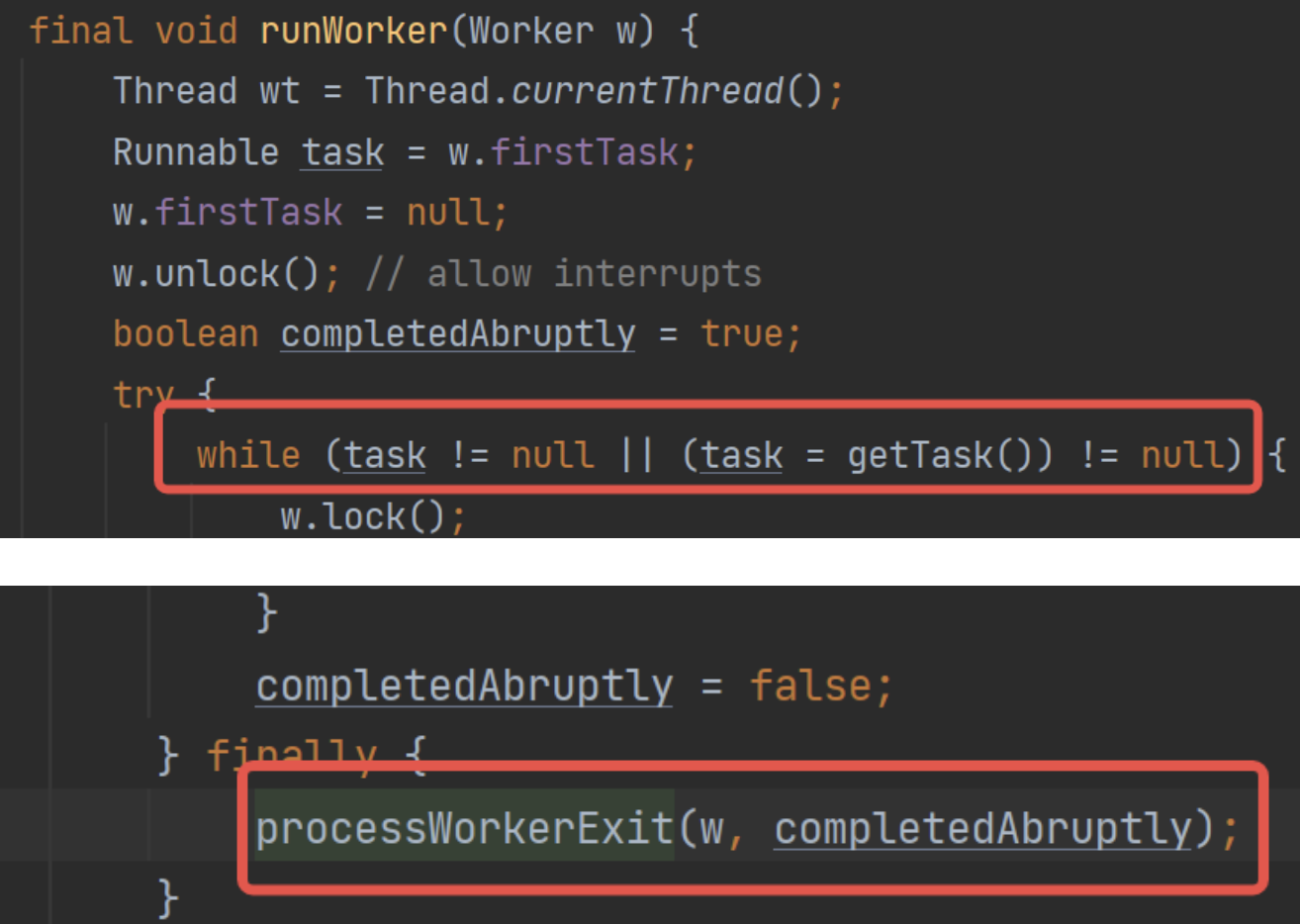
总体流程为:

-
shutdown()。可以看到执行了两次。
-
shutdownNow()。
-
remove(),移除任务时顺便执行一次。
-
purge(),todo。
interruptIdleWorkers
一般是针对线程池本身参数进行操作的时候,会触发回收,看其调用方式,可以梳理出来全部的线程回收时机:
- shutdown()。
- 设置核心池大小的时候,如果当前线程池线程数量大于核心池数量大小,执行一次回收:
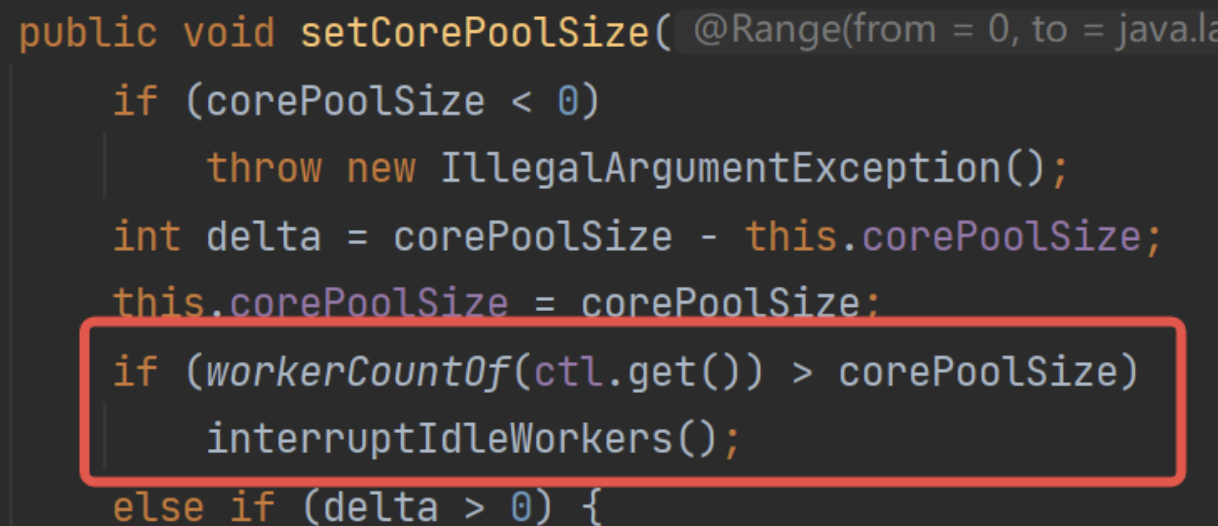
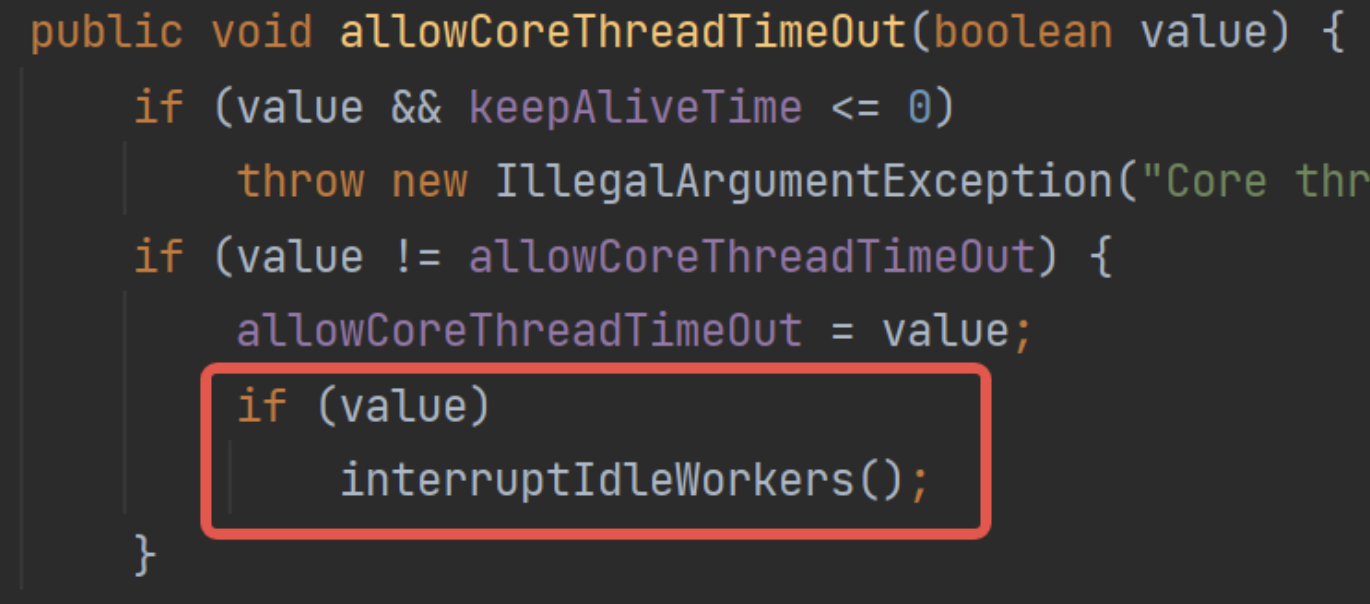
- 设置允许核心池超时时,执行一次回收:
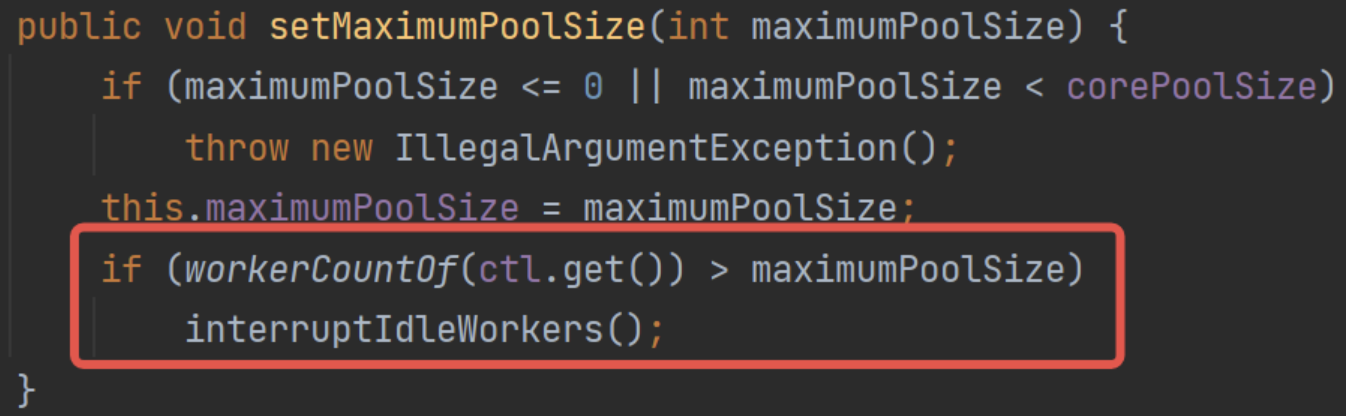
- 设置最大池数量时,如果当前线程池线程数量大于最大池数量,执行一次回收:
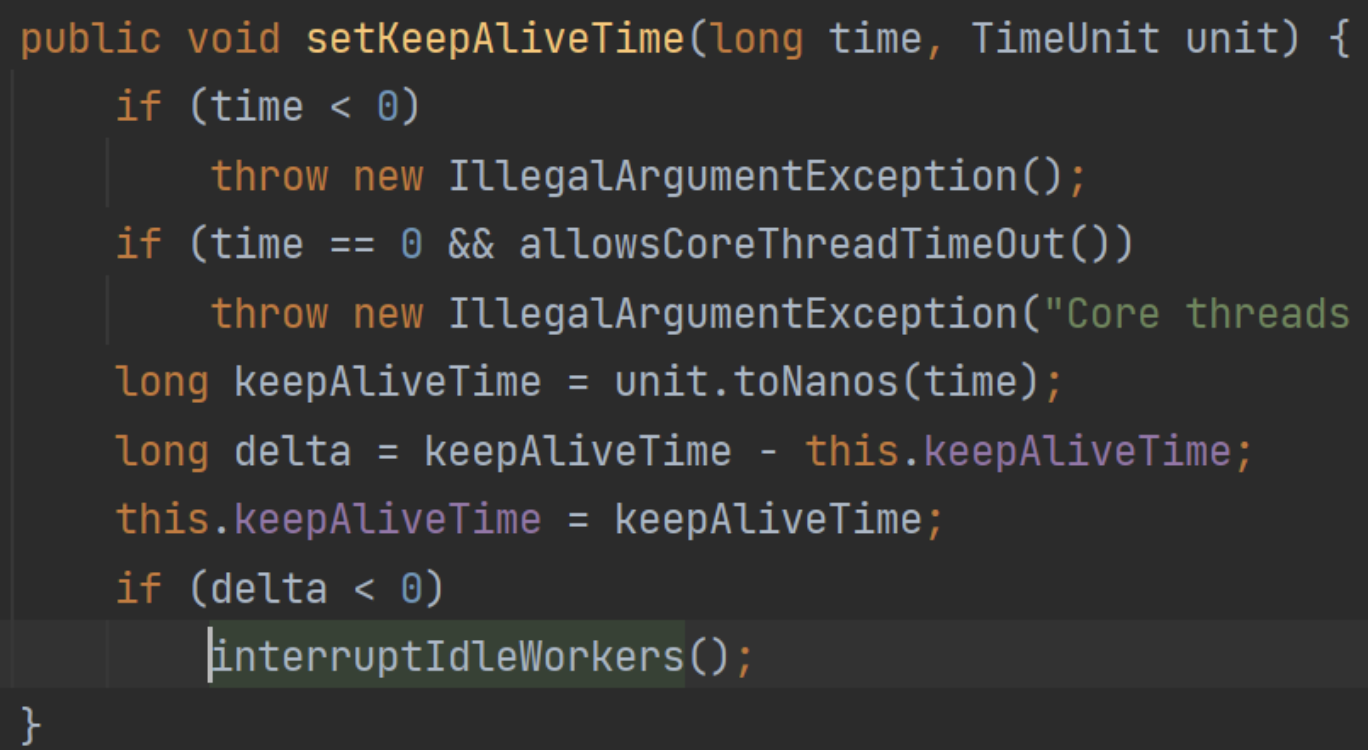
- 设置线程池线程存活时间时,如果设置变小了,那么执行一次回收:
不使用ReentrantLock和synchronized的原因
跟上面的逻辑一样,为啥要加锁,就是为了区分线程是否中断,而ReentrantLock和synchronized都有一个重要特性:可重入。因为可重入,那么这个锁就没有意义了,因为线程都是一个,既然可重入那么就是必然能获锁了。
所以选用AQS,手动删掉可重入的特性,实现互斥。
tryAcquire实现不可重入
也可以看看重写AQS的获锁代码:
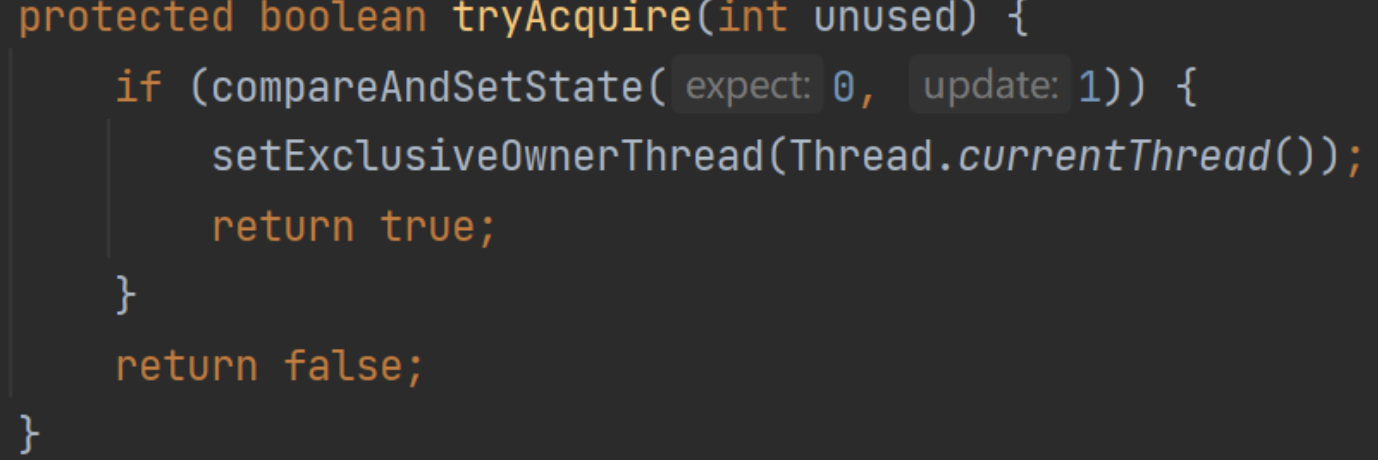
虽然设置的excluiveOwnerThread,但是完全不用,就是直接CAS获锁,没有重入的特性。
总结
综上,可以简单给出一个大致的回收流程:
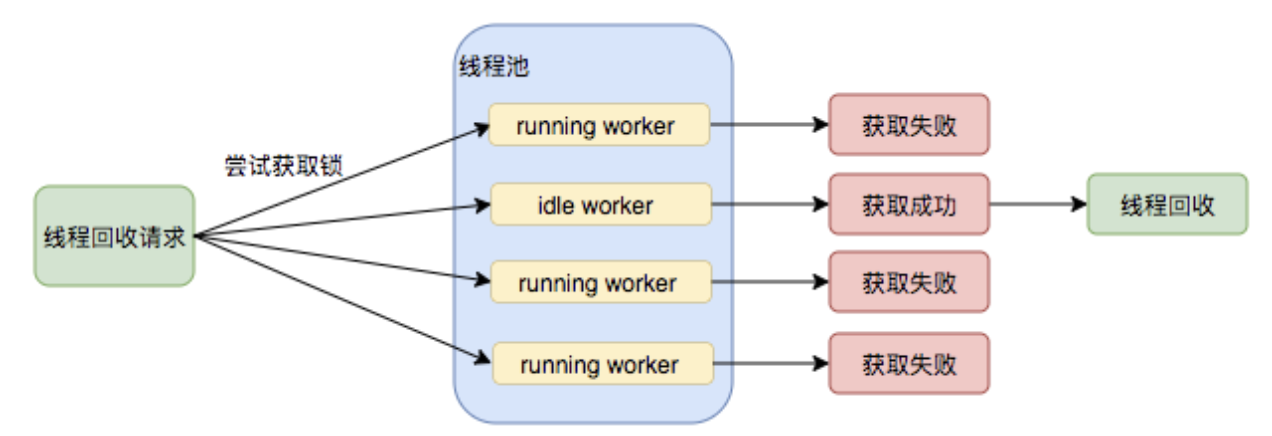
而回收请求执行时机:
- 任务队列空。
- shutdown()等线程池关闭任务。
- 线程池变量更改的时候,例如核心池大小变更等。
- 任务移除。
- purge(),todo。
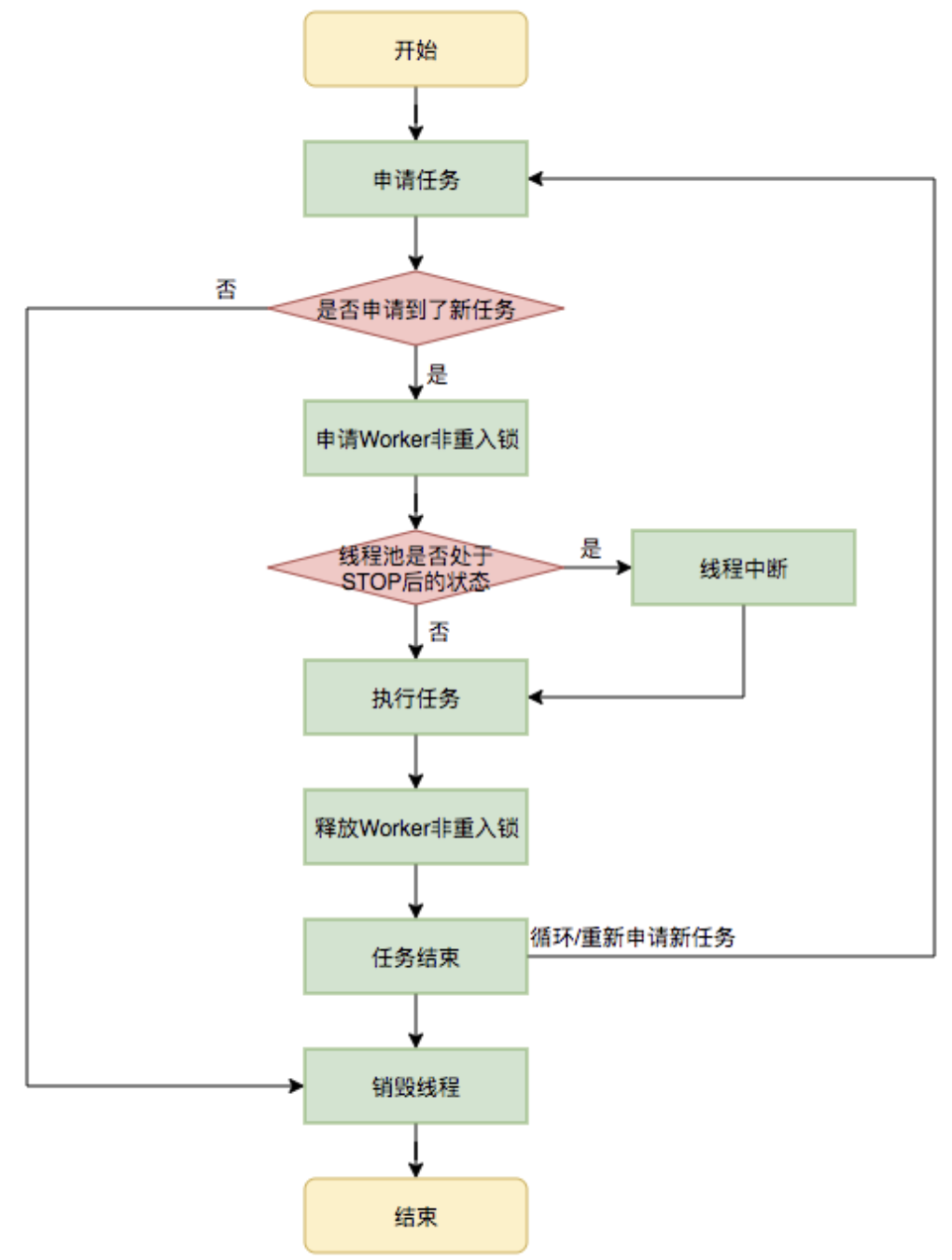
runWorker()方法的总结
也算是工作队列核心的总结吧:
线程池设置核心池和最大池的原因
个人理解了。
假设核心池数量为15,最大池数量为20。
线程的创建和销毁是很重的操作,所以线程池本意是想在核心池中的线程都能正常使用,偶尔使用最大池。
- 房子装修,一般来说聘15个工人,3天完成工作。
- 那么每天的工作量不一定,也有可能运水泥瓷砖的人不给力,导致今天工期延缓
- 但是不管怎样,3天左右或快或慢基本都能干完
- 运材料的人或多或少,每天都是15人份左右的装修材料。
那么就认为这15个工人是核心池,即完成任务基本就是需要这么些人,可以少点但不能多。
- 房子装修,这次设计的比较简单,13个人,3天完成工作。
- 那么多出来的两个人,要么找点别的活先干着。实在没活,就直接跑路了,也没啥好待的。
等于说核心池的线程释放。
- 房子装修,这次设计的比较复杂,15个人,干了一天后觉得不行,干不完了
- 老板为了不延期,说好的3天就3天,那么就临时加人手
- 花钱雇新工程师,让17个人,勉强3天干完。
等于说核心池线程不够用,则依旧可以创建线程。
- 老板也要挣钱,再让我快,我都不挣钱了,自然不会给你再增加工人,就这样凑合吧。
等于说达到了最大线程池。
那么keepAliveTime也是衍生出来的配置,控制线程空闲后多长时间后自动回收。
线程池数量设置方法论
这个跟业务相关,一般是跟着业务一起调整,包括实际上线之后的调整。刚开始可能也只是设计一个大概值。
本质上,一个任务可以区分成CPU密集型任务和I/O密集型任务。
-
CPU密集型任务。
- 需要大量CPU计算。
- 所以大量的切换上下文非常影响性能,最好一个时间片内执行完毕。
- 那么这种情况下,如果线程数量给的太大,会导致CPU大量轮询,每个时间片给的也少。
- 所以CPU密集型任务尽量保证CPU核心数量和线程数量一致,减少上下文切换的损耗。
- 所以线程数量比CPU核心数量稍高或者相等相对会好一点。
- 需要大量CPU计算。
-
IO密集型任务(操作数据库也算IO)。
- 可能会阻塞。
- CPU可能会长时间空转,等待IO操作。
- 所以恰恰相反,这种任务需要设置很多线程,IO等待的时候不要让CPU闲着,去处理其他线程,提高吞吐量。
- 可以考虑线程数量是核心数量的两倍。
-
混合型任务。
- 这种就是取个中间值。
- 建议做好区分,分开处理。
美团遇到的问题
Java线程池实现原理及其在美团业务中的实践 - 美团技术团队 (meituan.com)
这篇文章有一些详细案例,可以看看。
线程池大小预估错误
比较常见,核心池最大池数量较小,从而导致触发拒绝策略。
但是不能太大,并发量太高可能会打挂下游。
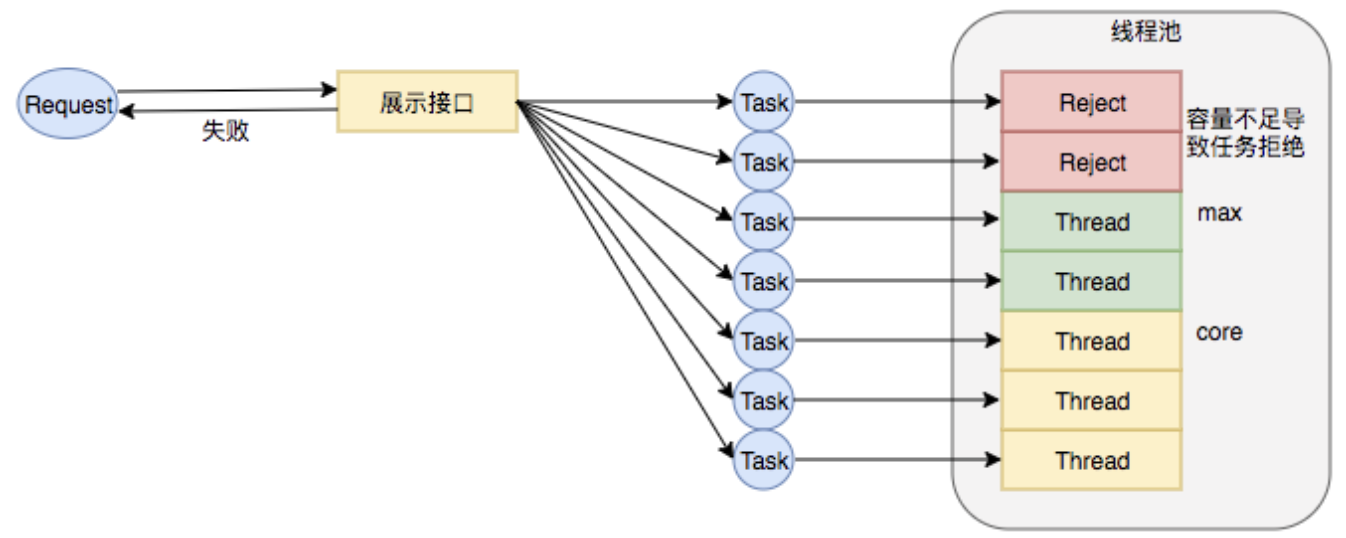
线程池任务堆积
一方面是没有设置好量,容量太大,导致大量任务堆积,或者没有预估到任务RT可能会很高,瞬间就大量堆积。
而此时如果业务本身要求RT较低,那么整个方法接口就会因为堆积,持续发生大量超时。









![[深入理解DDR] 总目录](https://img-blog.csdnimg.cn/direct/8d31fad7a28745eb81e253606f226423.png#pic_center)