网络爬虫
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
搜索引擎离不开爬虫,比如百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛每天会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序并将结果展现给用户。
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何覆盖互联网中更多的优质网页?又如何筛选这些重复的页面?这些都是由百度蜘蛛爬虫的算法决定的。采用不同的算法,爬虫的运行效率会不同,爬取结果也会有所差异。
实现简单版百度贴吧爬虫
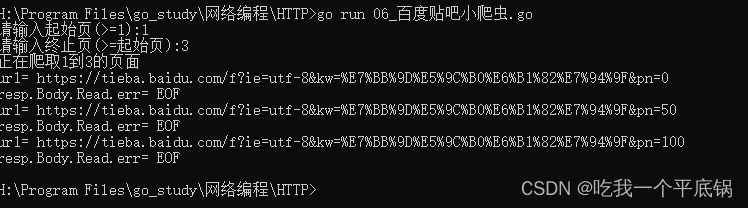
要求: 获取https://tieba.baidu.com/f?ie=utf-8&kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=页面内容,存入文件中。
func main() {var start, end intfmt.Printf("请输入起始页(>=1):")fmt.Scan(&start)fmt.Printf("请输入终止页(>=起始页):")fmt.Scan(&end)DoWork(start, end)
}- 输入起始页以及终止页
func DoWork(start, end int) {fmt.Printf("正在爬取%d到%d的页面\n", start, end)for i := start; i <= end; i++ {//明确要在那一个范围进行搜索ur1 := "https://tieba.baidu.com/f?ie=utf-8&kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=" +strconv.Itoa((i-1)*50)fmt.Println("ur1=", ur1)//爬result, err := HttpGet(ur1)if err != nil {fmt.Println("HttpGet.err=", err)continue}//把内容写入文件fileName := strconv.Itoa(i) + ".html"f, err1 := os.Create(fileName)if err1 != nil {fmt.Println("os.Create.err1=", err1)continue}f.WriteString(result) //写f.Close()}
}
- 明确要在那一个范围进行搜索
ur1 := "https://tieba.baidu.com/f?ie=utf-8&kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=" + strconv.Itoa((i-1)*50)实际的页面是一页50个数据,所以以此来进行获取。 - 获取
result, err := HttpGet(ur1)
func HttpGet(ur1 string) (result string, err error) {resp, err1 := http.Get(ur1)if err1 != nil {err = err1return}defer resp.Body.Close()//读取网页内容buf := make([]byte, 1024*4)for {n, err := resp.Body.Read(buf)if n == 0 { //读取结束或者出问题了fmt.Println("resp.Body.Read.err=", err)break}result += string(buf[:n])}return
}
Get底层
func Get(url string) (resp *Response, err error) {return DefaultClient.Get(url)
}
- 读取网页的内容
n, err := resp.Body.Read(buf) - 返回结果
- DoWork将放回的内容写入文件中
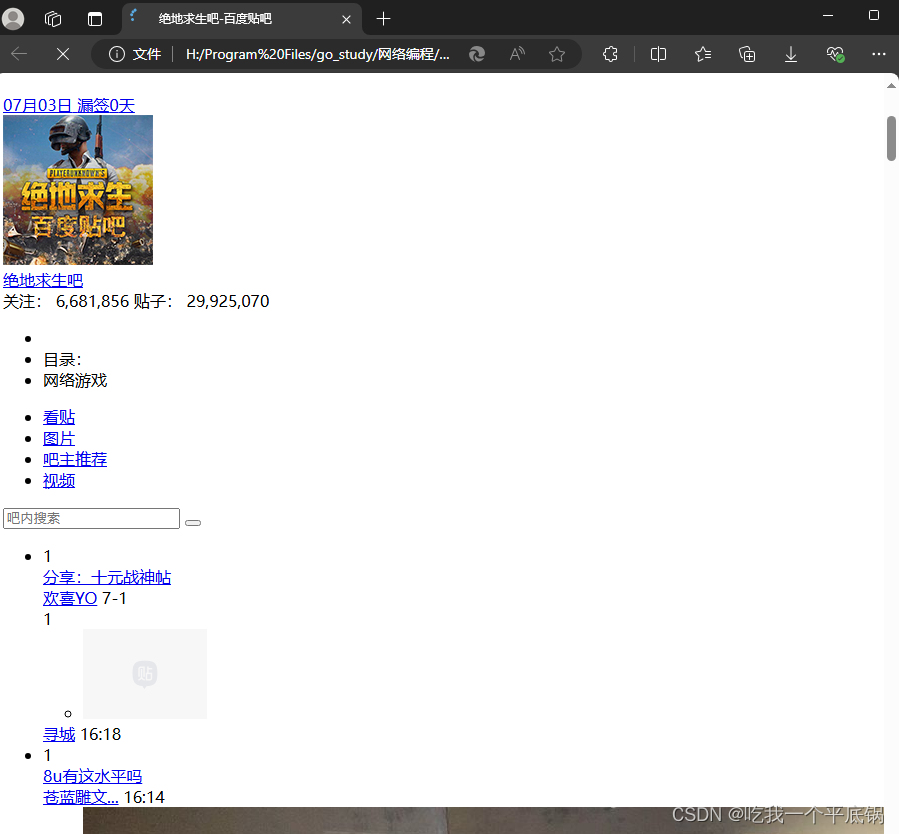
结果展示