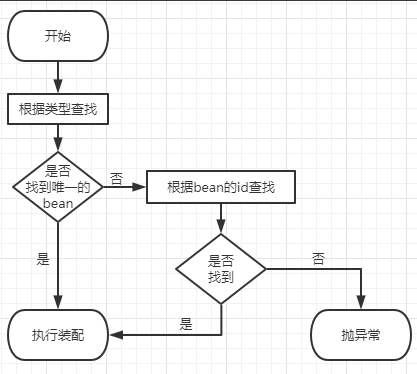
1. 指针和数组
数组指针 和 指针数组
int* p1[10]; // 指针数组int (*p2)[10]; // 数组指针因为 [] 的优先级比 * 高,p先和 [] 结合说明p是一个数组,p先和*结合说明p是一个指针
括号保证p先和*结合,说明p是一个指针变量,然后指着指向的是一个大小为10个整型的数组。所以p是一个 指针,指向一个数组,叫数组指针。
arr和&arr的区别
arr代表数组首元素的地址,&arr代表整个数组的地址
void test(int(*arr)[10], int size) // 这里arr也是整个数组的数组指针{for (int i = 0; i < size; ++i){cout << ((int*)arr)[i] << " ";}cout << endl;}int main(){int arr[10] = { 0 };int(*p)[10] = &arr; // 数组指针需要指整个数组test(p, 10);return 0;}二维数组传参
void test(int arr[3][5])//ok?{}void test(int arr[][])//ok? X{}void test(int arr[][5])//ok?{}// 总结:二维数组传参,函数形参的设计只能省略第一个[]的数字。// 因为对一个二维数组,可以不知道有多少行,但是必须知道一行多少元素。这样才方便运算。void test(int* arr)//ok?X{}void test(int* arr[5])//ok?{}void test(int(*arr)[5])//ok?arr是指向一个大小为5的一维数组{}void test(int** arr)//ok?{}int main(){int arr[3][5] = { 0 };test(arr);}函数指针
保存函数的地址:函数指针
#include <stdio.h>void test(){}int main(){printf("%p\n", test);printf("%p\n", &test); // 一样cout << typeid(test).name() << endl; // void __cdecl(void) 函数名cout << typeid(&test).name() << endl; // void (__cdecl*)(void) 函数指针void(*p1)(void) = test;void(*p2)(void) = &test; // 一样的return 0;}函数指针数组
typedef void(*handler)(void);int main(){handler arr[12] = { 0 };void(*arr1[12])(void) = { 0 };}const和指针
const修饰的指针变量:
-
const位于*前的,表示指针指向的对象内容无法修改,p指向的空间内容(指向对象的内容)无法修改
-
const位于*后面的,表示指针指向的位置无法修改,p的内容(保存的对象地址)无法修改
const int* p = nullptr;int const* p = nullptr;int* const p = nullptr;sizeof和指针,数组/strlen和指针,数组
sizeof是根据对象的类型判断大小,但是有一个特殊处理就是数组名,sizeof(数组名)
-
sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小
-
&数组名,这里的数组名表示整个数组,取出的是整个数组的地址
-
除此之外所有的数组名都表示首元素的地址
-
但是参数数组也是一个特殊的存在,当数组作为参数进行传递的时候,数组其实退化成了指针
//一维数组int a[] = {1,2,3,4};printf("%d\n",sizeof(a)); // 16printf("%d\n",sizeof(a+0)); // 4/8printf("%d\n",sizeof(*a)); // 4 printf("%d\n",sizeof(a+1)); // 4/8printf("%d\n",sizeof(a[1])); // 4printf("%d\n",sizeof(&a)); // 4/8printf("%d\n",sizeof(*&a)); // 16(*和&抵消了)printf("%d\n",sizeof(&a+1)); // 4/8printf("%d\n",sizeof(&a[0])); // 4/8printf("%d\n",sizeof(&a[0]+1)); // 4/8// 字符数组char arr[] = {'a','b','c','d','e','f'}; // 6个 系统不会给最后补0 ""这样赋值才行printf("%d\n", sizeof(arr)); // 6printf("%d\n", sizeof(arr+0)); // 4/8printf("%d\n", sizeof(*arr)); // 1printf("%d\n", sizeof(arr[1])); // 1printf("%d\n", sizeof(&arr)); // 4/8printf("%d\n", sizeof(&arr+1)); // 4/8printf("%d\n", sizeof(&arr[0]+1)); // 4/8printf("%d\n", strlen(arr)); // 未知printf("%d\n", strlen(arr+0)); // 未知printf("%d\n", strlen(*arr)); // 错误printf("%d\n", strlen(arr[1])); // 错误printf("%d\n", strlen(&arr)); // 报错printf("%d\n", strlen(&arr+1)); // 报错,因为&arr的类型char(*)[6]printf("%d\n", strlen(&arr[0]+1)); // 未知 优先级 [] > * > &char arr[] = "abcdef"; // 7个 最后补0printf("%d\n", sizeof(arr)); // 7printf("%d\n", sizeof(arr+0)); // 4/8printf("%d\n", sizeof(*arr)); // 1printf("%d\n", sizeof(arr[1])); // 1printf("%d\n", sizeof(&arr)); // 4/8printf("%d\n", sizeof(&arr+1)); // 4/8printf("%d\n", sizeof(&arr[0]+1)); // 4/8printf("%d\n", strlen(arr)); // 6printf("%d\n", strlen(arr+0)); // 6printf("%d\n", strlen(*arr)); // 报错printf("%d\n", strlen(arr[1])); // 报错printf("%d\n", strlen(&arr)); // 报错printf("%d\n", strlen(&arr+1)); // 报错printf("%d\n", strlen(&arr[0]+1)); // 5const char *p = "abcdef"; // 最后会补'\0'printf("%d\n", sizeof(p)); // 4/8printf("%d\n", sizeof(p+1)); // 4/8printf("%d\n", sizeof(*p)); // 1printf("%d\n", sizeof(p[0])); // 1printf("%d\n", sizeof(&p)); // 4/8printf("%d\n", sizeof(&p+1)); // 4/8printf("%d\n", sizeof(&p[0]+1)); // 4/8printf("%d\n", strlen(p)); // 6printf("%d\n", strlen(p+1)); // 5printf("%d\n", strlen(*p)); // 报错printf("%d\n", strlen(p[0])); // 报错printf("%d\n", strlen(&p)); // 报错printf("%d\n", strlen(&p+1)); // 报错printf("%d\n", strlen(&p[0]+1)); // 5//二维数组int a[3][4] = {0};printf("%d\n",sizeof(a)); // 48printf("%d\n",sizeof(a[0][0])); // 4printf("%d\n",sizeof(a[0])); // 16printf("%d\n",sizeof(a[0]+1)); // 4/8 (指针) a[0][1]// 这里a[0] 表示a的首个元素,因为sizeof的特殊所以被当成整个数组大小 +1 后这个特殊就没了printf("%d\n",sizeof(*(a[0]+1))); // 4printf("%d\n",sizeof(a+1)); // 4/8printf("%d\n",sizeof(*(a+1))); // 4/8X 16 a[1]printf("%d\n",sizeof(&a[0]+1)); // 4/8 printf("%d\n",sizeof(*(&a[0]+1))); // 4X 16 a[1]printf("%d\n",sizeof(*a)); // 4/8X 16 a[0]printf("%d\n",sizeof(a[3])); // 4/8X 16总结:先看类型再判断
2. 库函数的模拟实现
memcpy
void* memcpy(void* dest, const void* src, size_t num){assert(dest && src);char* d = (char*)dest;const char* s = (const char*)src;while (num--){*d++ = *s++;}return dest;}注意:c++使用括号强转类型,生成的是临时变量,不能进行++
memmove
void* memmove(void* dest, const void* src, size_t num){assert(dest && src);char* d = static_cast<char*>(dest);const char* s = static_cast<const char*>(src);while (num--){if (dest < src){*d++ = *s++;}else{*((char*)(d + num)) = *(s + num); // 这里根据num的减少来推进}}return dest;}strstr
// 从目的字符串中找src字符串static char* strstr(const char* dest, const char* src){assert(dest && src);const char* left = dest, * right = dest;const char* cur = src;while (true){while (*left != '\0' && *left != *cur) left++;if (*left == '\0')break;// *left == *curright = left;while (*right == *cur){right++;cur++;if (*cur == '\0')return const_cast<char*>(left);}cur = src; // cur 回执left++;}return nullptr;}memset/strcmp
void* memset(void* ptr, int val, size_t num){assert(ptr);char* cur = static_cast<char*>(ptr);while (num--){*cur++ = val;}return ptr;}int strcmp(const char* str1, const char* str2){assert(str1 && str2);while (*str1 != '\0' && *str2 != '\0' && *str1++ == *str2++);//if (*str1 < *str2)// return -1;//else if (*str1 > *str2)// return 1;//else return 0;return *str1 - *str2;}3. 自定义类型
内存对齐规则
-
第一个成员在与结构体变量偏移量为0的地址处。
-
其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
-
结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
-
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
对齐数 = 编译器默认的一个对齐数(VS下是8) 与 该成员大小的较小值
联合体
联合也是一种特殊的自定义类型 这种类型定义的变量也包含一系列的成员,特征是这些成员公用同一块空间(所以联合也叫共用体)
联合的成员是共用同一块内存空间的,这样一个联合变量的大小,至少是最大成员的大小(因为 联合至少得有能力保存最大的那个成员)
联合大小的计算:
联合的大小至少是最大成员的大小,当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍
4. 整形的存储规则
原码/反码/补码
计算机中的有符号数有三种表示方法,即原码、反码和补码
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位三种表示方法各不相同
-
原码:直接将二进制按照正负数的形式翻译成二进制就可以
-
反码: 将原码的符号位不变,其他位依次按位取反就可以得到了
-
补码: 反码+1就得到补码
正数的原、反、补码都相同
对于整形来说:数据存放内存中其实存放的是补码
大小端
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中(高低)
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,保存在内存的高地址中(高高)
如何判断:
#include <stdio.h>int check_sys(){int i = 1;return (*(char *)&i);}int main(){int ret = check_sys();if(ret == 1)printf("小端\n");elserintf("大端\n");return 0;}//代码2int check_sys(){union{int i;char c;}un;un.i = 1;return un.c;}5. 编译链接
宏
#define 替换规则 在程序中扩展#define定义符号和宏时,需要涉及几个步骤:
-
在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们首先被替换。
-
替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值替换。
-
最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上述处理过程。
注意:
-
宏参数和#define 定义中可以出现其他#define定义的变量。但是对于宏,不能出现递归
-
当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。
也就是说"宏"只会被当成字符串,宏不会生效,这时#宏:把一个宏参数变成对应的字符串
#include <stdio.h>#define PRINT1(FORMAT, VALUE) \printf("the value is "FORMAT"\n", VALUE)#define PRINT2(FORMAT, VALUE) \printf("the value of "#VALUE" is "FORMAT"\n", VALUE) // yes//printf("the value of ""VALUE"" is "FORMAT"\n", VALUE) // noint main(){char a = -1;signed char b = -1;unsigned char c = -1;printf("a=%d,b=%d,c=%d\n", a, b, c); // 对齐 -1 -1 255printf("file:%s\n line:%d\n time:%s\n", __FILE__, __LINE__, __TIME__);const char* p = "hello ""bit\n"; // 字符串合并printf("%s\n", p);PRINT1("%d", 10);PRINT2("%d", 10);return 0;}可以把位于它两边的符号合成一个符号。 它允许宏定义从分离的文本片段创建标识符
#define OFFSETOF(struct_name, member_name) \((size_t)&(((struct_name*)0)->member_name))// 获取成员变量的偏移量宏的优缺点:
优点
-
用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多。所以宏比函数在程序 的规模和速度方面更胜一筹。
-
更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之这个宏怎可 以适用于整形、长整型、浮点型等可以用于>来比较的类型。宏是类型无关的。(C++模板)
缺点
-
每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
-
宏是没法调试的。
-
宏由于类型无关,也就不够严谨。
-
宏可能会带来运算符优先级的问题,导致程序容易出现错。
#undef 于移除一个宏定义
gcc -D ARRAY_SIZE=10 programe.c // 命令行宏定义
条件编译
#if defined(OS_UNIX) #ifdef OPTION1 unix_version_option1(); #elif defined(OPTION2)unix_version_option2(); #elseunix_version_option3(); #endif #elif defined(OS_MSDOS) #ifdef OPTION2 msdos_version_option2(); #endif #endif编译链接过程



![[无广告!纯干货]免费用CodeFlying自动化生成一个专属的AI机器人](https://img-blog.csdnimg.cn/direct/25ab0ab3ed744499b43a962d5b584b99.jpeg)
![[数据集][目标检测]游泳者溺水检测数据集VOC+YOLO格式8275张4类别](https://i-blog.csdnimg.cn/direct/b5b325b3696d47c5a7c5b07a407b8d66.png)