DB-GPT的目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
1 处理流程
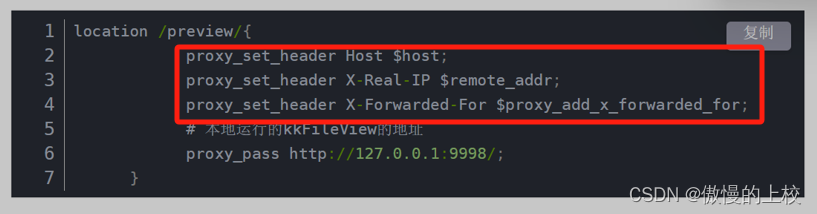
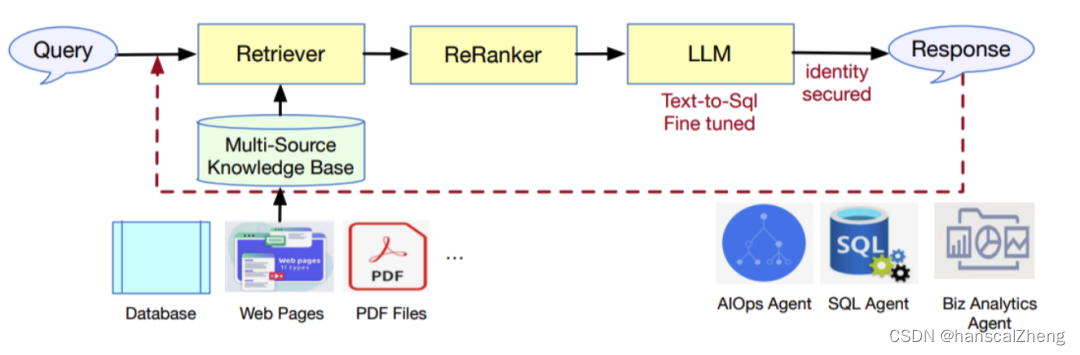
DB-GPT系统处理查询的架构,展示了以下组件和流程:
- 提交一个查询。
- 检索器组件选择相关信息。
- 重排器细化选择以确保最佳匹配。
- 为文本转SQL任务细化调整的语言模型(LLM)处理精炼信息。
- 系统确保身份安全。
- 生成并返回一个回复。
架构下方还展示了一个多源知识库,表明系统使用多个来源,如数据库、网页和PDF文件。还有如AIOps代理、SQL代理和商业分析代理,可以与不同类型的数据和服务接口。
2 关键特性
以下是DB-GPT的关键特性:
一、私域问答&数据处理&RAG
(Retrieval-Augmented Generation)
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索
二、多数据源&GBI(Generative Business Intelligence)
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告。
三、多模型管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱、星火等。
四、自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让TextSQL微调像流水线一样方便。
五、Data-Driven Multi-Agents&Plugins
支持自定义插件执行任务,原生支持Auto-GPT插件模型,Agents协议采用Agent Protocol标准。
六、隐私安全
通过私有化大模型、代理脱敏等多种技术保障数据的隐私安全。
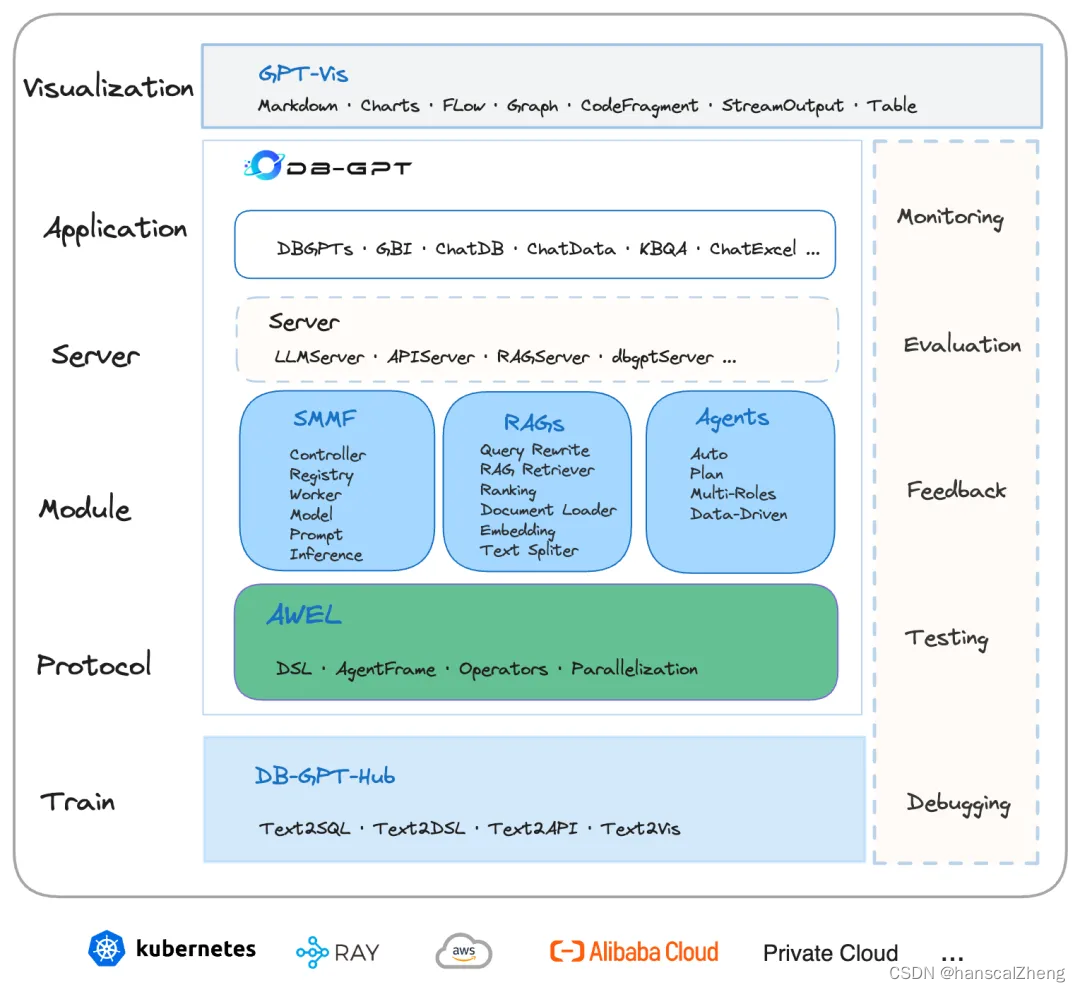
3 结语
DB-GPT是一个智能且生产就绪的项目,旨在通过增强型大型语言模型(LLMs)来改善数据摄取、结构化和访问,同时采用隐私化技术。其不仅利用了LLMs固有的自然语言理解和生成能力,还通过代理和插件机制不断优化数据驱动引擎。
论文:https://arxiv.org/pdf/2312.17449.pdf
代码:https://github.com/eosphoros-ai/DB-GPT
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!