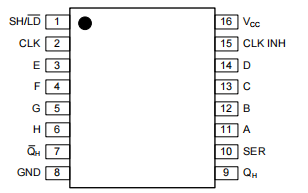
tl;dr:
在这篇文章中,我们将探讨 AI 工作负载依赖高性能对象存储的四个技术原因。
1. 对非结构化数据没有限制

在当前的机器学习范式中,性能和能力与计算成比例,计算实际上是数据集大小和模型大小的代理(神经语言模型的缩放定律,Kaplan等人)。在过去的几年里,这给机器学习和数据基础设施的构建方式带来了彻底的变化——即:存储和计算的分离,构建充满非结构化数据的大规模云原生数据湖,以及可以快速进行矩阵乘法的专用硬件。
当训练数据集(甚至是数据集的单个分片)需要的空间超过系统内存和/或本地存储中的可用空间时,将存储与计算分离的重要性就变得非常明显。对驻留在 MinIO 对象存储中的数据进行训练时,训练数据大小没有限制。由于 MinIO 专注于简单性和 I/O 吞吐量,因此网络成为训练速度和 GPU 利用率的唯一限制因素。
除了提供任何对象存储的最佳性能外,MinIO 还与所有现代机器学习框架兼容。MinIO 对象存储还 100% 与 S3 API 兼容,因此您可以使用熟悉的数据集实用程序(如 S3-Connector for PyTorch (BSD-3-Clause) 或 TorchData S3 Datapipe)对本地或设备上的对象存储执行 ML 工作负载。如果您的消费应用程序需要类似文件系统的功能,您甚至可以将 MinIO 与对象存储文件接口(如 Mountpoint S3 或 S3FS)一起使用。在以后的博客文章中,我们将在一些常见的 PyTorch 和 FairSeq 接口的自定义实现中使用 MinIO Python SDK,以便为模型训练启用“无限制”的训练数据和高 GPU 利用率。
除了性能和与现代 ML 堆栈的兼容性之外,对象存储的设计选择,即 (1) 扁平命名空间,(2) 将整个对象(及其元数据)封装为最低逻辑实体,以及 (3) 简单的 HTTP 谓词 API,是导致对象存储成为大规模非结构化数据湖的事实标准的原因。纵观机器学习的近期历史,可以看出训练数据(从某种意义上说,模型架构本身)已经变得不那么结构化,更加通用。过去的情况是,模型主要在表格数据上进行训练。如今,范围更广,从纯文本段落到数小时的视频。随着模型架构和 ML 应用程序的发展,对象存储的无状态、无模式以及可扩展的性质只会变得更加重要。
2. 模型和数据集的丰富元数据

由于 MinIO 对象存储的设计选择,每个对象都可以包含丰富的无架构元数据,而不会牺牲性能或需要使用专用元数据服务器。当涉及到你想向对象添加什么样的元数据时,想象力确实是唯一的限制。但是,以下是一些可能对 ML 相关对象特别有用的想法:
对于模型检查点:损失函数值、训练所用时间、用于训练的数据集。
对于数据集:配对索引文件的名称(如果适用)、数据集类别(训练、验证、测试)、有关数据集格式的信息。
像这样描述性很强的元数据,当能够有效地索引和查询这些元数据时,可以特别强大,即使是在数十亿个对象中,MinIO 企业目录也能提供这种能力。例如,可以查询标记为“已测试”的模型检查点或已在特定数据集上训练的检查点。
3. 模型和数据集是可用的、可审计的和可版本的

随着机器学习模型及其数据集成为越来越重要的资产,以容错、可审计和可版本化的方式存储和管理这些资产也变得同样重要。
数据集和基于数据集进行训练的模型是宝贵的资产,是时间、工程努力和金钱的来之不易的产物。因此,应以不妨碍应用程序访问的方式保护它们。MinIO 的内联操作(如 bitrot 检查和纠删码)以及多站点、主动-主动复制等功能可确保这些对象的大规模弹性。
特别是对于生成式 AI,在调试幻觉和其他模型不当行为时,了解哪个数据集的哪个版本用于训练正在提供的特定模型很有帮助。如果模型检查点已正确版本控制,则可以更轻松地信任快速回滚到以前提供的检查点版本。借助 MinIO 对象存储,您可以开箱即用地获得这些对象优势。
4. 自有服务基础设施

从根本上说,MinIO 对象存储是您或您的组织控制的对象存储。无论用例是用于原型设计、安全、监管还是经济目的,控制都是共同点。因此,如果经过训练的模型检查点驻留在对象存储中,则可以更好地控制为推理或使用模型提供服务的任务。
在上一篇文章中,我们探讨了将模型文件存储在对象存储上的好处,以及如何使用 PyTorch 的 TorchServe 推理框架直接提供它们。然而,这是一个完全与模型和框架无关的策略。
但为什么这很重要呢?第三方模型存储库上的网络滞后或中断可能会使模型在推理时变慢,或者完全不可用。此外,在推理服务器正在扩展并需要定期拉取模型检查点的生产环境中,这个问题可能会加剧。在最安全和/或最关键的情况下,最好尽可能避免第三方对互联网的依赖。将 MinIO 作为私有云或混合云对象存储,可以完全避免这些问题。
结束语

这四个原因绝不是详尽无遗的清单。开发人员和组织出于各种原因将 MinIO 对象存储用于其 AI 工作负载,从易于开发到超轻占用空间。
在本文的开头,我们介绍了采用高性能 AI 对象存储背后的驱动力。无论扩展定律是否成立,可以肯定的是,组织及其 AI 工作负载将始终受益于可用的最佳 I/O 吞吐量能力。除此之外,我们可以相当有信心,开发人员永远不会要求更难使用的 API 和不“正常工作”的软件。在这些假设成立的任何未来,高性能对象存储都是出路。
对于任何阅读本文的架构师和工程决策者来说,这里提到的许多最佳实践都可以自动化,以确保以一种使您的 AI/ML 工作流程更简单、更具可扩展性的方式利用对象存储。这可以通过使用任何现代 MLOps 工具集来完成。AI/ML SME Keith Pijanowski 探索了其中的许多工具 - 在我们的博客网站上搜索 Kubeflow、MLflow 和 MLRun,了解有关 MLOps 工具的更多信息。但是,如果这些 MLOps 工具不适合您的组织,并且您需要快速上手,那么本文中显示的技术是开始使用 MinIO 管理 AI/ML 工作流的最佳方式。
对于开发人员(或任何好奇🙂的人),在以后的博客文章中,我们将进行端到端演练,以调整 ML 框架以利用对象存储,以实现“无限制”训练数据和适当的 GPU 利用率。