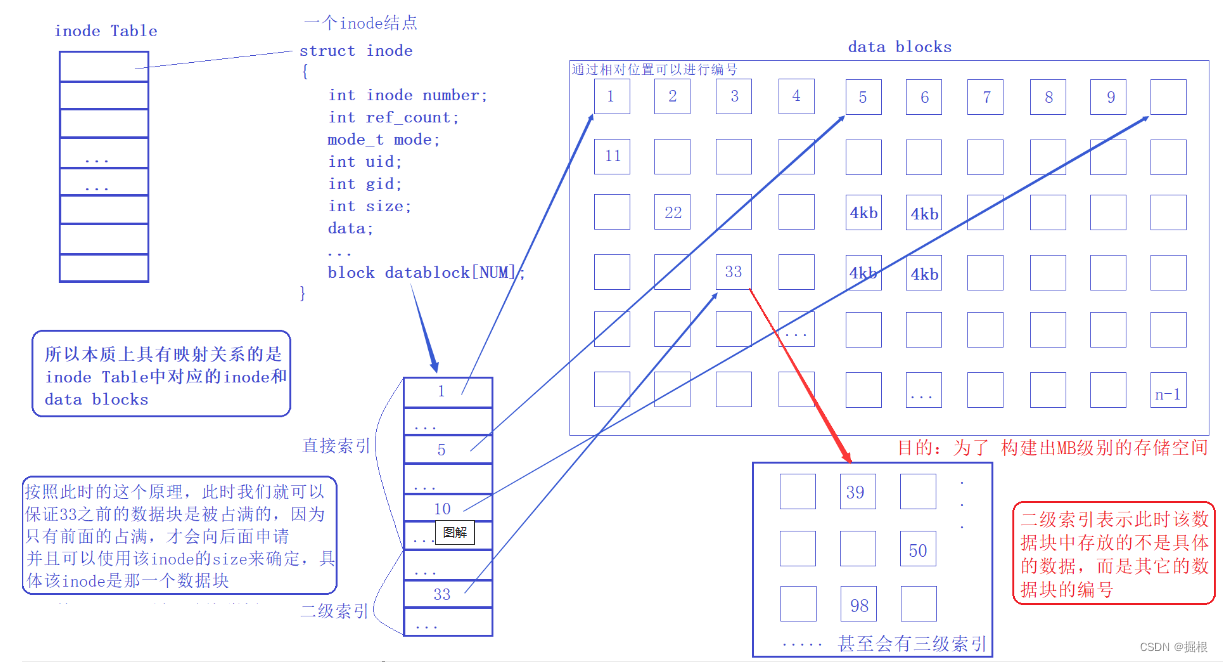
写在前面
检索检索,刚好发现一篇分区还挺高,但结果内容看上去还挺熟悉的文章,特记录一下。
文章
Exploring the mechanism underlying hyperuricemia using comprehensive research on multi-omics
Sci Rep IF:3.8中科院分区:2区 综合性期刊WOS分区:Q1
数据
1.血液及尿液的代谢组(15 名参与者,10 名高尿酸血症患者和 5 名对照)
2.小鼠模型(RNA测序)
3.痛风、凉茶摄入量、咖啡摄入量和茶摄入量的遗传关联摘要数据来自 FinnGen 数据库
结果
1.基本基线情况一致
年龄、血尿素氮水平、尿pH值、尿比重有差异,肌酐、尿酸差异。
2.鉴别差异代谢物
PCA说明两组有差异,差异分析代谢物。
3.差异代谢物差异富集
kegg通路富集,“咖啡因代谢”、“氨酰基-tRNA生物合成”、“半胱氨酸和蛋氨酸代谢”、“缬氨酸、亮氨酸和异亮氨酸生物合成”、“精氨酸和脯氨酸代谢”、“色氨酸代谢”和“嘌呤代谢”。点出咖啡因
4.咖啡及茶与痛风的孟德尔随机化分析
3组,无咖啡因凉茶为对照组、咖啡、茶各一组。

5.构建调控网络
用高尿酸差异代谢物与高尿酸差异rna的交集,做kegg通路富集,最后富集为“氨酰-tRNA生物合成”4个基因,“精氨酸和脯氨酸代谢”4个基因,“色氨酸代谢”10个基因,“半胱氨酸和蛋氨酸代谢”5个基因,“嘌呤代谢”途径24个基因。
写在最后
这篇文章做的话感觉还是较简单的,可能就是有自己的数据。从代谢组入手,再到孟德尔随机化分析。