#AI夏令营 #Datawhale #夏令营
赛题
一句话介绍赛题任务可以这样理解赛题:
【训练时序预测模型助力电力需求预测】
电力需求的准确预测对于电网的稳定运行、能源的有效管理以及可再生能源的整合至关重要。
赛题任务
给定多个房屋对应电力消耗历史 N 天的相关序列数据等信息,预测房屋对应电力的消耗。
赛题数据简介
赛题数据由训练集和测试集组成,为了保证比赛的公平性,将每日日期进行脱敏,用 1-N 进行标识。
即 1 为数据集最近一天,其中 1-10 为测试集数据。
数据集由字段 id(房屋 id)、 dt(日标识)、type(房屋类型)、target(实际电力消耗)组成。
下面进入 baseline 代码
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np# 2. 读取训练集和测试集
# 使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train = pd.read_csv('./data/data283931/train.csv')
# 使用 read_csv() 函数从文件中读取测试集数据,文件名为 'train.csv'
test = pd.read_csv('./data/data283931/test.csv')# 3. 计算训练数据最近11-20单位时间内对应id的目标均值
target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index()# 4. 将target_mean作为测试集结果进行合并
test = test.merge(target_mean, on=['id'], how='left')# 5. 保存结果文件到本地
test[['id','dt','target']].to_csv('submit.csv', index=None)Step1:报名赛事!(点击即可跳转)
赛事链接:2024 iFLYTEK AI开发者大赛-讯飞开放平台2024 iFLYTEK AI开发者大赛-讯飞开放平台
https://challenge.xfyun.cn/h5/detail?type=electricity-demand&ch=dw24_uGS8Gs
Step2:5 分钟体验一站式 baseline!(点击即可跳转)
项目链接:从零入门机器学习竞赛-Baseline - 飞桨AI Studio星河社区- 飞桨AI Studio星河社区![]() https://aistudio.baidu.com/projectdetail/8151133
https://aistudio.baidu.com/projectdetail/8151133
跑通baseline
根据task1跑通baseline
注册账号
直接注册或登录百度账号,etc
fork 项目
从零入门机器学习竞赛-Baseline - 飞桨AI Studio星河社区- 飞桨AI Studio星河社区![]() https://aistudio.baidu.com/projectdetail/8151133
https://aistudio.baidu.com/projectdetail/8151133
启动项目
 选择运行环境,并点击确定,没有特殊要求就默认的基础版就可以了
选择运行环境,并点击确定,没有特殊要求就默认的基础版就可以了
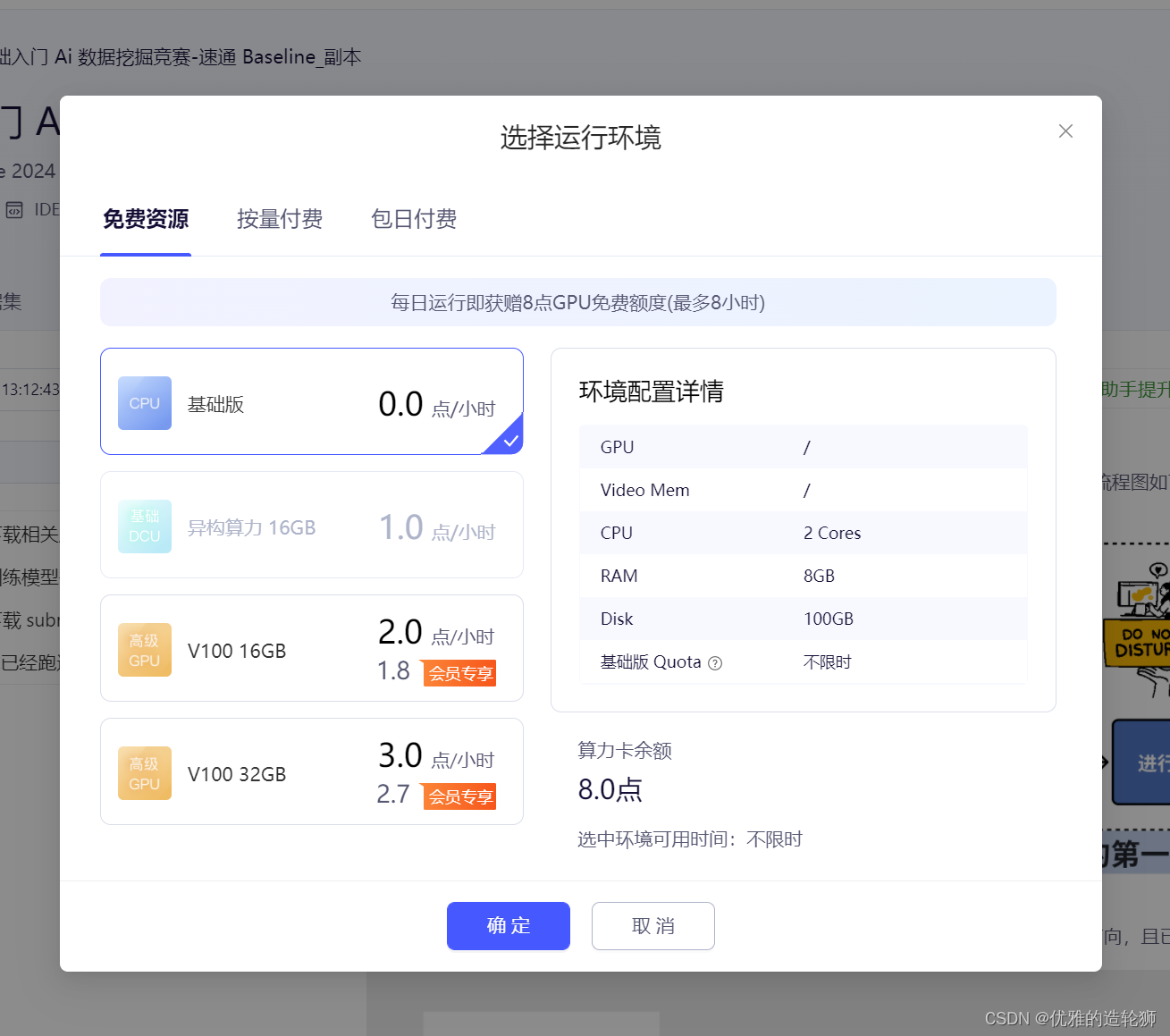
等待片刻,等待在线项目启动
 运行项目代码
运行项目代码

点击 运行全部Cell

程序运行完生成文件 submit.csv

这个文件就最终提交的文件。
提交并获取分数
| 1 | 返回分数 | 373.89846 | submit.csv | baseline | 1gszwJaV | 2024-07-11 16:57:27 |
知识点:
常见的时间序列场景有:
金融领域:股票价格预测、利率变动、汇率预测等。
气象领域:温度、降水量、风速等气候指标的预测。
销售预测:产品或服务的未来销售额预测。
库存管理:预测库存需求,优化库存水平。
能源领域:电力需求预测、石油价格预测等。
医疗领域:疾病爆发趋势预测、医疗资源需求预测。
时间序列问题的数据往往有如下特点:
时间依赖性:数据点之间存在时间上的连续性和依赖性。
非平稳性:数据的统计特性(如均值、方差)随时间变化。
季节性:数据表现出周期性的模式,如年度、月度或周度。
趋势:数据随时间推移呈现长期上升或下降的趋势。
周期性:数据可能存在非固定周期的波动。
随机波动:数据可能受到随机事件的影响,表现出不确定性。
时间序列分析在很多领域中具有重要的应用价值。通过对时间序列数据的分析和建模,可以得到对未来趋势的预测和预测误差的估计,为决策提供依据。
时间序列预测问题可以通过多种建模方法来解决,包括传统的时间序列模型、机器学习模型和深度学习模型。
传统时间序列模型
用于分析和预测时间序列数据的统计模型。
它假设数据点之间存在一定的时间关系,即后一个数据点的值可以根据前一个数据点的值和其他相关因素预测得出。
常见的时间序列模型包括
- AR模型(自回归模型)
- MA模型(滑动平均模型)
- ARMA模型(自回归滑动平均模型)
- ARIMA模型(差分自回归滑动平均模型)
- SARIMA模型(季节性差分自回归滑动平均模型)等。
这些模型基于不同的假设和参数设置,可以根据数据的特点选择合适的模型进行建模和预测。
时间序列模型可以用于不同领域的数据分析和预测,如经济学中的金融时间序列分析、气象学中的气象预测、生态学中的生态系统变化预测等。它们可以帮助我们理解数据的时间规律,发现趋势和周期性变化,以及预测未来的走势。
机器学习模型
在时间序列预测中,机器学习模型可以通过将时间序列数据转化为特征和目标变量的组合来进行建模和预测。
以下是一些常用的机器学习时间序列模型:
- 自回归模型(AR):自回归模型基于时间序列数据的历史值来预测未来值。AR模型假设未来值与过去的若干个值有线性相关性。
- 移动平均模型(MA):移动平均模型基于时间序列数据的过去误差来预测未来值。MA模型假设未来值与过去的若干个误差有相关性。
- 自回归移动平均模型(ARMA):ARMA模型是AR模型和MA模型的组合。它结合了过去的时间序列值和误差来进行预测。
- 差分自回归移动平均模型(ARIMA):ARIMA模型在ARMA模型的基础上增加了对时间序列数据进行差分的步骤,用于处理非平稳数据。
- 季节性ARIMA模型(SARIMA):SARIMA模型是ARIMA模型在考虑季节性因素的基础上进行建模的一种扩展模型。
- 支持向量机(SVM):支持向量机是一种常用的机器学习模型,在时间序列预测中可以用于线性回归、非线性回归和分类问题。
- 随机森林(Random Forest):随机森林是一种集成学习模型,通过多个决策树的组合来进行预测。在时间序列预测中,可以利用随机森林进行回归和分类问题的预测
深度学习模型
深度学习模型在时间序列预测问题上表现出色,尤其是在处理大规模数据和复杂模式时。
以下是一些常用的深度学习时间序列模型:
- 循环神经网络(RNN):RNN是一种能够处理序列数据的神经网络。它具有记忆能力,可以在处理每个时间步时将之前的信息传递给下一个时间步,从而捕捉到时间序列的依赖关系。
- 长短期记忆网络(LSTM):LSTM是一种RNN的变体,通过引入“门控”机制来解决传统RNN中的梯度消失和梯度爆炸问题。LSTM对于长期依赖关系的建模能力更强,适用于处理长时间序列数据。
- 门控循环单元(GRU):GRU也是一种RNN的变体,类似于LSTM,它通过引入“门控”机制来记忆和更新信息。GRU相对于LSTM具有更简单的结构,参数量更小,计算效率更高。
- 卷积神经网络(CNN):CNN在处理时间序列数据时常用于提取局部特征。通过卷积和池化操作,CNN可以捕捉时间序列中的局部模式,并提取有用的特征,用于预测未来值或分类问题。
- 注意力机制(Attention):注意力机制在深度学习中很有用,尤其是在处理长时间序列数据时。它可以将模型的注意力集中在序列中最重要的部分,提高预测的准确性。
这些深度学习时间序列模型具有强大的建模能力,能够处理复杂的时间序列数据,但同时也需要大量的训练数据和计算资源。
各种模型之间的对比
| 模型类型 | 特点 | 适用场景 |
|---|---|---|
| 传统时间序列模型 | 基于统计分析的方法,对时间序列数据的基本特性进行建模,如自相关性、季节性等 | 非常适合处理具有明显的趋势和季节性的数据。 对于相对简单的时间序列数据,建模和预测效果较好。 例如AR、MA、ARIMA、SARIMA模型 |
| 机器学习模型 | 基于机器学习算法,通过对时间序列数据的样本特征进行训练建模,学习数据的模式和规律 | 适用于数据较为复杂、特征较多的时间序列问题。 需要手动提取和选择合适的特征。 常用的机器学习模型包括线性回归、决策树、随机森林、支持向量机等 |
| 深度学习模型 | 基于神经网络的模型,通过多层次的神经网络结构进行特征提取和模式学习 | 适用于大规模数据、复杂特征的时间序列预测问题。 自动学习数据中的特征和模式,无需手动提取。 常见的深度学习模型包括循环神经网络(RNN)、长短时记忆网络(LSTM)、卷积神经网络(CNN)等 |
- 如果数据具有明显的趋势和季节性,且相对简单,可以使用传统时间序列模型进行建模和预测。
- 如果数据较为复杂,特征较多,可以考虑使用机器学习模型进行建模。
- 对于大规模数据、复杂特征和自动学习特征的需求,可以考虑使用深度学习模型。