若有不懂地方,可查阅我之前文章哦!

个人主页:小八哥向前冲~_csdn博客
所属专栏:数据结构_专栏
目录
排序的概念
几种排序方法介绍
冒泡排序
选择排序
插入排序
堆排序
向上调整建堆排序
向下调整建堆排序
希尔排序
快速排序
hoare版本快排
前后指针版本快排
非递归快排
归并排序
递归归并
非递归归并
扩展
计数排序
排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次 序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排 序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不断地在内外存之间移动数据的排序
几种排序方法介绍
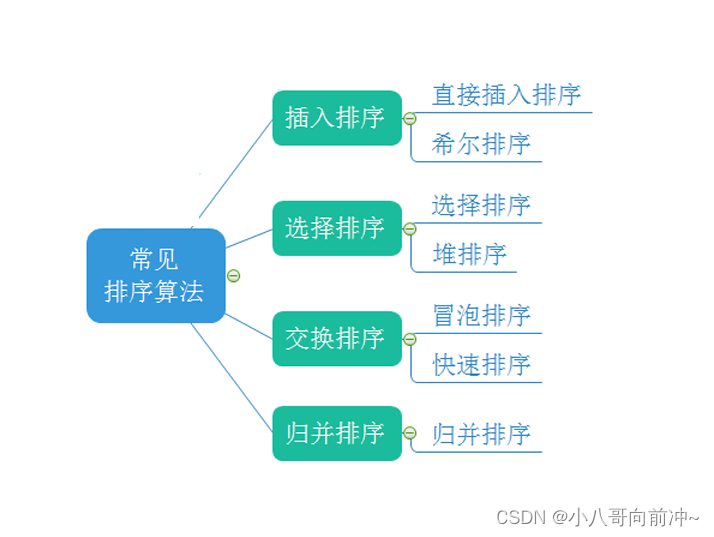
注意:下面各种排序将数组升序!
冒泡排序
冒泡排序相信你们都已经非常了解了!这里我们简单介绍一下就行!
有n个数,需要升序排列。我们只需要n-1趟排序,每趟排序将最大的排到了最后一个位置!
也就是说,每趟可以选出最大一个数且在最后一个位置上!
动画演示:
时间复杂度:o(N^2)
代码:
//交换
void Swap(int* p, int* q)
{int tmp = *p;*p = *q;*q = tmp;
}//冒泡排序 o(N^2)
void BubbleSort(int* a, int n)
{for (int j = 0; j < n - 1; j++){for (int i = 0; i < n - 1 - j; i++){if (a[i] > a[i + 1]){Swap(&a[i], &a[i + 1]);}}}
}选择排序
思路:
选择排序比较简单,选择——顾名思义,不断遍历数组,选择其中最小和最大的数,将最小数放在数组左侧,最大数放在数组右侧!
对于这个排序,我不做过多解释,比较简单!但是这里有一个小坑!
图:

代码:
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){int maxi = 0, mini = 0;for (int i = begin ; i <= end; i++){if (a[i] > a[maxi]){maxi = i;}if (a[i] < a[mini]){mini = i;}}Swap(&a[mini], &a[begin]);//begin和maxi相等时,刷新maxiif (begin == maxi){maxi = mini;}Swap(&a[maxi], &a[end]);begin++;end--;}
}插入排序
插入排序动画演示:
比如:要求升序,将一个一个数依次往前比较,比它大的往后移,知道比它小的数,再插进去!
时间复杂度:最坏情况-逆序-o(N^2) 最好情况-有序-o(N)
代码:
//插入排序
void Insert(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (a[end] > tmp){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}
堆排序
由于前俩章介绍了堆和二叉树,这里的堆排序不过多讲述,可翻阅我之前文章!
传送门:CSDN--详解堆
我们这里介绍俩种排序方法!
向上调整建堆排序
思路:
以将数组拍成升序为例,将数组中的数建成大堆,此时第一个数就是最大的数!再将第一个数和最后一个数交换,以此循环!
代码:
//向上调整
void AdjustUp(int* a, int child)
{int parent = (child - 1) / 2;while (child > 0){if (a[child] > a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
//向下调整
void AdjustDown(int* a, int n, int parent)
{int child = 2 * parent + 1;while (child < n){if (child + 1 < n&&a[child + 1] > a[child]){child++;}if (a[child] > a[parent]){Swap(&a[parent], &a[child]);}else{break;}}
}
//堆排序--向上调整-o(N*logN)
void HeapUpSort(int* a, int n)
{for (int i = 0; i < n; i++){AdjustUp(a, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}注意:时间复杂度——o(N*logN)
向下调整建堆排序
思路:
用向下调整的方法将数组调成大堆,那么第一个数就是数组中最大的数!然后将第一个数和数组最后一个数交换,以此循环交换!
代码:
//向下调整
void AdjustDown(int* a, int n, int parent)
{int child = 2 * parent + 1;while (child < n){if (child + 1 < n&&a[child + 1] > a[child]){child++;}if (a[child] > a[parent]){Swap(&a[parent], &a[child]);}else{break;}}
}
//堆排序—向下调整建堆—o(N)
void HeapDownSort(int* a, int n)
{for (int i = (n - 1 - 1) / 2; i > 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[end], &a[0]);AdjustDown(a, end, 0);end--;}
}希尔排序
先将数组里面的数分组,然后将分组好了的数排序,最后将整个数组利用插入排序进行最后的排序!
第一种代码:
//希尔排序 o(N^1.3)
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int j = 0; j < gap; j++){for (int i = j; i < n - gap; i += gap){int end = i;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}}
}
第二种代码:
//希尔排序 o(N^1.3)
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}快速排序
hoare版本快排
霍尔版本的快速排序动画演示:

思路:
先在这个数组中寻找一个参考值,将数组左边排成都比参考值小,数组右边排成都比参考值大!然后中间值将参考值交换。再将中间值左右边都这样循环往复操作,形成有序!
代码:
void Swap(int* q, int* p)
{int tmp = *q;*q = *p;*p = tmp;
}
void QuickSort(int* a, int left, int right)
{if (left >= right){return;}int keyi = left;int begin = left, end = right;while (begin < end){//右边找小while (begin<end && a[end]>a[keyi]){end--;}//左边找大while (begin < end && a[begin] < a[keyi]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);keyi = begin;QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);
}但是这样写有一点瑕疵,我们可以近一步优化!
这段代码的“瑕疵”在:
- 可能会栈溢出(递归太深)
- 可以将后面递归排序进行优化
第一个瑕疵可以:当你取的参考值是数组里面最小的,那么就只会递归后面的n-1个数!这种情况是最有可能栈溢出(递归太深)!
我们可以进行三数取中优化!
第二个瑕疵可以:当一直递归排序时,数组过大非常适合取中快排,但是当数组过小,我们没有必要用快排排序,我们可以用插入排序!
优化代码:
void Swap(int* q, int* p)
{int tmp = *q;*q = *p;*p = tmp;
}//三数取中
int GetMid(int* a, int left, int right)
{int midi = (left + right) / 2;if (a[left] < a[right]){if (a[midi] < a[left]){return left;}else if (a[midi] > a[right]){return right;}else{return midi;}}else{if (a[midi] > a[left]){return left;}else if (a[midi] < a[right]){return right;}else{return midi;}}
}
//插入排序
void Insort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (a[end] > tmp){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}void QuickSort(int* a, int left, int right)
{if (left >= right){return;}//三数取中优化int midi = GetMid(a, left, right);Swap(&a[left], &a[midi]);//小区间优化if ((right - left + 1) < 10){Insort(a+left, right - left + 1);}else{int keyi = left;int begin = left, end = right;while (begin < end){//右边找小while (begin<end && a[end]>a[keyi]){end--;}//左边找大while (begin < end && a[begin] < a[keyi]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);keyi = begin;QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}
}前后指针版本快排
前后指针版本的快排动画演示:

思路:
俩种方法大差不差,只是相比hoare版本,前后指针更好理解。俩种都是将数组分割成俩个小数组,进行排序!用的是双指针来分割交换数组!
代码:
//三数取中
int GetMid(int* a, int left, int right)
{int midi = (left + right) / 2;if (a[left] < a[right]){if (a[midi] < a[left]){return left;}else if (a[midi] > a[right]){return right;}else{return midi;}}else{if (a[midi] > a[left]){return left;}else if (a[midi] < a[right]){return right;}else{return midi;}}
}
int Partsort02(int* a, int left, int right)
{//三数取中优化int midi = GetMid(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;int prev = left;int cur = prev + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[keyi], &a[prev]);return prev;
}
void QuickSort(int* a, int left, int right)
{if (left >= right){return;}//小区间优化if ((right - left + 1) < 10){Insort(a+left, right - left + 1);}else{int keyi = Partsort02(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}
}递归固然好,但它再好也逃不过栈溢出的风险!所以我们可以将递归改成非递归!
我们可以用栈来模拟递归思想从而变成非递归!
非递归快排
我们可以将区间入栈,再将区间出栈进行排序,分成俩组,再将这俩组分别入栈(后一组先入栈),前一组出栈排序,循环往复!

代码:
注意:里面的ST为栈结构,若有不懂可去我这篇文章---栈——CSDN-小八哥向前冲
//非递归
void QuickStack(int* a, int left, int right)
{ST st;STInit(&st);STpush(&st, right);STpush(&st, left);while (!STEmpty(&st)){//出栈取数据int begin = STtop(&st);STpop(&st);int end = STtop(&st);STpop(&st);//开始排序int keyi = Partsort02(a, begin, end);//排完一趟就入栈if (keyi + 1 < end){STpush(&st, end);STpush(&st, keyi + 1);}if (begin < keyi - 1){STpush(&st, keyi - 1);STpush(&st, begin);}}
}归并排序
递归归并
倘若有这样一个数组----它的前半部分有序,后半部分也有序(只不过整体不有序),就能利用归并将这个数组排成有序!
单趟理解:

那么使用归并排序,是不是应该先要前后部分分别有序呢?我们可以将数组一直二分下去归并排!
我们可以将它一直分开,直到不能分开了,就开始归并!
理解:

整体理解:

代码:
void _MergeSort(int* a, int* tmp, int left, int right)
{if (left >= right){return;}int mid = (left + right) / 2;//分区间_MergeSort(a, tmp, left, mid);_MergeSort(a, tmp, mid + 1, right);//开始排int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int i = left;while (begin1<=end1 && begin2<=end2)//但凡有一个越界就跳出来{if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}memcpy(a + left, tmp + left, sizeof(int) * (right - left + 1));
}
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);_MergeSort(a, tmp, 0, n - 1);free(tmp);tmp = NULL;
}时间复杂度:N*logN
非递归归并
非递归思路:
那么如何将递归方式改成非递归呢?一定要区别归并和快排,快排是先排序再分,归并是先分再排!快排相当于是二叉树里面的前序,而归并相当于是后序!
这里利用栈不好实现,我们可以另辟蹊径!
既然不好实现分组,那我们可以进行手动分组,然后进行归并!
理解:

代码:
void MergeSortNon(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc faild !");return;}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//第二组完全越界了,这组就不用归并了if (begin2 >= n){break;}//第一组没越界,第二组部分越界,需要进行修正再归并if (end2 >= n){end2 = n - 1;}int j = begin1;while (begin1 <= end1 && begin2 <= end2)//但凡有一个越界就跳出来{if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}memcpy(a + i, tmp + i, sizeof(int) * (end2-i+1));}gap *= 2;}free(tmp);tmp = NULL;
}这里解释一下为什么需要归并一部分复制一部分:
如果后部分越界了,就不会归并,那么tmp数组里面就没有没归并的数,只有归并了的数,如果是全部归并了再去复制一份的话,就直接覆盖了原来就有的数值!所以归并一部分再复制一部分是再好不过的选择!
扩展
计数排序
计数排序和其他排序方法截然不同,它摒弃了以往的比较大小的方法,转化成计数的方法!
我们上图比较好理解:

代码:
void CountSort(int* a, int n)
{int max = a[0], min = a[0];for (int i = 0; i < n; i++){if (a[i] > max){max = a[i];}if (a[i] < min){min = a[i];}}int range = max - min + 1;int* count = (int*)calloc(range,sizeof(int));if (count == NULL){perror("malloc faild!");return;}//开始计数for (int i = 0; i < n; i++){count[a[i] - min]++;}//开始往回写int j = 0;for (int i = 0; i < range; i++){while (count[i]--){a[j++] = i + min;}}free(count);count = NULL;
}这里代码有个小细节:
开辟空间不用malloc,而用calloc,是因为我们新开辟的数组里面元素都要置0,再进行计数,而calloc开辟完了空间就会将数组元素全部置0!
全部排序总结

好了,今天的分享就到这里,我们在C++不见不散!




![[算法] 优先算法(六):二分查找算法(下)](https://i-blog.csdnimg.cn/direct/551e5df4b4764f0d8655f732ae740e38.png)