Redis基本数据结构
Redis是C语言开发的一个开源的(遵从BSD协议)高性能键值对(key-value)的内存数据库,可以用作数据库、缓存、消息中间件等。它是一种NoSQL(not-only sql,泛指非关系型数据库)的数据库。
数据模型
概述
下图是执行set hello world时,所涉及到的数据模型。
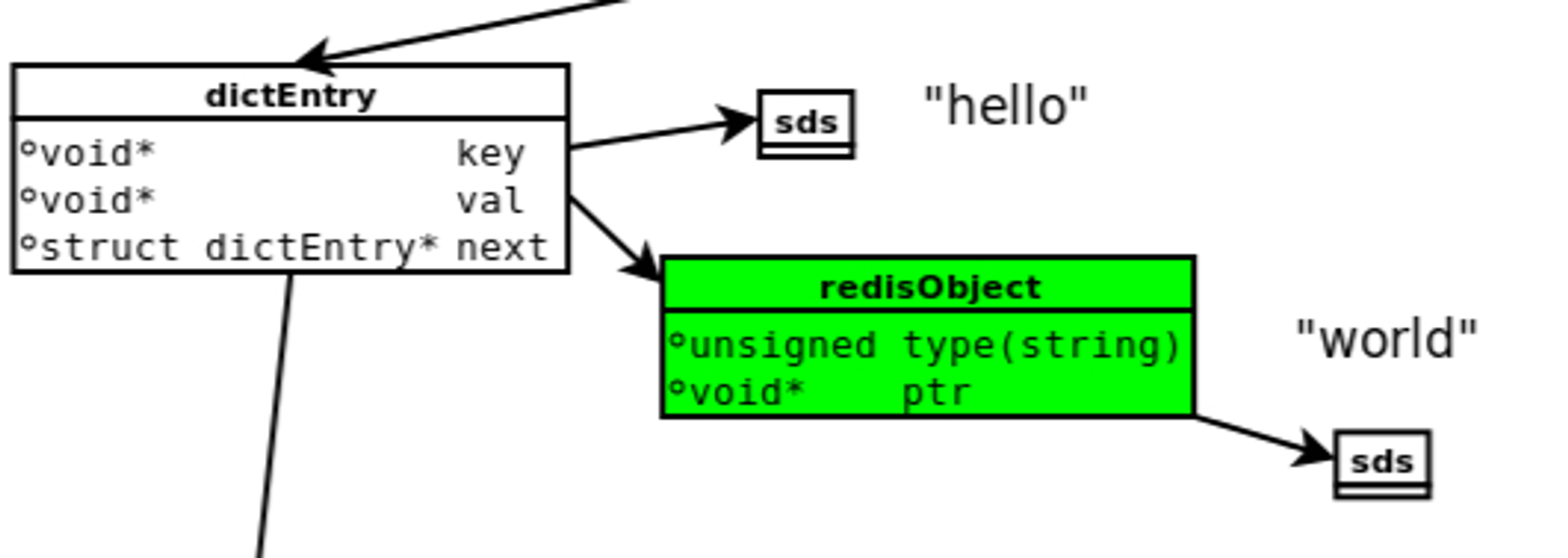
dictEntry
Redis是Key-Value数据库,因此对每个键值对都会有一个dictEntry,里面存储了指向Key和Value的指针;next指向下一个dictEntry,与本Key-Value无关。
typedef` `struct` `dictEntry{`` ``void` `*key;`` ``union``{`` ``void` `*val;`` ``uint64_tu64;`` ``int64_ts64;`` ``}v;`` ``struct` `dictEntry *next;``}dictEntry;
Key
图中右上角可见,Key(”hello”)并不是直接以字符串存储,而是存储在SDS结构中。
redisObject
value(“world”)既不是直接以字符串存储,也不是像Key一样直接存储在SDS中,而是存储在redisObject中。实际上,不论Value是5种类型的哪一种,都是通过redisObject来存储的;而redisObject中的type字段指明了value对象的类型,ptr字段则指向对象所在的地址。不过可以看出,字符串对象虽然经过了redisObject的包装,但仍然需要通过SDS存储。
jemalloc
无论是DictEntry对象,还是redisObject、SDS对象,都需要内存分配器(如jemalloc)分配内存进行存储。以DictEntry对象为例,有3个指针组成,在64位机器下占24个字节,jemalloc会为它分配32字节大小的内存单元。
RedisObject
无论是哪种类型,Redis都不会直接存储,而是通过redisObject对象进行存储。
redisObject的定义如下(不同版本的Redis可能稍稍有所不同):
typedef struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */int refcount;void *ptr;
} robj;
type
type字段表示对象的类型,占4个比特;目前包括:
- REDIS_STRING(字符串)
- REDIS_LIST (列表)
- REDIS_HASH(哈希)
- REDIS_SET(集合)
- REDIS_ZSET(有序集合)
当我们执行type命令时,便是通过读取RedisObject的type字段获得对象的类型;如下所示:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> type hello
string
encoding
encoding表示对象的内部编码,占4个比特。
对于Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码。通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵活性和效率。以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
通过object encoding命令,可以查看对象采用的编码方式,如下所示:
127.0.0.1:6379> set name tom
OK
127.0.0.1:6379> object encoding name
"embstr"
不同类型和编码的对象:
REDIS_STRING REDIS_ENCODING_INT 使用整数值实现的字符串对象。
REDIS_STRING REDIS_ENCODING_EMBSTR 使用 embstr 编码的简单动态字符串实现的字符串对象。
REDIS_STRING REDIS_ENCODING_RAW 使用简单动态字符串实现的字符串对象。
REDIS_LIST REDIS_ENCODING_ZIPLIST 使用压缩列表实现的列表对象。
REDIS_LIST REDIS_ENCODING_LINKEDLIST 使用双端链表实现的列表对象。
REDIS_HASH REDIS_ENCODING_ZIPLIST 使用压缩列表实现的哈希对象。
REDIS_HASH REDIS_ENCODING_HT 使用字典实现的哈希对象。
REDIS_SET REDIS_ENCODING_INTSET 使用整数集合实现的集合对象。
REDIS_SET REDIS_ENCODING_HT 使用字典实现的集合对象。
REDIS_ZSET REDIS_ENCODING_ZIPLIST 使用压缩列表实现的有序集合对象。
REDIS_ZSET REDIS_ENCODING_SKIPLIST 使用跳跃表和字典实现的有序集合对象。
OBJECT ENCODING 对不同编码的输出:
整数 REDIS_ENCODING_INT "int"
embstr 编码的简单动态字符串(SDS) REDIS_ENCODING_EMBSTR "embstr"
简单动态字符串 REDIS_ENCODING_RAW "raw"
字典 REDIS_ENCODING_HT "hashtable"
双端链表 REDIS_ENCODING_LINKEDLIST "linkedlist"
压缩列表 REDIS_ENCODING_ZIPLIST "ziplist"
整数集合 REDIS_ENCODING_INTSET "intset"
跳跃表和字典 REDIS_ENCODING_SKIPLIST "skiplist"
lru
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
通过对比lru时间与当前时间,可以计算某个对象的空转时间;object idletime命令可以显示该空转时间(单位是秒)。object idletime命令的一个特殊之处在于它不改变对象的lru值。
127.0.0.1:6379> set china shanghai
OK
127.0.0.1:6379> object idletime china
(integer) 8
127.0.0.1:6379> object idletime china
(integer) 12
127.0.0.1:6379> get china
"shanghai"
127.0.0.1:6379> object idletime china
(integer) 2
refcount
refcount记录的是该对象被引用的次数,类型为整型。
refcount的作用,主要在于对象的引用计数和内存回收。当创建新对象时,refcount初始化为1;当有新程序使用该对象时,refcount加1;当对象不再被一个新程序使用时,refcount减1;当refcount变为0时,对象占用的内存会被释放。
Redis中被多次使用的对象(refcount>1),称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象,之所以如此,实际上是对内存和CPU(时间)的平衡。
共享对象的引用次数可以通过object refcount命令查看,如下所示:
27.0.0.1:6379> set a b
OK
127.0.0.1:6379> set c b
OK
127.0.0.1:6379> object refcount a
(integer) 1
127.0.0.1:6379> object refcount c
(integer) 1
ptr
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。
总结
综上所述,redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;一个redisObject对象的大小为16字节:4bit+4bit+24bit+4Byte+8Byte=16Byte。
SDS
sds的结构如下:
struct sdshdr {// 等于SDS所保存字符串的长度int len;// 记录buf数组中未使用字节的数量int free;// 字节数组,用于保存字符串char buf[];
};

free属性的值为0,表示这个SDS没有分配任何未使用空间。-
len属性的值为5,表示这个SDS保存了一个五字节长的字符串。 -
buf属性是一个char类型的数组,数组的前五个字节分别保存了'R'、'e'、'd'、'i'、's'五个字符,而最后一个字节则保存了空字符'\0'。
SDS与C字符串的比较
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
- 获取字符串长度:
SDS是O(1),C字符串是O(n) - 缓冲区溢出:使用
C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。 - 修改字符串时内存的重分配:对于
C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化:空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。 - 存取二进制数据:
SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS以字符串长度len来作为字符串结束标识,因此没有这个问题。
RedisObject 与SDS 之间的关系
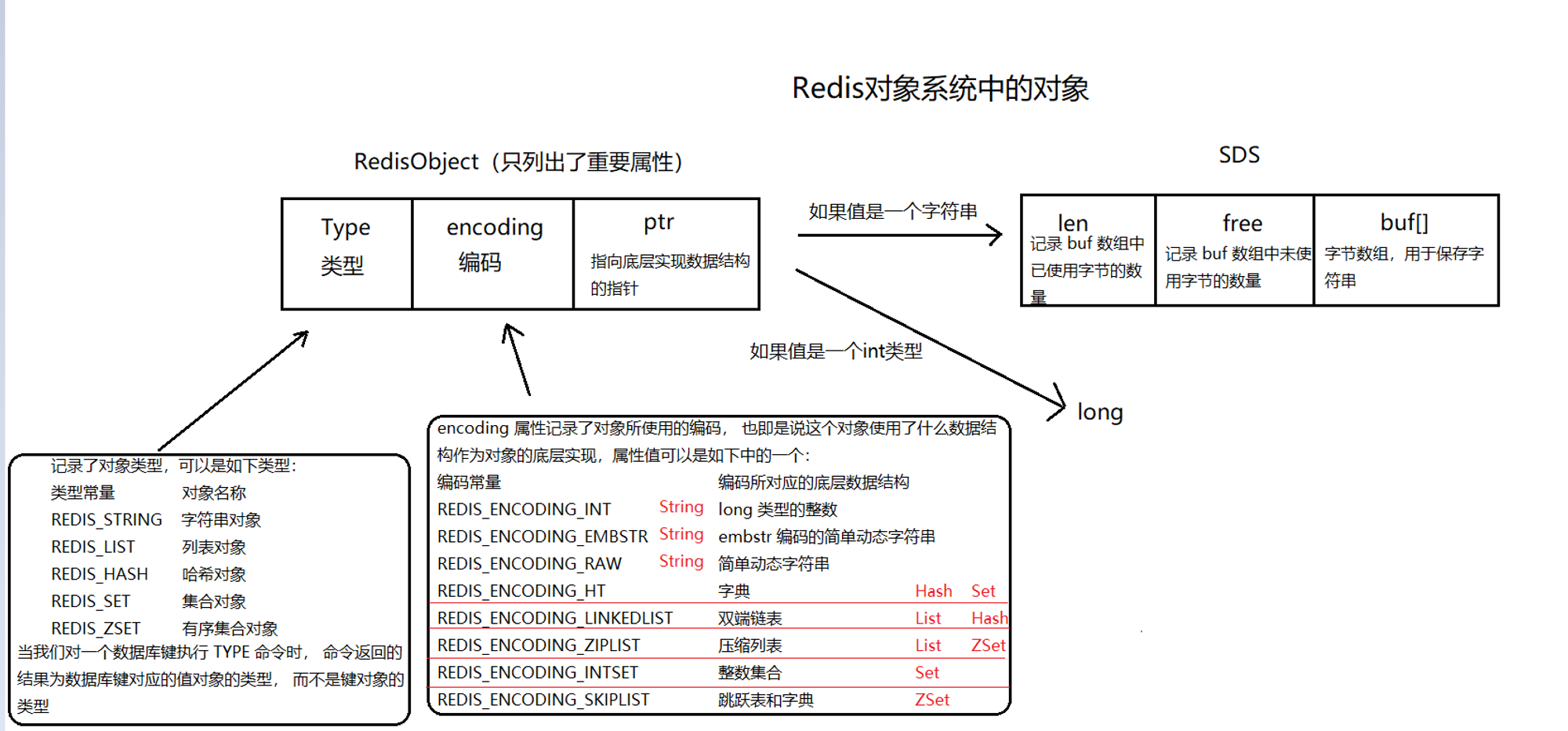
对象类型与内部编码
String(字符串)
概况
string 是 redis 最基本的数据类型,一个 key 对应一个 value。
string 是二进制安全的。也就是说 redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象。
string 类型的值最大能存储 512 MB。
内部编码
字符串类型的内部编码有3种,它们的应用场景如下:
-
int:8个字节的长整型。字符串值是整型时,这个值使用long整型表示。 -
embstr:小于等于39字节的字符串。 -
raw:大于39个字节的字符串。
embstr与raw都使用redisObject和sds保存数据。区别在于,embstr的使用只分配一次内存空间(因此redisObject和sds是连续的),而raw需要分配两次内存空间(分别为redisObject和sds分配空间)。因此与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。
基本命令
-
set key value:设定key持有指定的字符串value,如果该key存在则进行覆盖操作。总是返回”OK” -
mget :批量获取多个key的值,如果可以不存在则返回nil -
setnx :设置key对应的值为String类型的value,如果key已经存在则返回0。 -
setex :设置key对应的值为String类型的value,并设定有效期 -
setrange :设置key对应value的子字符串 -
mset :批量设置多个key的值,如果成功表示所有值都被设置,否则返回0表示没有任何值被设置 -
msetnx :同mset,不存在就设置,不会覆盖已有的key -
strlen :取指定key的value的长度 -
get key:获取key的value。如果与该key关联的value不是String类型,redis将返回错误信息,因为get命令只能用于获取String value;如果该key不存在,返回null。 -
getset key value:先获取该key的值,然后在设置该key的值。 -
incr key:将指定的key的value原子性的递增1.如果该key不存在,其初始值为0,在incr之后其值为1。如果value的值不能转成整型,如hello,该操作将执行失败并返回相应的错误信息。 -
decr key:将指定的key的value原子性的递减1.如果该key不存在,其初始值为0,在incr之后其值为-1。如果value的值不能转成整型,如hello,该操作将执行失败并返回相应的错误信息。 -
incrby key increment:将指定的key的value原子性增加increment,如果该key不存在,器初始值为0,在incrby之后,该值为increment。如果该值不能转成整型,如hello则失败并返回错误信息 -
decrby key decrement:将指定的key的value原子性减少decrement,如果该key不存在,器初始值为0,在decrby之后,该值为decrement。如果该值不能转成整型,如hello则失败并返回错误信息 -
append key value:如果该key存在,则在原有的value后追加该值;如果该key不存在,则重新创建一个key/value。
List(列表)
概况
列表(list)用来存储多个有序的字符串,每个字符串称为元素;一个列表可以存储2^32-1个元素。Redis中的列表支持两端插入和弹出,并可以获得指定位置(或范围)的元素,可以充当数组、队列、栈等。
内部编码
列表的内部编码可以是压缩列表(ziplist)或双端链表(linkedlist)。
- 压缩列表:压缩列表是
Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。 - 双端链表:同时保存了表头指针和表尾指针,并且每个节点都有指向前和指向后的指针;链表中保存了列表的长度;
dup、free和match为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。而链表中每个节点指向的是type为字符串的RedisObject。
压缩列表可以节省内存空间,但是进行修改或增删操作时,复杂度较高;因此当节点数量较少时,可以使用压缩列表;但是节点数量多时,还是使用双端链表划算
基本命令
-
lpush key values[value1 value2…]:在指定的key所关联的list的头部插入所有的values,如果该key不存在,该命令在插入的之前创建一个与该key关联的空链表,之后再向该链表的头部插入数据。插入成功,返回元素的个数。 -
lpushx key value:仅当参数中指定的key存在时(如果与key管理的list中没有值时,则该key是不存在的)在指定的key所关联的list的头部插入value。 -
lrange key start end:获取链表中从start到end的元素的值,start、end可为负数,若为-1则表示链表尾部的元素,-2则表示倒数第二个,依次类推… -
lpop key:返回并弹出指定的key关联的链表中的第一个元素,即头部元素。如果该key不存在,返回nil;若key存在,则返回链表的头部元素。 -
llen key:返回指定的key关联的链表中的元素的数量。 -
lrem key count value:删除count个值为value的元素,如果count大于0,从头向尾遍历并删除count个值为value的元素,如果count小于0,则从尾向头遍历并删除。如果count等于0,则删除链表中所有等于value的元素。 -
lset key index value:设置链表中的index的脚标的元素值,0代表链表的头元素,-1代表链表的尾元素。操作链表的脚标则放回错误信息。 -
linsert key before|after pivot value:在pivot元素前或者后插入value这个元素。 -
rpush key values[value1、value2…]:在该list的尾部添加元素。 -
rpushx key value:在该list的尾部添加元素 -
rpop key:从尾部弹出元素。
Hash(哈希)
概况
Hash是一个String类型的field和value之间的映射表,即redis的Hash数据类型的key(hash表名称)对应的value实际的内部存储结构为一个HashMap,因此Hash特别适合存储对象。相对于把一个对象的每个属性存储为String类型,将整个对象存储在Hash类型中会占用更少内存。
内部编码
内层的哈希使用的内部编码可以是压缩列表(ziplist)和哈希表(hashtable)两种。
Redis的外层的哈希则只使用了hashtable。
-
hashtable:一个hashtable由1个dict结构、2个dictht结构、1个dictEntry指针数组(称为bucket)和多个dictEntry结构组成。
基本命令
-
hset key value(k-v---map):为指定的key设定field/value对(键值对)。 -
hsetnx 设置key对应的HashMap中的field的value,如果不存在则先创建 -
hget key field:返回指定的key中的field的值 -
hexists key field:判断指定的key中的filed是否存在,返回1存在,0不存在 -
hlen key:获取key所包含的field的数量 -
hincrby key field increment:设置key中filed的值增加increment,如:age增加20 -
hmset key fields:设置key中的多个filed/value -
hmget key fileds:获取key中的多个filed的值 -
hgetall key:获取key中的filed/value
Set(集合)
概况
集合(set)与列表类似,都是用来保存多个字符串,但集合与列表有两点不同:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
还支持多个集合取交集、并集、差集。
内部编码
集合的内部编码可以是整数集合(intset)或哈希表(hashtable)。
基本命令
-
sadd key values[value1、value2…]:向set中添加数据,如果该key的值已有则不会重复添加 -
smembers key:获取set中所有的成员 -
scard key:获取set中成员的数量 -
sismember key member:判断参数中指定的成员是否在该set中,1表示存在,0表示不存在或者该key本身就不存在 -
srem key members[member1、member2…]:删除set中指定的成员 -
srandmember key:随机返回set中的一个成员 -
sdiff key[sdiff key1 key2…]:返回key1与key2中相差的成员,而且与key的顺序有关。即返回差集。例如:sdiff key1 key2,以key1为目标,key2比key1差哪些成员。 -
sdiffstore destination key[key1、key2…]:将key1、key2相差的成员存储在destination上 -
sinter key[key1,key2…]:返回交集。 -
sinterstore destination key[key…]:将返回的交集存储在destination上 -
sunion key[key1、key2…]:返回并集。 -
sunionstore destination key[key…]:将返回的并集存储在destination上
SortSe(有序集合)
概况
有序集合与集合一样,元素都不能重复;但与集合不同的是,有序集合中的元素是有顺序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
内部编码
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。
- 跳跃表:是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。跳跃表支持平均O(logN)、最坏O(N)的复杂点进行节点查找,并支持顺序操作。Redis的跳跃表实现由
zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾节点、长度等),后者用于表示跳跃表节点。
基本命令
-
zadd key score member score2 member2 … :将所有成员以及该成员的分数存放到sorted-set中 -
zcard key:获取集合中的成员数量 -
zcount key min max:获取分数在[min,max]之间的成员 -
zincrby key increment member:设置指定成员的增加的分数。 -
zrange key start end [withscores]:获取集合中脚标为start-end的成员,[withscores]参数表明返回的成员包含其分数。 -
zrank key member:返回成员在集合中的位置。 -
zrem key members[member…]:移除集合中指定的成员,可以指定多个成员。 -
zscore key member:返回指定成员的分数
内存划分
数据
作为数据库,数据是最主要的部分;这部分占用的内存会统计在used_memory中。
进程本身运行需要的内存
Redis主进程或子进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
缓冲内存
缓冲内存包括客户端缓冲区、复制积压缓冲区、AOF缓冲区等;其中,客户端缓冲存储客户端连接的输入输出缓冲;复制积压缓冲用于部分复制功能;AOF缓冲区用于在进行AOF重写时,保存最近的写入命令。在了解相应功能之前,不需要知道这些缓冲的细节;这部分内存由jemalloc分配,因此会统计在used_memory中。
内存碎片
内存碎片是Redis在分配、回收物理内存过程中产生的。例如,如果对数据的更改频繁,而且数据之间的大小相差很大,可能导致redis释放的空间在物理内存中并没有释放,但redis又无法有效利用,这就形成了内存碎片。内存碎片不会统计在used_memory中。
内存分配器
Redis在编译时便会指定内存分配器;内存分配器可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc。
jemalloc作为Redis的默认内存分配器,在减小内存碎片方面做的相对比较好。jemalloc在64位系统中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当Redis存储数据时,会选择大小最合适的内存块进行存储。
jemalloc划分的内存单元如下图所示:
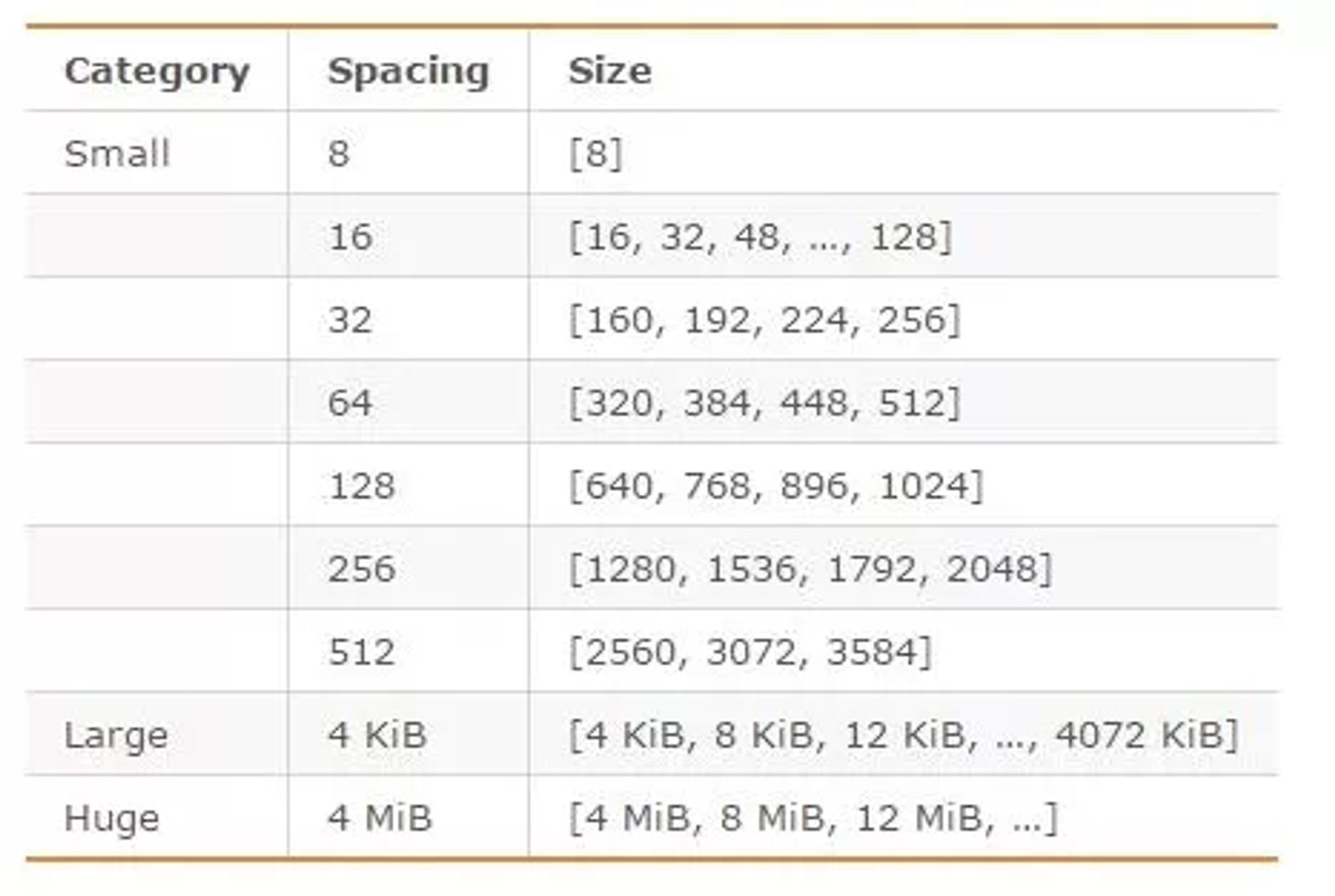
例如,如果需要存储大小为130字节的对象,jemalloc会将其放入160字节的内存单元中。
Redis内存统计
在客户端通过redis-cli连接服务器后(后面如无特殊说明,客户端一律使用redis-cli),通过info命令可以查看内存使用情况:
127.0.0.1:6379> info memory
# Memory
used_memory:853816
used_memory_human:833.80K
used_memory_rss:5742592
used_memory_rss_human:5.48M
used_memory_peak:853912
used_memory_peak_human:833.90K
used_memory_peak_perc:99.99%
used_memory_overhead:841486
used_memory_startup:791264
used_memory_dataset:12330
used_memory_dataset_perc:19.71%
allocator_allocated:845624
allocator_active:1015808
allocator_resident:8626176
total_system_memory:2095968256
total_system_memory_human:1.95G
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.20
allocator_frag_bytes:170184
allocator_rss_ratio:8.49
allocator_rss_bytes:7610368
rss_overhead_ratio:0.67
rss_overhead_bytes:-2883584
mem_fragmentation_ratio:7.07
mem_fragmentation_bytes:4929792
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:49694
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
其中,info命令可以显示redis服务器的许多信息,包括服务器基本信息、CPU、内存、持久化、客户端连接信息等等;memory是参数,表示只显示内存相关的信息。
返回结果中比较重要的几个说明如下:
-
used_memory:Redis分配器分配的内存总量(单位是字节),包括使用的虚拟内存(即swap);Redis分配器后面会介绍。used_memory_human只是显示更友好。 -
used_memory_rs:Redis进程占据操作系统的内存(单位是字节),与top及ps命令看到的值是一致的;除了分配器分配的内存之外,used_memory_rss还包括进程运行本身需要的内存、内存碎片等,但是不包括虚拟内存。因此,used_memory和used_memory_rss,前者是从Redis角度得到的量,后者是从操作系统角度得到的量。二者之所以有所不同,一方面是因为内存碎片和Redis进程运行需要占用内存,使得前者可能比后者小,另一方面虚拟内存的存在,使得前者可能比后者大。由于在实际应用中,Redis的数据量会比较大,此时进程运行占用的内存与Redis数据量和内存碎片相比,都会小得多;因此used_memory_rss和used_memory的比例,便成了衡量Redis内存碎片率的参数;这个参数就是mem_fragmentation_ratio。 -
mem_fragmentation_ratio:内存碎片比率,该值是used_memory_rss /used_memory的比值。mem_fragmentation_ratio一般大于1,且该值越大,内存碎片比例越大。mem_fragmentation_ratio<1,说明Redis使用了虚拟内存,由于虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。一般来说,mem_fragmentation_ratio在1.03左右是比较健康的状态(对于jemalloc来说);上面代码中的mem_fragmentation_ratio值很大,是因为还没有向Redis中存入数据,Redis进程本身运行的内存使得used_memory_rss 比used_memory大得多。 -
mem_allocator:Redis使用的内存分配器,在编译时指定;可以是libc 、jemalloc或者tcmalloc,默认是jemalloc。
bigKeys
redis-cli自带的一个命令。对整个redis进行扫描,寻找较大的key。
redis-cli -h b.redis -p 1959 --bigkeys
输出:
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).[00.00%] Biggest hash found so far 's_9329222' with 3 fields
[00.00%] Biggest string found so far 'url_http://mini.eastday.com/mobile/170722090206890.html?qid=sgllq&ch=east_sogou_push&pushid=13' with 8 bytes
[00.00%] Biggest string found so far 'foo' with 40 bytes
[00.00%] Biggest hash found so far 's_9329084' with 4 fields
[00.23%] Biggest zset found so far 'region_hot_菏泽地' with 625 members
[00.23%] Biggest zset found so far 'region_hot_葫芦岛' with 914 members
[00.47%] Biggest string found so far 'top_notice_list' with 135193 bytes
[00.73%] Biggest zset found so far 'region_hot_自贡' with 2092 members
[01.90%] Biggest hash found so far 'uno_facet_2018-12-20' with 59 fields
[11.87%] Biggest zset found so far 'region_hot_上海' with 2233 members
[27.05%] Biggest set found so far 'blacklist_set_key' with 31832 members
[73.87%] Biggest string found so far 'PUSH_NEWS' with 3104237 bytes
[86.18%] Biggest zset found so far 'region_hot_北京' with 2688 members-------- summary -------Sampled 4263 keys in the keyspace!
Total key length in bytes is 174847 (avg len 41.02)Biggest string found 'PUSH_NEWS' has 3104237 bytes
Biggest set found 'blacklist_set_key' has 31832 members
Biggest hash found 'uno_facet_2018-12-20' has 59 fields
Biggest zset found 'region_hot_北京' has 2688 members1616 strings with 3771161 bytes (37.91% of keys, avg size 2333.64)
0 lists with 0 items (00.00% of keys, avg size 0.00)
1 sets with 31832 members (00.02% of keys, avg size 31832.00)
2353 hashs with 7792 fields (55.20% of keys, avg size 3.31)
293 zsets with 333670 members (06.87% of keys, avg size 1138.81)
该命令使用scan方式对key进行统计,所以使用时无需担心对redis造成阻塞。
输出大概分为两部分,summary之上的部分,只是显示了扫描的过程。summary部分给出了每种数据结构中最大的Key。统计出的最大key只有string类型是以字节长度为衡量标准的。list,set,zset等都是以元素个数作为衡量标准,不能说明其占的内存就一定多。所以,如果你的Key主要以string类型存在,这种方法就比较适合。
debug object key
redis的命令,可以查看某个key序列化后的长度。
连接上redis后执行如下命令b.redis:1959> hmset myhash k1 v1 k2 v2 k3 v3
OK
b.redis:1959> debug object myhash
Value at:0x7f005c6920a0 refcount:1 encoding:ziplist serializedlength:36 lru:3341677 lru_seconds_idle:2
-
Value at:key的内存地址refcount:引用次数 -
encoding:编码类型 -
serializedlength:序列化长度 -
lru_seconds_idle:空闲时间
应用举例
估算Redis内存使用量
假设有90000个键值对,每个key的长度是7个字节,每个value的长度也是7个字节(且key和value都不是整数);下面来估算这90000个键值对所占用的空间。在估算占据空间之前,首先可以判定字符串类型使用的编码方式:embstr。
90000个键值对占据的内存空间主要可以分为两部分:一部分是90000个dictEntry占据的空间;一部分是键值对所需要的bucket空间。
每个dictEntry占据的空间包括:
- 一个
dictEntry,24字节,jemalloc会分配32字节的内存块 - 一个
key,7字节,所以SDS(key)需要7+9=16个字节,jemalloc会分配16字节的内存块 - 一个
redisObject,16字节,jemalloc会分配16字节的内存块 - 一个
value,7字节,所以SDS(value)需要7+9=16个字节,jemalloc会分配16字节的内存块
综上,一个dictEntry需要32+16+16+16=80个字节。
bucket空间:bucket数组的大小为大于90000的最小的2^n,是131072;每个bucket元素为8字节(因为64位系统中指针大小为8字节)。
因此,可以估算出这90000个键值对占据的内存大小为:9000080 + 1310728 = 8248576。
下面写个程序在redis中验证一下:
publicclass RedisTest {publicstatic Jedis jedis = new Jedis("localhost", 6379);public static void main(String[] args) throws Exception{Long m1 = Long.valueOf(getMemory());insertData();Long m2 = Long.valueOf(getMemory());System.out.println(m2 - m1);}public static void insertData(){for(int i = 10000; i < 100000; i++){jedis.set("aa" + i, "aa" + i); //key和value长度都是7字节,且不是整数}}public static String getMemory(){String memoryAllLine = jedis.info("memory");String usedMemoryLine = memoryAllLine.split("\\r\\n")[1];String memory = usedMemoryLine.substring(usedMemoryLine.indexOf(':') + 1);return memory;}
}
运行结果:8247552
优化内存占用
利用jemalloc特性进行优化
由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用内存很大的变动;在设计时可以利用这一点。
例如,如果key的长度如果是8个字节,则SDS为17字节,jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则每个key所占用的空间都可以缩小一半。
使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。
共享对象
利用共享对象,可以减少对象的创建(同时减少了redisObject的创建),节省内存空间。目前redis中的共享对象只包括10000个整数(0-9999);可以通过调整REDIS_SHARED_INTEGERS参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可以共享。
考虑这样一种场景:论坛网站在redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。
避免过度设计
然而需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影响到代码的复杂度、可维护性。
如果数据量较小,那么为了节省内存而使得代码的开发、维护变得更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
关注内存碎片率
内存碎片率是一个重要的参数,对redis 内存的优化有重要意义。
- 如果内存碎片率过高(
jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重;这时便可以考虑重启redis服务,在内存中对数据进行重排,减少内存碎片。 - 如果内存碎片率小于1,说明
redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取速度比物理内存差很多(2-3个数量级),此时redis的访问速度可能会变得很慢。因此必须设法增大物理内存(可以增加服务器节点数量,或提高单机内存),或减少redis中的数据。
要减少redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。