1、了解requests的功能
1.1 使用post和get发送请求
HTTP中常见发送网络请求的方式有两种,GET和POST。GET是从指定的资源请求数据,POST是向指定的资源提交要被处理的数据。
GET的用法:
import requestsr = requests.get("https://www.baidu.com/")
r = r.text
print(r)运行结果:

POST的用法:
import requestsr = requests.post("http://httpbin.org/post", data = {'key':'value'})
r = r.text
print(r)运行结果:

1.2 设置超时
在请求时给timeout一个值,单位是秒,如果请求时间超过这个值,自动断开。
import requestsr = requests.get("https://github.com/", timeout=1)
这个成功import requestsr = requests.get("https://github.com/", timeout=0.0001)
这个失败1.3改变编码方式
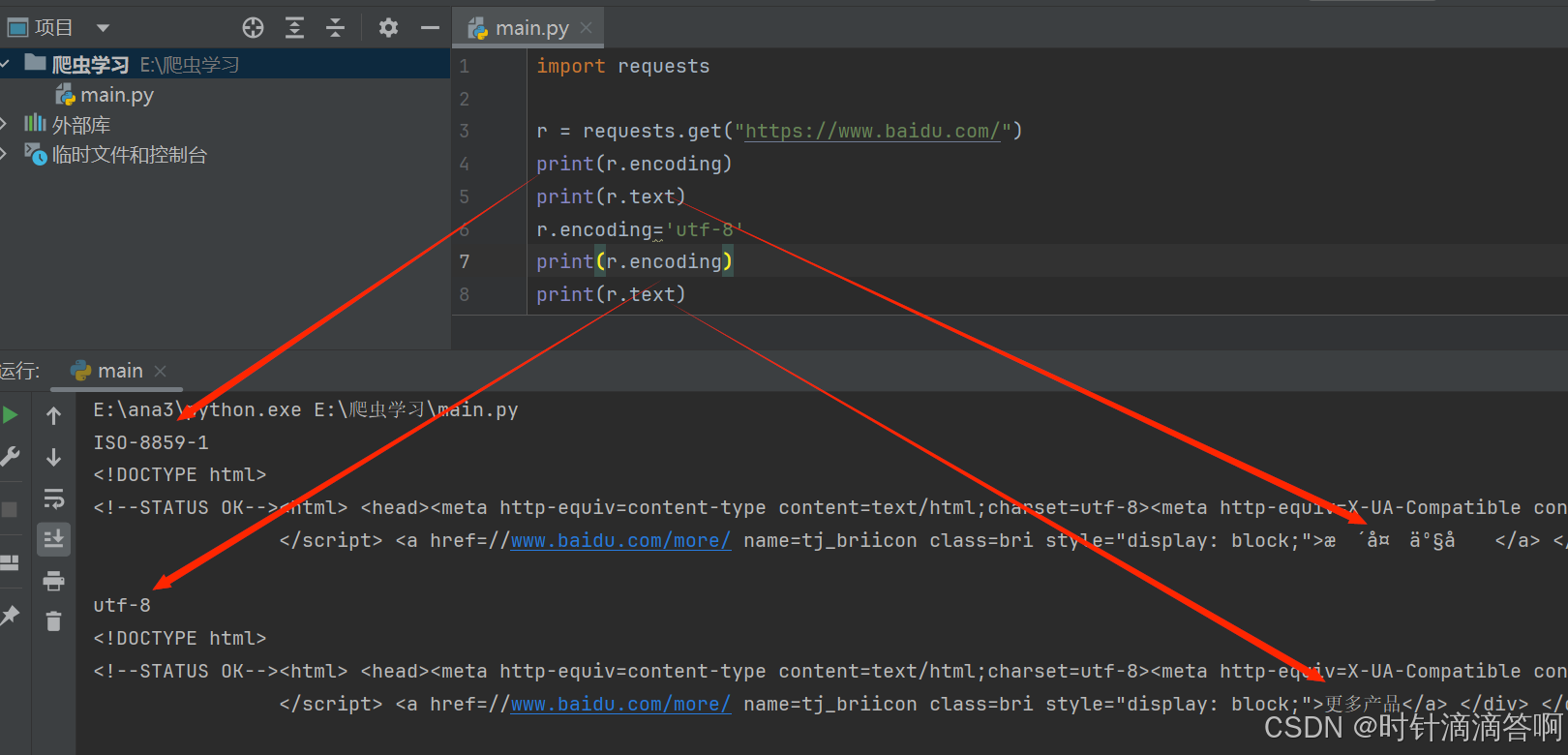
import requestsr = requests.get("https://www.baidu.com/")
print(r.encoding)
print(r.text)
r.encoding='utf-8'
print(r.encoding)
print(r.text)
输出结果:
1.4 设置代理IP
爬虫一般是是以每次分钟数百次甚至上万次的频率访问目标网站,如果爬虫是进行长时间的大量爬取工作的话,一定要给爬虫配置代理IP,否则会被ban。
2、自动化测试工具Selenium
2.1 Selenium安装
在PyCharm中的终端里面输入
pip install seleniumSelenium需要使用浏览器里面的driver打开浏览器来进行交互。
这里讲一下webdriver的安装(Edge为例),火狐浏览器还需要安装geckodriver。
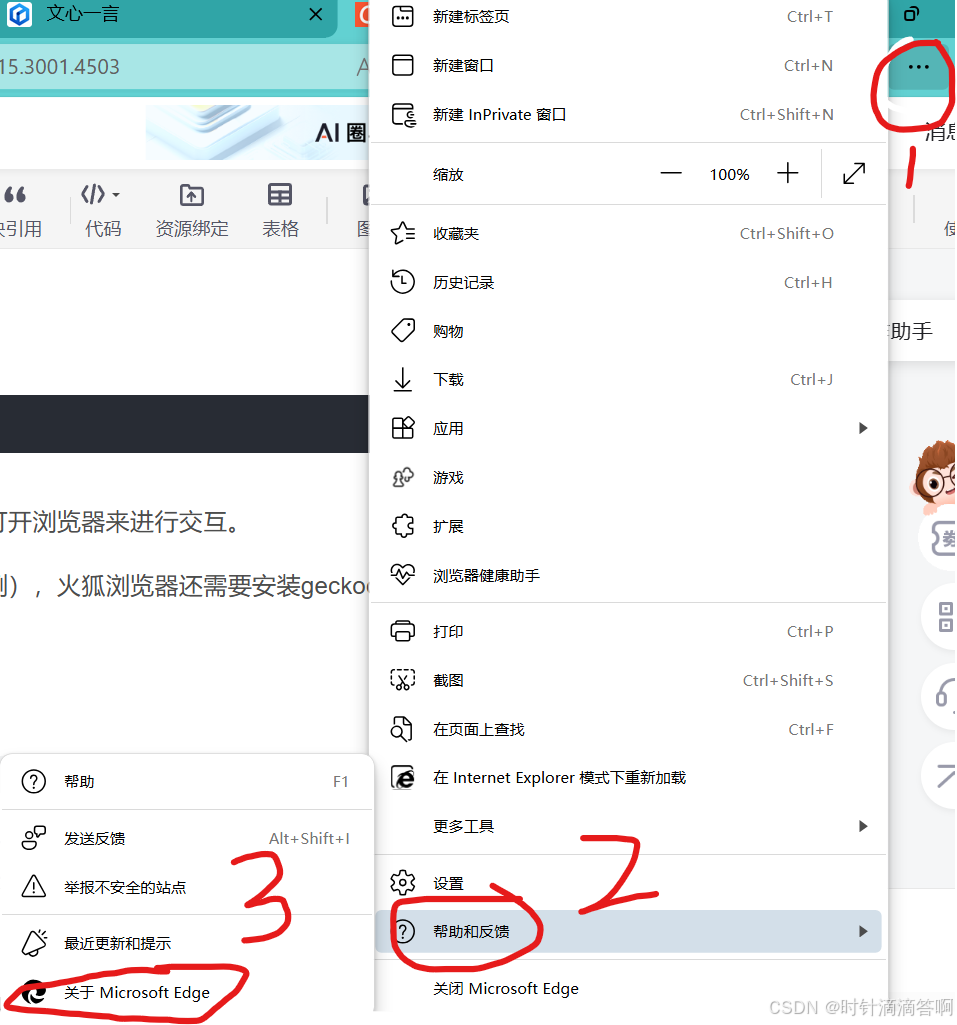
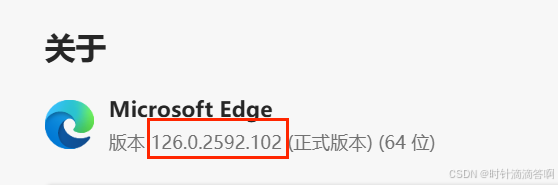
记住这个版本号
然后打开这个网站:Microsoft Edge WebDriver |Microsoft Edge 开发人员

然后点击开始下载,把解压出来的exe文件复制到与python.exe同一个文件夹下
在pycharm中运行下面的代码:
import time
from selenium import webdriverbrowser = webdriver.Edge()
browser.get("http://www.baidu.com")
time.sleep(10)如果弹出百度的网页,则安装成功。
2.2 使用Selnium爬取网站
可以执行下面的代码感受一下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.edge.service import Service
import timeservice = Service("E:/ana3/msedgedriver.exe") # 指定驱动程序的位置
driver = webdriver.Edge(service=service) # 创建驱动的实例
driver.get("http://www.python.org") # 发送请求到指定的 URI
if "Python" in driver.title: # 检查页面标题是否包含 "Python"print("ok") # 如果包含,输出 "ok"elem = driver.find_element(By.NAME, "q") # 找到参数名为 q 的输入框
elem.clear() # 清空输入框
elem.send_keys("python") # 输入文字
elem.send_keys(Keys.RETURN) # 按回车发送time.sleep(5) # 保留浏览器窗口 5 秒driver.close() # 关闭浏览器,释放内存
2.3 Selenium元素定位
我之后单独出一期