在介绍缓存的false sharing之前,本文先介绍一下多核系统中缓存一致性是如何维护的。
目前主流的多核系统中的缓存一致性协议是MESI协议及其衍生协议。
MESI协议
MESI协议的4种状态
MESI协议有4种状态。MESI是4种状态的首字母缩写,缓存行的4种状态分别如下。
(1)修改(Modified):表示数据只在本处理器的缓存中存在副本,数据是脏的,即数据被修改过,没有写回到内存。
(2)独占(Exclusive):表示数据只在本处理器的缓存中存在副本,数据是干净的,即副本和内存中的数据相同。
(3)共享(Shared):表示数据可能在多个处理器的缓存中存在副本,数据是干净的,即所有副本和内存中的数据相同。
(4)无效(Invalid):表示缓存行中没有存放数据。
MESI协议的消息
为了维护缓存一致性,处理器之间需要通信,MESI协议提供了以下消息。
(1)读(Read):包含想要读取的缓存行的物理地址。
(2)读响应(Read Response):包含读消息请求的数据。读响应消息可能是由内存控制器发送的,也可能是由其他处理器的缓存发送的。如果一个处理器的缓存有想要的数据,并且处于修改状态,那么必须发送读响应消息。
(3)使无效(Invalidate):包含想要删除的缓存行的物理地址。所有其他处理器必须从缓存中删除对应的数据,并且发送使无效确认消息来应答。
(4)使无效确认(Invalidate Acknowledge):处理器收到使无效消息,必须从缓存中删除对应的数据,并且发送使无效确认消息来应答。
(5)读并且使无效(Read Invalidate):包含想要读取的缓存行的物理地址,同时要求从其他缓存中删除数据。它是读消息和使无效消息的组合,需要接收者发送读响应消息和使无效确认消息。
(6)写回(Writeback):包含想要写回到内存的地址和数据。
MESI协议的状态转换
缓存行状态的转换如下图所示。
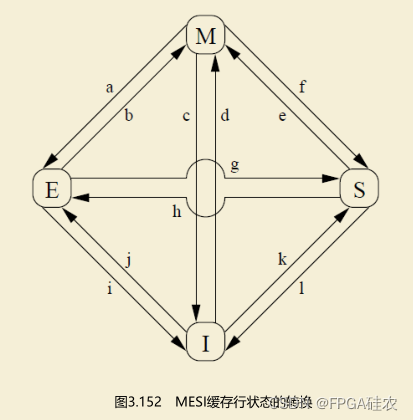
(1)转换a,修改M到独占E:处理器收到写回消息,把缓存行写回内存,但是缓存行保留数据。
(2)转换b,独占E到修改M:处理器写数据到缓存行。
(3)转换c,修改M到无效I:处理器收到“读并且使无效”消息,发送读响应消息和使无效确认消息,删除本地副本(不需要写回内存,因为发送“读并且使无效”消息的处理器需要写数据)。
(4)转换d,无效I到修改M:处理器写不在本地缓存中的数据,发送“读并且使无效”消息,通过读响应消息收到数据。处理器可以在收到所有其他处理器的使无效确认消息以后转换到修改状态M。
(5)转换e,共享S到修改M:处理器写数据,该数据在缓存中命中,则只需发送使无效消息,收到所有其他处理器的使无效确认消息以后转换到修改状态M。
(6)转换f,修改M到共享S:其他处理器读取缓存行,发送读消息,本处理器收到读消息后,写回内存,保留一个只读副本,发送读响应消息。
(7)转换g,独占E到共享S:其他处理器读取缓存行,发送读消息,本处理器收到后发送读响应消息,保留一个只读副本。
(8)转换h,共享S到独占E:本处理器意识到很快需要写数据,发送使无效消息,收到所有其他处理器的使无效确认消息以后转换到独占状态E。
(9)转换i,独占E到无效I:其他处理器写数据,发送“读并且使无效”消息,本处理器收到消息后,发送读响应消息和使无效确认消息。
(10)转换j,无效I到独占E:处理器写不在本地缓存中的数据,发送“读并且使无效”消息,收到读响应消息和所有其他处理器的使无效确认消息后转换到独占状态E,完成写操作后转换到修改状态M。
(11)转换k,无效I到共享S:处理器加载不在本地缓存中的数据,发送读消息,收到读响应消息后转换到共享状态S。
(12)转换l,共享S到无效I:其他处理器写本地缓存中的数据,发送使无效消息,本处理器收到后,把缓存行的状态转换为无效,发送使无效确认消息。
false sharing伪共享
false sharing概念
定义:当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
Cache和内存之间交换数据的最小粒度不是字节,而是称为cache line的一块固定大小的区域,缓存行是内存交换的实际单位。缓存行是2的整数幂个连续字节,一般为32~256个字节,最常见的缓存行大小是64个字节。
在写多线程代码时,为了避免使用锁,通常会采用这样的数据结构:根据线程的数目,安排一个数组, 每个线程一个项,互相不冲突。从逻辑上看这样的设计无懈可击,但是实践的过程可能会发现有些场景下非但没提高执行速度,反而性能会很差。
问题在于cpu的Cache Line,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享,即false-sharing。
例如,在Intel Core 2 Duo处理器平台上,L2 cache是由两个core共享的,而L1 data cache是分开的,由两个core分别存取。cache line的大小是64 Bytes。假设有个全局共享结构体变量f由2个线程A和B共享读写,该结构体一共8个字节同时位于同一条cache line上。
struct foo {int x;int y;
};
若此时两个线程一个读取f.x另一个读取f.y,即便两个线程的执行是在独立的cpu core上的,实际上结构体对象f被分別读入到两个CPUs的cache line中且该cache line 处于shared状态。若此时在核心1上运行的线程A想更新变量X,同时核心2上的线程B想要更新变量Y,则:
如果核心1上线程A优先获得了所有权,线程A修改f.x会使该CPU core 1上的这条cache line将变为modified状态,另一个CPU core 2上对应的cache line将变成invalid状态;此时若线程B马上读取f.y,为了确保cache一致性,B所在CPU核上的相应cache line的数据必须被更新;当核心2上线程B优先获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,影响性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,若读写的次数频繁,将增大cache miss的次数,严重影响系统性能。
虽然在memory的角度这两种访问是隔离的,但是由于错误的紧凑地放在了一起,使得两个变量处于同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。可见,false sharing会导致多核处理器上对于缓存行Cache Line的写竞争,造成严重的系统性能下降,有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
false-sharing避免方法
把每个项凑齐Cache Line的长度,即可实现隔离,虽然这不可避免的会浪费一些内存。
- 对于共享数组而言,增大数组元素的间隔使得由不同线程存取的数组元素位于不同的Cache Line上,使一个核上的Cache line修改不会影响其它核;或者在每个线程中创建全局数组的本地拷贝,然后执行结束后再写回全局数组,此方法比较粗暴不优雅。
- 对于共享结构体而言,使每个结构体成员变量按照Cache Line大小(一般64B)对齐。可能需要使用#pragma宏。