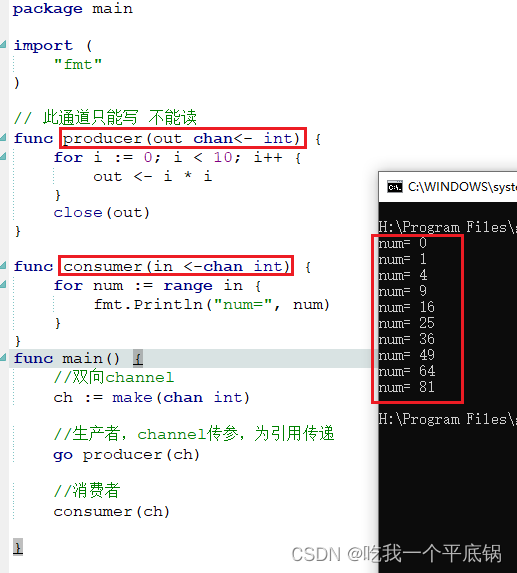
模型层 ( Model Layer ) 是MVC或MTV架构中的一个核心组成部分 , 它主要负责定义和管理应用程序中的数据结构及其行为 .
具体职责包括 :
* 1. 封装数据 : 模型层封装了应用程序所需的所有数据 , 这些数据以结构化的形式存在 , 如数据库表 , 对象等 .
* 2. 数据操作 : 执行与数据相关的所有操作 , 包括但不限于数据的验证 ( 确保数据的正确性和完整性 ) , 数据的持久化 ( 将数据保存到数据库或其他持久化存储中 ) , 以及业务规则的实现 ( 确保数据操作符合业务逻辑 ) .
* 3. 提供接口 : 模型层通过定义良好的接口 , 使得视图层 ( 或模板层 ) 和控制器层 ( 或其他逻辑处理层 ) 能够与之交互 , 进行数据的读取 , 更新 , 删除等操作 , 而无需深入了解数据的具体存储方式或实现细节 . 通过这种方式 , 模型层在MVC或MTV框架中起到了桥梁作用 , 它不仅连接了数据世界与业务逻辑 ,
还通过接口将数据的操作细节隐藏起来 , 使得其他部分可以更加专注于自身的职责 , 从而提高了整个应用程序的模块化和可维护性 .
为了实现这一目的 , 模型层是借助对象关系映射 ( ORM ) 技术来实现 .
ORM技术或框架通过提供一套机制 , 允许开发者以 '面向对象' 的方式来操作数据库 , 从而避免了直接编写SQL语句的复杂性 .
ORM通过映射应用程序中的对象到数据库中的表和列 , 自动处理对象的保存 , 检索 , 更新和删除等操作 , 并生成相应的SQL语句 .
这种映射不仅简化了数据库操作 , 还减少了开发者在数据库层面上的工作量 , 提高了开发效率 , 并降低了出错的风险 .
Django ORM的特点 :
* 1. 解耦性 : Django ORM实现了数据模型与数据库的解耦 . 开发者可以设计数据模型而不必关心底层数据库的具体实现 . 当需要更换数据库时 , 只需更改Django的配置文件即可 , 无需修改数据模型或业务逻辑代码 .
* 2. 方便性 : 使用Django ORM , 开发者可以通过简单的Python代码来执行数据库的增删改查 ( CRUD ) 操作 . ORM会自动将Python代码转换为对应的SQL语句 , 并执行它们 .
* 3. 安全性 : Django ORM提供了许多内置的保护机制 , 比如防止SQL注入攻击 . 开发者无需担心自己编写的SQL语句会被恶意利用 .
* 4. 灵活性 : 尽管Django ORM提供了大量的便利 , 但开发者仍然可以在需要时直接编写SQL语句 . Django允许通过RawSQL或其他方式直接执行原生SQL语句 .
在使用ORM的框架时 , 开发者通过定义模型类 ( 这些类继承自ORM框架提供的基类并定义数据的结构和行为 ) 来构建模型层 .
随后 , ORM框架会根据这些模型类的定义自动创建数据库表 , 并在应用程序运行时执行各种数据库操作 .
通过这种方式 , 开发者能够更专注于业务逻辑的实现 , 而无需深入关注数据库的具体实现细节 .
同时 , 它也提高了代码的可移植性和可维护性 , 因为更换数据库时 , 只需要修改ORM的配置 , 而不需要修改大量的业务代码 .
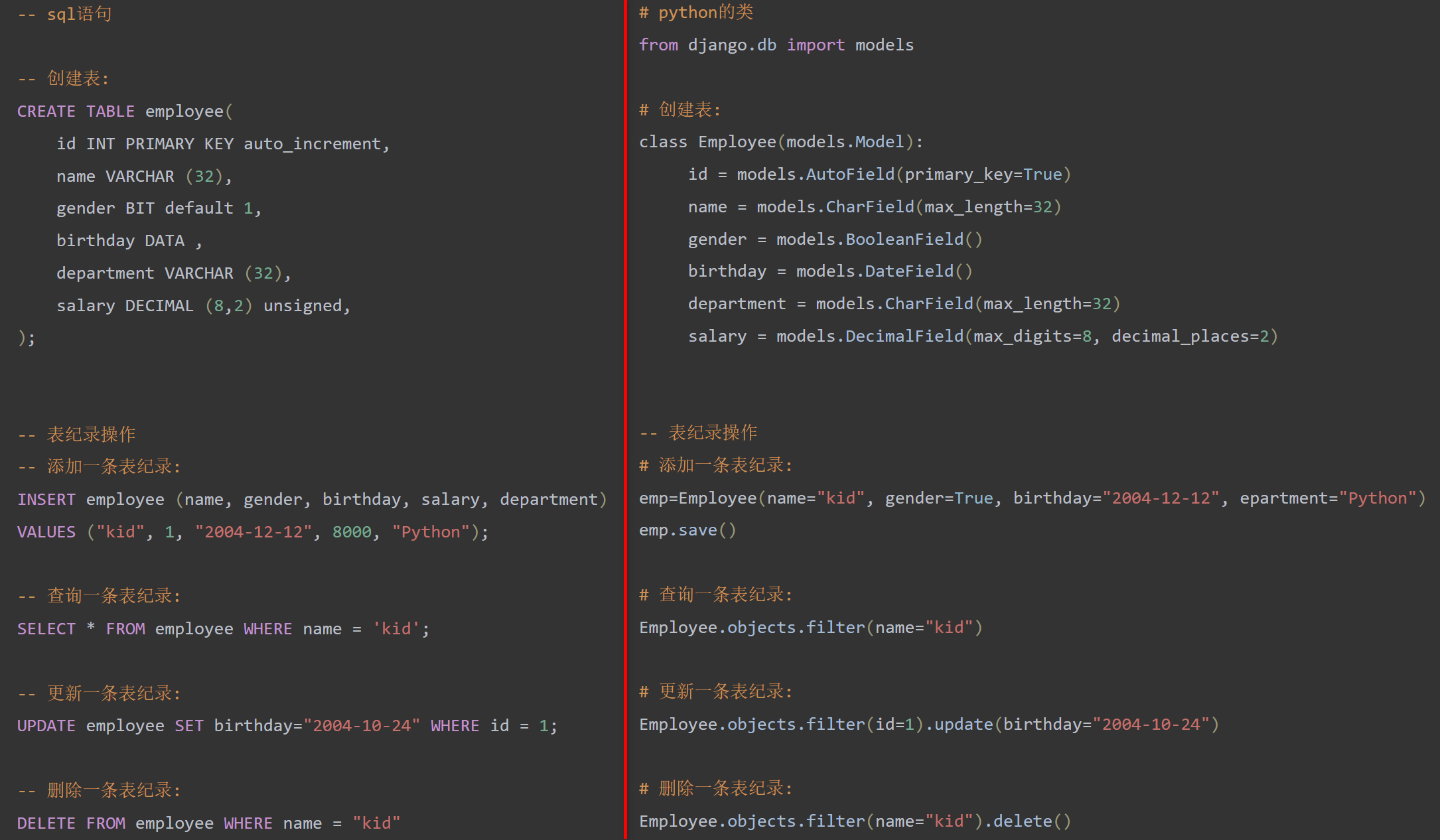
SQL语句与ORM语句对比预览 :
CREATE TABLE employee( id INT PRIMARY KEY auto_increment , name VARCHAR ( 32 ) , gender BIT default 1 , birthday DATA , department VARCHAR ( 32 ) , salary DECIMAL ( 8 , 2 ) unsigned ,
) ;
INSERT employee ( name, gender, birthday, salary, department)
VALUES ( "kid" , 1 , "2004-12-12" , 8000 , "Python" ) ;
SELECT * FROM employee WHERE name = 'kid' ;
UPDATE employee SET birthday= "2004-10-24" WHERE id = 1 ;
DELETE FROM employee WHERE name = "kid"
from django. db import models
class Employee( models. Model) :id = models. AutoField( primary_key= True ) name = models. CharField( max_length= 32 ) gender = models. BooleanField( ) birthday = models. DateField( ) department = models. CharField( max_length= 32 ) salary = models. DecimalField( max_digits= 8 , decimal_places= 2 )
emp= Employee( name= "kid" , gender= True , birthday= "2004-12-12" , epartment= "Python" )
emp. save ( )
Employee. objects. filter( name= "kid" )
Employee. objects. filter( id= 1 ) . update ( birthday= "2004-10-24" )
Employee. objects. filter( name= "kid" ) . delete ( )
在Web开发领域 , 随着应用复杂性的增加 ,
开发者们逐渐意识到将应用的不同部分分离成独立的组件可以提高代码的可维护性 , 可扩展性和可测试性 .
MVC框架就是这样一种设计模式的代表 , 它将Web应用划分为三个核心部分 : 模型 , 视图 , 控制器 .
虽然Django框架在官方文档中使用了MTV的术语来描述其架构 , 但本质上它与MVC非常相似 ,
只是将视图层中的 '视图' 部分进一步细分为模板 ( Template ) 和视图逻辑 ( View Logic ) . 在MVC框架中 , 数据库操作主要集中在模型层 , 模型与数据库之间的交互通常通过ORM ( 对象关系映射 ) 来实现 ,
这进一步简化了数据库操作并提高了开发效率 . 以下 , 将详细解析MVC / MTV框架下的数据库操作层次 , 从数据库本身开始 , 一直到用户通过前端界面与Web应用进行交互的整个过程 .
这个过程中 , 会看到每个层次是如何相互协作 , 共同实现一个高效 , 可扩展的Web应用的 .
MVC / MTV框架下的数据库操作层次解析 : 数据库 ( 如 : MySQL ) | v
数据库驱动 ( 如 : MySQL Connector / Python , PyMySQL , mysqlclient ) | v
ORM ( 对象关系映射 , 如 : Django ORM , SQLAlchemy ) | v
MVC / MTV 框架 | + ---- 模型层 ( Model ) | | | v | 与ORM直接交互,定义数据结构和行为 | + ---- 视图层 ( View ) / 模板层 ( Template ) | | | v | 负责渲染数据到用户界面 | + ---- 控制器层(Controller) / 业务逻辑层 | | | v | 处理用户输入 , 调用模型层进行数据操作 , 并与视图层进行交互 | | v
应用程序 ( 如 : Django , Flask 项目 ) | v
用户 / 前端 ( 通过浏览器或其他客户端访问 )
MVC / MTV框架下的数据库操作层次说明 :
- 数据库 ( 如 : MySQL ) : 这是存储数据的系统 , 可以是关系型数据库 ( 如 : MySQL , PostgreSQL ) 或非关系型数据库 ( 如 : MongoDB , Redis ) .
- 数据库驱动 ( 如 : PyMySQL , mysqlclient ) : 这些是Python库 , 用于Python程序与数据库之间的通信 . 它们提供了Python代码可以直接调用的API来执行SQL语句 , 管理数据库连接等 .
- ORM ( 对象关系映射 ) : ORM在数据库驱动之上又进行了一层封装 , 它允许开发者使用面向对象的方式来操作数据库 , 而不是直接写SQL语句 . ORM将数据库中的表映射为Python中的类 , 表中的行映射为类的实例 , 列则映射为实例的属性 . 开发者可以通过操作这些类和实例来间接地操作数据库 , 而无需关心底层的SQL语句和数据库细节 . 常见的Python ORM有Django ORM ( Django框架自带 ) , SQLAlchemy等 .
- 应用程序 ( 如 : Django , Flask 项目 ) : 这些是开发者使用Python和ORM等库构建的实际应用程序 . 应用程序通过ORM与数据库进行交互 , 执行数据查询 , 更新 , 删除等操作 /
- MVC / MTV框架 : MVC和MTV是软件开发中常用的设计模式 , 它们将应用程序分为三个主要部分 : 模型 , 视图 , 控制器 / 模板 . 模型 ( Model ) 部分 : 通常与ORM紧密相关 , 负责处理数据逻辑和数据库交互 . 视图 ( View ) : 负责呈现用户界面。 控制器 / 模板 ( Controller / Template ) : 负责处理用户输入和输出 , 将用户请求转发给模型 , 并将模型处理的结果展示给用户 .
- 用户 / 前端 : 最终用户通过浏览器或其他客户端界面与应用程序进行交互 .
django . db . models . Model是Django ORM框架的核心基类 , 它为定义和操作数据库表提供了丰富的功能和接口 .
通过继承这个类 , 可以创建与数据库表相对应的Python类 ( 称为模型 ) , 这些类支持以面向对象的方式操作数据库中的数据 . 以下是django . db . models . Model的主要功能和特点 :
* 1. 定义数据模型 : 通过在模型类中定义字段 ( 如 : CharField , IntegerField , ForeignKey等 ) , 可以明确指定数据库中表的结构 , 包括列的名称 , 数据类型 , 是否可以为空 , 默认值 , 约束条件等 .
* 2. 数据库表映射 : Django ORM自动将模型类映射到数据库中的表 . 默认情况下 , Django会使用 < app_label > _ < model_name > 的格式来命名表 , 但可以通过在模型内部定义Meta类并设置db_table属性来自定义表名 .
* 3. 数据查询 : Django提供了一套强大的查询API ( 如 : QuerySet ) , 允许开发者以Python代码的形式编写数据库查询 , 而无需直接编写SQL语句 . 这些查询语句在运行时会被Django转换为相应的SQL语句并执行 .
* 4. 数据验证 : 在将数据保存到数据库之前 , Django会自动验证数据的有效性 , 确保数据符合字段的定义 ( 如数据类型 , 长度限制 , 唯一性约束等 ) . 如果数据不符合要求 , 会抛出相应的异常 .
* 5. 关系定义 : Django ORM支持定义模型之间的关系 , 包括一对多 ( ForeignKey ) , 多对多 ( ManyToManyField ) 和一对一 ( OneToOneField ) 关系 . 这些关系使得在数据库中表示复杂的数据结构变得简单和直观 .
* 6. 数据修改和删除 : 除了查询数据外 , Django ORM还提供了修改 ( 更新 ) 和删除数据库中数据的方法 . 这些方法使得以面向对象的方式操作数据库成为可能 .
* 7. 数据迁移和数据库同步 : Django提供了一套迁移 ( migration ) 系统 , 用于跟踪模型的变化 , 并生成相应的SQL语句来更新数据库结构 . 通过运行迁移 , 可以确保数据库与模型保持同步 .
* 8. 自定义管理界面 : Django的admin应用允许开发者通过定义模型的Meta类中的admin属性 , 为模型自动生成一个管理界面 . 此外 , 还可以自定义管理界面的行为 , 如添加自定义的表单字段 , 过滤器和操作等 .
* 9. 信号 ( Signals ) : Django的信号机制允许在模型执行特定操作时 ( 如保存前 , 保存后 , 删除前 , 删除后等 ) 自动执行代码 . 这可以用于执行一些额外的任务 , 如发送通知 , 更新缓存等 .
* 10. 性能优化 : Django ORM提供了一些机制来优化查询性能 , 如查询集缓存 , 选择相关的优化查询 ( 如 : select_related和 prefetch_related ) 等 . 这些机制有助于减少数据库查询次数和提高应用性能 . 综上所述 , django . db . models . Model是Django ORM框架的核心 , 它提供了定义数据模型 , 数据库表映射 , 数据查询 , 数据验证 ,
关系定义 , 数据修改和删除 , 数据迁移和同步 , 自定义管理界面 , 信号以及性能优化等全方位的功能 .
在Django框架中 , python manage . py makemigrations和python manage . py migrate是两个非常重要的命令 ,
它们一起用于管理数据库的模式 ( schema ) 和迁移 ( migrations ) . 这两个命令在Django的数据库同步过程中扮演着不同的角色 . 下面是命令的详细说明 :
* 1. python manage . py makemigrations命令 : 用于根据你的模型 ( models ) 变化自动生成迁移文件 . 当修改了模型 ( 比如添加了新的字段 , 删除了字段 , 修改了字段类型等 ) 并希望这些变化反映到数据库中时 , 需要首先运行这个命令 . 它会扫描你的所有应用 ( apps ) 的模型文件 , 并与之前的迁移状态进行比较 , 然后生成一个新的迁移文件 ( 如果检测到变化的话 ) . 迁移文件是一个Python脚本 , 它包含了将数据库从当前状态迁移到新的期望状态所需的所有操作 . 这些文件被保存在每个应用的migrations目录下 , 并且是以时间戳命名的 , 以确保迁移的顺序 . * 2. python manage . py migrate命令 : 用于应用所有未应用的迁移文件到数据库中 . 在运行了makemigrations命令并生成了新的迁移文件之后 , 需要运行这个命令来将这些迁移应用到你的数据库中 . 它会检查所有应用的迁移文件 , 并找出那些还没有应用到数据库中的迁移 , 然后按照顺序执行它们 . 这个过程确保了数据库模式与Django模型保持同步 . 如果正在开发环境中工作 , 并且经常修改模型 , 那么这两个命令会是开发者工作流中的一部分 .
请注意 , 如果没有为特定的应用指定名称 , makemigrations命令会检查项目中所有应用的模型 , 并为那些需要生成迁移的应用生成迁移文件 .
如果想为特定的应用 ( app ) 生成迁移文件 , 可以在makemigrations命令后面指定该应用的名称 .
这样 , Django就只会为那个特定的应用生成迁移文件 , 而不会检查其他应用是否也有需要生成迁移的变更 . 命令的格式如下 :
python manage . py makemigrations < app_name >
其中 , < app_name > 是你想要为其生成迁移的应用的名称 . 例如 , 如果Django项目中有一个名为books的应用 , 并且只对books应用的模型做了修改 ,
那么可以使用以下命令来只为books应用生成迁移文件 : python manage . py makemigrations books .
这条命令会检查books应用下的models . py文件 , 与之前的迁移状态进行比较 , 然后生成一个新的迁移文件 ( 如果发现有需要迁移的变更的话 ) .
这个文件将位于books / migrations / 目录下 , 并且包含将数据库从当前状态迁移到新状态所需的步骤 .
Django模型字段是Django ORM系统中的一个核心概念 , 它们用于定义数据库表中的列类型 , 并提供了丰富的参数来定义数据的行为和约束 . 常用字段类型及其参数介绍 :
* 1. AutoField ( 自增列 ) : 如果没有显式定义主键 , Django会自动生成一个名为id的AutoField字段 . 如果需要自定义自增列 , 必须将primary_key = True设置给该字段 . Django 3.2 之后,DEFAULT_AUTO_FIELD被设置为BigAutoField,以支持更大的数据集。
* 2. CharField ( 字符串字段 ) : 用于存储较短的字符串 , 如名字或标题 . 必须设置max_length参数来指定字符串的最大长度 .
* 3. BooleanField ( 布尔类型 ) : 用于存储布尔值 ( True或False ) . 在大多数数据库系统中 , 没有原生支持布尔类型 , 当Django的BooleanField映射到数据库时 , 它通常不会直接存储布尔值 ( True或False ) 作为数据类型的原生表示 . 通常会被映射为一个小整数类型 , 如tinyint ( 1 ) , 其中 1 代表True , 而 0 代表False . 可以通过设置Blank = True允许表单验证中空值的存在 .
* 4. DateField ( 日期类型 ) : 用于存储日期 ( 年-月-日 ) . auto_now参数 : 会在每次保存对象时 , 自动将该字段设置为当前日期 . auto_now_add参数 : 会在对象首次创建时自动设置为当前日期 , 之后不会改变 .
* 5. DateTimeField ( 日期时间类型 ) : 同时存储日期和时间 . 参数与DateField相同 .
* 6 TimeField ( 时间字段 ) : 用于存储时间 ( 时 : 分 : 秒 ) .
* 7. DecimalField ( 十进制小数类型 ) : 用于存储需要精确小数的数值 . 必须设置max_digits ( 总位数 , 包括整数部分和小数部分 ) 和decimal_places ( 小数位数 ) 参数 .
* 8. EmailField ( 电子邮件字段 ) : 继承自CharField , 用于存储电子邮件地址 , 并验证其格式 .
* 9. FloatField ( 浮点类型 ) : 用于存储浮点数 . 需要设置max_digits和decimal_places参数来限制数值的范围和精度 .
* 10. IntegerField ( 整形 ) : 用于存储整数 .
* 11. BigIntegerField ( 长整形 ) : 用于存储非常大的整数 .
* 12. TextField ( 大文本字段 ) : 用于存储大量文本 , 如文章或评论 . 不需要max_length参数 .
* 13. URLField ( URL字段 ) : 继承自CharField , 用于存储URL , 并验证其格式 .
* 14. ImageField ( 图片字段 ) : 继承自FileField , 用于上传图片文件 , 并验证其是否为图片 .
* 15. 需要安装Pillow库来处理图片 .
* 16. FileField ( 文件字段 ) : 用于上传文件 .
* 17. upload_to参数指定文件上传的目录 .
* 18. NullBooleanField ( 布尔类型 ) : 与BooleanField类似 , 但它允许存储空 ( NULL ) 值 . 这意味着除了True和False之外 , 还可以存储NULL来表示未知或未设置的状态 .
* 19. IPAddressField ( IP字段 ) : 用于存储IPv4地址的字符串类型字段 .
* 20. GenericIPAddressField ( IP字段 ) : 用于存储IPv4或IPv6地址 . 通过protocol参数 , 可选值 : 'both' , 'ipv4' , 'ipv6' ) , 可以指定接受的IP版本 .
* 21. SlugField ( 字符类型 ) : 这是一个特殊的CharField , 用于存储一个 'slug' 值 . Slug通常用于URL中 , 并且只包含字母 , 数字 , 下划线 ( _ ) 和连接符 ( - ) .
* 22. CommaSeparatedIntegerField ( 字符类型 ) : 这个字段以字符串形式存储由逗号分隔的整数序列 .
* 23. UUIDField ( UUID类型 ) : 用于存储UUID值的字符串类型字段 .
* 24. ForeignKey ( 外键字段 ) : 定义模型之间的关系 , 表示一对多或多对一的关系 . 需要指定关联的模型 , 并设置on_delete参数来定义当关联对象被删除时的行为 .
* 25 : ManyToManyField ( 多对多字段 ) : 定义模型之间的多对多关系 . 不需要设置on_delete参数 .
* 26. OneToOneField ( 一对一字段 ) : 定义模型之间的一对一关系 . 需要指定关联的模型 , 并设置on_delete参数 .
除了字段类型特有的参数外 , Django的字段类型还有一些通用参数 , 这些参数可以用来进一步定义字段的行为和约束 .
通用参数 :
* 1. null : 如果为True , 表示数据库中该字段可以存储NULL值 .
* 2. blank : 如果为True , 表示在Django的表单验证中可以接受空值 .
* 3. default : 为字段指定一个默认值 .
* 4. unique : 如果为True , 表示该字段在整个表中必须是唯一的 .
* 5. b_index : 如果为True , 表示在数据库中为该字段创建索引 .
* 6. editable : 在Django Admin中是否可编辑 .
* 7. choices : 为字段提供一个选项集合 , 用户在选择时只能从提供的选项中选择 . Django的模型字段类型及其参数为开发者提供了灵活而强大的方式来定义和操作数据库中的数据 .
通过合理使用这些字段类型和参数 , 可以构建出既符合业务需求又具有良好数据库性能的数据模型 . 注意 : 在Django的模型定义中 , 字段类型如 : IntegerField , 并不直接支持像MySQL中的UNSIGNED这样的数据库特定属性 .
Django的ORM旨在提供一种数据库无关的方式来定义模型 ,
以便可以在不同的数据库系统 ( 如PostgreSQL , MySQL , SQLite等 ) 之间迁移而无需更改模型代码 . 然而 , 有时候可能确实需要在底层数据库中使用某些特定于数据库的属性 , 比如MySQL的UNSIGNED属性 .
在这种情况下 , 可以通过继承Django的现有字段类 ( 如IntegerField ) 来创建一个自定义字段来实现 .
在Django开发过程中 , 为了调试和优化数据库查询 , 通常需要查看Django ORM生成的SQL语句 .
这可以通过调整Django的日志配置来实现 , 但更直接和常用的方法是确保Django的调试模式开启 , 并可能借助一些额外的工具或属性 .
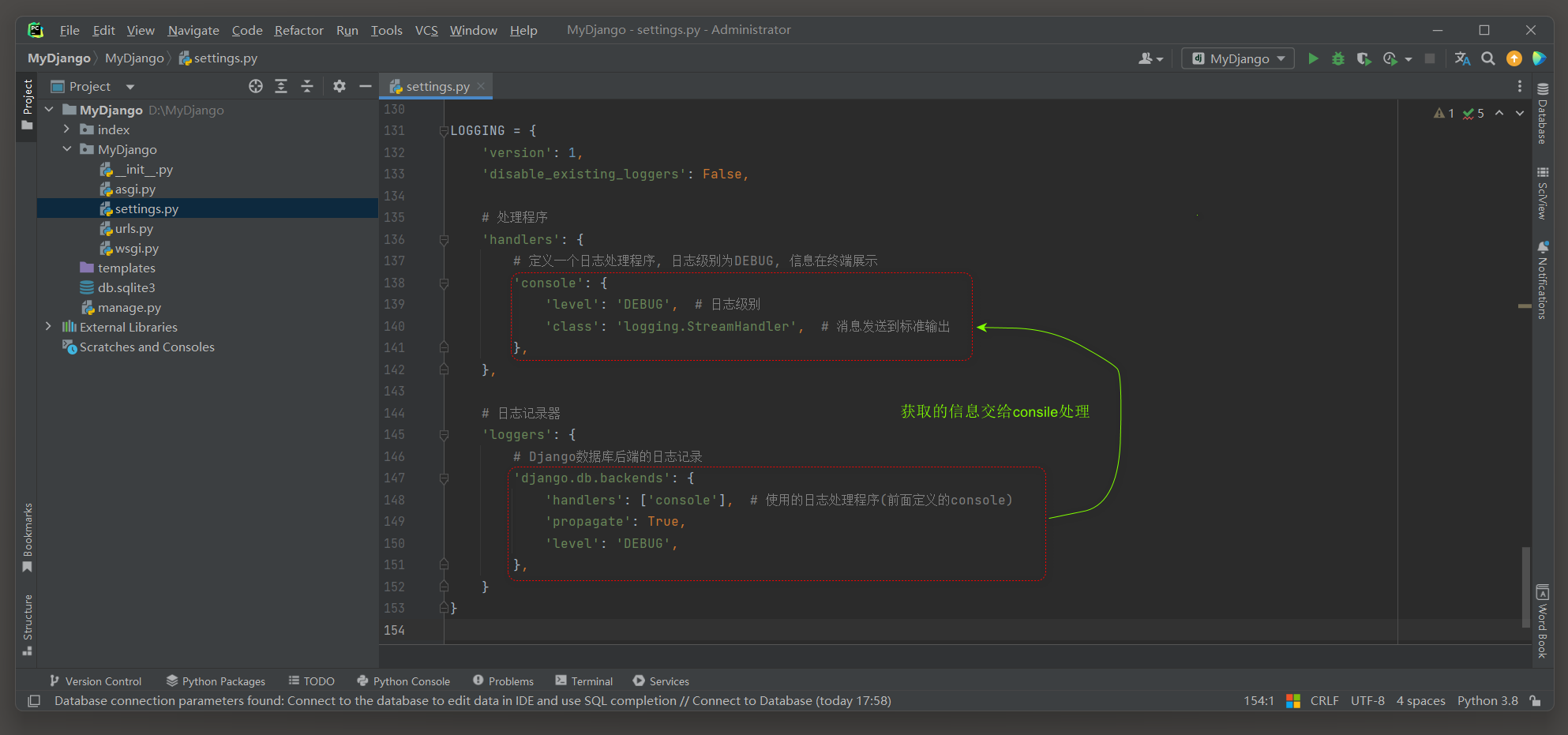
LOGGING = { 'version' : 1 , 'disable_existing_loggers' : False , 'handlers' : { 'console' : { 'level' : 'DEBUG' , 'class' : 'logging.StreamHandler' , } , } , 'loggers' : { 'django.db.backends' : { 'handlers' : [ 'console' ] , 'propagate' : True , 'level' : 'DEBUG' , } , }
}
这个配置定义了日志的行为 , 特别是如何处理和记录Django数据库后端 ( django . db . backends ) 的日志消息 .
总体作用 : 该配置旨在将Django数据库后端的日志消息 ( 如SQL查询 ) 以DEBUG级别记录到控制台 ( 通常是命令行或终端 ) . 下面是对这个配置代码的详细作用与介绍 :
* 1. version : 1 : 这指定了配置字典的格式版本 . 目前 , logging模块主要使用版本 1 的配置格式 ( 暂时没有别的 ) . 这个版本提供了基本的配置选项 , 包括日志记录器 ( loggers ) , 处理程序 ( handlers ) , 过滤器 ( filters ) 和格式化器 ( formatters ) 的配置 .
* 2. disable_existing_loggers : False : 这个设置决定了是否禁用项目中已存在的日志记录器 ( loggers ) . 设置为False意味着不会禁用它们 , 即保持已有的日志记录器不变 .
* 3. handlers : 这个部分定义了日志处理程序的字典 . 每个处理程序都指定了如何将日志消息发送到其目的地 . console : 这是一个日志处理程序 , 它使用logging . StreamHandler类将日志消息发送到标准输出 ( 即控制台 ) . 其日志级别被设置为DEBUG , 意味着所有DEBUG级别及以上 ( INFO , WARNING , ERROR , CRITICAL ) 的日志都将被发送到控制台 . * 4. loggers : 这个部分定义了特定日志记录器的配置 django . db . backends : 这是一个特定的日志记录器 , 专门用于控制Django数据库后端的日志记录 . 它配置了以下几个属性 : - handlers : 指定了要将日志消息发送到的处理程序列表 . 在这个例子中 , 它使用了之前定义的console处理程序 , 意味着数据库后端的日志消息将被发送到控制台 . - propagate : 设置为True意味着日志消息不仅会被发送到指定的处理程序 , 而且这些消息还会被这个日志记录器的父记录器 ( 如果存在 ) 处理 ( 前提是消息满足父记录器的级别要求 ) . 然而 , 在大多数情况下 , 对于django . db . backends这样的具体日志记录器 , propagate的值可能不会影响太多 , 因为Django的日志系统已经为这些记录器设置了合适的父级和级别 . - level : 设置了该日志记录器的日志级别为DEBUG . 由于这个记录器特别关注数据库后端的操作 , 因此将级别设置为DEBUG可以捕获到所有的SQL查询语句 . 注意事项 :
尽管这个配置非常有用于开发过程中的调试 , 但在生产环境中 , 通常不建议将django . db . backends的日志级别设置为DEBUG ,
因为这可能会产生大量的日志消息 , 对性能产生负面影响 , 并且可能暴露敏感信息 .
在生产环境中 , 需要将日志记录到文件中 , 而不是控制台 , 并且可能会调整日志级别以捕获更少的消息 .
Django的日志系统非常灵活 , 可以根据需要添加更多的处理程序 , 日志记录器 , 甚至自定义日志记录器的行为 .
Django的日志系统支持多种日志级别 , 从低到高依次为 : DEBUG , INFO , WARNING , ERROR、CRITICAL .
每个级别都对应了不同类型的日志信息 :
- DEBUG : 用于调试目的的详细日志信息 . 这包括程序运行中的变量值 , 流程信息等 , 对于开发过程中的问题定位非常有用 . 但在生产环境中 , 由于这些日志信息可能包含敏感信息或过于详细 , 因此通常不建议开启 . ( 设置为DEBUG才能开的到sql语句的信息 . . . )
- INFO : 普通的日志信息 , 通常用于记录程序的正常运行流程 , 请求处理结果等 . 这个级别适用于生产环境 , 可以帮助你了解程序的基本运行情况 .
- WARNING : 警告信息 , 表示程序运行中可能出现了需要注意的情况 , 但还不至于影响程序的正常执行 . 这个级别可以帮助你提前发现潜在的问题 .
- ERROR : 错误信息 , 表示程序执行过程中遇到了错误 , 但程序还能继续运行 . 这个级别的日志信息对于问题排查和修复非常重要 .
- CRITICAL : 严重错误 , 表示程序已经无法继续运行 . 这个级别的日志信息通常表示出现了非常严重的错误 , 需要立即关注并修复 .
在LOGGING配置字典中设置两个 'level' : 'DEBUG' , 它们分别作用于不同的上下文或组件中 :
* 1. 处理程序的级别 : 它作为一道过滤器 , 用于限制发送到处理程序的消息数量 . 如果处理程序的级别设置得很高 ( 比如WARNING ) , 那么即使记录器的级别很低 ( 比如DEBUG ) , 也只有WARNING级别及以上的消息会被发送到该处理程序 .
* 2. 记录器的级别 : 它决定了哪些日志消息会被记录器捕获并可能转发到其处理程序 . 如果记录器的级别设置得很低 ( 比如DEBUG ) , 那么它会捕获所有DEBUG级别及更高级别的消息 , 并根据处理程序的配置来决定是否将这些消息发送到目的地 . 在例子中 , 由于django . db . backends记录器的级别和处理程序 'console' 的级别都被设置为DEBUG ,
这意味着django . db . backends记录器会捕获所有DEBUG级别及更高级别 ( INFO , WARNING , ERROR , CRITICAL ) 的日志消息 .
由于 'console' 处理程序的级别也是DEBUG , 它不会对这些消息进行进一步的过滤 ( 因为它被设置为允许通过所有DEBUG及以上级别的消息 ) ,
所以所有被django . db . backends记录器捕获的日志消息都会被发送到控制台 .
这样 , 就可以在控制台上看到所有从django . db . backends发出的详细数据库操作日志 . 这种设计提供了灵活性 , 允许根据需要对不同的日志记录器和处理程序进行细粒度的控制 .
例如 , 可能希望将某些关键组件的日志级别设置为DEBUG以进行详细的调试 ,
但同时又不想在控制台上看到过多的日志消息 , 这时可以通过调整处理程序的级别来实现 .
下面的代码片段是为表 'index_user' 插入三条用户记录时执行的SQL语句 .
表中有三个字段 , 分别是 : name , age , register_time ( 自动获取当前时间 ) .
Users = [ User( name= "aa" , age= 19 ) , User( name= "bb" , age= 19 ) , User( name= "cc" , age= 19 ) ,
]
created_users = User. objects. bulk_create( Users) 执行这样代码会在终端看到如下信息 :
( 0.015 ) SELECT VERSION ( ) , @ @ sql_mode , @ @ default_storage_engine , @ @ sql_auto_is_null , @ @ lower_case_table_names , CONVERT_TZ ( '2001-01-01 01:00:00' , 'UTC' , 'UTC' ) IS NOT NULL ; args = None
( 0.000 ) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED ; args = None
( 0.000 ) INSERT INTO ` index_user ` ( ` name ` , ` age ` , ` register_time ` ) VALUES ( 'aa' , 19 , '2024-07-04 12:22:49.469064' ) , ( 'bb' , 19 , '2024-07-04 12:22:49.469064' ) , ( 'cc' , 19 , '2024-07-04 12:22:49.469064' ) ; args = ( 'aa' , 19 , '2024-07-04 12:22:49.469064' , 'bb' , 19 , '2024-07-04 12:22:49.469064' , 'cc' , 19 , '2024-07-04 12:22:49.469064' )
下面是对这段日志的详细解释:
* 1. 初始化数据库连接查询 : SELECT VERSION ( ) , @ @ sql_mode , @ @ default_storage_engine , @ @ sql_auto_is_null , @ @ lower_case_table_names , CONVERT_TZ ( '2001-01-01 01:00:00' , 'UTC' , 'UTC' ) IS NOT NULL ; 这个查询是Django在建立数据库连接时执行的 , 用于检查数据库的版本 , SQL模式 , 默认存储引擎 , 自动将NULL转换为TRUE / FALSE的设置 , 表名是否不区分大小写 , 以及时区转换函数的支持情况 . 这个查询对于确保Django与数据库兼容非常重要 . * 2. 设置事务隔离级别 : SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED ; 这个命令设置了当前数据库会话的事务隔离级别为 '读已提交' ( Read Committed ) . 这是数据库事务处理中的一个关键特性 , 用于控制并发事务之间的可见性 . * 3. 插入数据 : INSERT INTO index_user ( name , age , register_time ) VALUES ( 'aa' , 19 , '2024-07-04 12:22:49.469064' ) , ( 'bb' , 19 , '2024-07-04 12:22:49.469064' ) , ( 'cc' , 19 , '2024-07-04 12:22:49.469064' ) ; 这个查询是在index_user表中插入了三条记录 . 每条记录包含name ( 用户名 ) , age ( 年龄 ) 和register_time ( 注册时间 ) 三个字段 . 这里一次性插入了三个用户 , 分别是 'aa' , 'bb' 和 'cc' , 年龄都是 19 岁 , 注册时间都是 2024 - 07 - 04 12 : 22 : 49.469064 . * 4. args参数 : 第一个查询 ( 初始化数据库连接 ) 没有args参数 , 因为它是一个静态的查询 , 不依赖于外部变量 . 设置事务隔离级别的查询同样没有args参数 , 因为它是直接执行的SQL命令 . 插入数据的查询有一个args参数 , 它包含了要插入的数据 . 在这个例子中 , args参数是一个元组 , 包含了三个用户的数据 ( 每个用户的数据又是一个元组 , 包括name , age和register_time ) . Django在构建这个查询时 , 会将这些数据动态地插入到SQL语句中 . * 5. 日志的时间戳 : 日志中的 ( 0.015 ) , ( 0.000 ) 等表示执行这些查询所花费的时间 ( 以秒为单位 ) . 这个时间非常短 , 说明查询执行得非常快 . 总结来说 , 这段日志记录了Django应用程序与数据库交互的过程 , 包括初始化数据库连接 , 设置事务隔离级别以及插入数据的操作 .
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED ; 这个命令是数据库事务管理中的一个重要概念 : 事务隔离级别 .
那么下面尽量用简单的语言来解释它 . * 数据库事务 : 数据库事务是一组操作 , 这些操作要么全部成功 , 要么在遇到错误时全部回滚 ( 撤销 ) . 事务的主要目的是确保数据库的完整性和一致性 . * 事务隔离级别 : 在并发环境中 , 多个事务可能会同时运行并尝试访问或修改数据库中的相同数据 . 事务隔离级别就是用来控制这种并发访问的可见性和影响的一种机制 . 不同的隔离级别提供了不同程度的保护 , 以防止数据不一致 ( 如脏读 , 不可重复读 , 幻读等问题 ) 的发生 , 但也可能对性能产生影响 . * 读已提交 ( Read Committed ) . 定义 : 在Read Committed隔离级别下 , 一个事务只能看到已经提交 ( Committed ) 的事务所做的修改 . 也就是说 , 如果一个事务在读取某个数据项时 , 另一个事务正在对该数据项进行修改 , 并且这个修改还没有被提交 , 那么当前事务是看不到这个未提交的修改的 . 只有当修改被提交后 , 当前事务再次读取该数据项时 , 才能看到最新的修改 . 特点 : 避免了脏读 ( Dirty Read ) : 脏读是指一个事务读取了另一个事务未提交的数据 . 但仍可能遇到不可重复读 ( Non-repeatable Read ) 和幻读 ( Phantom Read ) 的问题 . "不可重复读" 是指在一个事务内多次读取同一数据集合时 , 由于其他事务的修改或删除 , 导致每次读取的结果集不同 . "幻读" 是指当一个事务重新执行一个查询时 , 返回了之前不存在的行 ( 即由于其他事务的插入操作导致的 ) . * 其他隔离级别 , 除了Read Committed之外 , 常见的隔离级别还包括 : 读未提交 ( Read Uncommitted ) : 最低的隔离级别 , 允许脏读 . 可重复读 ( Repeatable Read ) L 比Read Committed更高的隔离级别 , 保证了在同一事务内多次读取同一数据的结果是一致的 , 避免了不可重复读 , 但在某些数据库 ( 如MySQL的InnoDB存储引擎 ) 中仍可能遇到幻读 . 串行化 ( Serializable ) : 最高的隔离级别 , 通过强制事务串行执行 , 来避免脏读 , 不可重复读和幻读 . 但会严重影响并发性能 . 结论 : 了解事务隔离级别对于设计和维护数据库应用程序至关重要 , 因为它直接影响到数据的一致性和应用程序的性能 .
在实际应用中 , 需要根据具体的需求和场景来选择合适的隔离级别 .
Django在执行数据迁移 ( migrations ) 时 , 默认会根据其内置的应用 ( apps ) 和可能的自定义应用生成一系列表格 .
这些表格主要用于管理用户认证 , 内容类型 , 会话 , 权限 , 组等 .
以下是Django执行数据迁移默认生成的几张表 :
* 1. 用户认证相关表 . auth_user : 存储用户信息 , 如用户名 , 密码 ( 哈希 ) , 邮箱 , 姓名 , 是否活跃等 . auth_group : 存储用户组信息 . auth_group_permissions : 存储用户组与权限之间的关联 . auth_permission : 存储系统中定义的权限信息 . auth_user_groups : 于存储用户和用户组之间的多对多关系 . auth_user_user_permissions : 于存储用户与权限之间的多对多关系 .
* 2. 内容类型相关表 . django_content_type : 存储模型的元数据信息 , 如模型的名称 , 应用名称等 , 用于支持泛外键等高级功能 .
* 3. 会话管理表 . django_session : 存储用户会话信息 , 包括登录状态 , 会话数据等 .
* 4. 管理后台相关表 . django_admin_log : 记录管理员对系统数据的操作日志 .
* 5. 迁移记录表 . django_migrations : 记录系统中所有数据迁移的历史记录 , 以避免重复应用迁移 . 在Django项目中 , 这些默认生成的表在很多情况下都是必需的 , 因为它们支持Django的核心功能 , 如用户认证 , 会话管理 , 内容类型支持等 .
此外 , 如果没有在项目中安装或启用某些内置应用 ( 如django . contrib . admin , django . contrib . auth等 ) , 那么相应的表也不会被创建 .
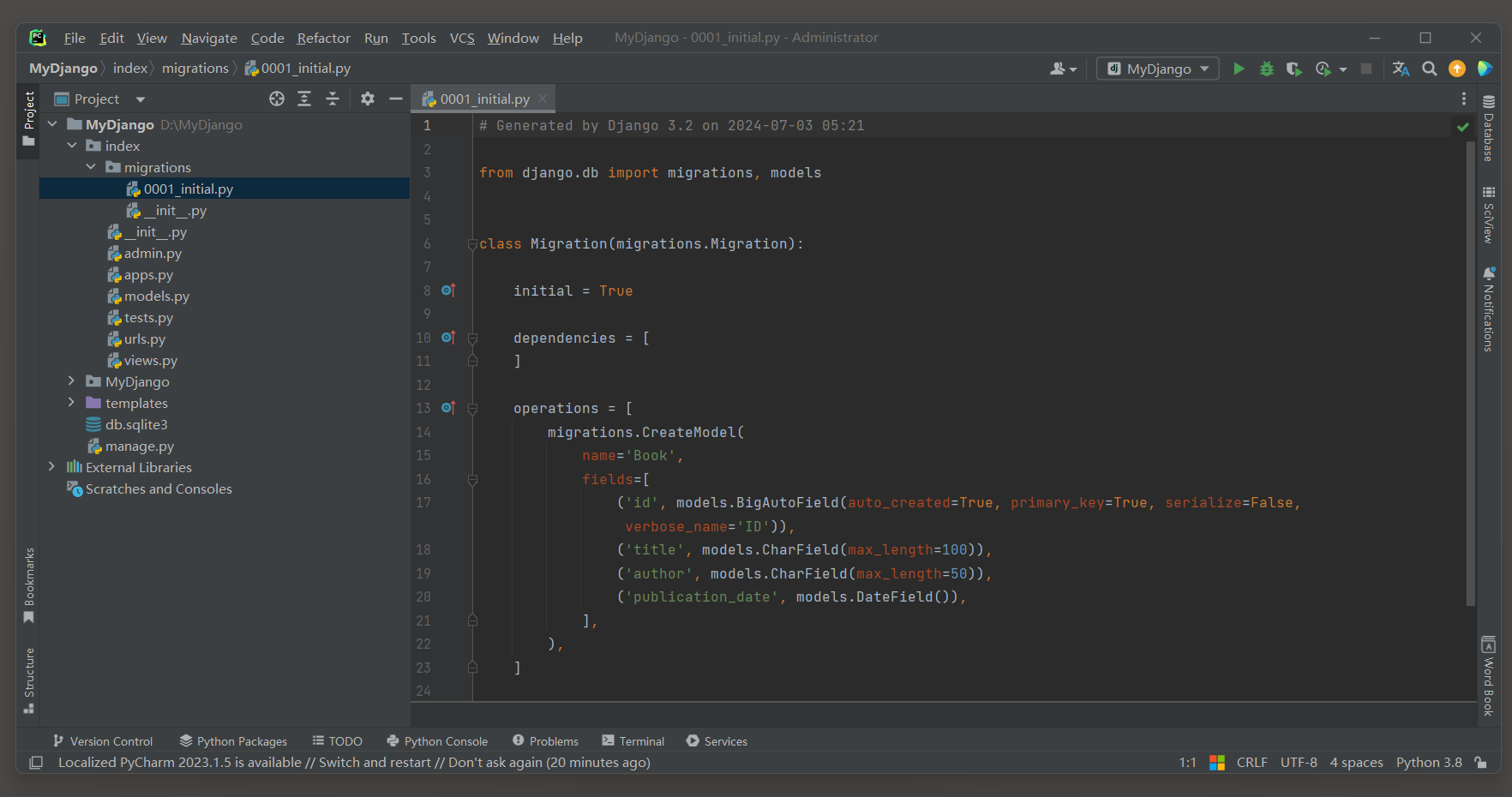
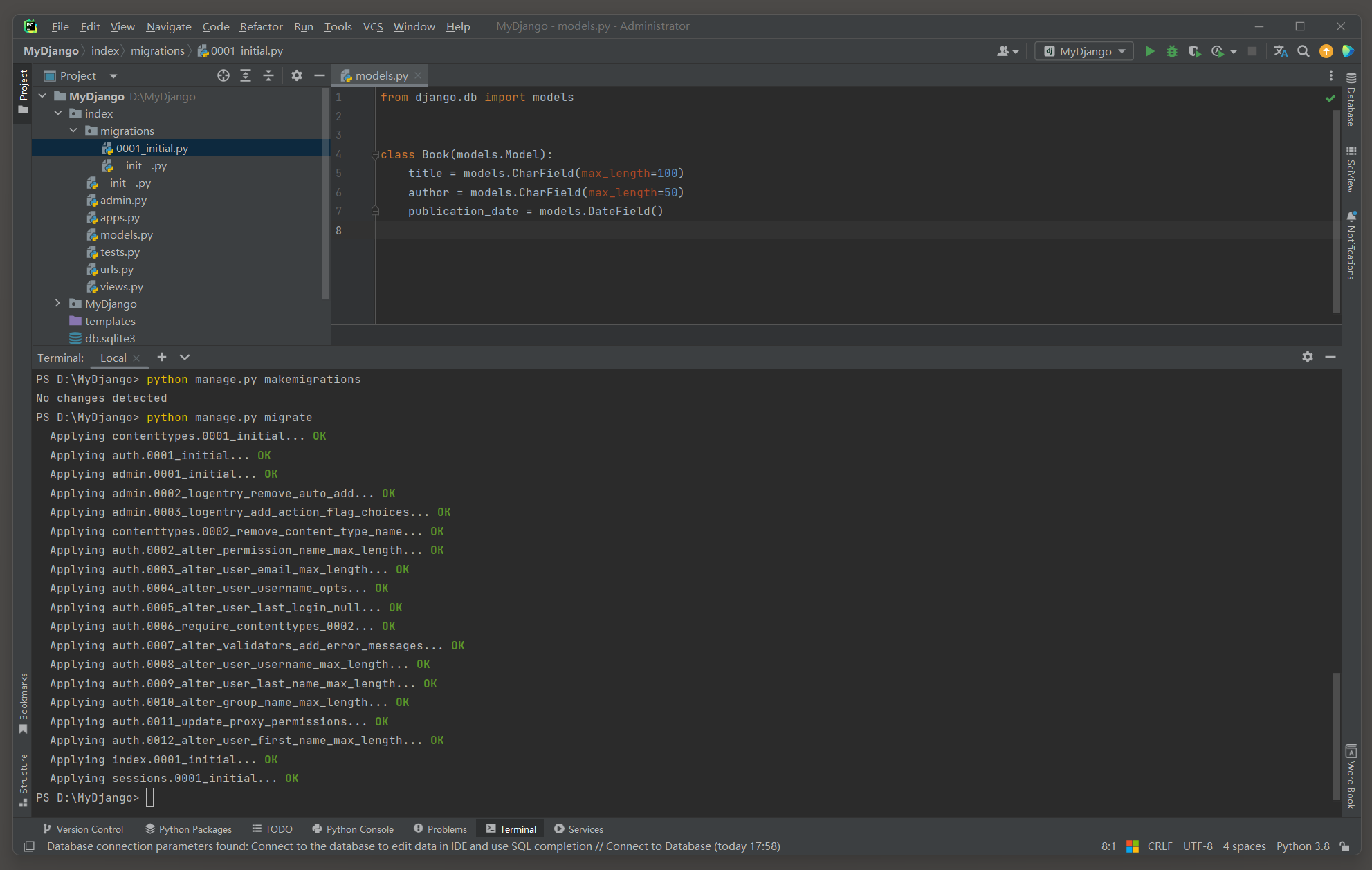
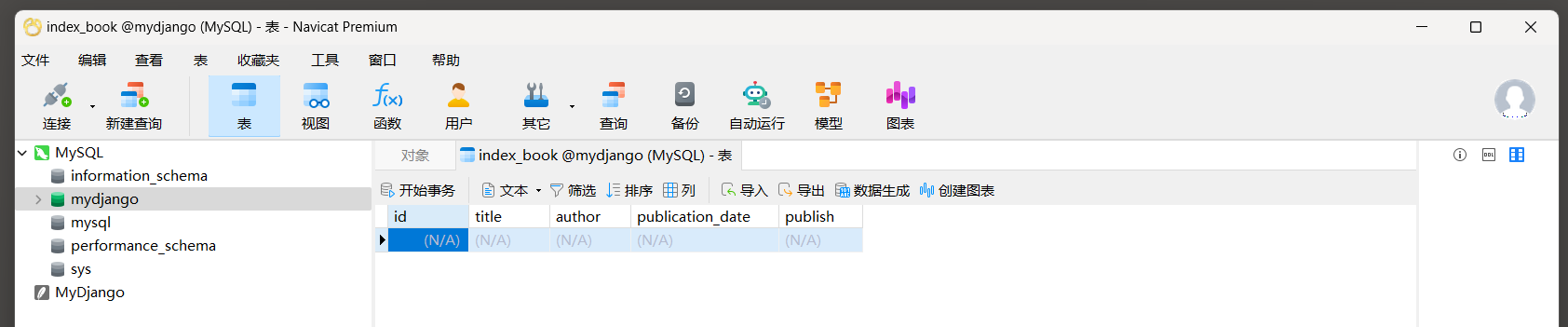
下面是一个简单的Django模型定义示例 :
* 1. 定义模型 . 在Django中 , 每个模型都是一个Python类 , 它继承自django . db . models . Model . 在类中 , 可以定义字段 , 这些字段会映射到数据库表的列上 .
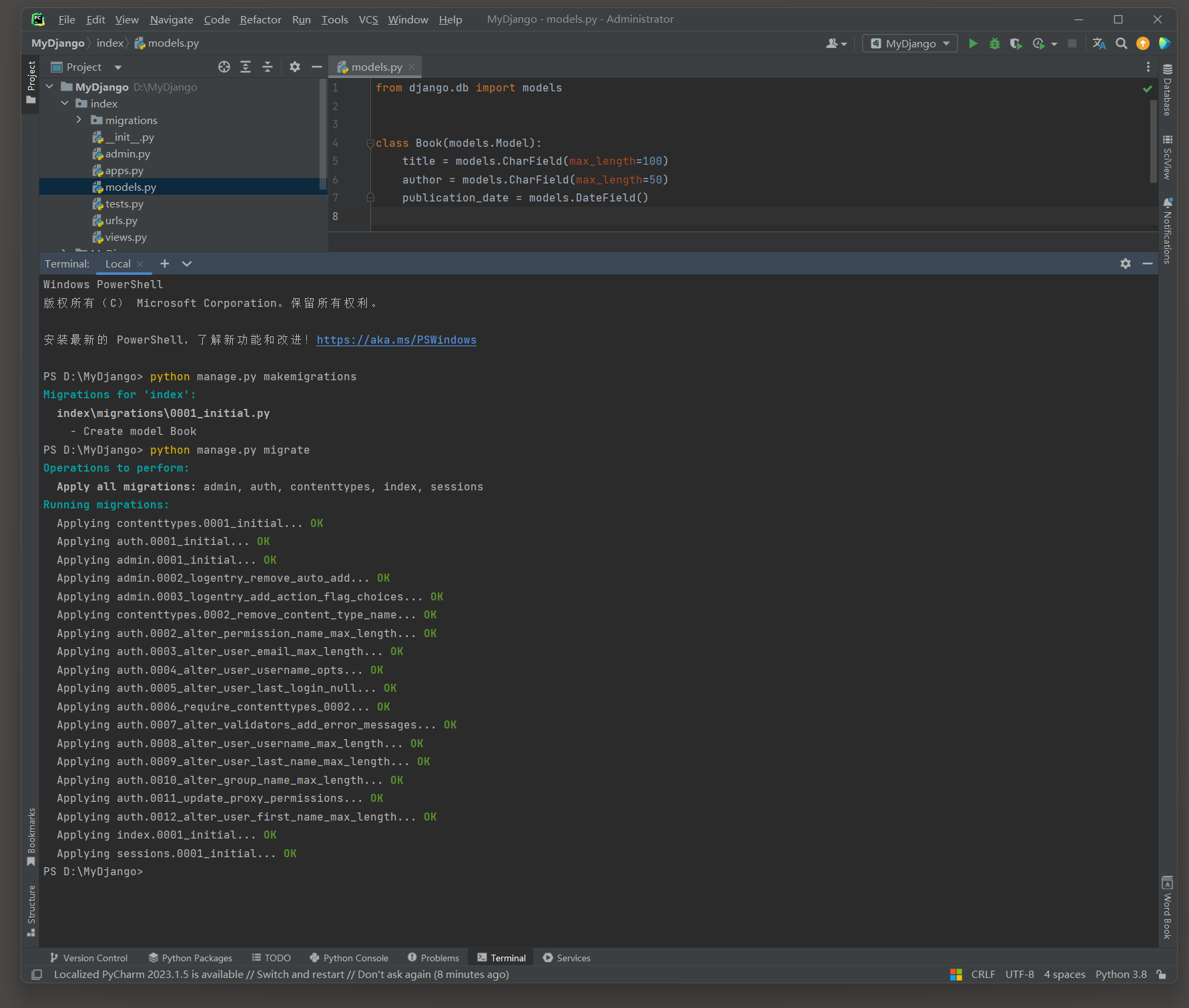
from django. db import models class Book ( models. Model) : title = models. CharField( max_length= 100 ) author = models. CharField( max_length= 50 ) publication_date = models. DateField( ) 这段代码是Django框架中的models . py文件的一部分 , 它定义了一个名为Book的模型 ( Model ) ,
该模型对应于数据库中的一个表 , 用于存储书籍的信息 . 代码解释 :
- from django . db import models : 这行代码从Django的db模块中导入了models类 , 它是所有模型类的基类 .
- class Book ( models . Model ) : 这定义了一个名为Book的类 , 它继承自models . Model . 在Django中 , 每个模型类都映射到数据库中的一个表 .
- title = models . CharField ( max_length = 100 ) : 定义了一个名为title的字段 , 该字段是CharField类型 , 用于存储书籍的标题 . max_length = 100 表示该字段在数据库中最多可以存储 100 个字符 .
- author = models . CharField ( max_length = 50 ) : 定义了一个名为author的字段 , 用于存储书籍的作者 , 该字段最多可以存储 50 个字符 .
- publication_date = models . DateField ( ) : 这定义了一个名为publication_date的字段 , 该字段是DateField类型 , 用于存储书籍的出版日期 . DateField用于存储日期 ( 年-月-日 ) , 没有时间部分 .
* 2. 迁移数据库 . 在定义了模型之后 , 需要通过Django的迁移系统来更新数据库结构 . 首先 , 需要运行makemigrations命令来生成迁移文件 , 然后运行migrate命令来应用这些迁移 , 从而在数据库中创建或更新表 . ( 如果migrations这个包被删除了就无法生成迁移文件了 , 可以手动创建migrations这个包 . )
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0001_initial. py - Create model Book
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying contenttypes. 0001_initial. . . OKApplying auth. 0001_initial. . . OKApplying admin. 0001_initial. . . OKApplying admin. 0002_logentry_remove_auto_add. . . OKApplying admin. 0003_logentry_add_action_flag_choices. . . OKApplying contenttypes. 0002_remove_content_type_name. . . OKApplying auth. 0002_alter_permission_name_max_length. . . OKApplying auth. 0003_alter_user_email_max_length. . . OKApplying auth. 0004_alter_user_username_opts. . . OKApplying auth. 0005_alter_user_last_login_null. . . OKApplying auth. 0006_require_contenttypes_0002. . . OKApplying auth. 0007_alter_validators_add_error_messages. . . OKApplying auth. 0008_alter_user_username_max_length. . . OKApplying auth. 0009_alter_user_last_name_max_length. . . OKApplying auth. 0010_alter_group_name_max_length. . . OKApplying auth. 0011_update_proxy_permissions. . . OKApplying auth. 0012_alter_user_first_name_max_length. . . OKApplying index. 0001_initial. . . OKApplying sessions. 0001_initial. . . OK
PS D: \MyDjango>
这段日志显示的是在Django项目中应用数据库迁移 ( migrations ) 的过程 .
Django的迁移系统允许你通过创建和应用迁移文件来跟踪和管理数据库模式的变化 .
这些迁移文件被设计成可重复应用的 , 这意味着可以在开发过程中多次运行它们而不会导致数据丢失或不一致 . 在这个特定的日志中 , Django正在逐一应用一系列的迁移文件 , 这些文件通常是为了创建或修改数据库中的表 , 字段 , 索引等 .
下面是对日志中迁移文件的简要说明 :
* 1. contenttypes . 0001 _initial : 创建了Django的内容类型 ( ContentType ) 表 , 这是Django内容类型框架的基础 , 用于为模型提供元数据 .
* 2. auth . 0001 _initial 到 auth . 0012 _alter_user_first_name_max_length : 这些迁移文件主要处理Django的认证系统 ( auth app ) , 包括用户 ( User ) 模型 , 权限 ( Permission ) 模型等的创建和修改 . 例如 , 修改了用户名的最大长度 , 增加了错误消息验证器等 .
* 3. admin . 0001 _initial 到 admin . 0003 _logentry_add_action_flag_choices : 这些迁移文件与Django的admin站点相关 , 主要用于创建和管理admin日志条目 ( LogEntry ) 等 .
* 4. contenttypes . 0002 _remove_content_type_name : 这个迁移文件删除了ContentType表中的name字段 , 可能是因为该字段不再需要或已经被其他方式所取代 .
* 5. index . 0001 _initial : 这个迁移文件可能用于创建一些索引 , 以优化数据库查询性能 .
* 6. sessions . 0001 _initial : 这个迁移文件创建了Django会话 ( Session ) 表 , 用于跟踪用户的会话信息 . 每个迁移文件应用后 , 如果成功 , 日志中会显示 'OK' , 表示该迁移已成功应用于数据库 .
这个过程是Django开发过程中常见的一部分 , 特别是在进行数据库模式变更时 .
Django项目中自定义应用的迁移文件是直接暴露给开发者的 , 它们位于应用的migrations目录下 , 并且可以被编辑 , 添加或删除 .
然而 , 对于Django内置的应用 ( 如admin , auth , contenttypes , sessions等 ) ,
其迁移文件并不是直接暴露给开发者进行编辑的 , 因为这些迁移文件是Django框架的一部分 , 并且被设计为在Django安装或升级时自动处理 . 内置应用的迁移文件通常位于Django的源代码中的django / contrib / < app_name > / migrations / 目录下 .
由于这些迁移文件是Django核心代码的一部分 , 因此它们不应该被直接修改或删除 .
如果删除了这些迁移文件 ( 尽管这在实际操作中几乎是不可能的 , 因为它们位于Django的安装目录中 ) ,
那么将无法执行与这些内置应用相关的回滚操作 , 因为Django将无法找到必要的迁移记录 . 对于自定义应用 , 迁移文件是管理数据库结构变更的关键 .
如果删除了自定义应用的迁移文件 , 那么可能会遇到以下几种情况 :
* 1. 无法回滚 : 如果删除了一个或多个迁移文件 , 并且想要回滚到这些迁移之前的状态 , Django将无法找到这些迁移文件来执行回滚操作 .
* 2. 数据库与模型不同步 : 如果数据库中的表结构已经根据之前的迁移进行了更新 , 但迁移文件被删除了 , 那么数据库将与Django模型不同步 . 这可能会导致在尝试执行与这些模型相关的数据库操作时出现错误 .
* 3. 重新生成迁移 : 如果意识到已经删除了迁移文件并且需要它们 , 可以尝试重新生成迁移 . 但是 , 如果数据库中的表结构已经根据之前的迁移进行了更改 , 那么重新生成的迁移可能与数据库的实际状态不完全匹配 . 处理迁移文件的最佳实践 :
- 不要随意删除迁移文件 : 迁移文件是管理数据库结构变更的重要记录 , 除非有充分的理由并且知道如何安全地处理后果 , 否则不要删除它们 .
- 使用版本控制系统 : 将迁移文件纳入版本控制系统 ( 如Git ) , 这样可以轻松地回滚到之前的版本 , 并在需要时恢复已删除的迁移文件 .
- 小心编辑迁移文件 : 虽然你可以编辑迁移文件 , 但通常建议只在绝对必要时才这样做 , 并且确保你完全理解这些更改的后果 .
- 定期备份数据库 : 定期备份你的数据库是防止数据丢失和能够恢复之前状态的好方法 .
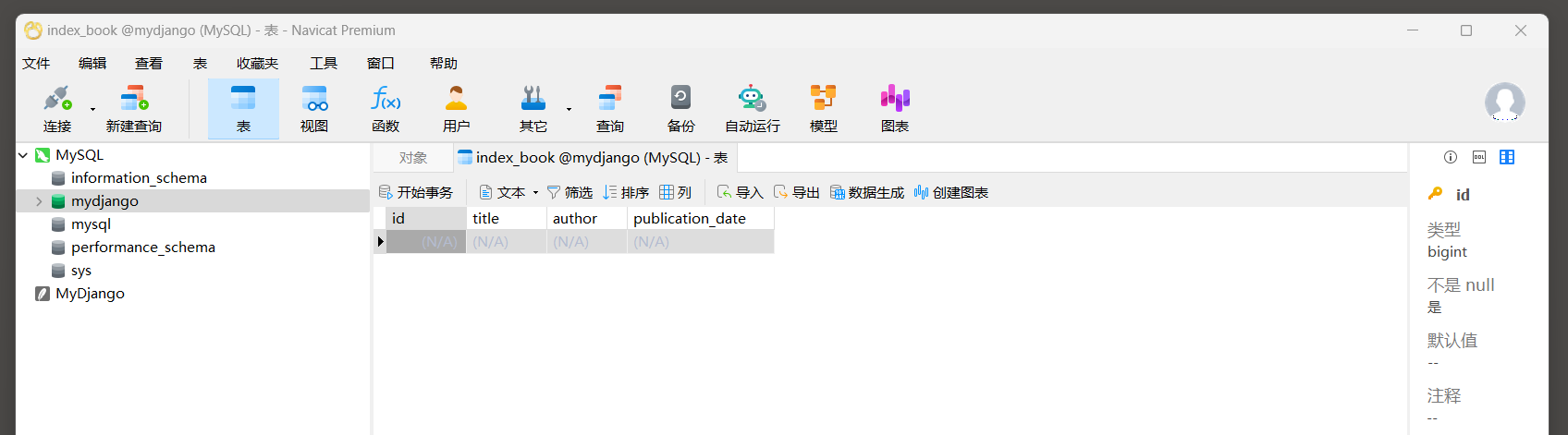
当Django的ORM执行数据库迁移 ( migrations ) 时 , 它会自动根据Book模型的定义创建或更新数据库中的表 .
假设这是第一次为Book模型创建表 , 并且使用的是MySQL数据库 , 那么Django会执行类似以下的SQL语句来创建表 :
CREATE TABLE ` index_book` ( ` id` bigint AUTO_INCREMENT NOT NULL PRIMARY KEY , ` title` varchar ( 100 ) NOT NULL , ` author` varchar ( 50 ) NOT NULL , ` publication_date` date NOT NULL
) ;
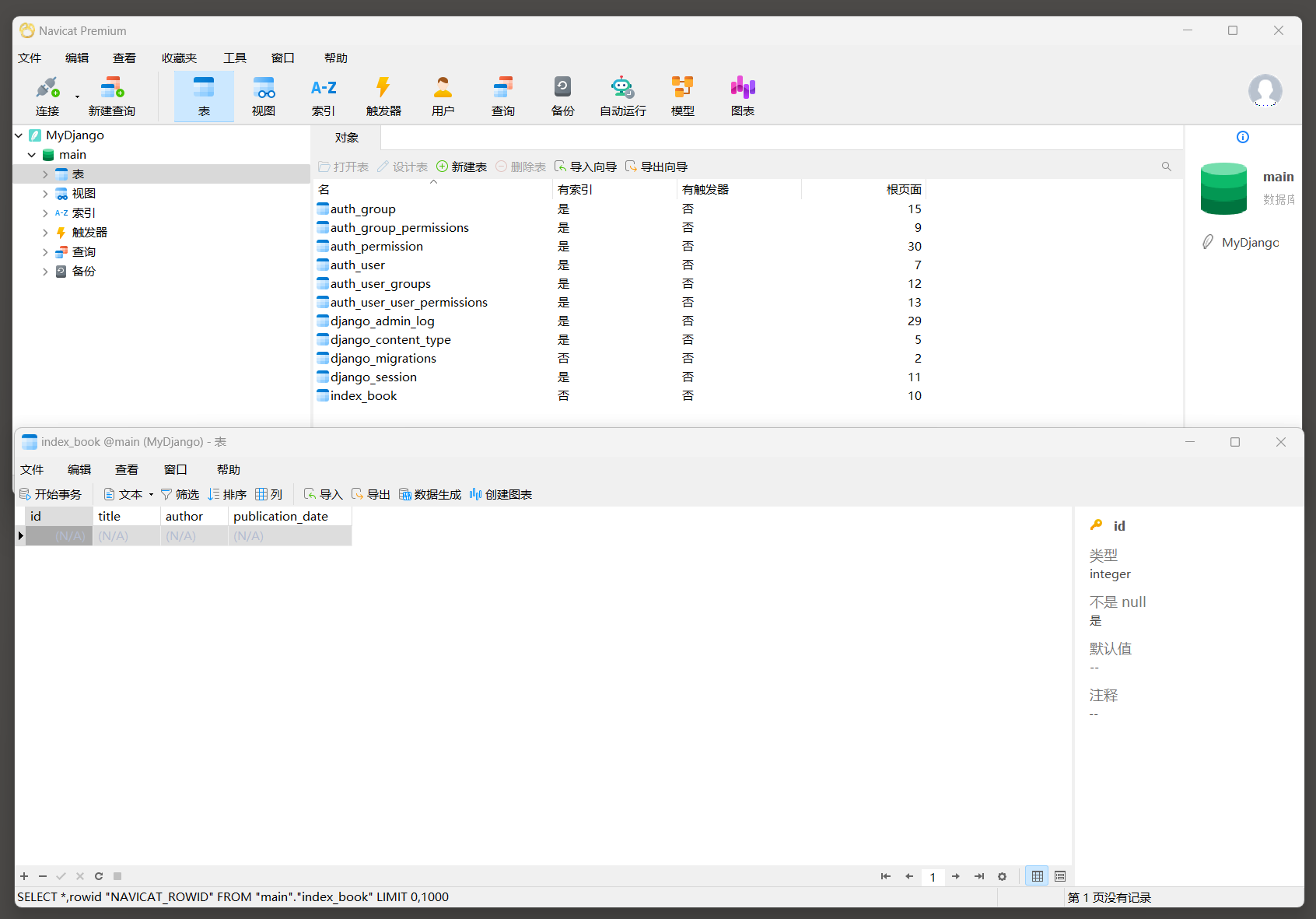
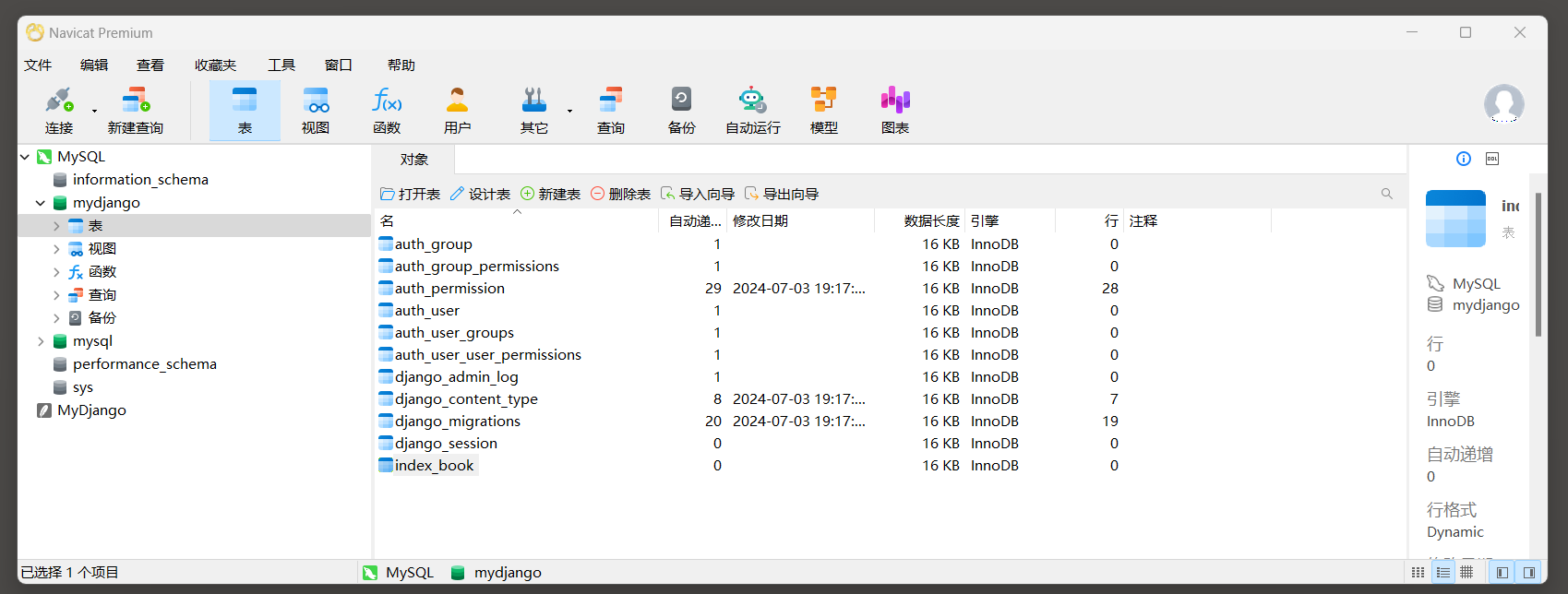
使用Navicat工具打开db . sqlite3文件 , 如下所示 :
注意事项 :
* 1. 表名myapp_book中的myapp是Django应用的名称 . 默认情况下 , Django会使用 < app_label > _ < model_name > 的格式来命名表 , 但可以通过Meta内部类来自定义表名 .
* 2. Django为每个模型自动添加了一个id字段作为主键 , 它是一个自增的整数 .
* 3. 字段类型 ( 如varchar , date ) 和约束 ( 如NOT NULL ) 根据Django模型字段的定义自动生成 .
* 4. 实际的SQL语句可能会根据的数据库设置 ( 如使用的数据库后端 , Django版本等 ) 而有所不同 .
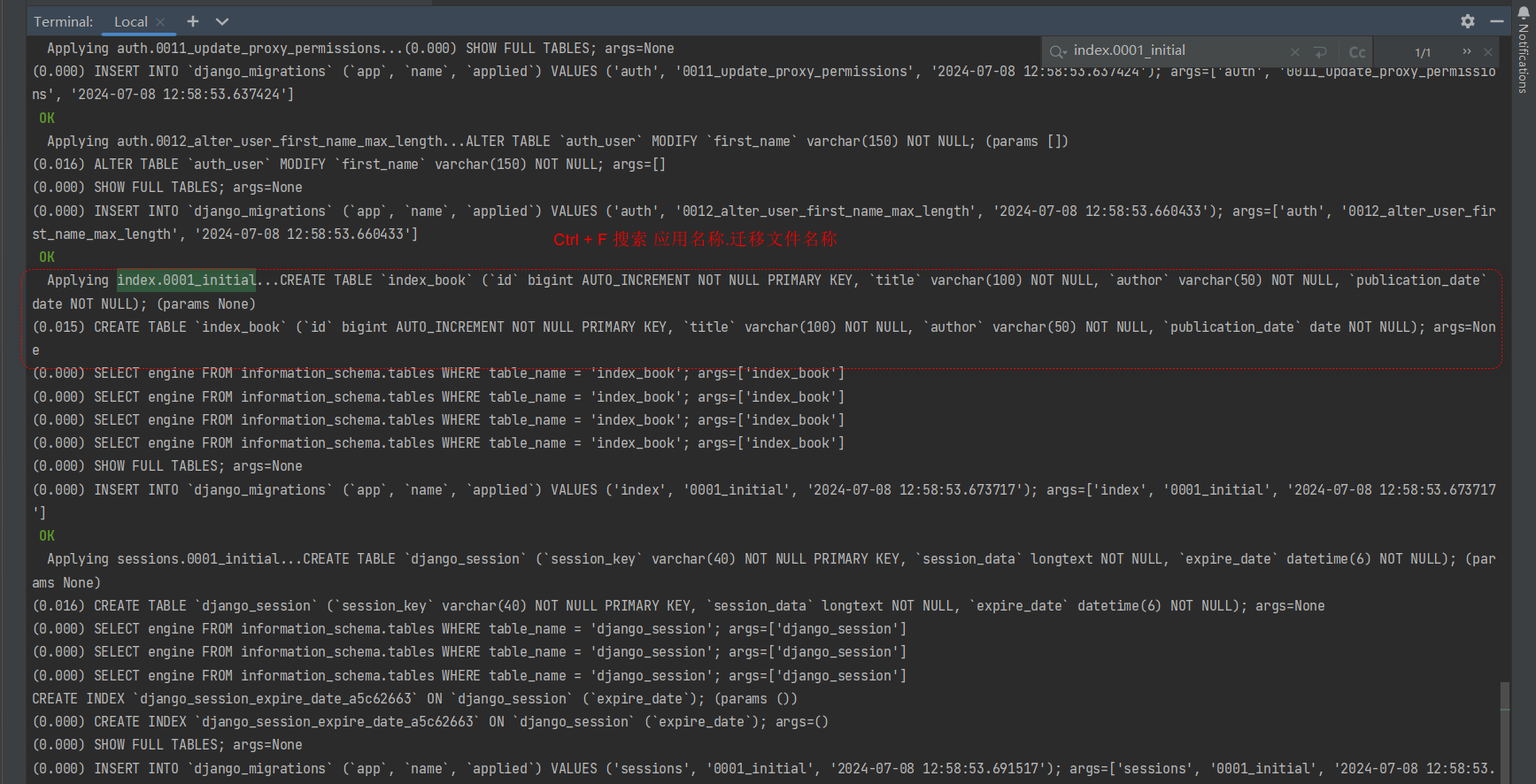
现在开启ORM日志 , 删除迁移记录和数据库中所有表格 , 重新执行数据库迁移命令 , 观察在终端打印出执行的SQL语句 .
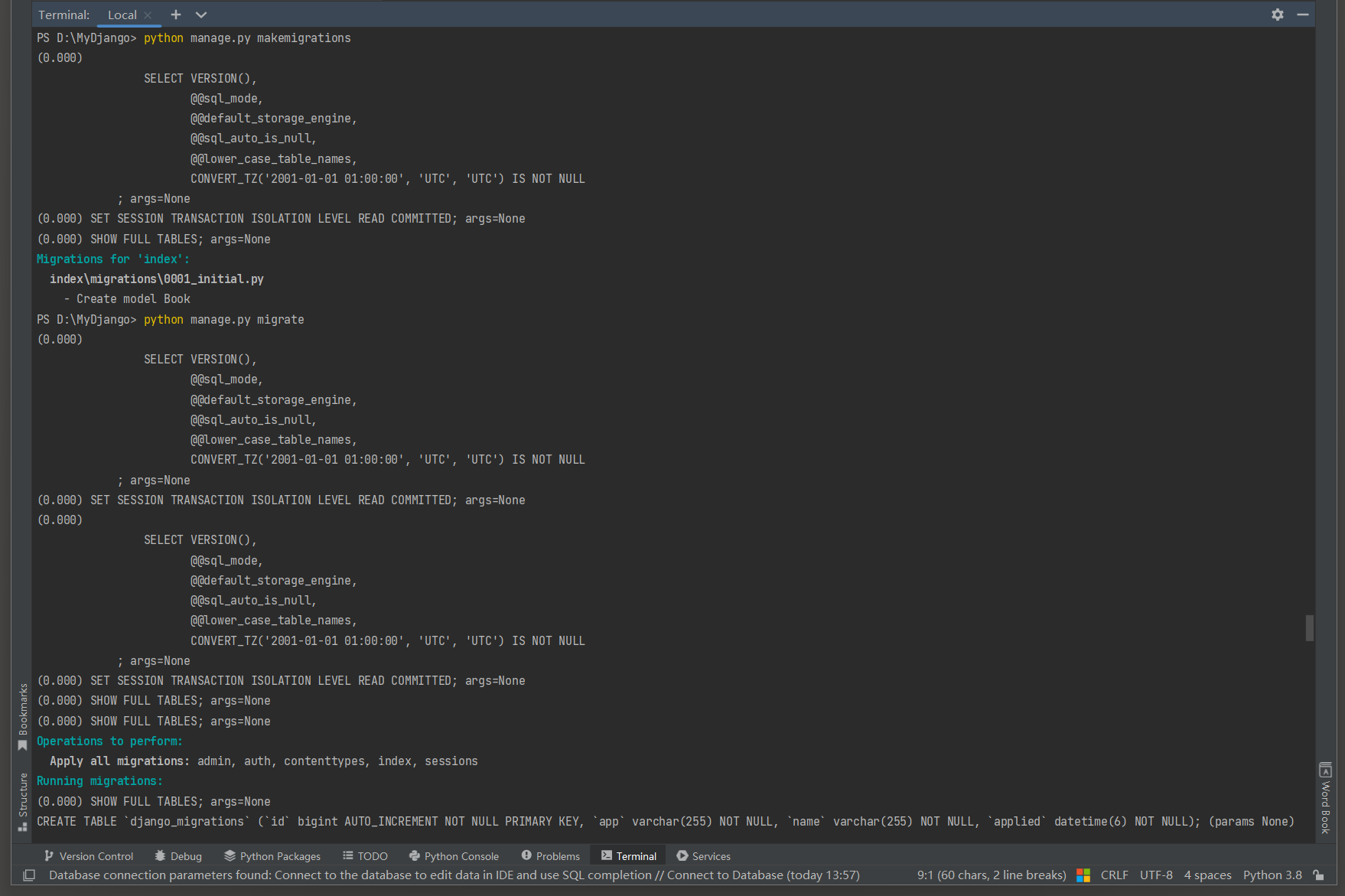
PS D: \MyDjango> python manage. py makemigrations
( 0.000 ) SELECT VERSION( ) , @@sql_mode, @@default_storage_engine, @@sql_auto_is_null, @@lower_case_table_names, CONVERT_TZ( '2001-01-01 01:00:00' , 'UTC' , 'UTC' ) IS NOT NULL; args= None
( 0.000 ) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args= None
( 0.000 ) SHOW FULL TABLES; args= None
Migrations for 'index' : index\migrations\0001_initial. py- Create model Book
PS D: \MyDjango> python manage. py migrate
( 0.000 ) SELECT VERSION( ) , @@sql_mode, @@default_storage_engine, @@sql_auto_is_null, @@lower_case_table_names, CONVERT_TZ( '2001-01-01 01:00:00' , 'UTC' , 'UTC' ) IS NOT NULL; args= None
( 0.000 ) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args= None
( 0.000 ) SELECT VERSION( ) , @@sql_mode, @@default_storage_engine, @@sql_auto_is_null, @@lower_case_table_names, CONVERT_TZ( '2001-01-01 01:00:00' , 'UTC' , 'UTC' ) IS NOT NULL; args= None
( 0.000 ) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args= None
( 0.000 ) SHOW FULL TABLES; args= None
. . .
Applying index. 0001_initial. . .
CREATE TABLE `index_book`( `id ` bigint AUTO_INCREMENT NOT NULL PRIMARY KEY, `title` varchar( 200 ) NOT NULL,
`author` varchar( 50 ) NOT NULL, `publication_date` date NOT NULL) ; ( params None )
( 0.000 ) CREATE TABLE `index_book` ( `id ` bigint AUTO_INCREMENT NOT NULL PRIMARY KEY, `title` varchar( 200 ) NOT NULL, `author` varchar( 50 ) NOT NULL, `publication_date` date NOT NULL) ; args= None . . .
使用终端的搜索快速定位 ( Ctrl + F 搜索 应用名称 . 迁移文件名称 ) 到应用迁移文件执行的SQL语句 .
执行数据迁移命令的ORM日志信息太多 , 后续只获取最重要SQL语句 , 其他信息不展示了 .
在Django模型中设置默认值后 , 这个默认值主要是用于Django ORM ( 对象关系映射 ) 在创建新记录时自动填充该字段 .
当通过Django的ORM ( 如使用Model . objects . create ( ) 或instance . save ( ) 方法 ) 来创建或更新模型实例时 ,
如果相关字段没有显式地设置值 , Django将会使用模型中定义的默认值 . 然而 , 当在数据库管理工具 ( 如Navicat ) 中直接查看或编辑数据库表时 , 看到的是数据库层面的结构和数据 , 而不是Django模型层面的逻辑 .
数据库表本身可能并没有显式地 '存储' Django模型中的默认值设置 ,
因为默认值是在应用程序层面 ( 即Django ORM ) 处理的 , 而不是在数据库层面 . 如果你通过Navicat查看数据库表 , 并尝试插入新记录而没有为某个字段提供值 , 而这个字段在Django模型中有默认值 ,
但数据库表本身没有为该字段设置默认值 ( 这通常是Django迁移文件没有为数据库表字段显式设置默认值的情况 ) ,
那么数据库将不会自动填充该字段 .
数据库会期待你在插入记录时为该字段提供一个值 , 或者该字段被设置为允许NULL ( 如果模型中也允许NULL的话 ) . 要解决这个问题 , 有几个选项 :
* 1. 在数据库层面设置默认值 : 可以手动修改数据库表 , 为相关字段设置默认值 . 这通常不是推荐的做法 , 因为它会与Django模型的定义脱节 , 并可能在将来的迁移中导致问题 . 但是 , 如果确实需要在数据库层面设置默认值 , 并且了解这样做的后果 , 可以这样做 .
* 2. 在插入数据时显式提供值 : 当通过Navicat等数据库管理工具插入数据时 , 确保为所有字段提供值 , 包括那些在Django模型中有默认值的字段 .
* 3. 使用Django ORM : 尽可能使用Django的ORM来管理你的数据库操作 , 这样就可以利用Django提供的所有功能 , 包括默认值处理 . 请记住 , Django的模型定义和数据库表结构之间可能存在差异 , 特别是在处理默认值 , 约束和索引等高级特性时 .
这些差异通常是通过Django的迁移系统来管理和解决的 . ( 在 4.2 小节查看defaule默认值的设置效果 . )
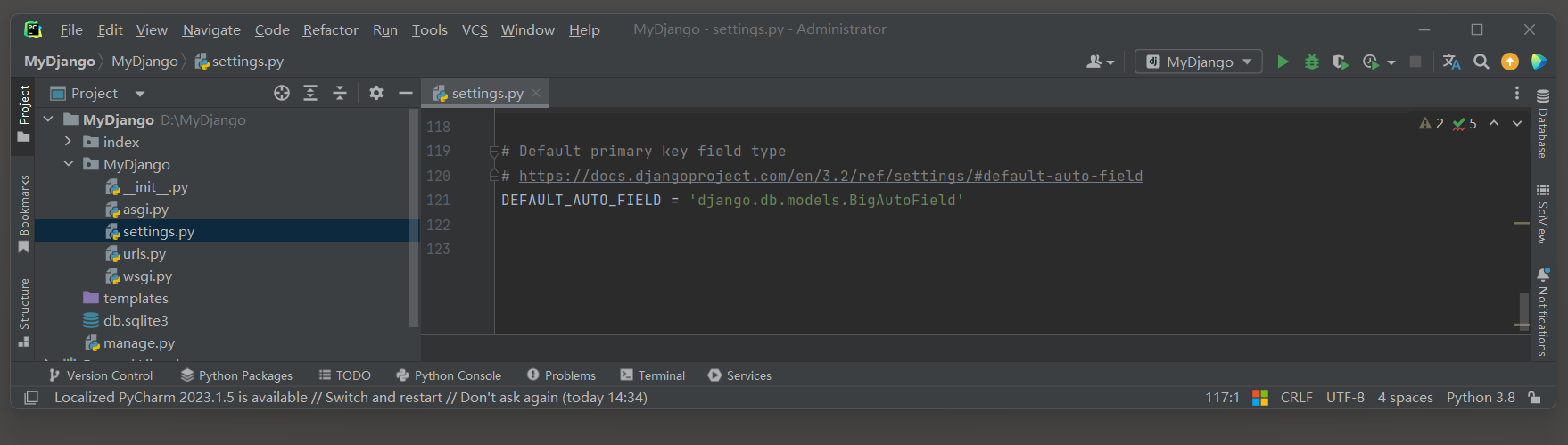
在Django中 , DEFAULT_AUTO_FIELD是一个在项目的settings . py文件中设置的全局选项 ,
它用于指定当模型 ( Model ) 中未显式指定主键字段时 , Django应该使用哪种自动增长字段类型作为主键 . 从Django 3.2 版本开始 , 这个设置变得更加重要 , 因为Django默认的主键类型从AutoField更改为了BigAutoField ,
以适应更大的数据集和更广泛的数据库兼容性 .
DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'
当将DEFAULT_AUTO_FIELD设置为 'django.db.models.BigAutoField' 时 ,
告诉Django , 对于所有未明确指定主键字段的模型 , 都应该使用BigAutoField作为主键 .
这意味着 , Django会为这些模型的主键字段生成一个大的自增整数 , 这有助于避免在数据量大时遇到整数溢出的问题 .
为什么使用 BigAutoField?
* 1. 支持更大的数据集 : BigAutoField使用的是 64 位整数 , 相比于AutoField ( 通常使用 32 位整数 ) , 它可以支持更大的数据范围 , 这对于存储大量记录的应用程序尤为重要 .
* 2. 数据库兼容性 : 尽管大多数现代数据库系统都支持大整数作为主键 , 但显式地指定BigAutoField可以帮助确保Django应用在不同数据库之间具有更好的兼容性 . 注意事项 :
* 1. 这个设置仅影响在DEFAULT_AUTO_FIELD设置之后创建的模型 . 对于已经存在的模型 , 如果它们的主键是AutoField , 并且你希望更改为BigAutoField , 需要手动修改这些模型的定义 .
* 2. 在迁移现有项目以使用BigAutoField时 , 请注意数据库迁移的复杂性和潜在的性能影响 . 特别是 , 如果有一个非常大的数据库 , 更改主键类型可能会非常耗时 , 并且需要仔细规划 .
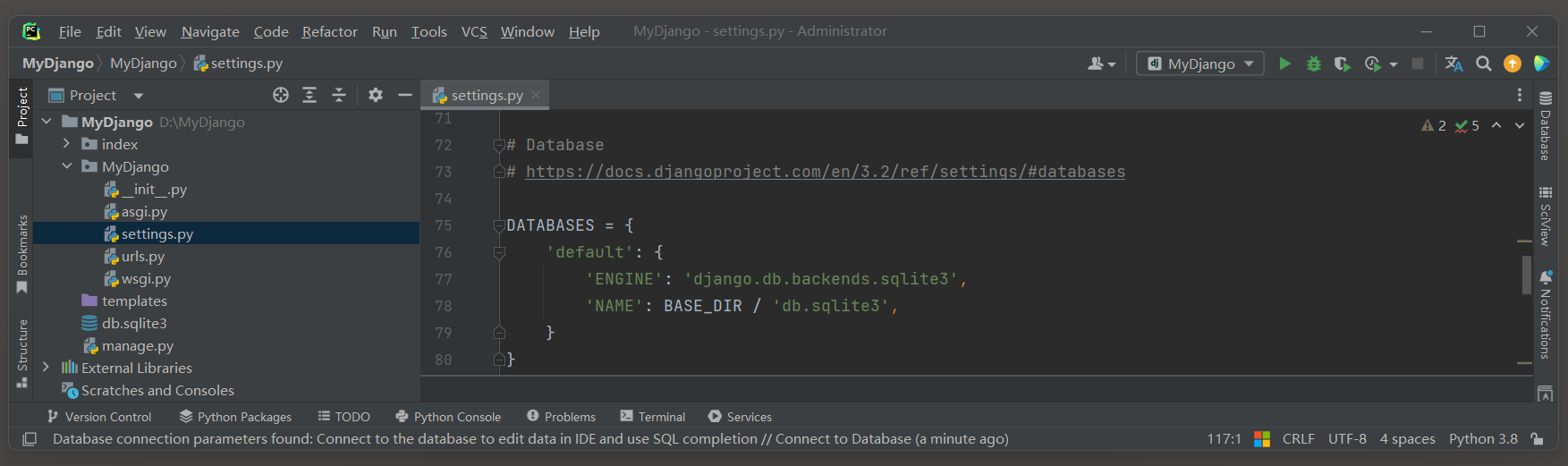
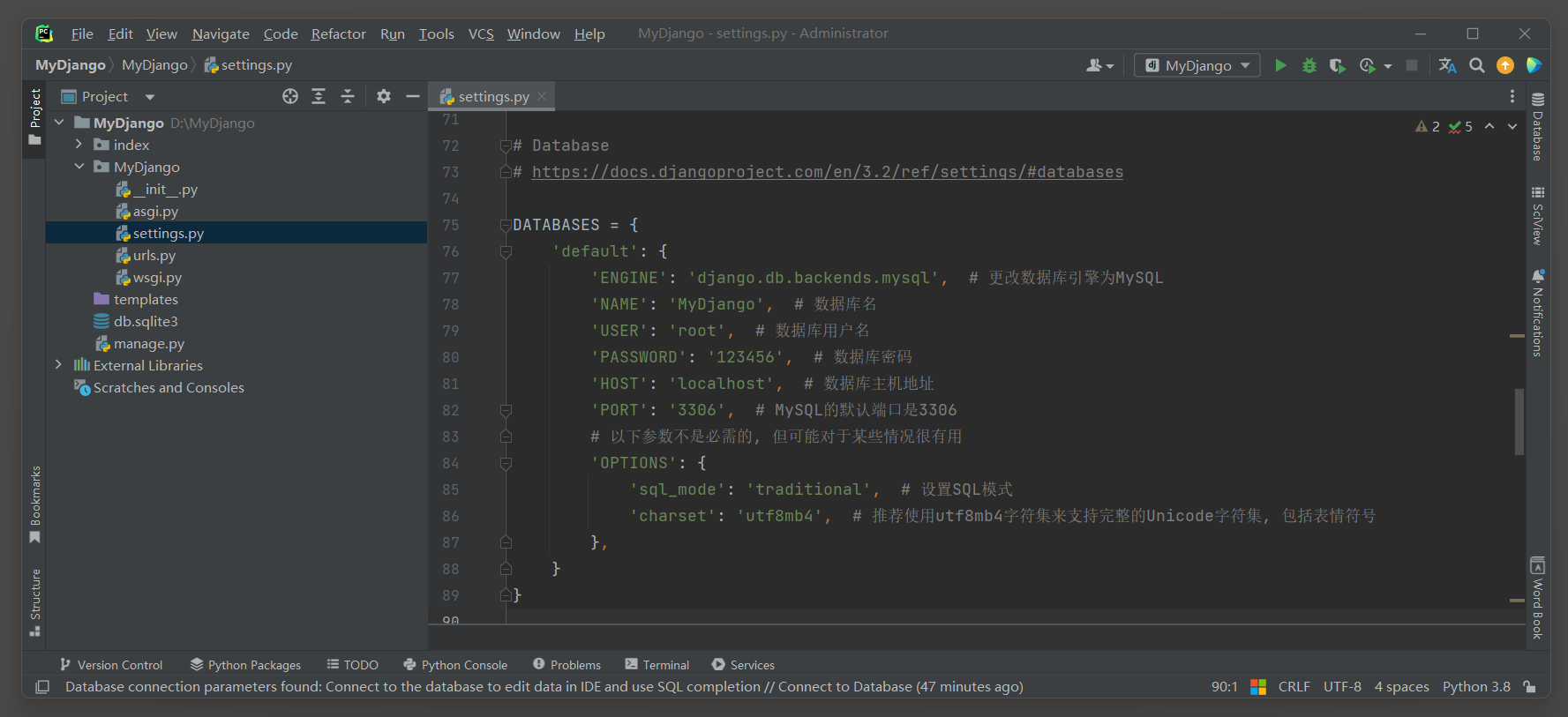
在settings . py文件中 , DATABASES是一个字典类型的配置项 , 用于指定Django项目使用的数据库 .
这个字典可以包含多个数据库的配置 , 但默认情况下 , Django会使用名为default的数据库配置 .
以下是一个DATABASES的默认配置 , 展示了如何配置Django使用SQLite数据库 :
DATABASES = { 'default' : { 'ENGINE' : 'django.db.backends.sqlite3' , 'NAME' : BASE_DIR / 'db.sqlite3' , }
}
在这个配置中 , ENGINE指定了Django使用的数据库后端 , 'django.db.backends.sqlite3' 表示使用SQLite数据库 .
NAME是数据库的名称 , 对于SQLite来说 , 它通常是数据库文件的路径 .
BASE_DIR是项目根目录的路径 , 它在settings . py文件顶部定义 , 用于帮助定位项目内的其他文件 .
如果需要配置Django以使用其他类型的数据库 ( 如 : MySQL ) , 可以修改ENGINE的值 , 并相应地调整其他配置选项 .
注意 : ORM只负责根据模型 ( models ) 的定义来创建或修改数据库中的表 , 而不会直接创建数据库本身 .
在连接数据库之前 , 需要确保数据库已经存在 , 并且Django ( 或任何其他ORM框架 ) 的配置能够正确地指向这个数据库 .
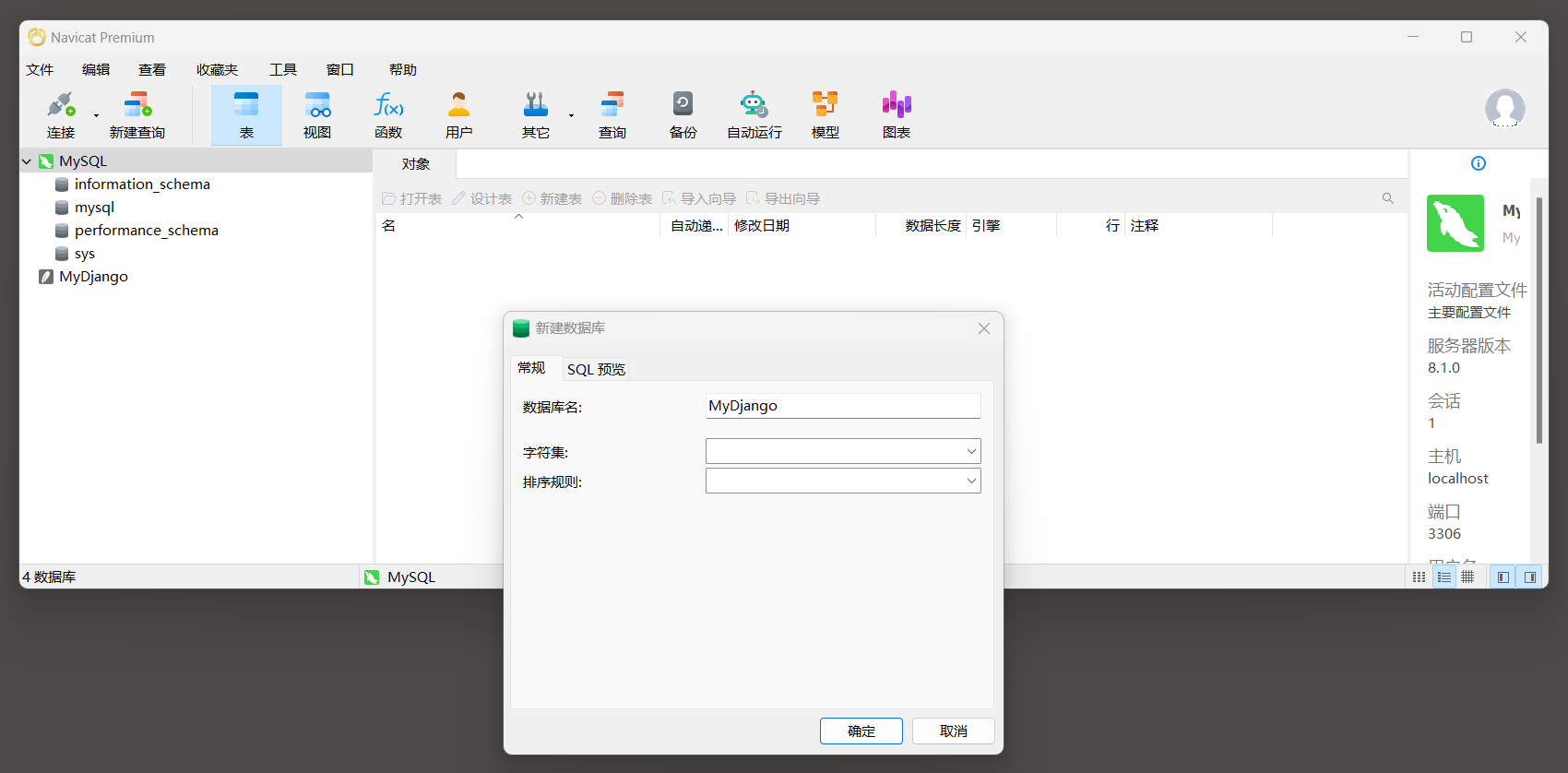
首先使用Navicat工具连接MySQL服务器 , 并创建 "MyDjango" 数据库 .
然后 , 编辑连接数据库的配置 , 代码如下 :
DATABASES = { 'default' : { 'ENGINE' : 'django.db.backends.mysql' , 'NAME' : 'MyDjango' , 'USER' : 'root' , 'PASSWORD' : '123456' , 'HOST' : 'localhost' , 'PORT' : '3306' , 'OPTIONS' : { 'sql_mode' : 'traditional' , 'charset' : 'utf8mb4' , } , }
}
在使用MySQL作为Django项目的数据库后端时 , 需要安装一个额外的Python库来提供对MySQL的支持 .
对于MySQL数据库 , 这个库通常是mysqlclient或PyMySQL , 可以通过pip安装它们之一 :
pip install mysqlclient
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple mysqlclient
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple PyMySQL
mysqlclient ( 也被称为MySQLdb或MySQL-python , 尽管后者是早期的名称 ) 是一个用于Python的MySQL数据库适配器 .
它允许Python程序连接到MySQL数据库服务器 , 执行SQL查询 , 并处理查询结果 .
mysqlclient是Python中最流行的MySQL数据库接口之一 , 它提供了对MySQL数据库的强大支持 . 从Django 3.1 开始 , 官方文档推荐使用 'mysqlclient' 作为MySQL数据库的后端 , 因为它比 'PyMySQL' 提供了更好的性能和兼容性 .
MySQLdb是Python连接MySQL的一个流行驱动 , 也被称为MySQL-python .
它原本是一个基于C语言开发的库 , 专为Python 2. x版本设计 .
由于它只支持Python 2. x , 并且安装时需要许多前置条件 ( 尤其是在Windows平台上安装较为困难 ) ,
因此在Python 3. x环境下逐渐被其衍生版本所取代 . mysqlclient是MySQLdb的一个分支 , 它解决了对Python 3. x版本的兼容性问题 .
mysqlclient同样基于C语言开发 , 因此在性能上通常优于纯Python实现的数据库驱动 ( 如PyMySQL ) .
然而 , 这也意味着在编译安装时可能会遇到一些与C扩展模块相关的问题 .
在mysqlclient的上下文中 , 通过import MySQLdb导入的模块实际上是mysqlclient的一个接口或别名 , 而不是一个独立的MySQLdb模块 .
这种设计允许开发者在不修改旧代码的情况下 , 将项目迁移到Python 3. x并继续使用mysqlclient作为MySQL数据库的驱动 .
PS D: \MyDjango> pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple mysqlclient
Looking in indexes: https: // pypi. tuna. tsinghua. edu. cn/ simple
Collecting mysqlclientDownloading https: // pypi. tuna. tsinghua. edu. cn/ packages/ . . . / mysqlclient- 2.2 .4 - cp38- cp38- win_amd64. whl ( 203 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 203.3 / 203.3 kB 650.2 kB/ s eta 0 : 00 : 00
Installing collected packages: mysqlclient
Successfully installed mysqlclient- 2.2 .4
使用上面 2.3 示例中的模型 , 执行数据迁移命令 :
PS D: \MyDjango> python manage. py makemigrations
No changes detected
PS D: \MyDjango> python manage. py migrateApplying contenttypes. 0001_initial. . . OKApplying auth. 0001_initial. . . OKApplying admin. 0001_initial. . . OKApplying admin. 0002_logentry_remove_auto_add. . . OKApplying admin. 0003_logentry_add_action_flag_choices. . . OKApplying contenttypes. 0002_remove_content_type_name. . . OKApplying auth. 0002_alter_permission_name_max_length. . . OKApplying auth. 0003_alter_user_email_max_length. . . OKApplying auth. 0004_alter_user_username_opts. . . OKApplying auth. 0005_alter_user_last_login_null. . . OKApplying auth. 0006_require_contenttypes_0002. . . OKApplying auth. 0007_alter_validators_add_error_messages. . . OKApplying auth. 0008_alter_user_username_max_length. . . OKApplying auth. 0009_alter_user_last_name_max_length. . . OKApplying auth. 0010_alter_group_name_max_length. . . OKApplying auth. 0011_update_proxy_permissions. . . OKApplying auth. 0012_alter_user_first_name_max_length. . . OKApplying index. 0001_initial. . . OKApplying sessions. 0001_initial. . . OK
PS D: \MyDjango>
当看到 : No changes detected这个消息时 , 它意味着Django的ORM在检查模型后 , 没有发现自上次迁移以来有任何变更 .
这并不意味着数据库没有创建或不存在 , 而是指当前的模型状态与数据库中已经存在的表结构相匹配 .
使用Navicat工具查询数据库中创建的表格 .
如果遇到安装mysqlclient的问题 ( 例如 , 因为它依赖于本地安装的MySQL客户端库 ) , 那么PyMySQL可能是一个可行的替代方案 .
PyMySQL模块是一个纯Python实现的MySQL客户端 , 它提供了一个与Python标准数据库接口 ( DB-API ) 兼容的接口 ,
使得开发人员可以使用Python代码来连接和操作MySQL数据库 .
PS D: \MyDjango> pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple PyMySQL
Looking in indexes: https: // pypi. tuna. tsinghua. edu. cn/ simple
Collecting PyMySQLDownloading https: // pypi. tuna. tsinghua. edu. cn/ packages/ 0c/ 94 / . . . / PyMySQL- 1.1 .1 - py3- none- any . whl ( 44 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 45.0 / 45.0 kB 2.2 MB/ s eta 0 : 00 : 00
Installing collected packages: PyMySQL
Successfully installed PyMySQL- 1.1 .1
PS D: \MyDjango>
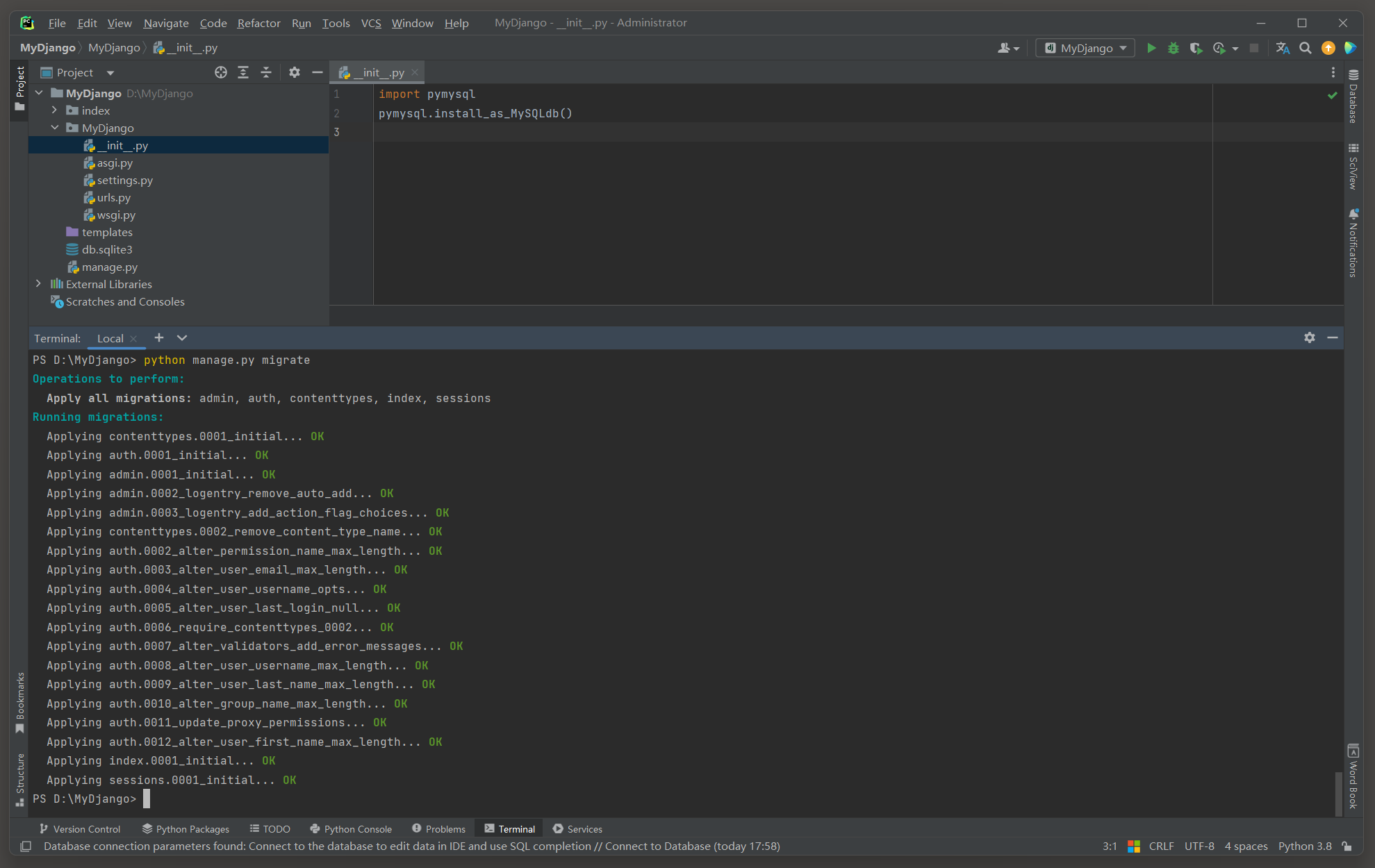
使用PyMySQL , 还需要在Django项目或应用的目录的__init__ . py文件中添加以下代码来告诉Django使用 'PyMySQL' 作为MySQL数据库的后端 .
由于Django的MySQL后端 ( django . db . backends . mysql ) 默认期望使用mysqlclient , 因此需要告诉Django在连接MySQL时使用PyMySQL .
这通常可以通过在项目的__init__ . py文件中调用pymysql . install_as_MySQLdb ( ) 来实现 ,
这样Django在尝试导入MySQLdb时就会实际加载PyMySQL .
( 如果不放心就卸载mysqlclient , 命令 : pip uninstall mysqlclient . )
PS D: \MyDjango> pip uninstall mysqlclient
Found existing installation: mysqlclient 2.2 .4
Uninstalling mysqlclient- 2.2 .4 : Would remove: d: \python\python38\lib\site- packages\mysqlclient- 2.2 .4 . dist- info\* d: \python\python38\lib\site- packages\mysqldb\*
Proceed ( Y/ n) ? ySuccessfully uninstalled mysqlclient- 2.2 .4
PS D: \MyDjango>
import pymysql
pymysql. install_as_MySQLdb( ) 为什么这样做?
Django的数据库后端系统是基于一个叫做DATABASES的配置字典 , 它允许你指定要使用的数据库引擎 .
对于MySQL , Django期望有一个名为django . db . backends . mysql的数据库后端 , 该后端内部会使用MySQLdb来与MySQL数据库进行通信 . pymysql . install_as_MySQLdb ( ) 这个函数的目的是让Django在尝试使用MySQL数据库时 .
能够透明地通过PyMySQL来连接和操作MySQL数据库 , 而不需要修改Django源代码中的任何数据库后端代码 .
这是因为Django在内部查找名为MySQLdb的模块来与MySQL通信 , 而pymysql . install_as_MySQLdb ( ) 正是将PyMySQL模块伪装成MySQLdb ,
从而使得Django能够无缝地使用PyMySQL .
删除MyDjango中的数据表 , 重新执行数据迁移命令来验证数据库的连接 :
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying contenttypes. 0001_initial. . . OKApplying auth. 0001_initial. . . OKApplying admin. 0001_initial. . . OKApplying admin. 0002_logentry_remove_auto_add. . . OKApplying admin. 0003_logentry_add_action_flag_choices. . . OKApplying contenttypes. 0002_remove_content_type_name. . . OKApplying auth. 0002_alter_permission_name_max_length. . . OKApplying auth. 0003_alter_user_email_max_length. . . OKApplying auth. 0004_alter_user_username_opts. . . OKApplying auth. 0005_alter_user_last_login_null. . . OKApplying auth. 0006_require_contenttypes_0002. . . OKApplying auth. 0007_alter_validators_add_error_messages. . . OKApplying auth. 0008_alter_user_username_max_length. . . OKApplying auth. 0009_alter_user_last_name_max_length. . . OKApplying auth. 0010_alter_group_name_max_length. . . OKApplying auth. 0011_update_proxy_permissions. . . OKApplying auth. 0012_alter_user_first_name_max_length. . . OKApplying index. 0001_initial. . . OKApplying sessions. 0001_initial. . . OK
PS D: \MyDjango>
然而 , 值得注意的是 , 随着Django和PyMySQL的发展 , Django从 2. x版本开始已经内置了对PyMySQL的支持 ,
这意味着你不再需要通过pymysql . install_as_MySQLdb ( ) 来 '欺骗' Django使用PyMySQL . 相反 , 可以在DATABASES配置字典中直接指定使用django . db . backends . mysql作为引擎 ,
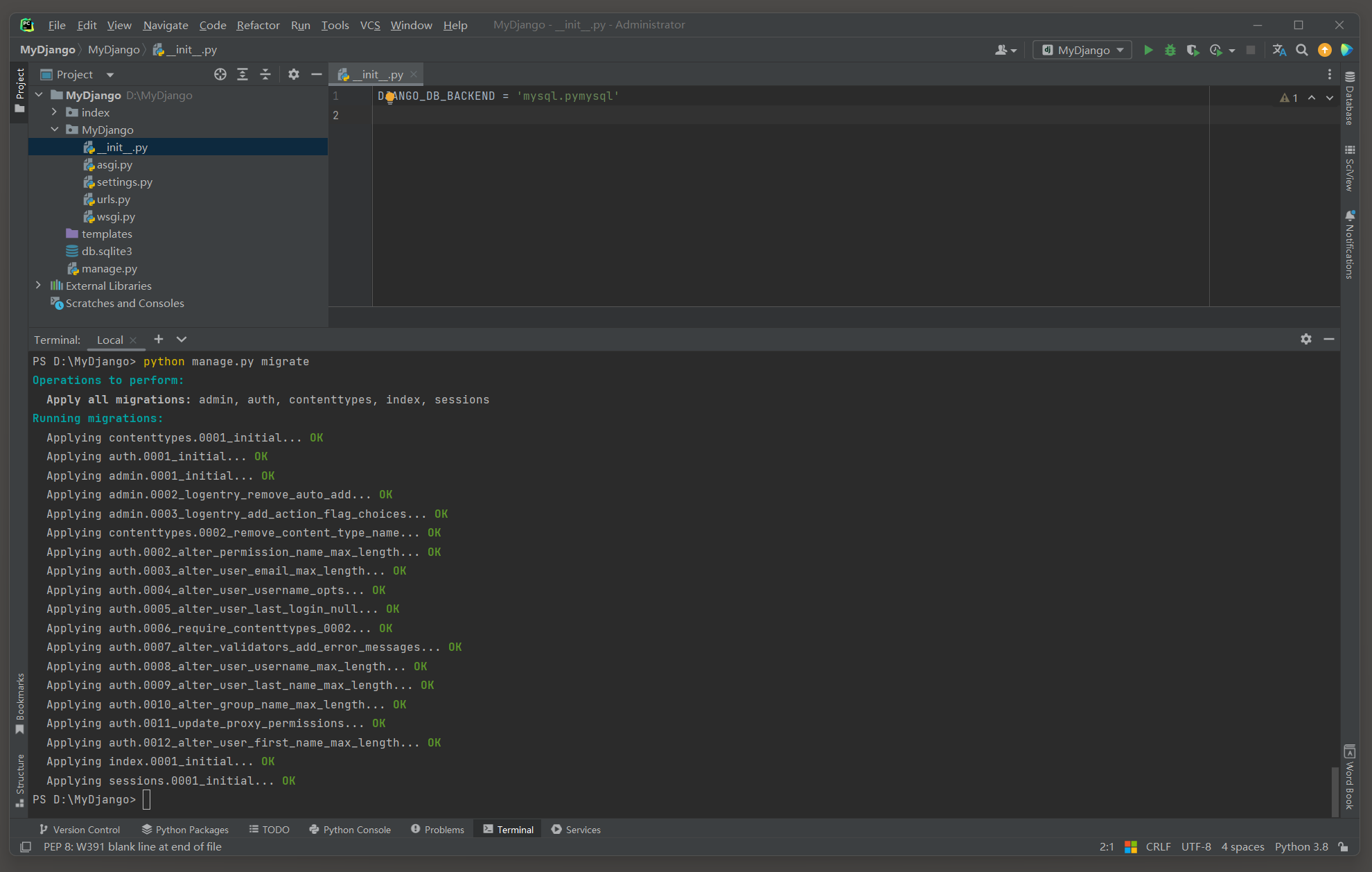
并在项目的__init__ . py文件或任何在数据库连接之前被导入的地方设置DJANGO_DB_BACKEND环境变量为 'mysql.pymysql' .
注意 , 这种环境变量的方法可能不是所有Django版本都支持 , 具体请参考你正在使用的Django版本的官方文档 .
DJANGO_DB_BACKEND = 'mysql.pymysql'
删除MyDjango中的数据表 , 重新执行数据迁移命令来验证数据库的连接 :
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying contenttypes. 0001_initial. . . OKApplying auth. 0001_initial. . . OKApplying admin. 0001_initial. . . OKApplying admin. 0002_logentry_remove_auto_add. . . OKApplying admin. 0003_logentry_add_action_flag_choices. . . OKApplying contenttypes. 0002_remove_content_type_name. . . OKApplying auth. 0002_alter_permission_name_max_length. . . OKApplying auth. 0003_alter_user_email_max_length. . . OKApplying auth. 0004_alter_user_username_opts. . . OKApplying auth. 0005_alter_user_last_login_null. . . OKApplying auth. 0006_require_contenttypes_0002. . . OKApplying auth. 0007_alter_validators_add_error_messages. . . OKApplying auth. 0008_alter_user_username_max_length. . . OKApplying auth. 0009_alter_user_last_name_max_length. . . OKApplying auth. 0010_alter_group_name_max_length. . . OKApplying auth. 0011_update_proxy_permissions. . . OKApplying auth. 0012_alter_user_first_name_max_length. . . OKApplying index. 0001_initial. . . OKApplying sessions. 0001_initial. . . OK
PS D: \MyDjango>
在Django中 , ORM用于将数据库表映射为Python类 , 使得数据库操作更加直观和易于管理 .
ORM中通过直接修改Django模型 ( 即Python类 ) , 来反映数据库表结构的变更 ( 如添加 , 删除或修改字段 ) ,
并使用迁移 ( migrations ) 系统来同步这些变更到数据库 .
以下是一些常见的修改表结构的操作 :
添加新列 : 在模型中添加新的字段 .
删除列 : 从模型中删除字段 , 并运行迁移以从数据库中删除相应的列 .
修改列的数据类型 : 通过修改模型字段的类型来实现 .
修改列名 : 在Django中 , 通常不直接修改列名 , 而是通过重命名模型中的字段名 , 并运行迁移来更新数据库 .
修改表名 : Django的Meta类中的db_table选项可以用来指定表名 .
以下是如何使用Django ORM修改表结构的一般步骤 :
* 1. 修改模型 ( Model ) . 首先 , 在Django应用的models . py文件中修改模型 . 这可以包括添加新字段 , 删除现有字段或修改字段的属性 ( 如字段类型 , 长度等 ) 等操作 . * 2. 生成迁移文件 . 修改模型后 , 需要运行makemigrations命令来生成一个或多个迁移文件 . 这些文件描述了如何将你的数据库从当前状态迁移到新状态 . * 3. 查看迁移文件 . 生成的迁移文件位于应用的migrations目录下 . * 4. 应用迁移 . 在确认迁移文件正确无误后 , 需要运行migrate命令来应用迁移 , 从而更新数据库 . 通过遵循上述步骤 , 可以使用Django ORM安全地修改数据库表结构 . 注意事项 :
- 数据迁移 : 在修改字段类型或删除字段时要特别小心 , 因为这可能会导致数据丢失或损坏 . 确保了解这些操作对数据的影响 , 并在必要时备份数据 .
- 依赖关系 : 如果应用之间有迁移依赖关系 ( 例如 , 一个应用的迁移依赖于另一个应用的迁移 ) , 请确保按正确的顺序应用迁移 .
- 回滚 : 如果发现迁移导致了问题 , 可以使用migrate命令的回滚功能来撤销最近的迁移 . 但是 , 请注意 , 并非所有迁移都是可逆的 .
- 自定义迁移 : 在某些情况下 , 可能需要编写自定义迁移来处理复杂的数据库变更 . 这可以通过在migrations目录下创建包含自定义Python脚本的迁移文件来实现 .
在Django中 , 当为模型添加新字段时 , 应该考虑为该字段设置默认值 .
如果不这样做 , 尝试运行迁移 ( migration ) 命令 ( 如python manage . py makemigrations和python manage . py migrate ) ,
Django迁移系统会发出警告 , 特别是当新字段不允许为空 ( null = False ) 且没有设置默认值时 . 这种警告的原因是 , Django需要知道如何在数据库中为现有记录填充这个新字段的值 .
如果字段不允许为空且没有默认值 , 那么对于现有记录来说 , 迁移将无法进行 , 因为没有合适的值可以填充 .
为了避免这种警告 , 可以采取以下几种方法之一 :
* 1. 设置默认值 : 为新字段设置一个合理的默认值 . 这可以通过在模型字段定义中设置default参数来实现 , 例如 : new_field = models . CharField ( max_length = 100 , default = 'default_value' ) 这样 , 当迁移应用到数据库时 , 所有现有记录的新字段都将被设置为 'default_value' . * 2. 允许字段为空 : 如果新字段没有合适的默认值 , 可以将其设置为允许为空 ( null = True ) , 这样现有记录就不需要为这个字段提供值 . new_field = models . CharField ( max_length = 100 , null = True ) 注意 : 允许字段为空可能会影响你的数据完整性和查询逻辑 . * 3. 为现有记录编写数据迁移 : 如果新字段的默认值依赖于现有数据 , 或者想要根据特定逻辑为每个现有记录设置不同的值 , 可以编写一个数据迁移 ( data migration ) . 这通常涉及在迁移文件中编写自定义的Python代码 , 用于在迁移应用时更新数据库中的记录 . 注意 : 数据迁移比简单的模型字段更改更复杂 , 需要更仔细地考虑和测试 . * 4. 使用django-extensions的runscript或自定义管理命令 : 如果数据迁移过于复杂 , 或者想要在迁移之外的时间点更新数据 , 可以使用django-extensions的runscript命令或编写自定义的Django管理命令来执行这些更新 . 总之 , 为模型添加新字段时设置默认值是一个好习惯 , 它有助于确保迁移过程的顺利进行 , 并避免在数据库中出现意外的空值或错误 .
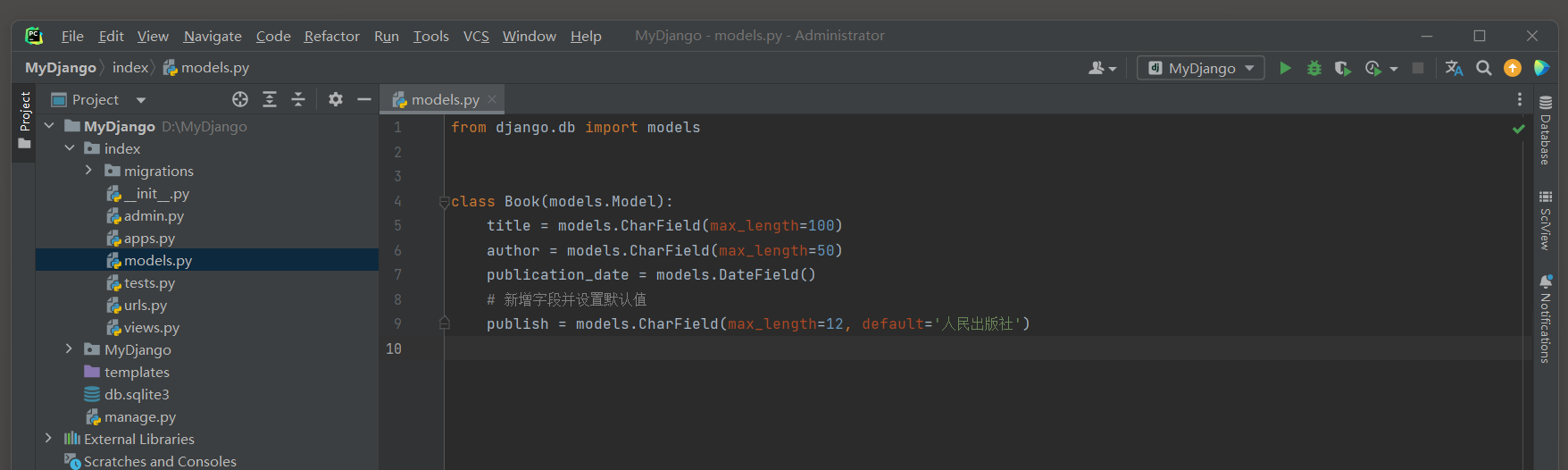
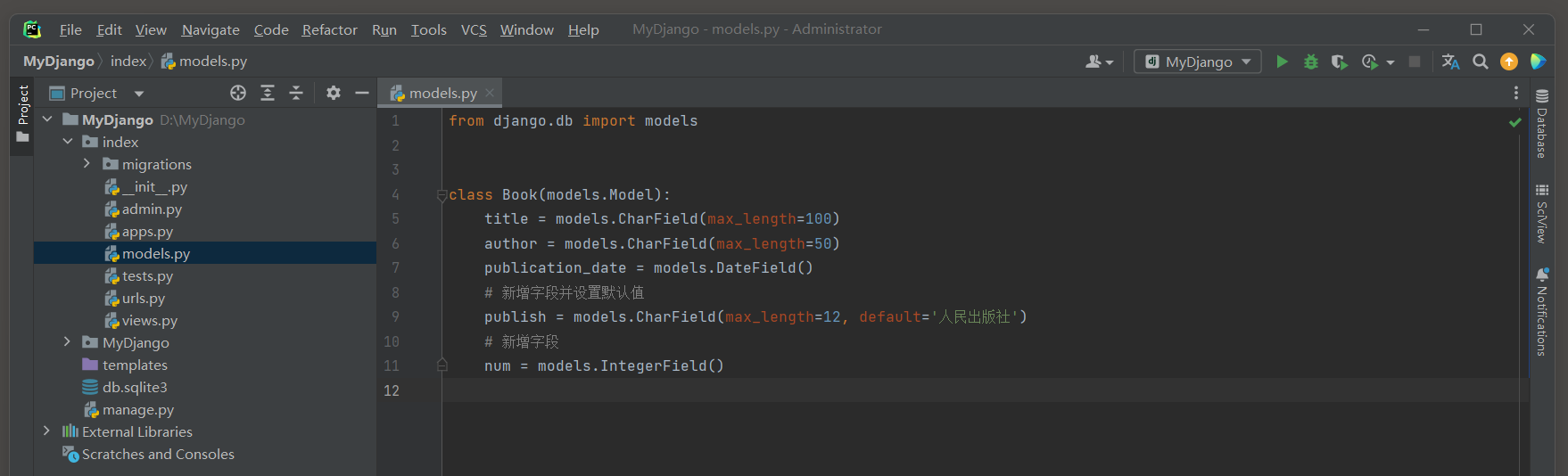
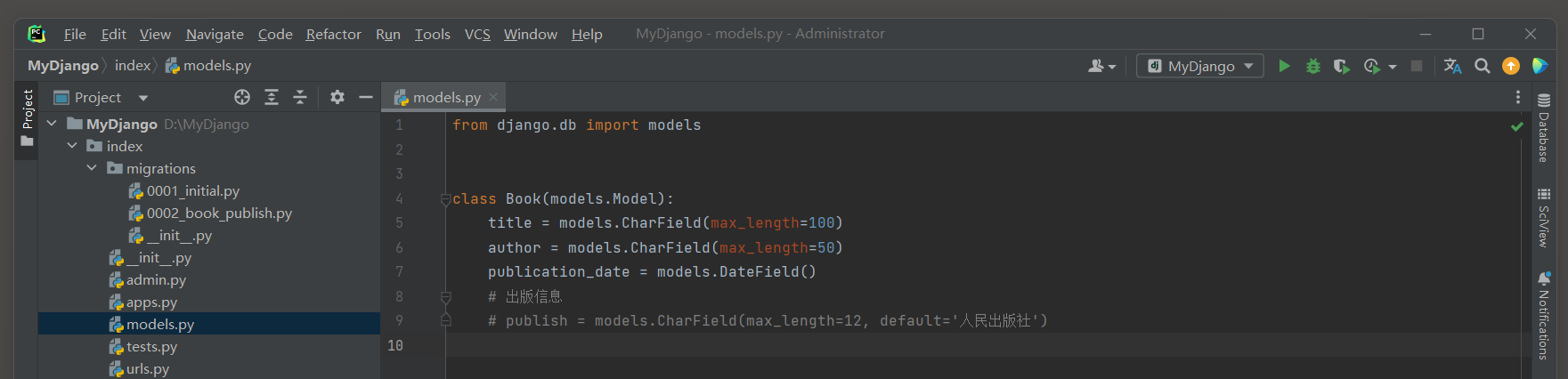
下面将在Django模型类中增加一个新的字段 . 例如在Book模型中添加一个publish字段 , 可以这样做 :
from django. db import modelsclass Book ( models. Model) : title = models. CharField( max_length= 100 ) author = models. CharField( max_length= 50 ) publication_date = models. DateField( ) publish = models. CharField( max_length= 12 , default= '人民出版社' )
接下来 , 需要运行makemigrations命令来生成一个新的迁移文件 , 这个文件描述了模型变更 .
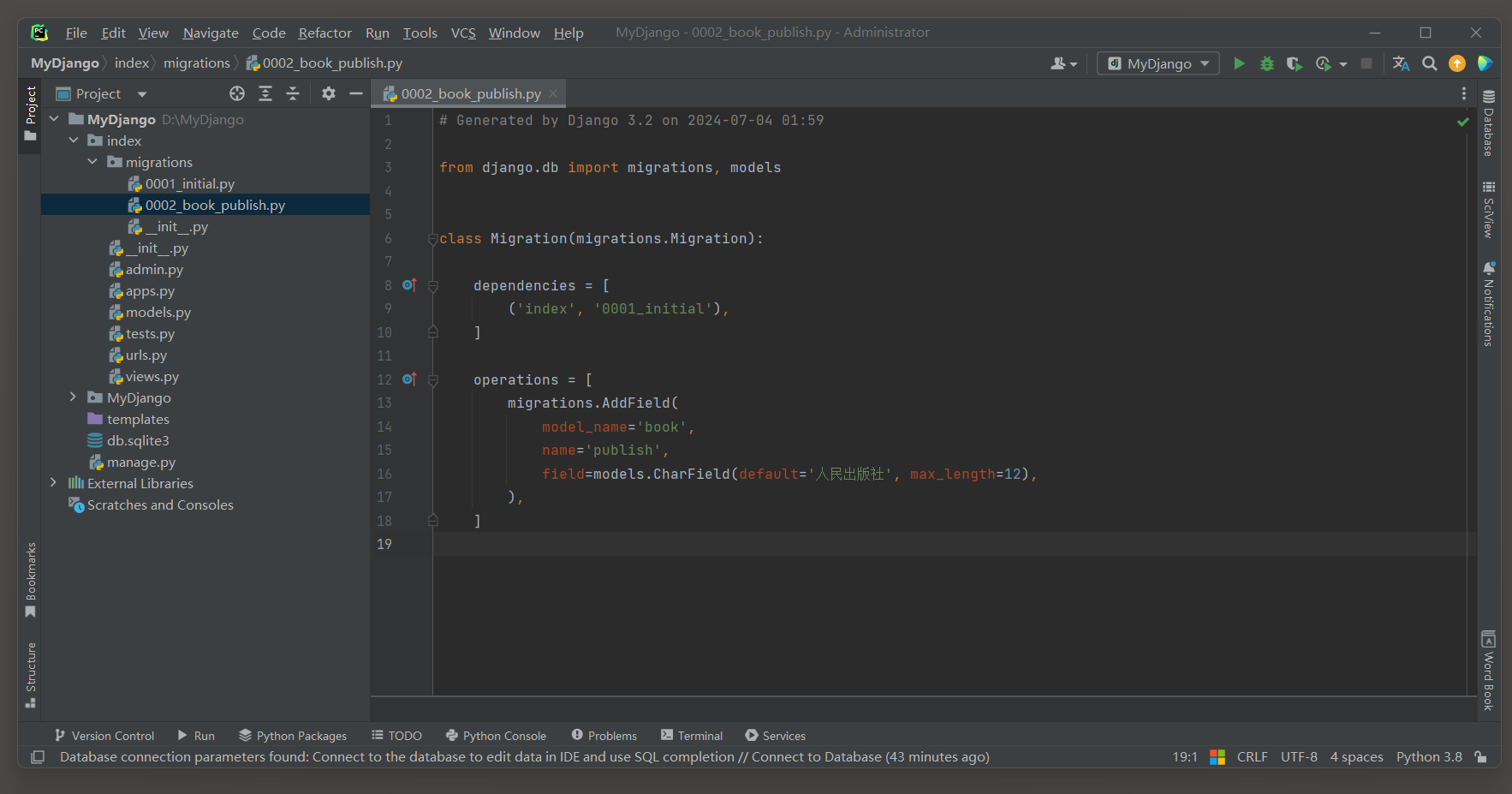
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0002_book_publish. py- Add field publish to book
PS D: \MyDjango>
这将在app的migrations目录下创建一个新的迁移文件 .
最后 , 需要运行migrate命令来应用这个迁移 , 这将更新数据库以匹配模型 .
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying index. 0002_book_publish. . . OK
Applying index . 0002 _book_publish. . .
ALTER TABLE ` index_book` ADD COLUMN ` publish` varchar ( 12 ) DEFAULT % s NOT NULL ; ( params [ '人民出版社' ] ) ( 0.016 ) ALTER TABLE ` index_book` ADD COLUMN ` publish` varchar ( 12 ) DEFAULT '人民出版社' NOT NULL ; args= [ '人民出版社' ]
ALTER TABLE ` index_book` ALTER COLUMN ` publish` DROP DEFAULT ; ( params [ ] )
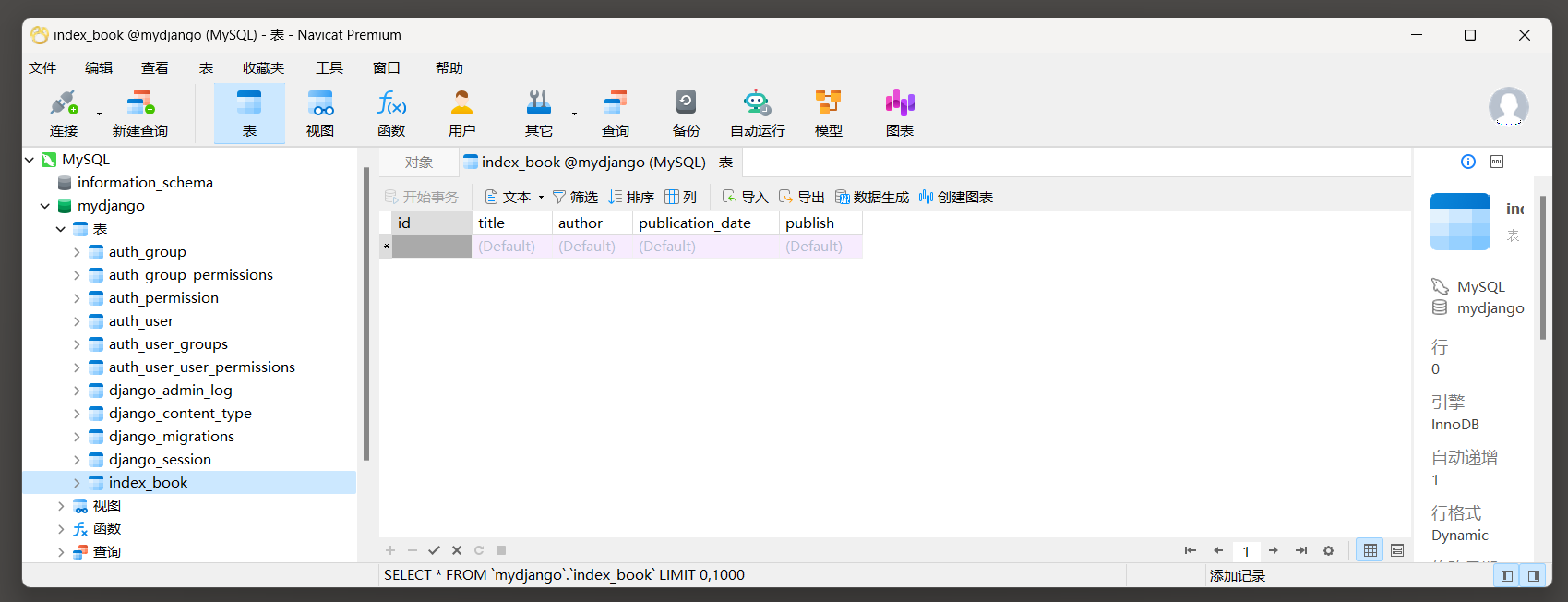
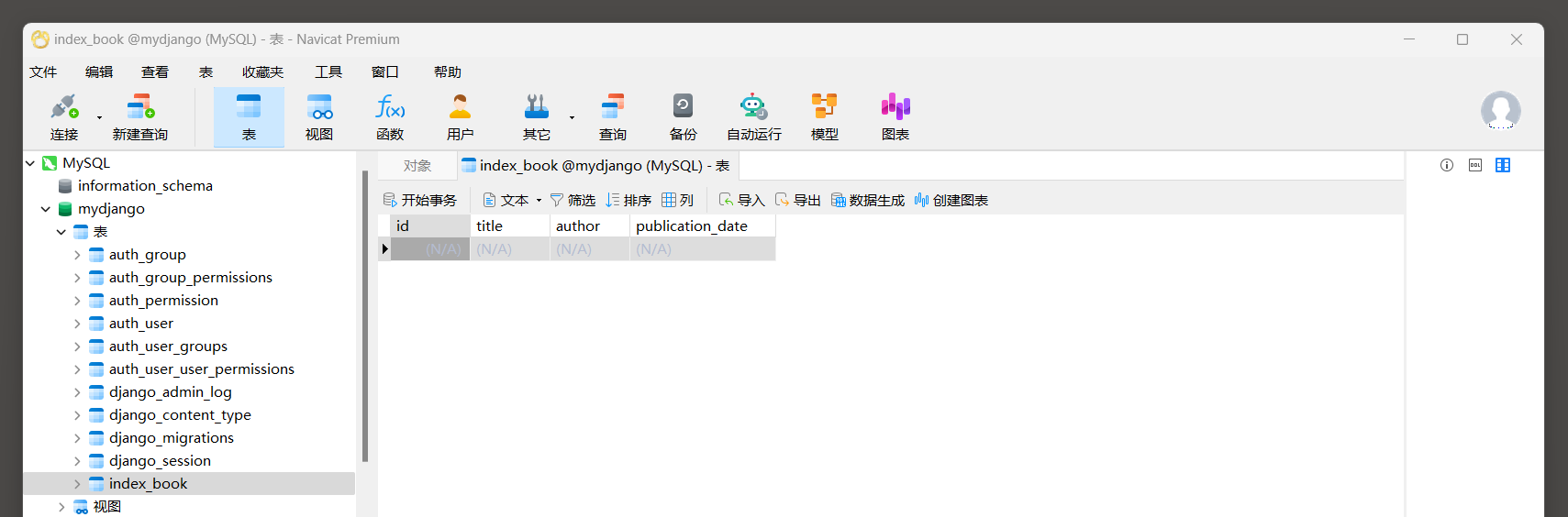
( 0.015 ) ALTER TABLE ` index_book` ALTER COLUMN ` publish` DROP DEFAULT ; args= [ ] 使用Navicat工具查看表格的字段 .
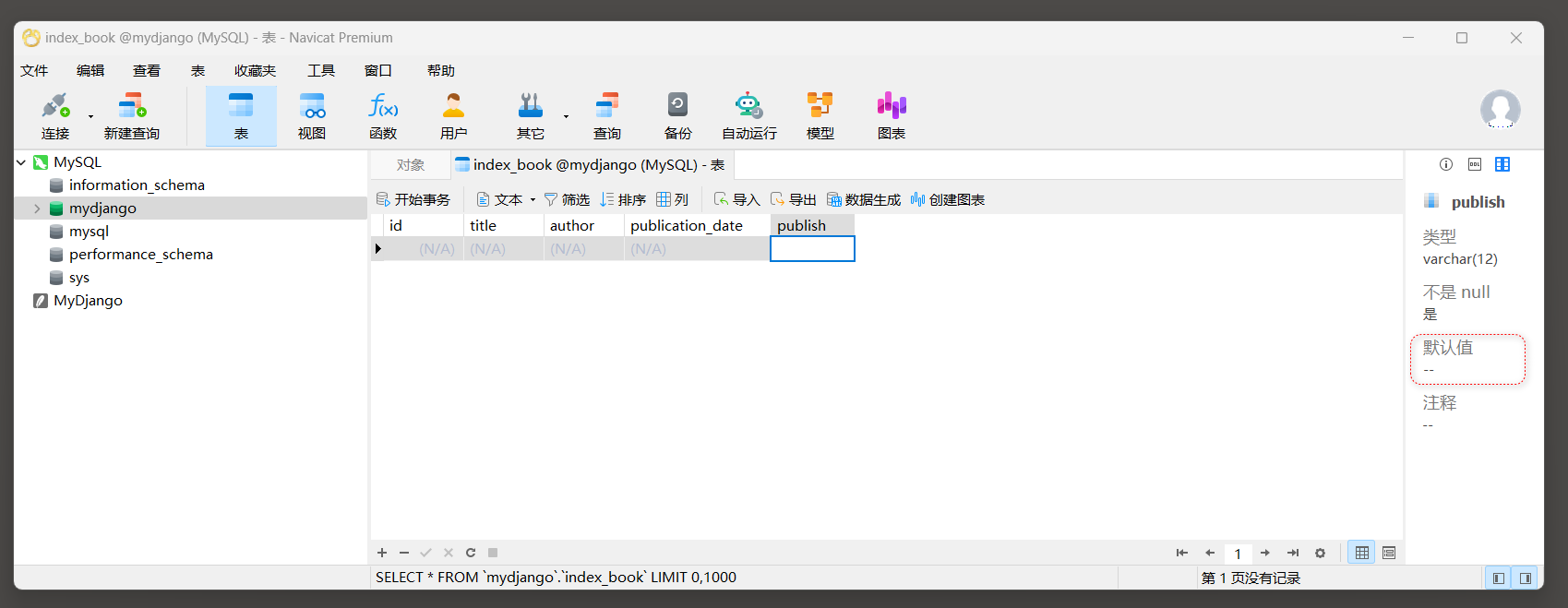
查看publish字段的信息 , 发现没有设置默认值 ( 看 2.5 小节说明 ) .
再新增一个字段num到book , 不设置默认值 , 不设置允许为空 , 查看执行迁移时的提示信息 .
from django. db import modelsclass Book ( models. Model) : title = models. CharField( max_length= 100 ) author = models. CharField( max_length= 50 ) publication_date = models. DateField( ) publish = models. CharField( max_length= 12 , default= '人民出版社' ) num = models. IntegerField( )
PS D: \MyDjango> python manage. py makemigrations
You are trying to add a non- nullable field 'num' to book without a default;
we can't do that ( the database needs something to populate existing rows) .
Please select a fix: 1 ) Provide a one- off default now ( will be set on all existing rows with a null value for this column) 2 ) Quit, and let me add a default in models. py
Select an option:
如果选择 1 , 则迁移工具将要求您输入一个默认值 , 该值将用于填充所有现有记录的num字段 .
如果选择 2 , 则需要在models . py中为该字段设置一个默认值 , 然后重新运行迁移命令 .
在Django中 , 可以使用migrate命令结合应用名和迁移名称 ( 可选 ) 来执行回滚 .
具体操作步骤如下 :
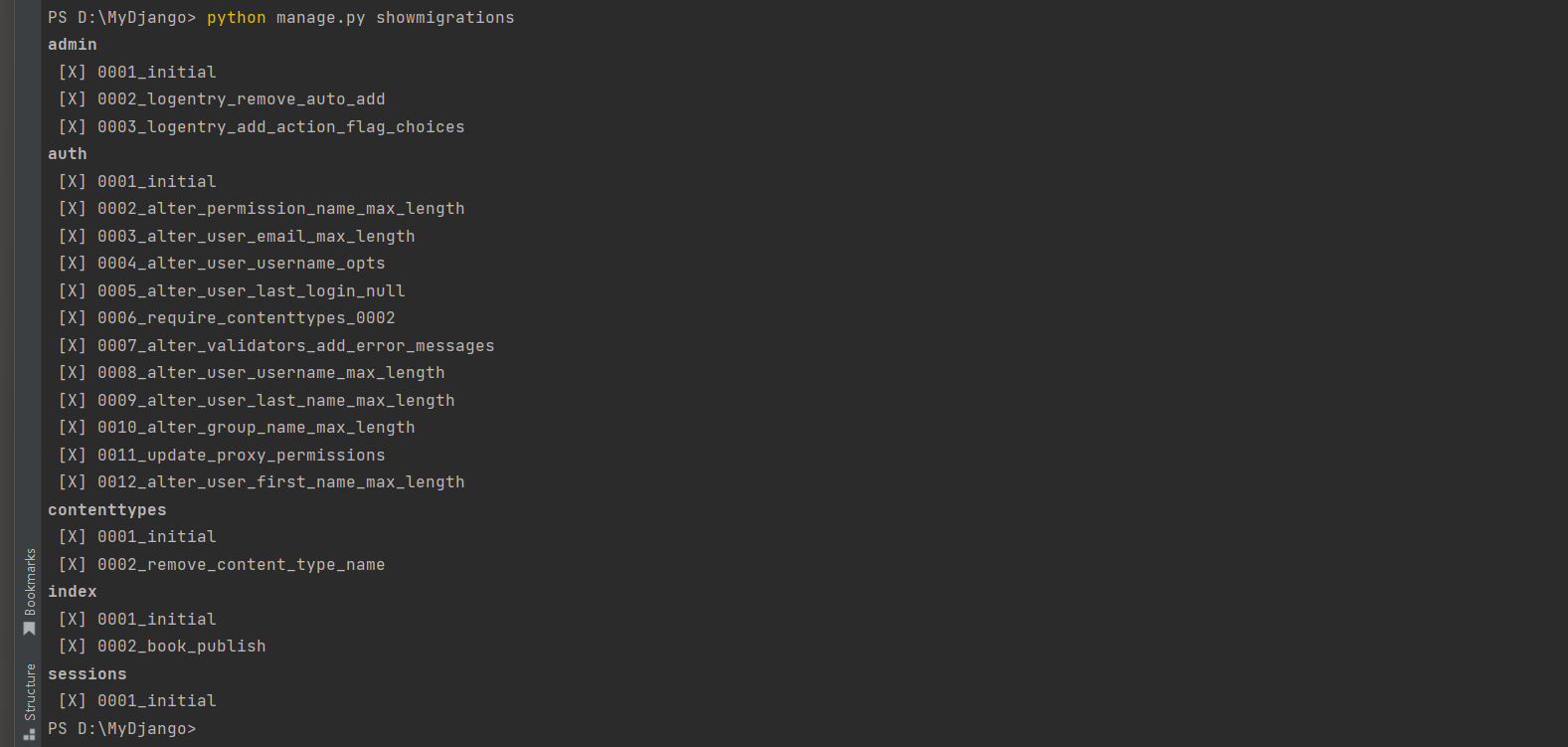
* 1. 首先列出所有迁移 ( 以找到要回滚到的迁移名称 ) : python manage . py showmigrations . 使用showmigrations查看迁移状态命令来查看哪些迁移文件已经被应用 , 哪些还没有 .
PS D: \MyDjango> python manage. py showmigrations
admin[ X] 0001_initial[ X] 0002_logentry_remove_auto_add[ X] 0003_logentry_add_action_flag_choices
auth[ X] 0001_initial[ X] 0002_alter_permission_name_max_length[ X] 0003_alter_user_email_max_length[ X] 0004_alter_user_username_opts[ X] 0005_alter_user_last_login_null[ X] 0006_require_contenttypes_0002[ X] 0007_alter_validators_add_error_messages[ X] 0008_alter_user_username_max_length[ X] 0009_alter_user_last_name_max_length[ X] 0010_alter_group_name_max_length[ X] 0011_update_proxy_permissions[ X] 0012_alter_user_first_name_max_length
contenttypes[ X] 0001_initial[ X] 0002_remove_content_type_name
index[ X] 0001_initial[ X] 0002_book_publish
sessions[ X] 0001_initial
在这个上下文中 , 可以看到标记 ( 如 : [ X ] ) 和编号 ( 如 0001 _initial , 0002 _logentry_remove_auto_add , . . . ) 信息 .
这通常与Django的迁移 ( migrations ) 系统相关 .
Django的迁移系统允许以增量方式修改数据库模式 , 而不是直接修改数据库本身 .
每次对模型 ( models ) 进行更改时 , Django都可以生成一个迁移文件 , 该文件描述了如何将这些更改应用到数据库上 . 这里的标记和编号具体解释如下 : [ X ] : 表示迁移文件已经被执行或确认 . [ ] : ( 空方括号 ) , 表示迁移文件未被执行或未确认 . 0001 _initial : 这是迁移文件的名称 , 表示这是该应用的第一个迁移 . initial迁移通常包含了创建模型所需的所有数据库表结构的SQL语句 .
. . . 总的来说 , 这些迁移文件是Django项目中用于管理数据库模式变更的重要组件 .
通过运行这些迁移 , 可以确保数据库结构与你的Django模型保持一致 .
* 2. 执行对应的回滚命令 : - 回滚到上一个迁移 ( 例如 , 针对myapp应用 ) : python manage . py migrate myapp previous . 注意 , 这将撤销myapp的最近一次迁移 . - 撤销到特定的迁移状态 , 可以使用迁移名称 ( 如 0001 _initial ) : python manage . py migrate myapp 0001 _initial . - 撤销所有迁移 ( 慎用 ) : python manage . py migrate myapp zero . 注意 : 回滚操作主要影响的是数据库中的表结构和数据 , 而不会影响models . py文件 . Django的迁移系统并没有直接提供一个命令来回滚的记录 .
PS D: \MyDjango> python manage. py migrate index 0001_initial
Operations to perform: Target specific migration: 0001_initial, from index
Running migrations: Rendering model states. . . DONEUnapplying index. 0002_book_publish. . . OK
Unapplying index. 0002_book_publish. . .
ALTER TABLE `index_book` DROP COLUMN `publish`; ( params ( ) )
( 0.000 ) ALTER TABLE `index_book` DROP COLUMN `publish`; args= ( )
使用Navicat工具查询 , 表格已经恢复到没有新增publish字段前的状态 .
请注意 , 在执行回滚操作之前 , 最好备份你的数据库 , 以防万一出现不可预见的情况 .
此外 , 回滚操作可能会涉及到数据的丢失或损坏 , 特别是当迁移中包含了数据更改操作时 .
因此 , 在执行这些操作之前 , 请确保你完全理解其后果 .
PS D: \MyDjango> python manage. py showmigrations
. . .
index[ X] 0001_initial[ ] 0002_book_publish
sessions[ X] 0001_initial
PS D: \MyDjango>
PS D: \MyDjango> python manage. py migrate index 0002_book_publish
Operations to perform: Target specific migration: 0002_book_publish, from index
Running migrations: Applying index. 0002_book_publish. . . OK
PS D: \MyDjango>
使用Navicat工具查询 , 表格已经恢复到新增publish字段时的状态 .
Applying index. 0002_book_publish. . .
ALTER TABLE `index_book` ADD COLUMN `publish` varchar( 12 ) DEFAULT % s NOT NULL; ( params [ '人民出版社' ] )
( 0.015 ) ALTER TABLE `index_book` ADD COLUMN `publish` varchar( 12 ) DEFAULT '人民出版社' NOT NULL; args= [ '人民出版社' ] ALTER TABLE `index_book` ALTER COLUMN `publish` DROP DEFAULT; ( params [ ] )
( 0.000 ) ALTER TABLE `index_book` ALTER COLUMN `publish` DROP DEFAULT; args= [ ]
要删除一个字段 , 只需从模型中注释掉或完全删除该字段的定义 .
比如 , 如果想要从Book模型中删除publish字段 , 可以这样做 :
from django. db import modelsclass Book ( models. Model) : title = models. CharField( max_length= 100 ) author = models. CharField( max_length= 50 ) publication_date = models. DateField( )
需要运行makemigrations命令来生成一个描述删除操作的迁移文件 .
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0003_remove_book_publish. py- Remove field publish from book
PS D: \MyDjango>
运行migrate命令来应用这个迁移 , 更新数据库 .
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying index. 0003_remove_book_publish. . . OK
PS D: \MyDjango>
Applying index . 0003 _remove_book_publish. . .
ALTER TABLE ` index_book` DROP COLUMN ` publish` ; ( params ( ) )
( 0.016 ) ALTER TABLE ` index_book` DROP COLUMN ` publish` ; args= ( )
. . .
使用Navicat工具查看表格的字段 .
注意事项 :
* 1. 小心使用migrate : 在应用迁移之前 , 请确保你完全理解迁移文件的内容 . 特别是当涉及到删除字段或更改字段类型等可能导致数据丢失的操作时 .
* 2. 测试和备份 : 在对生产数据库进行迁移之前 , 请确保在开发或测试环境中彻底测试你的迁移 , 并考虑备份你的数据库以防万一 .
在修改数据库字段类型时 , 需要注意数据类型的兼容性 .
在修改前 , 应详细了解新旧数据类型的特性和限制 , 确保它们之间的转换是合理的 .
如果新的数据类型无法兼容原有的数据 , 可能会导致数据丢失 , 格式错误或查询错误 .
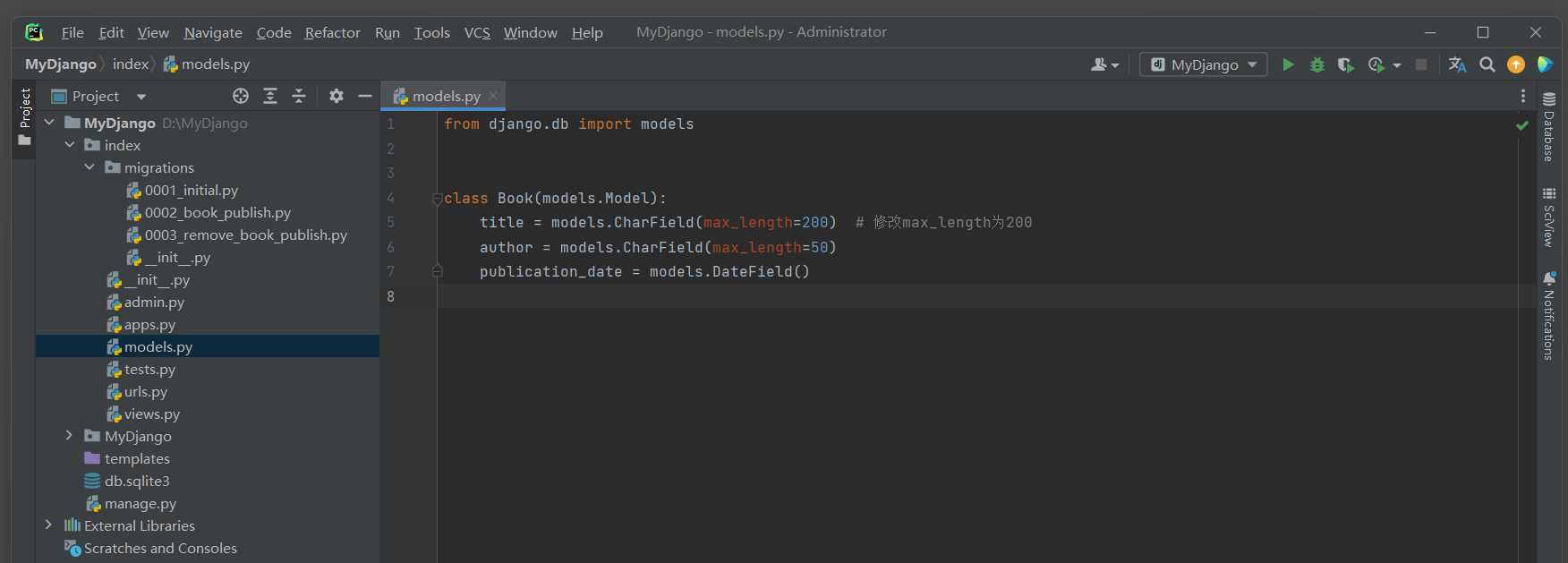
要修改一个字段 , 只需修改模型中字段的定义 .
例如 , 要修改Book模型的title字段的最大长度 , 可以这样做 :
from django. db import modelsclass Book ( models. Model) : title = models. CharField( max_length= 200 ) author = models. CharField( max_length= 50 ) publication_date = models. DateField( )
修改模型后 , 需要生成一个新的迁移文件来记录这个变更 .
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0004_alter_book_title. py- Alter field title on book
PS D: \MyDjango> 生成迁移文件后 , 需要将这些变更应用到数据库中 .
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying index. 0004_alter_book_title. . . OK
PS D: \MyDjango>
Applying index. 0004_alter_book_title. . .
ALTER TABLE `index_book` MODIFY `title` varchar( 200 ) NOT NULL; ( params [ ] )
( 0.016 ) ALTER TABLE `index_book` MODIFY `title` varchar( 200 ) NOT NULL; args= [ ]
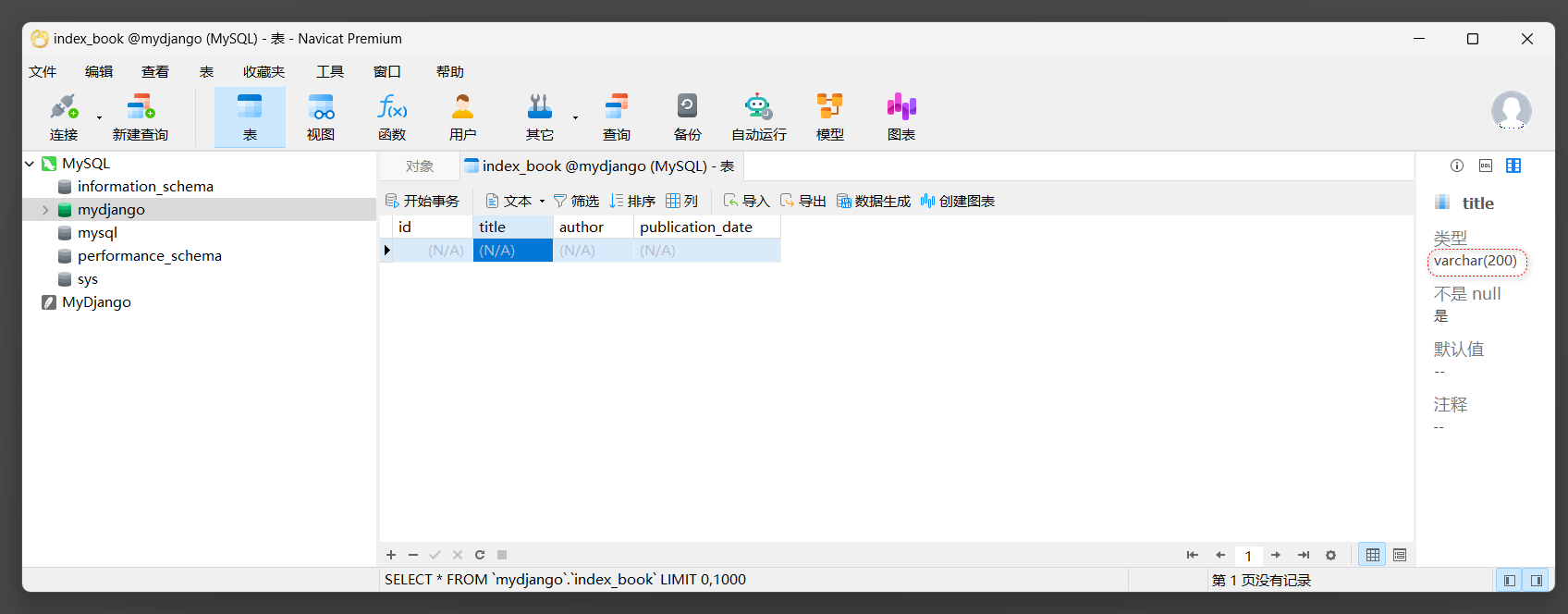
使用Navicat工具查看表格的字段信息 .
如果在Django模型中改小一个字段的最大长度 ( 比如将CharField的max_length减小 ) , 这会引发一些潜在的问题 ,
具体取决于字段当前的使用情况和数据库中的实际数据 : 例如 , 数据库中已经存在超出新max_length限制的数据 , 那么当尝试应用这个迁移时 , Django会尝试更新数据库模式以反映新的max_length .
但是 , 由于数据库中的数据超出了这个新限制 , 这通常会导致错误或数据截断 . 错误 : 在某些数据库配置或Django版本中 , 尝试应用这样的迁移可能会导致操作失败 , 并显示错误消息 , 指出无法将超出新长度限制的数据插入到该字段中 截断 : 在某些情况下 , 数据库可能会尝试将数据截断以适应新的长度限制 , 但这通常不是你所期望的行为 , 因为它会丢失数据 .
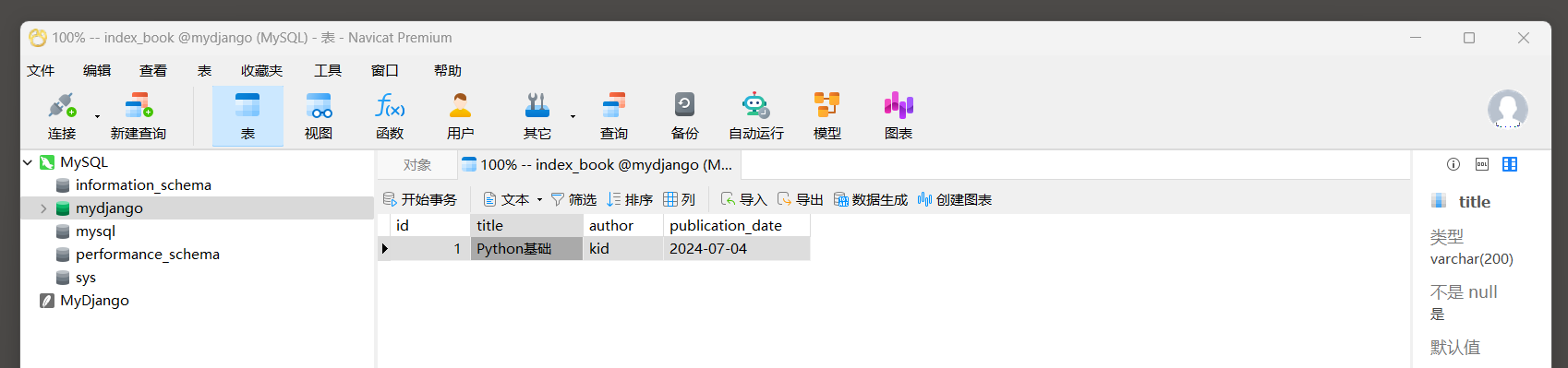
使用Navicat工具往表格中插入一条数据 , 如下所示 :
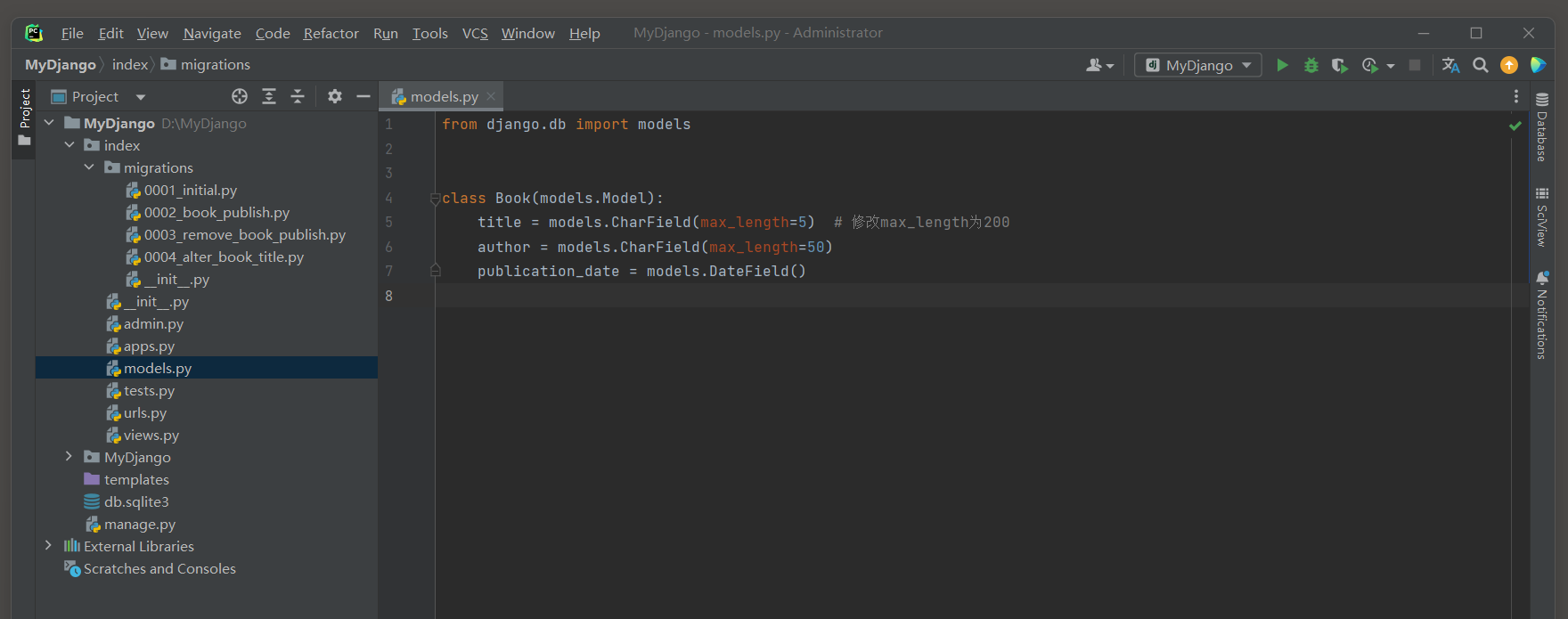
现在修改修改Book模型的title字段的最大长度为 5.
from django. db import modelsclass Book ( models. Model) : title = models. CharField( max_length= 5 ) author = models. CharField( max_length= 50 ) publication_date = models. DateField( )
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0005_alter_book_title. py- Alter field title on bookPS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying index. 0006_alter_book_title. . . Traceback ( most recent call last) : . . . django. db. utils. DataError: ( 1406 , "Data too long for column 'title' at row 1" )
执行迁移同步是提示 : django . db . utils . DataError : ( 1406 , "Data too long for column 'title' at row 1" ) .
注意 , 这里生成了 0005 _alter_book_title . py文件 , 但是无法执行同步 , 那么避免后续出现不同步的问题必须删除这个文件 !
修改数据库表中的字段名时 , 实际上是修改Django模型中的字段名 . 以下是修改字段名的步骤 :
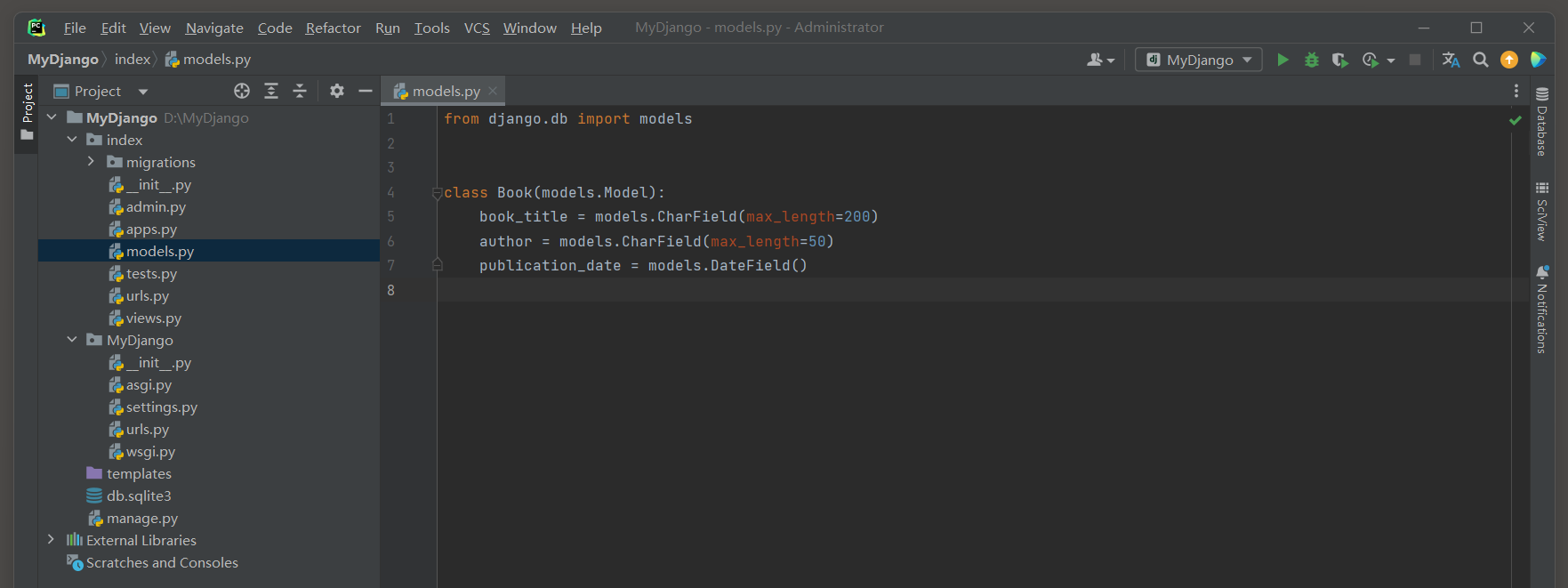
* 1. 首先 , 需要在Django的models . py文件中找到对应的模型 , 并修改你想要修改的字段名 . 这通常意味着你需要重命名该字段的变量名 . 例如 , 想要将Book模型的title字段名改为book_title , 需要修改模型定义如下 :
from django. db import modelsclass Book ( models. Model) : book_title = models. CharField( max_length= 200 ) author = models. CharField( max_length= 50 ) publication_date = models. DateField( )
* 2. 在修改了模型之后 , 需要为这一变更创建数据库迁移文件 .
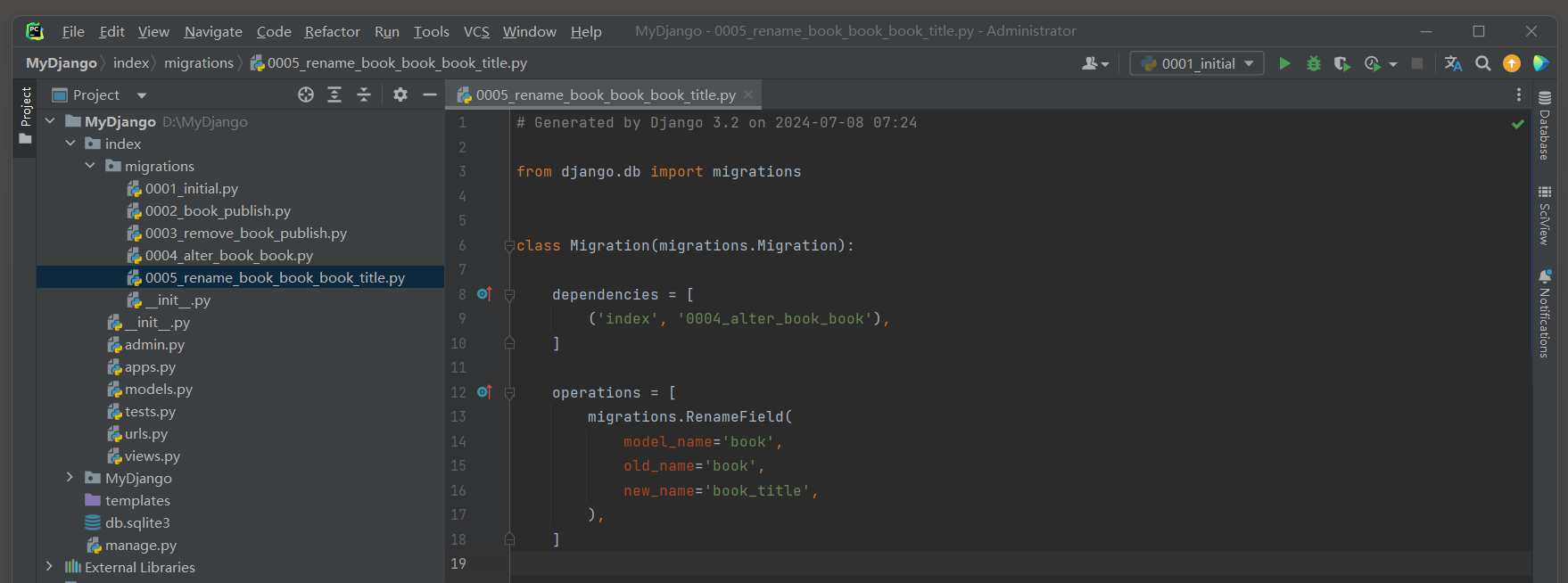
PS D: \MyDjango> python manage. py makemigrations
Did you rename book. book to book. book_title ( a CharField) ? [ y/ N] y
Migrations for 'index' : index\migrations\0005_rename_book_book_book_title. py- Rename field book on book to book_title
PS D: \MyDjango>
当看到提示 : Did you rename book . book to book . book_title ( a CharField ) ? [ y/N ] 时 ,
这意味着Django的迁移系统检测到了book模型中可能存在的字段重命名操作 .
这个提示是基于你当前模型的定义与之前迁移记录中模型定义的差异自动生成的 . 如果确实修改了字段的名称 ( 假设从book改为了book_title ) 应该回答y ( 是的 ) .
这将告诉Django , 它应该生成一个迁移文件来反映这个字段名的更改 ,
并假设新字段是一个CharField ( 如果没有指定其他类型 , 并且原始字段也是CharField的话 ) . 回答y后 , Django会生成一个迁移文件 , 通常位于你的应用目录下的migrations文件夹中 .
这个文件将包含SQL语句 , 用于在数据库中更新表结构 , 以匹配你的新模型定义 . 回答N ( 否 ) , Django将不会为这个假设的字段重命名操作生成迁移文件 .
* 3. 最后 , 需要将这些迁移应用到数据库中 .
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying index. 0005_rename_book_book_book_title. . . OK
Applying index. 0005_rename_title_book_book_title. . .
ALTER TABLE `index_book` RENAME COLUMN `title` TO `book_title`; ( params ( ) )
( 0.016 ) ALTER TABLE `index_book` RENAME COLUMN `title` TO `book_title`; args= ( )
. . .
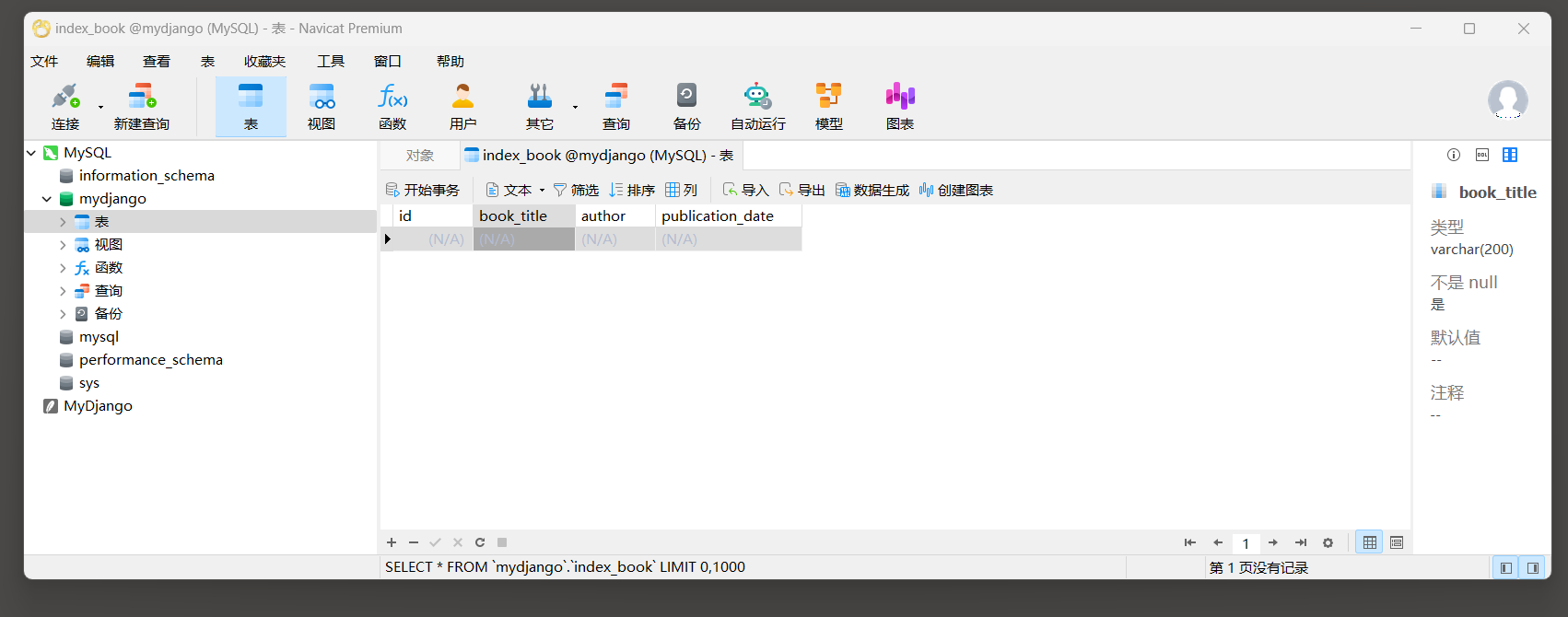
使用Navicat工具查看字典信息 , 如下所示 :
可以通过Meta类中的db_table属性来指定模型对应的数据库表名 , 然后进行数据迁移即可 .
from django. db import modelsclass Book ( models. Model) : book_title = models. CharField( max_length= 200 ) author = models. CharField( max_length= 50 ) publication_date = models. DateField( ) class Meta : db_table = 'book_table'
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0006_alter_book_table. py- Rename table for book to book_tablePS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: Applying index. 0006_alter_book_table. . . OK
Applying index. 0006_alter_book_table. . .
RENAME TABLE `index_book` TO `book_table`; ( params ( ) )
( 0.000 ) RENAME TABLE `index_book` TO `book_table`; args= ( )
. . .
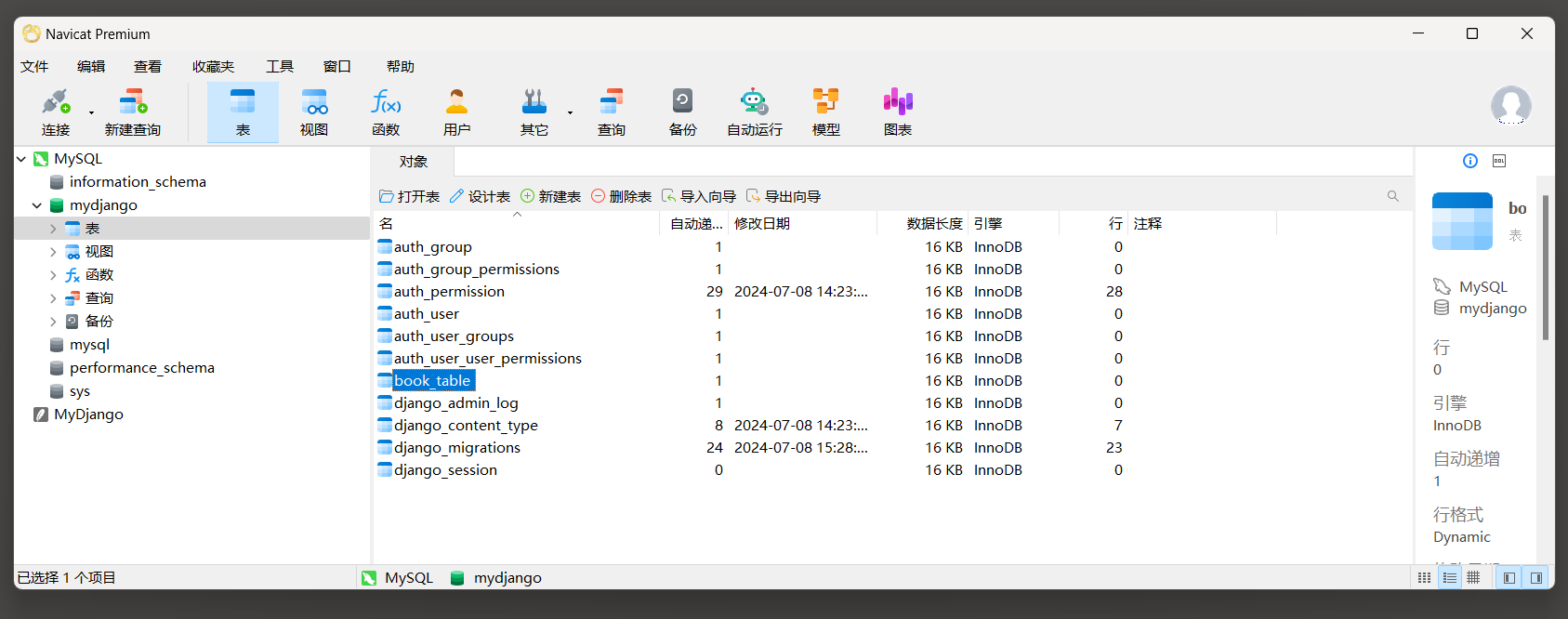
使用Navicat工具查看表名 , 如下所示 :