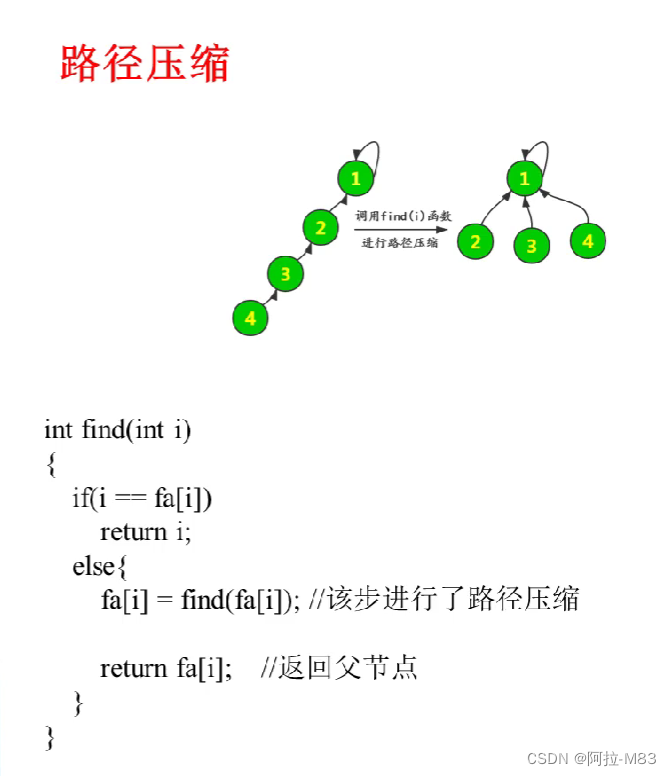
1 介绍
- PEFT 提供了参数高效的方法来微调大型预训练模型。
- 传统的范式是为每个下游任务微调模型的所有参数,但由于当前模型的参数数量巨大,这变得极其昂贵且不切实际。
- 相反,训练较少数量的提示参数或使用诸如低秩适应 (LoRA) 的重新参数化方法来减少可训练参数数量是更有效的
2 训练
2.1 加载并创建 LoraConfig 类
- 每种 PEFT 方法都由一个 PeftConfig 类定义,该类存储了构建 PeftModel 的所有重要参数
- eg:使用 LoRA 进行训练,加载并创建一个 LoraConfig 类,并指定以下参数
- task_type:要训练的任务(在本例中为序列到序列语言建模)
- inference_mode:是否将模型用于推理
- r:低秩矩阵的维度
- lora_alpha:低秩矩阵的缩放因子
- lora_dropout:LoRA 层的丢弃概率
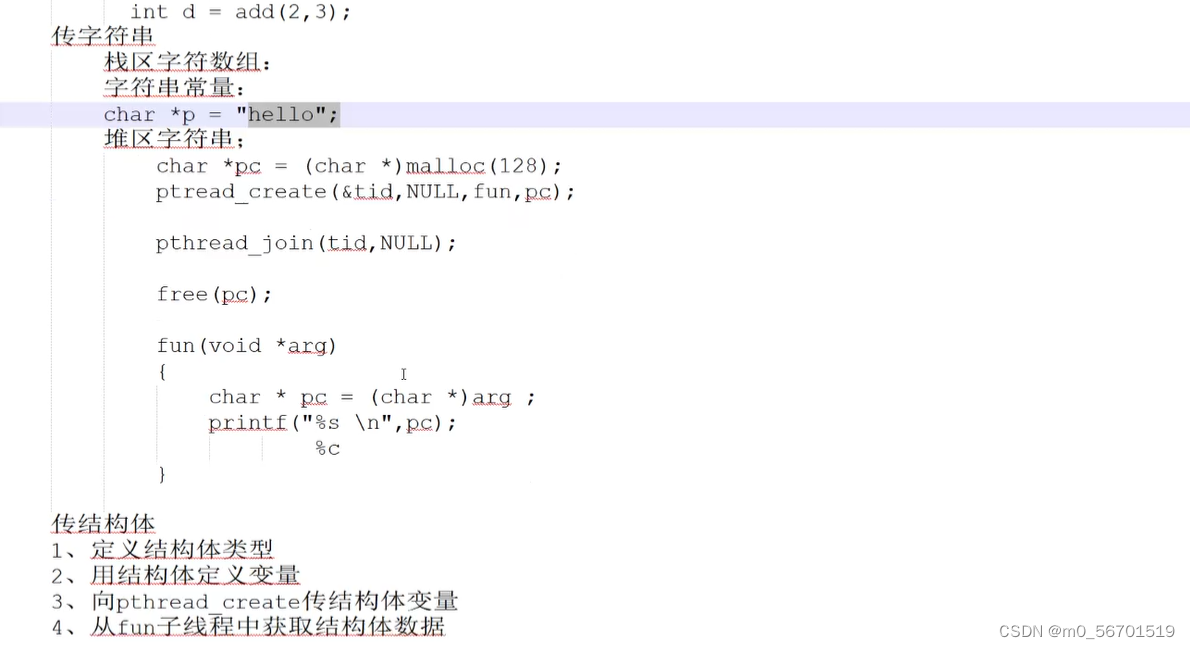
from peft import LoraConfig, TaskTypepeft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
2.2 创建 PeftModel
- 一旦设置了 LoraConfig,就可以使用 get_peft_model() 函数创建一个 PeftModel
- 需要一个基础模型 - 可以从 Transformers 库加载 -
- 以及包含如何配置 LoRA 模型参数的 LoraConfig
2.2.1 加载需要微调的基础模型
from transformers import AutoModel,AutoTokenizer
import os
import torchos.environ["HF_TOKEN"] = '*'
#huggingface的私钥tokenizer=AutoTokenizer.from_pretrained('meta-llama/Meta-Llama-3-8B')
model=AutoModel.from_pretrained('meta-llama/Meta-Llama-3-8B',torch_dtype=torch.bfloat16, low_cpu_mem_usage=True)2.2.2 创建 PeftModel
将基础模型和 peft_config 与 get_peft_model() 函数一起包装以创建 PeftModel
from peft import get_peft_modelmodel = get_peft_model(model, peft_config)
model.print_trainable_parameters()
#了解模型中可训练参数的数量
#trainable params: 3,407,872 || all params: 7,508,332,544 || trainable%: 0.0454之后就可以train了
3保存模型
模型训练完成后,可以使用 save_pretrained 函数将模型保存到目录中。
model.save_pretrained("output_dir")4 推理
- 使用 AutoPeftModel 类和 from_pretrained 方法加载任何 PEFT 训练的模型进行推理
- 对于没有明确支持 AutoPeftModelFor 类的任务,可以使用基础的 AutoPeftModel 类加载任务模型
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torchmodel = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
#LORA过的模型
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
#普通的tokenizermodel.eval()
inputs = tokenizer("Preheat the oven to 350 degrees and place the cookie dough", return_tensors="pt")outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=50)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])# "Preheat the oven to 350 degrees and place the cookie dough in the center of the oven. In a large bowl, combine the flour, baking powder, baking soda, salt, and cinnamon. In a separate bowl, combine the egg yolks, sugar, and vanilla."
5LoraConfig主要参数
| r (int) | LoRA 注意力维度(“秩”) 【默认8】 |
| target_modules | 应用适配器的模块名称。
【默认None] |
| lora_alpha | LoRA 缩放的 alpha 参数 【默认8】 |
| lora_dropout | LoRA 层的 dropout 概率 【默认0】 |
| fan_in_fan_out | 如果要替换的层存储权重为 (fan_in, fan_out),则设置为 True 例如,GPT-2 使用 Conv1D,它存储权重为 (fan_in, fan_out),因此应设置为 True |
| bias | LoRA 的偏置类型。可以是 'none'、'all' 或 'lora_only'。 如果是 'all' 或 'lora_only',则在训练期间将更新相应的偏置 |
| use_rslora |
|
| modules_to_save | 除适配器层外,在最终检查点中设置为可训练和保存的模块列表 |
| init_lora_weights | 如何初始化适配器层的权重。
|
| layers_to_transform | 要转换的层索引列表。
|
| layers_pattern | 层模式名称,仅在 layers_to_transform 不为 None 时使用 |
| rank_pattern | 层名称或正则表达式到秩的映射 |
| alpha_pattern | 层名称或正则表达式到 alpha 的映射 |
6举例
6.1 初始 model
from transformers import AutoModel,AutoTokenizer
import os
import torchos.environ["HF_TOKEN"] = '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'tokenizer=AutoTokenizer.from_pretrained('meta-llama/Meta-Llama-3-8B')
model=AutoModel.from_pretrained('meta-llama/Meta-Llama-3-8B',torch_dtype=torch.bfloat16, low_cpu_mem_usage=True)model
6.2 经典lora
from peft import LoraConfig, TaskTypepeft_config = LoraConfig(r=8, lora_alpha=32, lora_dropout=0.1)from peft import get_peft_modellora_model = get_peft_model(model, peft_config)
lora_model.print_trainable_parameters()lora_model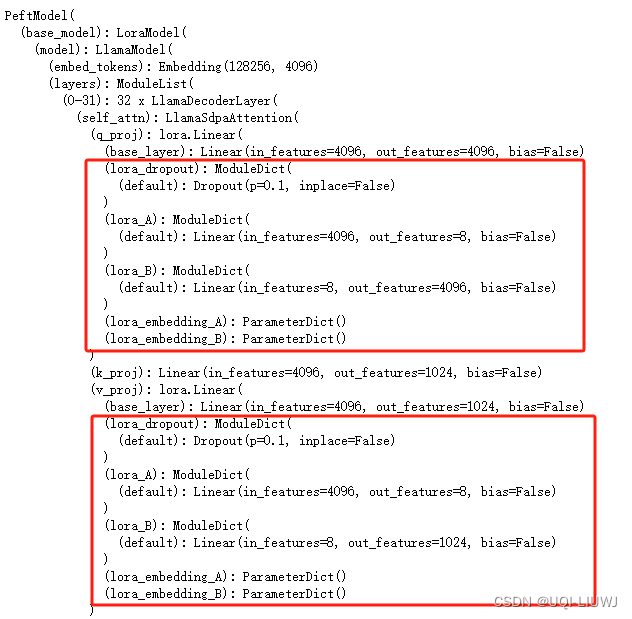

6.3 查看可训练参数
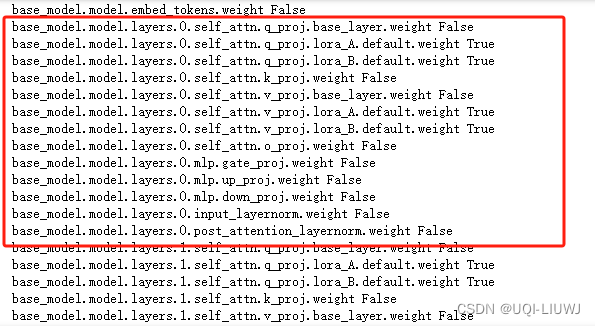
for name,tensor in model.named_parameters():print(name,tensor.requires_grad)
for name,tensor in lora_model.named_parameters():
print(name,tensor.requires_grad)







![[leetcode]文件组合](https://img-blog.csdnimg.cn/direct/4d65a04e44a340c5b005dd140ddba844.png)