
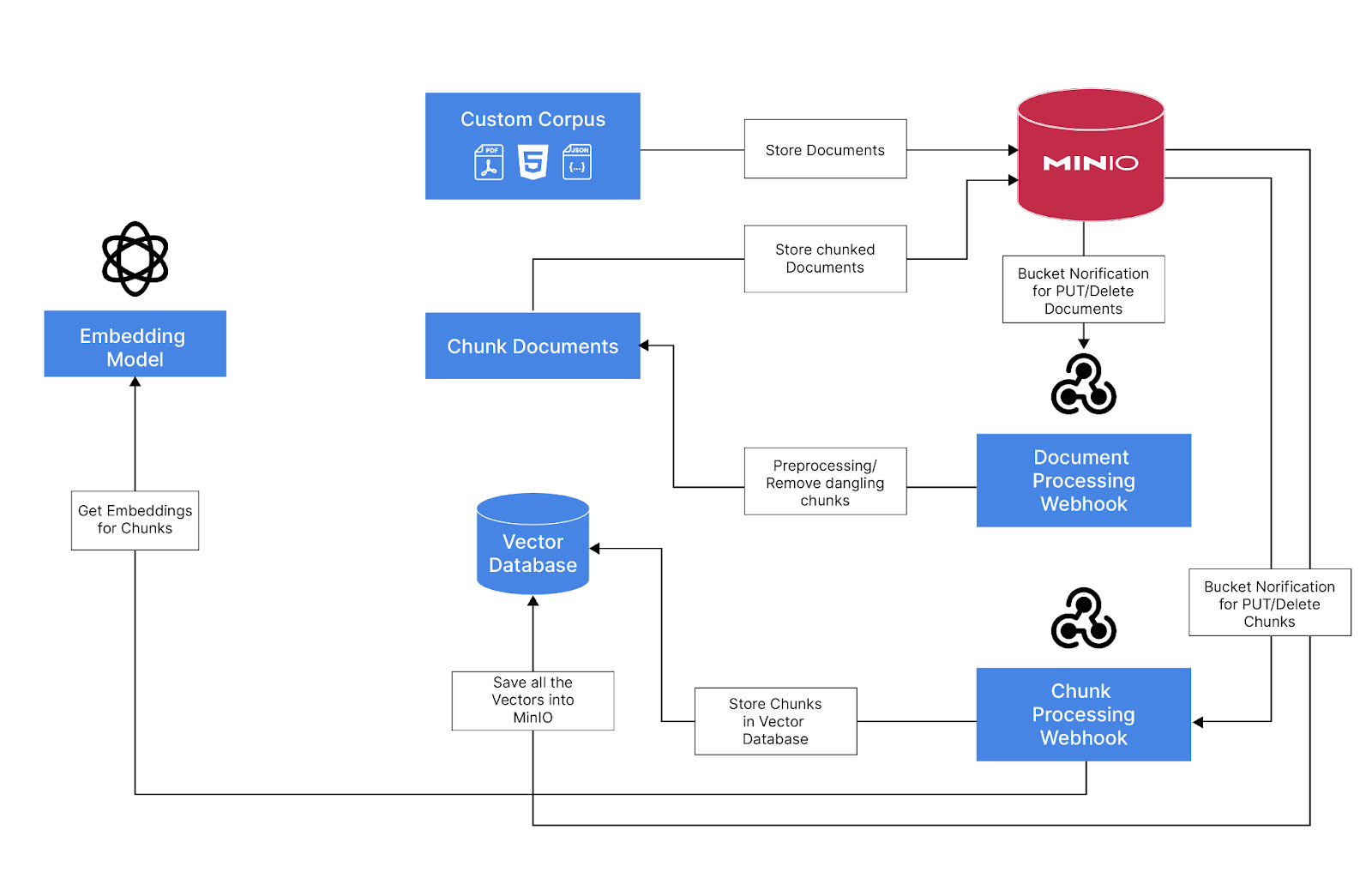
人们常说,在人工智能时代,数据是你的护城河。为此,构建生产级 RAG 应用程序需要合适的数据基础架构来存储、版本控制、处理、评估和查询构成专有语料库的数据块。由于 MinIO 采用数据优先的 AI 方法,因此对于此类项目,我们默认的初始基础结构建议是设置现代数据湖 (MinIO) 和向量数据库。虽然在此过程中可能需要插入其他辅助工具,但这两个基础架构单元是基础。它们将作为随后在将 RAG 应用程序投入生产时遇到的几乎所有任务的重心。
但你陷入了一个难题。您以前听说过这些术语LLM和 RAG,但除此之外,由于未知,您并没有冒险太多。但是,如果有一个“Hello World”或样板应用程序可以帮助您入门,那不是很好吗?
别担心,我在同一条船上。因此,在这篇博客中,我们将演示如何使用 MinIO 使用商用硬件构建基于检索增强生成 (RAG) 的聊天应用程序。
-
使用 MinIO 存储所有文档、处理过的块和使用矢量数据库的嵌入。
-
使用 MinIO 的存储桶通知功能在向存储桶添加或删除文档时触发事件
-
Webhook,使用事件并使用 Langchain 处理文档,并将元数据和分块文档保存到元数据桶中
-
为新添加或删除的分块文档触发 MinIO 存储桶通知事件
-
一个 Webhook,它使用事件并生成嵌入并将其保存到 MinIO 中保存的向量数据库 (LanceDB)
使用的关键工具
-
MinIO - 用于持久化所有数据的对象存储
-
LanceDB - 将数据持久化在对象存储中的无服务器开源向量数据库
-
Ollama - 在本地运行LLM和嵌入模型(兼容 OpenAI API)
-
Gradio - 与 RAG 应用程序交互的接口
-
FastAPI - 用于接收来自 MinIO 的存储桶通知并公开 Gradio 应用程序的 Webhook 服务器
-
LangChain & Unstructured - 从我们的文档中提取有用的文本,并将它们分块进行嵌入
使用的型号
-
LLM - Phi-3-128K(3.8B参数)
-
嵌入 - Nomic Embed Text v1.5 ( Matryoshka Embeddings/ 768 Dim, 8K context)
启动 MinIO 服务器
如果您还没有二进制文件,您可以从这里下载它
# Run MinIO detached
!minio server ~/dev/data --console-address :9090 &
启动Ollama Server + Download LLM & Embedding Model
从这里下载Ollama
# Start the Server
!ollama serve
# Download Phi-3 LLM
!ollama pull phi3:3.8b-mini-128k-instruct-q8_0
# Download Nomic Embed Text v1.5
!ollama pull nomic-embed-text:v1.5
# List All the Models
!ollama ls
使用 FastAPI 创建基本 Gradio 应用以测试模型
LLM_MODEL = "phi3:3.8b-mini-128k-instruct-q8_0"
EMBEDDING_MODEL = "nomic-embed-text:v1.5"
LLM_ENDPOINT = "http://localhost:11434/api/chat"
CHAT_API_PATH = "/chat"
def llm_chat(user_question, history):
history = history or []
user_message = f"**You**: {user_question}"
llm_resp = requests.post(LLM_ENDPOINT,
json={"model": LLM_MODEL,
"keep_alive": "48h", # Keep the model in-memory for 48 hours
"messages": [
{"role": "user",
"content": user_question
}
]},
stream=True)
bot_response = "**AI:** "
for resp in llm_resp.iter_lines():
json_data = json.loads(resp)
bot_response += json_data["message"]["content"]
yield bot_response
import json
import gradio as gr
import requests
from fastapi import FastAPI, Request, BackgroundTasks
from pydantic import BaseModel
import uvicorn
import nest_asyncio
app = FastAPI()
with gr.Blocks(gr.themes.Soft()) as demo:
gr.Markdown("## RAG with MinIO")
ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear")
ch_interface.chatbot.show_label = False
ch_interface.chatbot.height = 600
demo.queue()
if __name__ == "__main__":
nest_asyncio.apply()
app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH)
uvicorn.run(app, host="0.0.0.0", port=8808)
测试嵌入模型
import numpy as np
EMBEDDING_ENDPOINT = "http://localhost:11434/api/embeddings"
EMBEDDINGS_DIM = 768
def get_embedding(text):
resp = requests.post(EMBEDDING_ENDPOINT,
json={"model": EMBEDDING_MODEL,
"prompt": text})
return np.array(resp.json()["embedding"][:EMBEDDINGS_DIM], dtype=np.float16)
## Test with sample text
get_embedding("What is MinIO?")
引入管道概述

创建 MinIO 存储桶
使用 mc 命令或从 UI 执行此操作
-
custom-corpus - 存储所有文档
-
warehouse - 存储所有元数据、块和向量嵌入
!mc alias set 'myminio' 'http://localhost:9000' 'minioadmin' 'minioadmin'
!mc mb myminio/custom-corpus
!mc mb myminio/warehouse
创建从自定义语料库存储桶使用存储桶通知的 Webhook
import json
import gradio as gr
import requests
from fastapi import FastAPI, Request
from pydantic import BaseModel
import uvicorn
import nest_asyncio
app = FastAPI()
@app.post("/api/v1/document/notification")
async def receive_webhook(request: Request):
json_data = await request.json()
print(json.dumps(json_data, indent=2))
with gr.Blocks(gr.themes.Soft()) as demo:
gr.Markdown("## RAG with MinIO")
ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear")
ch_interface.chatbot.show_label = False
demo.queue()
if __name__ == "__main__":
nest_asyncio.apply()
app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH)
uvicorn.run(app, host="0.0.0.0", port=8808)
## Test with sample text
get_embedding("What is MinIO?")
创建 MinIO 事件通知并将其链接到 custom-corpus 存储桶
创建 Webhook 事件
在控制台中,转到 Events-> Add Event Destination -> Webhook
用以下值填写字段并点击保存
标识符 - doc-webhook
端点 - http://localhost:8808/api/v1/document/notification
单击顶部的 Restart MinIO (重新启动 MinIO) 时,将其设置为
(注意:您也可以为此使用 mc)
将 Webhook 事件链接到 custom-corpus bucket 事件
在控制台中,转到 Buckets (Administrator) -> custom-corpus -> Events
用以下值填写字段并点击保存
ARN - 从下拉列表中选择 doc-webhook
选择事件 - 选中 PUT 和 DELETE
(注意:您也可以为此使用 mc)
我们有了第一个 webhook 设置
现在通过添加和删除对象进行测试
从文档和区块中提取数据
我们将使用 Langchain 和 Unstructured 从 MinIO 读取对象,并将文档拆分为多个块
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import S3FileLoader
MINIO_ENDPOINT = "http://localhost:9000"
MINIO_ACCESS_KEY = "minioadmin"
MINIO_SECRET_KEY = "minioadmin"
# Split Text from a given document using chunk_size number of characters
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024,
chunk_overlap=64,
length_function=len)
def split_doc_by_chunks(bucket_name, object_key):
loader = S3FileLoader(bucket_name,
object_key,
endpoint_url=MINIO_ENDPOINT,
aws_access_key_id=MINIO_ACCESS_KEY,
aws_secret_access_key=MINIO_SECRET_KEY)
docs = loader.load()
doc_splits = text_splitter.split_documents(docs)
return doc_splits
# test the chunking
split_doc_by_chunks("custom-corpus", "The-Enterprise-Object-Store-Feature-Set.pdf")
将分块逻辑添加到 Webhook
将块逻辑添加到 webhook 中,并将元数据和块保存到仓库存储桶中
import urllib.parse
import s3fs
METADATA_PREFIX = "metadata"
# Using s3fs to save and delete objects from MinIO
s3 = s3fs.S3FileSystem()
# Split the documents and save the metadata to warehouse bucket
def create_object_task(json_data):
for record in json_data["Records"]:
bucket_name = record["s3"]["bucket"]["name"]
object_key = urllib.parse.unquote(record["s3"]["object"]["key"])
print(record["s3"]["bucket"]["name"],
record["s3"]["object"]["key"])
doc_splits = split_doc_by_chunks(bucket_name, object_key)
for i, chunk in enumerate(doc_splits):
source = f"warehouse/{METADATA_PREFIX}/{bucket_name}/{object_key}/chunk_{i:05d}.json"
with s3.open(source, "w") as f:
f.write(chunk.json())
return "Task completed!"
def delete_object_task(json_data):
for record in json_data["Records"]:
bucket_name = record["s3"]["bucket"]["name"]
object_key = urllib.parse.unquote(record["s3"]["object"]["key"])
s3.delete(f"warehouse/{METADATA_PREFIX}/{bucket_name}/{object_key}", recursive=True)
return "Task completed!"
使用新逻辑更新 FastAPI 服务器
import gradio as gr
import requests
from fastapi import FastAPI, Request, BackgroundTasks
from pydantic import BaseModel
import uvicorn
import nest_asyncio
app = FastAPI()
@app.post("/api/v1/document/notification")
async def receive_webhook(request: Request, background_tasks: BackgroundTasks):
json_data = await request.json()
if json_data["EventName"] == "s3:ObjectCreated:Put":
print("New object created!")
background_tasks.add_task(create_object_task, json_data)
if json_data["EventName"] == "s3:ObjectRemoved:Delete":
print("Object deleted!")
background_tasks.add_task(delete_object_task, json_data)
return {"status": "success"}
with gr.Blocks(gr.themes.Soft()) as demo:
gr.Markdown("## RAG with MinIO")
ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear")
ch_interface.chatbot.show_label = False
demo.queue()
if __name__ == "__main__":
nest_asyncio.apply()
app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH)
uvicorn.run(app, host="0.0.0.0", port=8808)
添加新的 Webhook 以处理文档元数据/块
现在我们有了第一个 webhook,下一步是获取所有带有元数据的块,生成嵌入并将其存储在向量数据库中
import json
import gradio as gr
import requests
from fastapi import FastAPI, Request, BackgroundTasks
from pydantic import BaseModel
import uvicorn
import nest_asyncio
app = FastAPI()
@app.post("/api/v1/metadata/notification")
async def receive_metadata_webhook(request: Request, background_tasks: BackgroundTasks):
json_data = await request.json()
print(json.dumps(json_data, indent=2))
@app.post("/api/v1/document/notification")
async def receive_webhook(request: Request, background_tasks: BackgroundTasks):
json_data = await request.json()
if json_data["EventName"] == "s3:ObjectCreated:Put":
print("New object created!")
background_tasks.add_task(create_object_task, json_data)
if json_data["EventName"] == "s3:ObjectRemoved:Delete":
print("Object deleted!")
background_tasks.add_task(delete_object_task, json_data)
return {"status": "success"}
with gr.Blocks(gr.themes.Soft()) as demo:
gr.Markdown("## RAG with MinIO")
ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear")
ch_interface.chatbot.show_label = False
demo.queue()
if __name__ == "__main__":
nest_asyncio.apply()
app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH)
uvicorn.run(app, host="0.0.0.0", port=8808)
创建 MinIO 事件通知并将其链接到仓库存储桶
创建 Webhook 事件
在控制台中,转到 Events-> Add Event Destination -> Webhook
用以下值填写字段并点击保存
标识符 - metadata-webhook
端点 - http://localhost:8808/api/v1/metadata/notification
当出现提示时,单击顶部的重新启动 MinIO
(注意:您也可以为此使用 mc)
将 Webhook 事件链接到 custom-corpus bucket 事件
在控制台中,转到 Buckets (Administrator) -> warehouse -> Events
用以下值填写字段并点击保存
ARN - 从下拉列表中选择 metadata-webhook
前缀 - metadata/
后缀 - .json
选择事件 - 选中 PUT 和 DELETE
(注意:您也可以为此使用 mc)
我们有了第一个 webhook 设置
现在通过在自定义语料库中添加和删除对象进行测试,看看是否触发了此 Webhook
在 MinIO 中创建 LanceDB 向量数据库
现在我们已经有了基本的 webhook 工作,让我们在 MinIO 仓库桶中设置 lanceDB vector databse,我们将在其中保存所有嵌入和其他元数据字段
import os
import lancedb
# Set these environment variables for the lanceDB to connect to MinIO
os.environ["AWS_DEFAULT_REGION"] = "us-east-1"
os.environ["AWS_ACCESS_KEY_ID"] = MINIO_ACCESS_KEY
os.environ["AWS_SECRET_ACCESS_KEY"] = MINIO_SECRET_KEY
os.environ["AWS_ENDPOINT"] = MINIO_ENDPOINT
os.environ["ALLOW_HTTP"] = "True"
db = lancedb.connect("s3://warehouse/v-db/")
# list existing tables
db.table_names()
# Create a new table with pydantic schema
from lancedb.pydantic import LanceModel, Vector
import pyarrow as pa
DOCS_TABLE = "docs"
EMBEDDINGS_DIM = 768
table = None
class DocsModel(LanceModel):
parent_source: str # Actual object/document source
source: str # Chunk/Metadata source
text: str # Chunked text
vector: Vector(EMBEDDINGS_DIM, pa.float16()) # Vector to be stored
def get_or_create_table():
global table
if table is None and DOCS_TABLE not in list(db.table_names()):
return db.create_table(DOCS_TABLE, schema=DocsModel)
if table is None:
table = db.open_table(DOCS_TABLE)
return table
# Check if that worked
get_or_create_table()
# list existing tables
db.table_names()
将 lanceDB 中的存储/删除数据添加到 metadata-webhook
import multiprocessing
EMBEDDING_DOCUMENT_PREFIX = "search_document"
# Add queue that keeps the processed meteadata in memory
add_data_queue = multiprocessing.Queue()
delete_data_queue = multiprocessing.Queue()
def create_metadata_task(json_data):
for record in json_data["Records"]:
bucket_name = record["s3"]["bucket"]["name"]
object_key = urllib.parse.unquote(record["s3"]["object"]["key"])
print(bucket_name,
object_key)
with s3.open(f"{bucket_name}/{object_key}", "r") as f:
data = f.read()
chunk_json = json.loads(data)
embeddings = get_embedding(f"{EMBEDDING_DOCUMENT_PREFIX}: {chunk_json['page_content']}")
add_data_queue.put({
"text": chunk_json["page_content"],
"parent_source": chunk_json.get("metadata", "").get("source", ""),
"source": f"{bucket_name}/{object_key}",
"vector": embeddings
})
return "Metadata Create Task Completed!"
def delete_metadata_task(json_data):
for record in json_data["Records"]:
bucket_name = record["s3"]["bucket"]["name"]
object_key = urllib.parse.unquote(record["s3"]["object"]["key"])
delete_data_queue.put(f"{bucket_name}/{object_key}")
return "Metadata Delete Task completed!"
添加用于处理队列中数据的调度程序
from apscheduler.schedulers.background import BackgroundScheduler
import pandas as pd
def add_vector_job():
data = []
table = get_or_create_table()
while not add_data_queue.empty():
item = add_data_queue.get()
data.append(item)
if len(data) > 0:
df = pd.DataFrame(data)
table.add(df)
table.compact_files()
print(len(table.to_pandas()))
def delete_vector_job():
table = get_or_create_table()
source_data = []
while not delete_data_queue.empty():
item = delete_data_queue.get()
source_data.append(item)
if len(source_data) > 0:
filter_data = ", ".join([f'"{d}"' for d in source_data])
table.delete(f'source IN ({filter_data})')
table.compact_files()
table.cleanup_old_versions()
print(len(table.to_pandas()))
scheduler = BackgroundScheduler()
scheduler.add_job(add_vector_job, 'interval', seconds=10)
scheduler.add_job(delete_vector_job, 'interval', seconds=10)
使用矢量嵌入更改更新 FastAPI
import json
import gradio as gr
import requests
from fastapi import FastAPI, Request, BackgroundTasks
from pydantic import BaseModel
import uvicorn
import nest_asyncio
app = FastAPI()
@app.on_event("startup")
async def startup_event():
get_or_create_table()
if not scheduler.running:
scheduler.start()
@app.on_event("shutdown")
async def shutdown_event():
scheduler.shutdown()
@app.post("/api/v1/metadata/notification")
async def receive_metadata_webhook(request: Request, background_tasks: BackgroundTasks):
json_data = await request.json()
if json_data["EventName"] == "s3:ObjectCreated:Put":
print("New Metadata created!")
background_tasks.add_task(create_metadata_task, json_data)
if json_data["EventName"] == "s3:ObjectRemoved:Delete":
print("Metadata deleted!")
background_tasks.add_task(delete_metadata_task, json_data)
return {"status": "success"}
@app.post("/api/v1/document/notification")
async def receive_webhook(request: Request, background_tasks: BackgroundTasks):
json_data = await request.json()
if json_data["EventName"] == "s3:ObjectCreated:Put":
print("New object created!")
background_tasks.add_task(create_object_task, json_data)
if json_data["EventName"] == "s3:ObjectRemoved:Delete":
print("Object deleted!")
background_tasks.add_task(delete_object_task, json_data)
return {"status": "success"}
with gr.Blocks(gr.themes.Soft()) as demo:
gr.Markdown("## RAG with MinIO")
ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear")
ch_interface.chatbot.show_label = False
ch_interface.chatbot.height = 600
demo.queue()
if __name__ == "__main__":
nest_asyncio.apply()
app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH)
uvicorn.run(app, host="0.0.0.0", port=8808)
现在,我们已经有了引入管道,让我们集成最终的 RAG 管道。
添加矢量搜索功能
现在,我们已经将文档摄取到 lanceDB 中,让我们添加搜索功能
EMBEDDING_QUERY_PREFIX = "search_query"
def search(query, limit=5):
query_embedding = get_embedding(f"{EMBEDDING_QUERY_PREFIX}: {query}")
res = get_or_create_table().search(query_embedding).metric("cosine").limit(limit)
return res
# Lets test to see if it works
res = search("What is MinIO Enterprise Object Store Lite?")
res.to_list()
提示LLM使用相关文件
RAG_PROMPT = """
DOCUMENT:
{documents}
QUESTION:
{user_question}
INSTRUCTIONS:
Answer in detail the user's QUESTION using the DOCUMENT text above.
Keep your answer ground in the facts of the DOCUMENT. Do not use sentence like "The document states" citing the document.
If the DOCUMENT doesn't contain the facts to answer the QUESTION only Respond with "Sorry! I Don't know"
"""
context_df = []
def llm_chat(user_question, history):
history = history or []
global context_df
# Search for relevant document chunks
res = search(user_question)
documents = " ".join([d["text"].strip() for d in res.to_list()])
# Pass the chunks to LLM for grounded response
llm_resp = requests.post(LLM_ENDPOINT,
json={"model": LLM_MODEL,
"messages": [
{"role": "user",
"content": RAG_PROMPT.format(user_question=user_question, documents=documents)
}
],
"options": {
# "temperature": 0,
"top_p": 0.90,
}},
stream=True)
bot_response = "**AI:** "
for resp in llm_resp.iter_lines():
json_data = json.loads(resp)
bot_response += json_data["message"]["content"]
yield bot_response
context_df = res.to_pandas()
context_df = context_df.drop(columns=['source', 'vector'])
def clear_events():
global context_df
context_df = []
return context_df
更新 FastAPI 聊天终端节点以使用 RAG
import json
import gradio as gr
import requests
from fastapi import FastAPI, Request, BackgroundTasks
from pydantic import BaseModel
import uvicorn
import nest_asyncio
app = FastAPI()
@app.on_event("startup")
async def startup_event():
get_or_create_table()
if not scheduler.running:
scheduler.start()
@app.on_event("shutdown")
async def shutdown_event():
scheduler.shutdown()
@app.post("/api/v1/metadata/notification")
async def receive_metadata_webhook(request: Request, background_tasks: BackgroundTasks):
json_data = await request.json()
if json_data["EventName"] == "s3:ObjectCreated:Put":
print("New Metadata created!")
background_tasks.add_task(create_metadata_task, json_data)
if json_data["EventName"] == "s3:ObjectRemoved:Delete":
print("Metadata deleted!")
background_tasks.add_task(delete_metadata_task, json_data)
return {"status": "success"}
@app.post("/api/v1/document/notification")
async def receive_webhook(request: Request, background_tasks: BackgroundTasks):
json_data = await request.json()
if json_data["EventName"] == "s3:ObjectCreated:Put":
print("New object created!")
background_tasks.add_task(create_object_task, json_data)
if json_data["EventName"] == "s3:ObjectRemoved:Delete":
print("Object deleted!")
background_tasks.add_task(delete_object_task, json_data)
return {"status": "success"}
with gr.Blocks(gr.themes.Soft()) as demo:
gr.Markdown("## RAG with MinIO")
ch_interface = gr.ChatInterface(llm_chat, undo_btn=None, clear_btn="Clear")
ch_interface.chatbot.show_label = False
ch_interface.chatbot.height = 600
gr.Markdown("### Context Supplied")
context_dataframe = gr.DataFrame(headers=["parent_source", "text", "_distance"], wrap=True)
ch_interface.clear_btn.click(clear_events, [], context_dataframe)
@gr.on(ch_interface.output_components, inputs=[ch_interface.chatbot], outputs=[context_dataframe])
def update_chat_context_df(text):
global context_df
if context_df is not None:
return context_df
return ""
demo.queue()
if __name__ == "__main__":
nest_asyncio.apply()
app = gr.mount_gradio_app(app, demo, path=CHAT_API_PATH)
uvicorn.run(app, host="0.0.0.0", port=8808)
RAGs-R-Us
作为 MinIO 专注于 AI 集成的开发人员,我一直在探索如何将我们的工具无缝集成到现代 AI 架构中,以提高效率和可扩展性。在本文中,我们向您展示了如何将 MinIO 与检索增强生成 (RAG) 集成以构建聊天应用程序。这只是冰山一角,可以推动您为 RAG 和 MinIO 构建更多独特的用例。现在,您已经具备了执行此操作的构建块。让我们开始吧!














![[论文笔记]RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL](https://img-blog.csdnimg.cn/img_convert/4ff13ba7d84e018ef4a4c93c5803adea.png)


