韩国 科学技术院(KAIST)的一家初创公司Panmnesia推出了一种尖端 IP,可通过 PCIe 上的 CXL 协议为人工智能 GPU 添加外部存储器,从而打破了存储器容量的障碍,提供有效的基础设施来解决 HBM 的局限性。

目前的人工智能加速器仅限于板载内存,而制造商只能提供非常有限的 HBM。随着数据集的不断增长和对功耗的需求,业界正专注于增加更多的人工智能 GPU,而考虑到其所占用的财务和制造资源,这种方法从长远来看是不可持续的。有鉴于此,由韩国 KAIST 研究所支持的公司 Panmnesia 推出了一个 CXL IP,可以让 GPU 利用 DRAM 甚至 SSD 的内存,扩展内置的 HBM。
为了实现连接,CXL 采用了 PCIe 链接,确保在消费者中得到广泛采用。不过,这也有一个问题。传统的人工智能加速器缺乏必要的子系统,无法直接连接并利用 CXL 进行内存扩展,而且 UVM(统一虚拟内存)等解决方案的速度相当慢,这就失去了初衷。
不过,作为一种解决方案,Panmnesia 开发出了自己的符合 CXL 3.1 标准的 Root Complex 芯片,它有多个端口,通过 PCIe 总线连接 GPU 和外部内存,HDM(主机管理设备内存)解码器则充当连接的桥梁,管理内存分配和转换。
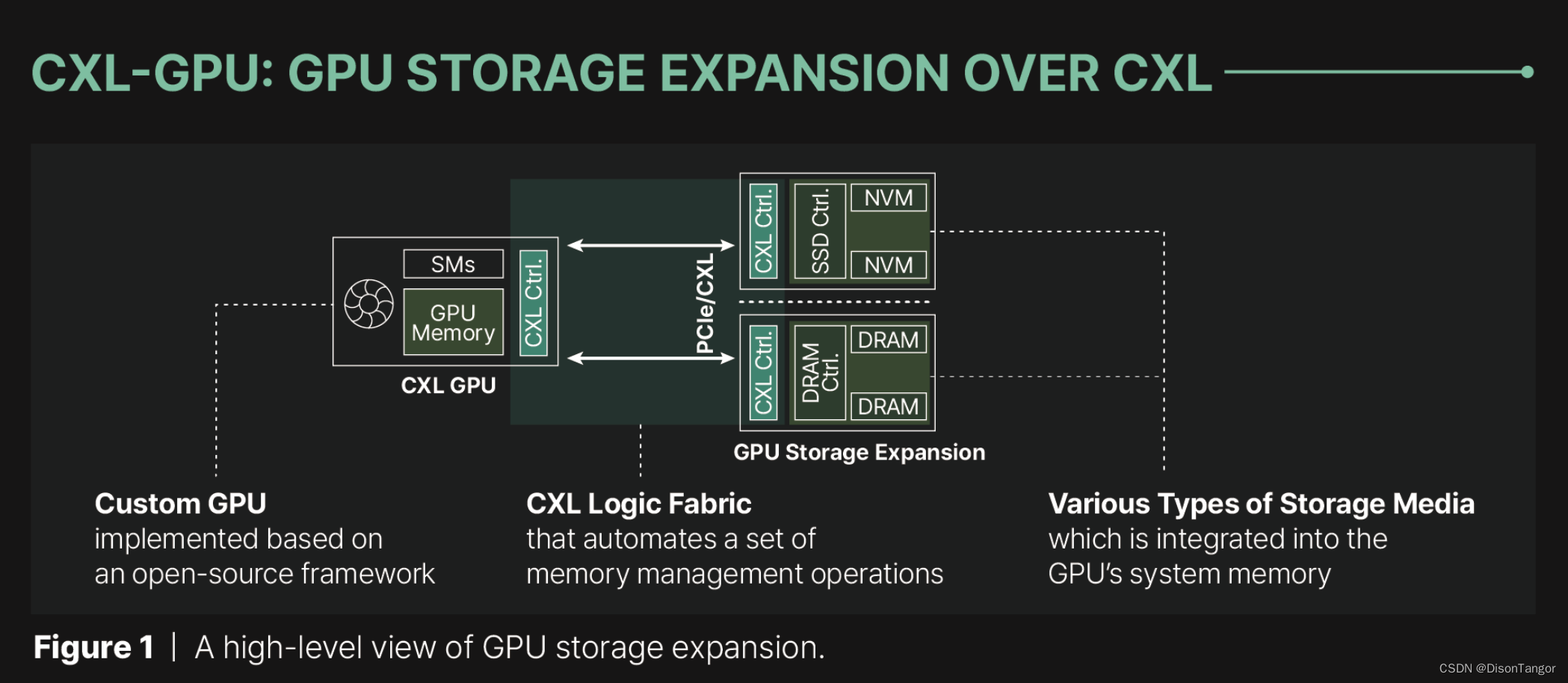
有趣的是,Panmnesia 决定将他们的解决方案(CXL-Opt)与三星和 Meta 开发的原型产品(他们称之为"CXL-Proto")进行基准测试。令我们惊讶的是,CXL-Opt 的往返延迟(即数据从 GPU 传输到内存再返回所需的时间)大大降低。 CXL-Opt 的延迟时间为两位数纳秒,而 CXL-Proto 的延迟时间为 250ns。除此之外,CXL-Opt 的执行时间远远少于 UVM 解决方案,因为它的 IPC 性能速度是 UVM 的 3.22 倍。
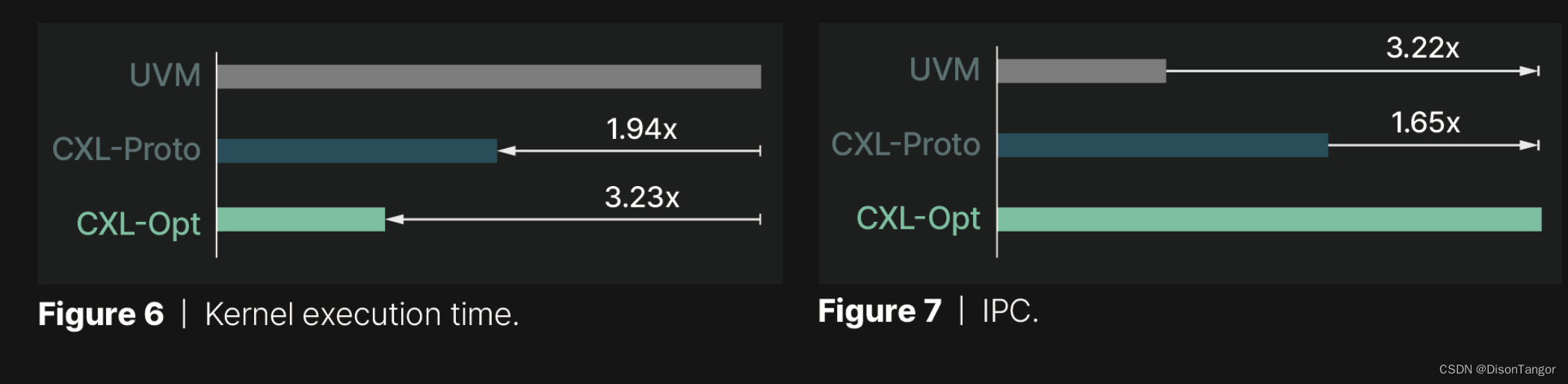
Panmnesia 的解决方案可以在市场上取得巨大进步,因为它是堆叠 HBM 芯片和实现更高效解决方案之间的中介。鉴于该公司是首批拥有创新 CXL IP 的公司之一,如果这一技术获得认可,Panmnesia 将受益匪浅。






![[数据结构] --- 树](https://img-blog.csdnimg.cn/direct/198d2befdee549009a4311420b120cdf.png)