目录
- 项目介绍:
- 概要设计:
- 技术调研
- 详细设计:
- 目录监控模块
- 样例编写(c++17的filesystem中的文件遍历功能)
- 数据管理模块
- 样例编写(unordered_map格式存储)
- 文件压缩与解压缩模块
- bundle数据压缩库使用测试
- 网络通信模块
- 样例编写(基于httplib库快速搭建)
- 客户端:
- 头文件编写(目录遍历,文件读写,数据管理)
- 主函数
- 服务端
- 头文件编写(目录遍历,文件读写,数据管理,文件上传与下载,断点续传,热度文件判断,压缩与解压缩)
- 主函数
项目介绍:
项目简介:
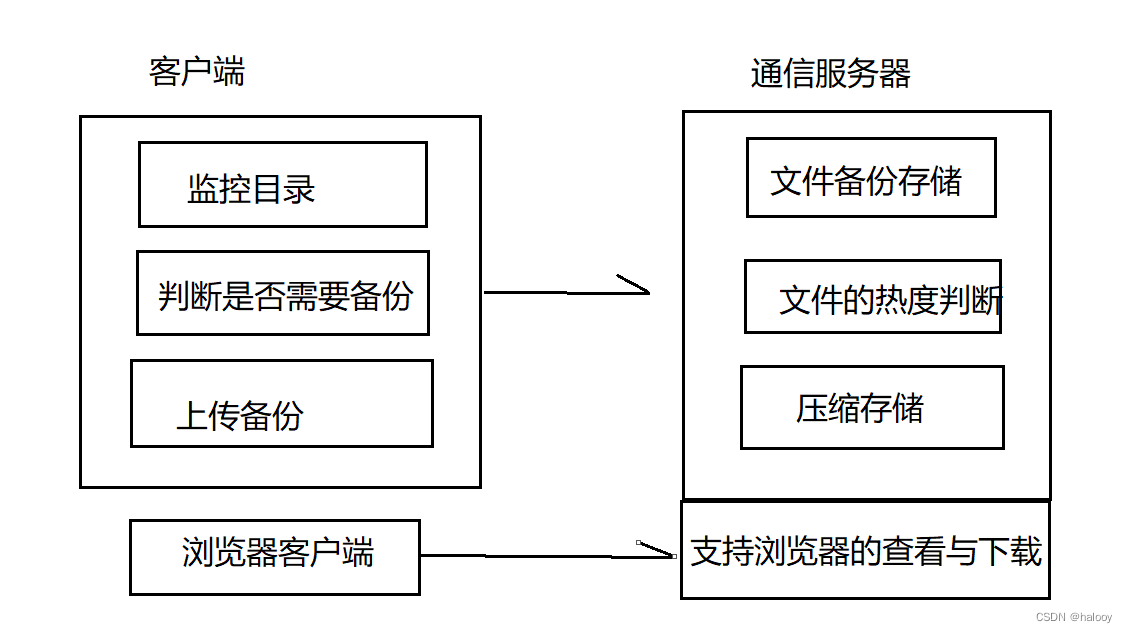
实现云备份服务器和客户端程序组成一套系统
客户端程序运行在客户端主机,对指定目录下需要备份的文件进行备份上传;
服务器对上传的文件进行备份存储,并对非热点文件进行压缩存储节省磁盘空间,并且支持浏览器访问以及断点续传下载;
项目特点:
http服务器,线程池,读写锁,lz压缩
项目实现:
- 客户端:
文件监控模块:采用c++14中的文件系统接口对目录进行遍历获取文件信息。
数据管理模块:记录备份的文件信息,并且通过信息判断文件是否需要备份。
文件上传模块:搭建http客户端,使用post请求方式实现文件上传备份。 - 服务端:
文件管理模块:对指定目录下的文件遍历判断是否为非热点文件,并进行非热点文件压缩存储。
数据管理模块:记录管理备份文件信息,实现判断文件是否已经压缩的功能。
HTTP服务器模块:与客户端进行交互,提供文件上传,查看,下载(断点续传)功能的处理。
概要设计:
一、客户端
- 编程环境:Windows 下的客户端程序:Win10-Visual Studio2017;
- 功能需求:监控目录,自动对指定目录下需要备份的文件进行上传备份;
1.目录监控: 用 C++17filesystem 遍历目录,判断文件是否需要备份,判断方式、条件如下;
- 获取历史备份信息,获取当前监控目录下文件信息(名称、时间、大小);
- 判断是否需要备份:当前文件信息与同名历史文件信息不符则需要备份,文件信息未在历史信息中出现需要备份;
2.网络通信: 遍历需要上传备份的文件,获取其文件名称,使用 httplib 库中提供的接口进行文件数据上传;
3.**数据管理:**从第一步中获取到需要备份的文件,将其信息保存到下来(代码内:map,代码外:文件),保存格式为【文件名称 : 创建时间 + 文件大小】的键值对,被保存的文件也相当于历史备份信息,可作为用来判断文件是否需要备份的比对;
二、服务端
- 编程环境:Linux服务器:Ubuntu18.04.1-vim/g++/makefile ;
- 功能需求:对客户端上传的文件进行保存,并对文件进行检查,如果是非热点文件,那么就进行压缩存储,删除源文件,支持用户浏览器对备份文件的访问与下载;
1.网络通信: 使用 httplib 库中提供的接口进行接收客户端上传的文件数据,并以文件形式保存;
2.浏览下载: 用户通过浏览器可以查看当前已备份文件,可以对备份文件进行下载,并且下载还支持断点续传;
3.文件压缩: 备份文件在一定时间内没有被访问过,那么该文件就是非热点文件,对其进行压缩存储,判断方法就是用当前时间减去文件最后一次访问时间;
3.数据管理: 压缩存储的文件,会将其对应的原文件删除,所以我们需要保留原文件与压缩文件之间的对应关系(代码内:map,代码外:文件),保存格式为【原文件 : 压缩文件】的键值对;
技术调研
目录监控
- 1.需要获取目录下所有的文件信息,使用c++17的
filesystem中的文件遍历功能 - 2.根据文件信息判断是否需要备份 ①.是否新增;②.是否修改
程序第一次启动,所有文件都需要进行备份,并且记录信息(文件名称–文件唯一标识(md5–大小+时间))
之后对获取到的文件信息进行判断:是否在已备份文件信息中 (1).不存在则为新增 (2).存在则通过唯一标识符进行判断是否已修改 - 3.文件备份
遍历需要备份的文件信息(获取文件路径名)
搭建http客户端,上传文件数据,备份到云端
数据管理
- 代码操作时使用
unordered_map进行数据管理; - 持久化存储使用
文件来进行数据管理。
压缩与解压缩
- 使用 bundle 实现文件压缩与解压缩;
网络通信
- 客户端
- 创建客户端对象:
httplib::Client cli("服务端ip", 服务端port); - 实现文件上传与接收:组织httplib::MultipartFormData结构的信息,需要填充的信息有以下四种:
httplib::MultipartFormData data;
data.name:位域信息,根据不同类型的内容设置不同的名字(双方协商),服务端通过这个字段可以判断是否有我需要的信息上传了,而且可以根据这个字段的信息来确定该文件的处理方式;
data.filename:上传文件的真实名称;
data.content:文件内容;
data.content_type:文件格式;
- 创建
httplib::MultipartFormDataItems数组,该数组存放的元素类型为httplib::MultipartFormData,当我们组织好文件信息后,将其添加入该数组中; - 使用客户端对象进行上传,上传格式为
cli.Post("请求信息", 数组); - 客户端通过浏览器进行访问、下载,浏览器请求格式为:
ip:port/请求资源;
- 服务端
- 创建服务端对象:
httplib::Server ser; - 为客户端不同的请求信息,创建不同的
void(*fun)(const httplib::Request&, httplib::Response&);回调函数; - 对于文件上传请求,回调函数如下:
static void Upload(const httplib::Request& req, httplib::Response& res){ //判断上传文件是否存在 if(!req.has_file("上传文件的位域信息,也就是name字段")){//... } //存在则获取文件 const httplib::MultipartFormData& file = req.get_file_value("上传文件的位域信息,也就是name字段"); //然后获取文件内容,写入文件,记录备份信息... //...return;
}
- 对于访问、下载等请求,则是组织相应格式的响应信息即可,需要注意的是,用户访问时展示的是所有备份文件的名字,但是可能有一部分文件已经被压缩存储了,所以下载时需要进行判断,对压缩文件进行解压缩才能下载;
- 开始监听,格式为:
srv.listen("0.0.0.0", 监听port),将监听 IP 设置为 “0.0.0.0” 的目的是,可以监听该主机上任意一个网卡设备的请求,这样做更加便捷可靠;
断点续传
- 假设现在用户通过浏览器要下载 xuexi.mp4 文件;
- 服务端收到请求后,检查是否为从头开始下载该文件,如果是从头开始下载,则响应信息设置为以下内容:
//回复响应信息的对象为:res
res.set_header("Accept-Ranges", "bytes");//告诉客户端,本服务器支持断点续传
res.set_header("ETag", newflag);//将备份文件的唯一标识返回给客户端,用于后续比较
res.set_header("Content-Type", "application/octet-stream");//下载则设置为二进制传输
res.body = str;//设置响应正文,也就是文件内容
res.status = 200;//成功响应返回200
- 客户端在下载的过程中出现了一些意外情况,导致下载中断,此时选择继续下载,因为服务端支持断点续传功能,所以进行断点续传;
- 客户端会通过会通过ranges字段向服务端请求需要断点续传的区间是哪些,ranges字段的每一个元素都是pair类型,first-代表了起始位置,second代表了结束位置;
- 服务端在收到请求后,判断此次下载为断点续传,则会进行以下操作:
//请求对象为req,响应对象为res
1. 判断该文件是否为断点续传,如果是断点续传,则获取之前传给客户端的文件唯一标识
std::string oldflag;
if(req.has_header("If-Range")){ oldflag = req.get_header_value("If-Range");
}
2. 然后拿当前文件唯一标识和旧的文件唯一表示进行比较,如果不相等,则说明备份文件被修改过了,那么就不能断点续传了,因为内容会接不上,需要全部下载,如果相等,则断点续传
if(req.has_header("If-Range") && newflag == oldflag){ //获取断点续传区间,因为只有一个区间,所以不需要循环获取begin = req.ranges[0].first; end = req.ranges[0].second; //如果end==-1,则说明是从begin位置到文件结束 if(end == -1){ //修改end为文件末尾,文件大小减一 end = filesize - 1; }
3. 设置头部3.1 ("Content-Range", "bytes 起始-结束/文件大小")std::stringstream ss; ss << "bytes " << begin << '-' << end << '/' << filesize; res.set_header("Content-Range", ss.str()); 3.2 将备份文件的唯一标识返回给客户端,用于后续比较res.set_header("ETag", newflag);3.3 下载则设置为二进制传输res.set_header("Content-Type", "application/octet-stream");res.body = str;//设置响应正文,也就是文件内容 res.status = 206;//断点续传成功响应码为206
}
详细设计:
目录监控模块
样例编写(c++17的filesystem中的文件遍历功能)
目录遍历的技术选型,以及文件信息的获取(大小,时间属性)
编写目录监控函数代码示例:
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <string>
#include <cstdlib>
#ifdef _WIN32
#include <windows.h>
#include <filesystem>
#else
#include <experimental/filesystem>
#include <unistd.h>
#endifvoid ScanDir(const std::string& path)
{if (!std::experimental::filesystem::exists(path)){ std::experimental::filesystem::create_directories(path);} for (auto& file : std::experimental::filesystem::directory_iterator(path)){ auto& f = file.path();if (std::experimental::filesystem::is_directory(f)){ std::cout << f.filename() << "/\n";continue;} else{ std::cout << f.filename();} //获取文件大小 uint64_t size = std::experimental::filesystem::file_size(f);std::cout << "\t" << size;//获取时间auto time_type = std::experimental::filesystem::last_write_time(f);std::time_t t = decltype(time_type)::clock::to_time_t(time_type);std::cout << "\t" << std::asctime(std::localtime(&t)) << std::endl;}return;
}
int main()
{//需要监控的目录const char* path = "./testdir/";while (1){ScanDir(path);
#ifdef _WIN32Sleep(1000);
#elsesleep(1);
#endif}return 0;
}
数据管理模块
在服务端需要对文件信息进行管理,这里采用的是unordered_map进行存储,主要函数有序列化和反序列化。
序列化:对以键值对形式的数据文件信息进行存储,进行写入操作。
反序列化:对之前写入的文件内容读取出来,进行读取操作。
样例编写(unordered_map格式存储)
/**将数据序列化、反序列化样例编写*/
#include <iostream>
#include <string>
#include <fstream>
#include <vector>
#include <unordered_map>
#include <sstream>
#include <experimental/filesystem>
using namespace std;//分割字符,str:被分割字符串,sp:分割符,arry:分割后存入数组
int Split(const string &str, const string &sp, vector<string> *arry)
{int count = 0;size_t pos, idx = 0;while(1){ pos = str.find(sp, idx);if(pos == string::npos){ break;} string tmp = str.substr(idx, pos-idx);arry->push_back(tmp);idx = pos + sp.size();count++;} if(idx != str.size()){ arry->push_back(str.substr(idx));count++;}return count;
}
void unseri()
{//反序列化,将文件内容读取出来const char *name = "test.dat";ifstream infile;std::string body;infile.open(name, std::ios::binary);if(infile.is_open() == false){std::cout << "open file failed!\n";return ;}uint64_t size = std::experimental::filesystem::file_size(name);body.resize(size);infile.read(&body[0], size);infile.close();//std::cout << body << std::endl;vector<string> arry;Split(body, "\n", &arry);for(auto &s: arry){//二次分割,将=两端进行分割输出vector<string> kv;Split(s, "=", &kv);std::cout << "[" << kv[0] << "]" << "=" << "[" << kv[1] << "]\n";}
}
void seri()
{unordered_map<string, string> _map = {{"main.cpp", "9913687567"},{"child.cpp", "9913676453"},{"client.cpp", "9913345244"},{"server.cpp", "9913687565"}};stringstream ss;ss.clear();for(auto &info: _map){ss << info.first << "=" << info.second << "\n";}ofstream outfile;outfile.open("test.dat", std::ios::binary);outfile << ss.str();outfile.close();
}
int main()
{//seri();unseri();return 0;
}
文件压缩与解压缩模块
bundle数据压缩库使用测试
bundle是一个GitHub开源的插件压缩库(https://github.com/r-lyeh-archived/bundle),提供文件的压缩和解压方法。可以直接嵌入到代码中,直接使用,支持23种压缩算法和2种存档格式,使用时只需加入bundle.h和bundle.cpp两个文件即可。
编译时,指明编译bundle.cpp,同时因为bundle.cpp中使用了多线程,还需要链接pthread库
g++ -o test test.cc bundle.cpp -std=c++11 -lptrhead
以下进行编写示例:
- 压缩函数编写示例
通过对bundle.cpp文件进行压缩,将压缩后的文件命名为bundle.cpp.lz
void compress()
{//将bendle.cpp文件内容进行读取,读取到body里面const char *name = "./bundle.cpp";uint64_t size = std::experimental::filesystem::file_size(name);std::string body;body.resize(size);std::ifstream infile;infile.open(name, std::ios::binary);infile.read(&body[0], size);infile.close();//读取结束后,对bundle.cpp的内容进行压缩,返回压缩后的内容std::string str = bundle::pack(bundle::LZIP, body);//压缩后,将压缩的内容写入到bundle.cpp.lz里面std::ofstream outfile;outfile.open("./bundle.cpp.lz", std::ios::binary);outfile.write(&str[0], str.size());outfile.close();return ;
}
将压缩bundle.cpp.lz进行解压,解压后得到的文件为bundle.cc
- 解压缩函数编写示例
#include <iostream>
#include <fstream>
#include <experimental/filesystem>
#include "bundle.h"void uncompress()
{const char *name = "./bundle.cpp.lz";//定义解压缩后的文件名const char *name1 = "./bundle.cc";//将压缩文件bundle.cpp.lz的内容读取出来,读取到bodyuint64_t size = std::experimental::filesystem::file_size(name);std::string body;body.resize(size);std::ifstream infile;infile.open(name, std::ios::binary);infile.read(&body[0], size);infile.close();//压缩内容读取出来后将其进行解压缩std::string str = bundle::unpack(body);//将解压缩后的内容写入bundle.cc文件内std::ofstream outfile;outfile.open(name1, std::ios::binary);outfile.write(&str[0], str.size());outfile.close();return ;
}
编写完成之后,将两个函数分别在main.cpp中调用,执行以下命令,因为要用到文件系统所以加上-lstdc++fs
g++ -std=c++17 main.cpp bundle.cpp -o main -lpthread -lstdc++fs

编译完成后,通过md5查看原文件和解压缩后的文件大小是否一致。
网络通信模块
样例编写(基于httplib库快速搭建)
- 客户端
对需要上传的文件信息组织成httplib::MultipartFormData格式后,加入到httplib::MultipartFormDataItems数组,再使用客户端对象进行上传。
#include <iostream>
#include <fstream>
#include "httplib.h"using namespace httplib;void ReadFile(const std::string &path, std::string *body)
{std::ifstream infile;infile.open(path);//跳转到文件末尾infile.seekg(0,std::ios::end);//获取偏移量-文件长度long len = infile.tellg();//跳转到文件起始infile.seekg(0, std::ios::beg);//申请空间body->resize(len);//读取文件数据infile.read(&(*body)[0], len);//关闭文件infile.close();
}
int main()
{const char *name = "./test.mp3";//创建客户端对象Client cli("127.0.0.1",9000);//组织结构信息MultipartFormDataItems items;MultipartFormData file1;file1.name = "file1";file1.filename = "out_test.mp3";file1.content_type = "application/octet-stream";ReadFile(name, &file1.content);items.push_back(file1);//使用客户端进行上传cli.Post("/Multipart", items);return 0;
}- 服务端
针对客户端不同的请求,创建不同的回调函数,如针对/Multipart的资源请求,创建对应的回调函数void Upload(const Request &req, Response &rsp)。
该回调函数实现进行判断文件是否存在,存在则将文件写入进行保存。
#include<iostream>
#include<string>
#include<fstream>
#include"httplib.h"using namespace httplib;
void WriteFile(const std::string &path, const std::string &body)
{std::ofstream outfile;outfile.open(path, std::ios::binary);outfile.write(&body[0], body.size());outfile.close();
}
void Upload(const Request &req, Response &rsp)
{auto ret = req.has_file("file1");if(ret == false){ std::cout << "have no file\n";return;} const auto& file = req.get_file_value("file1");WriteFile(file.filename, file.content);// file.filename;// file.content_type;// file.content;
}
int main()
{Server srv;srv.Post("/multipart", Upload);srv.listen("127.0.0.1", 9000);return 0;
}
客户端:
头文件编写(目录遍历,文件读写,数据管理)
#pragma once
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <vector>
#include <unordered_map>
#ifdef _WIN32
#include <filesystem>
#include <windows.h>
#else
#include <experimental/filesystem>
#include <unistd.h>
#endifnamespace cloud_sys
{namespace fs=std::experimental::filesystem;class ScanDir{private:std::string _path;public:ScanDir(const std::string &path): _path(path){//目录不存在则创建if(!fs::exists(_path)){fs::create_directories(_path);}//判断路径名最后是否为/如果不是则加上if(_path.back() != '/'){_path += '/';}}//开始浏览,需要返回目录里面的所有文件名称,在arry数组内bool Scan(std::vector<std::string> *arry){for(auto &file: fs::directory_iterator(_path)){std::string name;name = file.path().filename().string();std::string pathname = _path + name;//如果是目录,则不进行添加if (fs::is_directory(pathname)){continue;}arry->push_back(_path + name);}return true;}};class Util{public://将文件信息读取出来,存到bodystatic bool FileRead(const std::string &file, std::string *body){body->clear();std::ifstream infile;//以二进制方式打开,避免读出和写入的大小不同,因为ifsteam以字符为单位,一个字符可能占多个字节infile.open(file, std::ios::binary);if(infile.is_open() == false){std::cout << "open file failed!\n";return false;}uint64_t size = fs::file_size(file);body->resize(size);infile.read(&(*body)[0], size);if(infile.good() == false){std::cout << "read file failed!\n";return false;}infile.close();return true;}//将body信息写入到文件内static bool FileWrite(const std::string &file, const std::string &body){std::ofstream outfile;outfile.open(file, std::ios::binary);if(outfile.is_open() == false){std::cout << "open file failed!\n";return false;}outfile.write(&body[0], body.size());if(outfile.good() == false){std::cout << "write file failed!\n";return false;}outfile.close();return true;}//将信息进行分割,传入三个参数,1被分割内容.2分割符.3分割后的内容static int Split(const std::string &str,const std::string &sp,std::vector<std::string> *arry){//定义文件个数int count = 0;//定义分隔符位置和偏移量size_t pos, idx = 0;while(1){//从idx起始位置开始找pos = str.find(sp, idx);if(pos == std::string::npos)break;std::string tmp;//字符串截取,从偏移量idx开始到pos的位置tmp = str.substr(idx, pos-idx);arry->push_back(tmp);//更新偏移量idxidx = pos + sp.size();count++;}//如果分隔符找到字符串末尾还没有,那么将偏移量到字符串末尾的数据全部插入arryif(idx < str.size()){arry->push_back(str.substr(idx));count++;}return count;}};class DataManager{private:std::string _path;std::unordered_map<std::string, std::string> _map;public:DataManager(const std::string &path): _path(path){}//把文件数据读取出来存入到_map中bool Read(){std::string body;std::vector<std::string> arry;//调用Util类中的文件读取函数,将文件信息读到bodyif(Util::FileRead(_path, &body) == false){std::cout << "read data set failed!\n";return false;}//将body内的文件信息进行拆分//先按行进行拆分,将每个文件信息保存arry数组Util::Split(body, "\n", &arry);//对arry数据进行循环遍历,针对每一行的文件信息进一步拆分for(auto &line: arry){//定义kv数据存储每行文件信息的k和v值std::vector<std::string> kv;Util::Split(line, "=", &kv);_map[kv[0]] = kv[1];}return true;}//把_map数据写入到文件中bool Write(){std::stringstream ss;for(auto &it: _map){ss << it.first << "=" << it.second << "\n";}if(Util::FileWrite(_path, ss.str()) == false){std::cout << "write data set failed!\n";return false;}return true;}bool Exists(const std::string &key){auto it = _map.find(key);if(it == _map.end()){return false;}return true;}bool AddOrMod(const std::string &key, const std::string &val){_map[key] = val;return true;}bool Del(const std::string &key, const std::string &val){auto it = _map.find(key);if(it == _map.end()){std::cout << key << "not exists!\n";return false;}_map.erase(it);return true;}bool Get(const std::string &key, std::string *val){auto it = _map.find(key);if(it == _map.end()){std::cout << key << "not exitsts!\n";return false;}*val = _map[key];return true;}};#define LISTEN_DIR "./scandir"
#define CONFIG_FILE "./data.conf"class Client{private:ScanDir _scan; //给与监控的目录路径DataManager _data; //给与配置文件的路径httplib::Client *_client;public:Client(const std::string &host, int port): _scan(LISTEN_DIR), _data(CONFIG_FILE){_client = new httplib::Client(host, port);}//获取文件唯一标识:大小+时间std::string GetIdentifier(std::string &path){uint64_t mtime, fsize;fsize = fs::file_size(path);auto time_type = fs::last_write_time(path);mtime = decltype(time_type)::clock::to_time_t(time_type);std::stringstream ss;ss << fsize << mtime;return ss.str();}//获取需要备份的文件信息,参数值返回:不仅需要备份文件名,还要备份文件的唯一标识(pair实现)bool Scan(std::vector<std::pair<std::string, std::string>> *arry){//获取所有的文件名std::vector<std::string> files;_scan.Scan(&files);//对所有文件名进行遍历,对每个文件进行判断是否存在、是否进行修改:不存在或不一致则进行备份for (auto &file : files){//针对每个文件进行获取对应的标识std::string identifier = GetIdentifier(file);//判断是否存在if (_data.Exists(file) == false){//不存在进行备份,去判断下一个arry->push_back(std::make_pair(file, identifier));continue;}//存在进行判断是否一致std::string old;_data.Get(file, &old);//如果一致,跳过判断下一个文件if (old == identifier){continue;}//不一致进行备份arry->push_back(std::make_pair(file, identifier));}return true;}//上传指定的文件bool Upload(const std::string &path){//组织上传数据格式httplib::MultipartFormData file;//name字段的作用是位域的区分,用来区分是什么文件类型file.name = "file";file.content_type = "application/octet-stream";fs::path p(path);file.filename = p.filename().string();Util::FileRead(path, &file.content);httplib::MultipartFormDataItems items;items.push_back(file);auto rsp = _client->Post("/multipart", items);if (rsp && rsp->status == 200){return true;}return false;}bool Start(){//1.读取历史备份信息(如果有)_data.Read();while (1){//2.通过Scan接口获取到需要备份的文件信息(文件路径名,唯一标识)--数组std::vector<std::pair<std::string, std::string>> arry;Scan(&arry);//遍历需要备份的文件信息,然后逐个进行备份for (auto &file : arry){std::cout << file.first << "需要进行文件备份\n";//通过Upload接口对需要备份的文件进行上传备份if (Upload(file.first) == false){//上传失败则不能修改备份信息,等下次遍历这个文件就会检测不一致重新进行上传continue;}//记录备份成功的文件的备份信息_data.AddOrMod(file.first, file.second);//修改持久化存储信息_data.Write();}Sleep(1000);}return true;}};
}
主函数
#include "cloud.hpp"int main()
{cloud_sys::Client client("192.168.159.129", 9000);client.Start();return 0;
}
Windows下查看md5值:certutil -hashfile cloud.cpp md5
服务端
头文件编写(目录遍历,文件读写,数据管理,文件上传与下载,断点续传,热度文件判断,压缩与解压缩)
#pragma once
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <vector>
#include <unordered_map>
#ifdef _WIN32
#include <filesystem>
#include <windows.h>
#else
#include <experimental/filesystem>
#include <unistd.h>
#include <sys/stat.h>
#include <pthread.h>
#include "httplib.h"
#include "bundle.h"
#endifnamespace cloud_sys
{namespace fs=std::experimental::filesystem;class ScanDir{ private:std::string _path;public:ScanDir(const std::string &path): _path(path){ //目录不存在则创建if(!fs::exists(_path)){ fs::create_directories(_path);} //判断路径名最后是否为/如果不是则加上if(_path.back() != '/'){ _path += '/';} } //开始浏览,需要返回目录里面的所有文件名称,在arry数组内bool Scan(std::vector<std::string> *arry){ for(auto &file: fs::directory_iterator(_path)){ std::string name;name = file.path().filename().string();arry->push_back(_path + name);} return true;} };class Util{public:static bool RangeRead(const std::string &file, std::string *body, int *start, int *end){body->clear();std::ifstream infile;infile.open(file, std::ios::binary);if(infile.is_open() == false){std::cout << "open file failed!\n";return false;}uint64_t fsize = fs::file_size(file);uint64_t readlen;if(*end == -1){*end = fsize - 1;}readlen = *end - *start + 1;//从起始位置偏移到start位置infile.seekg(*start, std::ios::beg);body->resize(readlen);infile.read(&(*body)[0], readlen);if(infile.good() == false){std::cout << "read file failed!\n";return false;}infile.close();return true;}//将文件信息读取出来,存到bodystatic bool FileRead(const std::string &file, std::string *body){body->clear();std::ifstream infile;//以二进制方式打开,避免读出和写入的大小不同,因为ifsteam以字符为单位,一个字符可能占多个字节infile.open(file, std::ios::binary);if(infile.is_open() == false){std::cout << "open file failed!\n";return false;}uint64_t size = fs::file_size(file);body->resize(size);infile.read(&(*body)[0], size);if(infile.good() == false){std::cout << "read file failed!\n";return false;}infile.close();return true;}//将body信息写入到文件内static bool FileWrite(const std::string &file, const std::string &body){std::ofstream outfile;outfile.open(file, std::ios::binary);if(outfile.is_open() == false){std::cout << "open file failed!\n";return false;}outfile.write(&body[0], body.size());if(outfile.good() == false){std::cout << "write file failed!\n";return false;}outfile.close();return true;}//将信息进行分割,传入三个参数,1被分割内容.2分割符.3分割后的内容static int Split(const std::string &str,const std::string &sp,std::vector<std::string> *arry){//定义文件个数int count = 0;//定义分隔符位置和偏移量size_t pos, idx = 0;while(1){//从idx起始位置开始找pos = str.find(sp, idx);if(pos == std::string::npos)break;std::string tmp;//字符串截取,从偏移量idx开始到pos的位置tmp = str.substr(idx, pos-idx);arry->push_back(tmp);//更新偏移量idxidx = pos + sp.size();count++;}//如果分隔符找到字符串末尾还没有,那么将偏移量到字符串末尾的数据全部插入arryif(idx < str.size()){arry->push_back(str.substr(idx));count++;}return count;}};class DataManager{private:std::string _path;//map设计在多线程中访问,为了解决安全问题需要加锁//互斥锁只能互斥访问,效率较低//因此采用读写锁---读共享,写互斥std::unordered_map<std::string, std::string> _map;pthread_rwlock_t _rwlock;public:DataManager(const std::string &path): _path(path){pthread_rwlock_init(&_rwlock, NULL);}~DataManager(){pthread_rwlock_destroy(&_rwlock);}//把文件数据读取出来存入到_map中bool Read(){std::string body;std::vector<std::string> arry;//调用Util类中的文件读取函数,将文件信息读到bodyif(Util::FileRead(_path, &body) == false){std::cout << "read data set failed!\n";return false;}//将body内的文件信息进行拆分//先按行进行拆分,将每个文件信息保存arry数组Util::Split(body, "\n", &arry);//对arry数据进行循环遍历,针对每一行的文件信息进一步拆分for(auto &line: arry){//定义kv数据存储每行文件信息的k和v值std::vector<std::string> kv;Util::Split(line, "=", &kv);//加锁pthread_rwlock_wrlock(&_rwlock);_map[kv[0]] = kv[1];pthread_rwlock_unlock(&_rwlock);}return true;}//把_map数据写入到文件中bool Write(){std::stringstream ss;pthread_rwlock_rdlock(&_rwlock);for(auto &it: _map){ss << it.first << "=" << it.second << "\n";}pthread_rwlock_unlock(&_rwlock);if(Util::FileWrite(_path, ss.str()) == false){std::cout << "write data set failed!\n";return false;}return true;}bool Exists(const std::string &key){pthread_rwlock_rdlock(&_rwlock);auto it = _map.find(key);if(it == _map.end()){pthread_rwlock_unlock(&_rwlock);return false;}pthread_rwlock_unlock(&_rwlock);return true;}//添加数据到_map中bool AddOrMod(const std::string &key, const std::string &val){pthread_rwlock_wrlock(&_rwlock);_map[key] = val;pthread_rwlock_unlock(&_rwlock);return true;}//删除数据bool Del(const std::string &key, const std::string &val){pthread_rwlock_wrlock(&_rwlock);auto it = _map.find(key);if(it == _map.end()){pthread_rwlock_unlock(&_rwlock);std::cout << key << "not exists!\n";return false;}_map.erase(it);pthread_rwlock_unlock(&_rwlock);return true;}bool Get(const std::string &key, std::string *val){pthread_rwlock_rdlock(&_rwlock);auto it = _map.find(key);if(it == _map.end()){pthread_rwlock_unlock(&_rwlock);std::cout << key << "not exitsts!\n";return false;}*val = _map[key];pthread_rwlock_unlock(&_rwlock);return true;}bool GetAll(std::vector<std::string> *arry){arry->clear();pthread_rwlock_rdlock(&_rwlock);for(auto &file: _map){arry->push_back(file.first);}pthread_rwlock_unlock(&_rwlock);return true;}};class Compress{public:static bool Pack(const std::string &filename, const std::string &packname){std::string body;Util::FileRead(filename, &body);Util::FileWrite(packname, bundle::pack(bundle::LZIP, body));return true;}static bool UnPack(const std::string &packname, const std::string &filename){std::string body;Util::FileRead(packname, &body);Util::FileWrite(filename, bundle::unpack(body));return true;}};
#define BACKUP_PATH "./backup/"
#define CONFIG_PATH "./backup.conf"DataManager g_data(CONFIG_PATH);class Server{private:httplib::Server _srv;private:static void Upload(const httplib::Request &req, httplib::Response &rsp){//判断有无对应name的文件上传信息auto ret = req.has_file("file");if(ret == false){std::cout << "have no file\n";rsp.status == 400;return ;}if(fs::exists(BACKUP_PATH) == false){fs::create_directories(BACKUP_PATH);}const auto& file = req.get_file_value("file");//设置文件的存储路径./backup/test.txtstd::string filename = BACKUP_PATH + file.filename;if(Util::FileWrite(filename, file.content) == false){std::cout << "write file data failed!\n";rsp.status = 500;return ;}//上传文件名,实际存储文件名--在被压缩后就会改为压缩包名称g_data.AddOrMod(file.filename, file.filename); //添加备份信息g_data.Write();return ;}static void List(const httplib::Request &req, httplib::Response &rsp){std::stringstream ss;ss << "<html><head><meta http-equiv='content-type' content='text/html;charset=utf-8'>";ss << "</head><body>";std::vector<std::string> arry;g_data.GetAll(&arry);for(auto &filename: arry){//<a href='/download/main.txt'><strong>main.txt</strong></a>ss << "<hr />";ss << "<a href='/backup/" << filename << "'><strong>" << filename << "</strong></a>";}ss << "<hr /></body></html>";rsp.body = ss.str();rsp.set_header("Content-Type", "text/html");return ;}static std::string GetIdentifier(std::string &path){uint64_t mtime, fsize;fsize = fs::file_size(path);auto time_type = fs::last_write_time(path);mtime = decltype(time_type)::clock::to_time_t(time_type);std::stringstream ss;ss << fsize << mtime;return ss.str();}static void Download(const httplib::Request &req, httplib::Response &rsp){//std::cout << "into Download" << req.matches[1] << std::endl;std::string name = req.matches[1];std::string pathname = BACKUP_PATH + name;std::string newetag = GetIdentifier(pathname);uint64_t fsize = fs::file_size(pathname);//判断是否压缩文件,如果是则进行解压缩 if(g_data.Exists(name)){std::string realname;g_data.Get(name, &realname);if(name != realname){Compress::UnPack(realname, pathname);unlink(realname.c_str());g_data.AddOrMod(name, name);g_data.Write();}}if(req.has_header("If_Range")){std::string oldetag = req.get_header_value("If-Range");if(oldetag == newetag){//断点续传--获取区间范围std::cout << req.ranges[0].first << "-" << req.ranges[0].second << "\n";int start = req.ranges[0].first;int end = req.ranges[0].second;Util::RangeRead(pathname, &rsp.body, &start, &end);rsp.set_header("Content-Type", "application/octet-stream");rsp.set_header("ETag", newetag);std::stringstream ss;ss << "bytes" << start << "-" << end << "/" << fsize;rsp.set_header("Content-Range", ss.str());rsp.status = 206;return ;}}if(Util::FileRead(pathname, &rsp.body) == false){std::cout << "read file" << pathname << "failed\n";rsp.status = 500;return ;}rsp.set_header("Content-Type", "application/octet-stream");rsp.set_header("Accept-Ranges", "bytes");rsp.set_header("ETag", newetag);rsp.status = 200;return ;}public:bool Start(int port = 9000){g_data.Read();_srv.Post("/multipart", Upload);_srv.Get("/list", List);_srv.Get("/backup/(.*)", Download);_srv.listen("0.0.0.0", port);return true;}};
#define PACK_PATH "./packdir/"class FileManager{private:ScanDir _scan;time_t _hot_time = 60;private:time_t LastAccessTime(const std::string &filename){struct stat st;stat(filename.c_str(), &st);return st.st_atime;}public:FileManager(): _scan(BACKUP_PATH){}bool Start(){while(1){std::vector<std::string> arry;_scan.Scan(&arry);for(auto &file : arry){//文件最后一次访问时间time_t atime = LastAccessTime(file);//当前系统时间time_t ctime = time(NULL);if(ctime - atime > _hot_time){fs::path fpath(file);std::string pack = PACK_PATH + fpath.filename().string() + ".pack";std::cout << file << " <-压缩存储-> " << pack << std::endl;Compress::Pack(file, pack); //压缩存储文件unlink(file.c_str()); //删除源文件g_data.AddOrMod(fpath.filename().string(), pack); //修改备份信息g_data.Write();}}usleep(1000);}return true;}};
}
主函数
由于http服务器是个死循环,文件管理中的start也是一个死循环(用来不断判断热度文件),因此使用多线程。
#include "cloud.hpp"
#include <thread>void thread_start()
{cloud_sys::FileManager fm; fm.Start();
}
int main()
{std::thread scan_thr(thread_start);scan_thr.detach();cloud_sys::Server srv;srv.Start();return 0;
}执行命令:
g++ -std=c++14 cloud.cpp bundle.cpp -o cloud -lpthread -lstdc++fs
最终项目目录下的文件如下