ELK是ElasticSerach、Logstash、Kina
Logstash负责采集数据,Logstash有三个插件,input、filter、output,filter插件作用是对采集的数据进行处理,过滤的,因此filter插件可以选,可以不用配置。
ElasticSearch负责存储数据和检索数据。
Kina负责展示数据。
这三个补充配置样例:
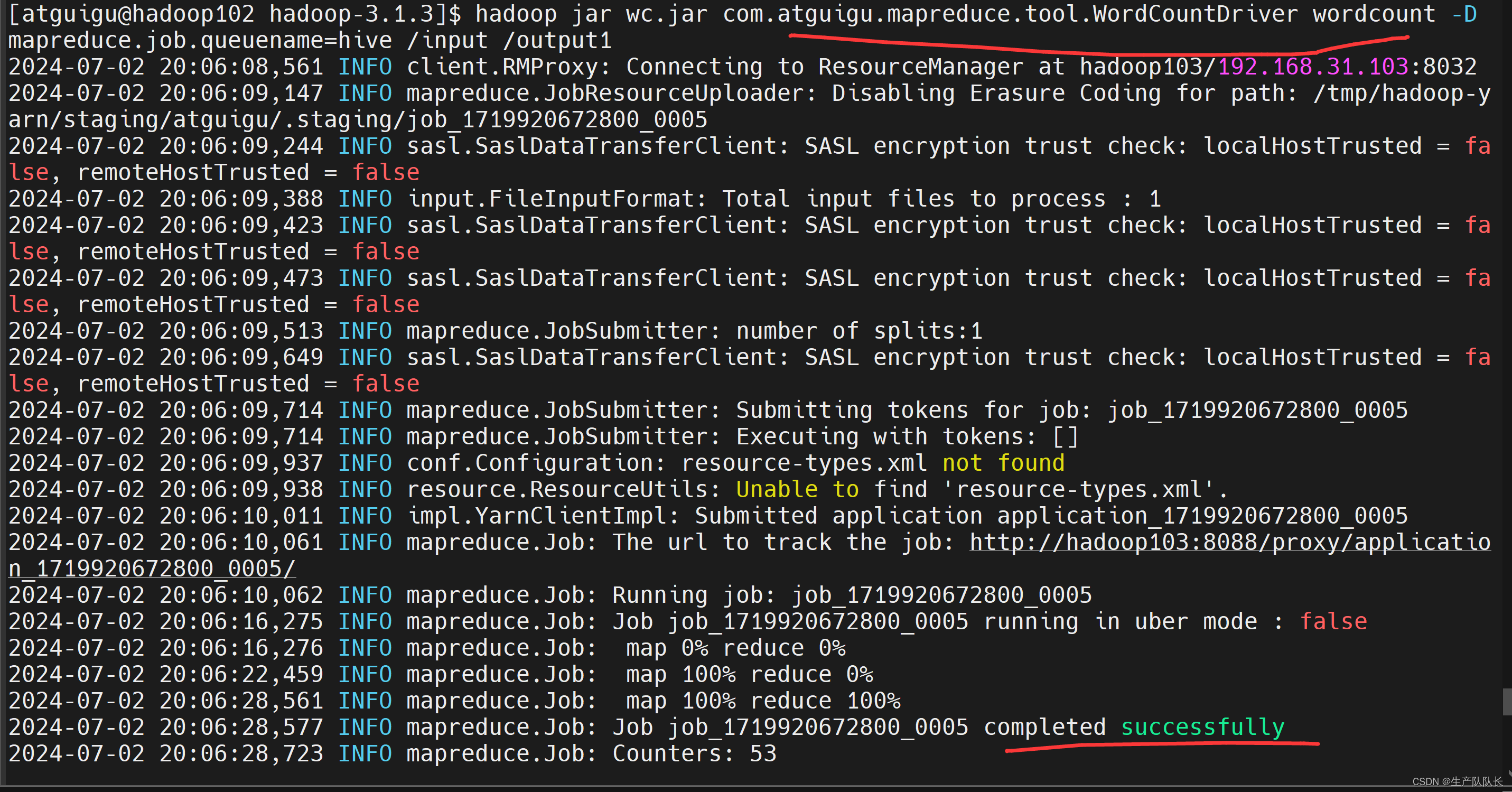
一个常见的部署方案,如下图所示,部署思路是:
(1)在每台生成日志文件的机器上,部署Logstash,作为Shipper的角色,负责从日志文件中提取数据,但是不做任何处理,直接将数据输出到Redis队列(list)中;
(2)需要一台机器部署Logstash,作为Indexer的角色,负责从Redis中取出数据,对数据进行格式化和相关处理后,输出到Elasticsearch中存储;
(3)部署Elasticsearch集群,当然取决于你的数据量了,数据量小的话可以使用单台服务,如果做集群的话,最好是有3个以上节点,同时还需要部署相关的监控插件;
(4)部署Kibana服务,提供Web服务。

在前期部署阶段,主要工作是Logstash节点和Elasticsearch集群的部署,而在后期使用阶段,主要工作就是Elasticsearch集群的监控和使用Kibana来检索、分析日志数据了,当然也可以直接编写程序来消费Elasticsearch中的数据。
在上面的部署方案中,我们将Logstash分为Shipper和Indexer两种角色来完成不同的工作,中间通过Redis做数据管道,为什么要这样做?为什么不是直接在每台机器上使用Logstash提取数据、处理、存入Elasticsearch?
首先,采用这样的架构部署,有三点优势:第一,降低对日志所在机器的影响,这些机器上一般都部署着反向代理或应用服务,本身负载就很重了,所以尽可能的在这些机器上少做事;第二,如果有很多台机器需要做日志收集,那么让每台机器都向Elasticsearch持续写入数据,必然会对Elasticsearch造成压力,因此需要对数据进行缓冲,同时,这样的缓冲也可以一定程度的保护数据不丢失;第三,将日志数据的格式化与处理放到Indexer中统一做,可以在一处修改代码、部署,避免需要到多台机器上去修改配置。
其次,我们需要做的是将数据放入一个消息队列中进行缓冲,所以Redis只是其中一个选择,也可以是RabbitMQ、Kafka等等,在实际生产中,Redis与Kafka用的比较多。由于Redis集群一般都是通过key来做分片,无法对list类型做集群,在数据量大的时候必然不合适了,而Kafka天生就是分布式的消息队列系统。

基本思路是:在服务器上装logstash,这个logstash只配置input和output,采集数据,往kakfa中写,然后在部署一个logstash读取kafka的数据进行处理,然后往ElasticSearch中写数据。然后用Kibana读取ElasticSearch中的数据进行展示。