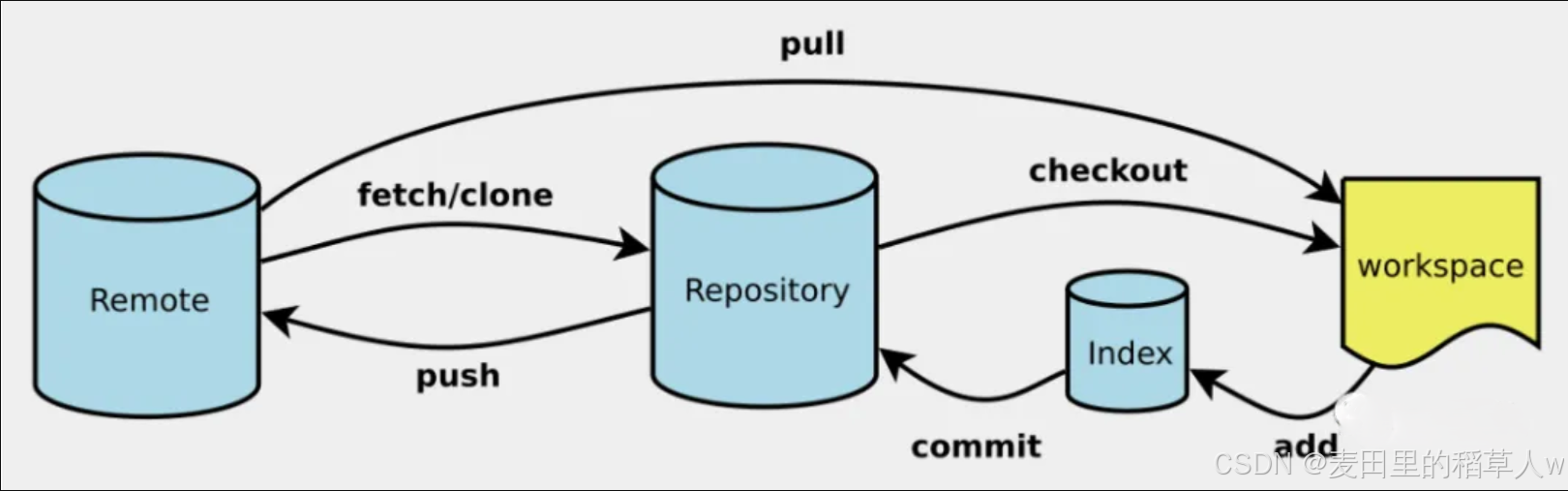
目录
- 引言
- Hadoop是什么?
- 学习Hadoop的"糙快猛"之道
- 1. 不要追求完美,先动手再说
- 2. 从简单的MapReduce开始
- 3. 利用大模型加速学习
- 4. 循序渐进,建立知识体系
- 构建您的Hadoop技能树
- 1. 夯实基础:Linux和Java
- 2. 深入理解HDFS
- 3. 掌握MapReduce编程模型
- 4. 探索Hadoop生态系统
- 实战项目:登录日志分析系统
- 高级主题探索
- 1. Hadoop性能优化
- 2. 调试Hadoop作业
- 3. 数据倾斜问题
- 4. 与Spark的集成
- 实战案例:构建数据湖
- 持续学习和职业发展
- 面对实际工作中的挑战
- 1. 大规模数据迁移
- 2. 处理实时流数据
- 3. 处理非结构化数据
- 新兴技术趋势
- 1. 容器化和Kubernetes
- 2. 机器学习集成
- 3. 图处理
- 将Hadoop技能与数据科学结合
- 实战项目:构建端到端的大数据分析平台
- 结语
引言
大家好,我是一名从0基础跨行到大数据开发的程序员。今天,我想和大家分享一下我学习Hadoop的心得,希望能够帮助到那些正在或即将踏上大数据之路的朋友们。
Hadoop是什么?

在开始之前,让我们先简单了解一下Hadoop。Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。它的核心组件包括:
- HDFS(Hadoop分布式文件系统):用于存储海量数据
- MapReduce:一种编程模型,用于大规模数据集的并行处理
- YARN:集群资源管理系统
学习Hadoop的"糙快猛"之道

1. 不要追求完美,先动手再说
记得我刚开始学习Hadoop时,面对繁多的概念和复杂的架构,我也曾感到迷茫。但我很快意识到,与其纠结于理论,不如直接上手实践。
就像我的座右铭:“学习就应该糙快猛,不要一下子追求完美,在不完美的状态下前行才是最高效的姿势。”
2. 从简单的MapReduce开始
让我们来看一个简单的WordCount示例,这是学习Hadoop的经典入门案例:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.util.StringTokenizer;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
这段代码看起来可能有点复杂,但别被吓到!记住我们的口号:“糙快猛往前冲”。先把这段代码跑起来,看看结果,然后再逐步理解每个部分的作用。
3. 利用大模型加速学习
现在我们有了强大的AI助手,学习效率可以大大提高。但请记住,AI是工具,不是替代品。如我所说:“大模型能帮不少忙,但远没有到能完全代劳的时候,建立审美特别重要,还得自己来。”
比如,你可以让AI解释上面的WordCount代码,但真正的理解和应用还需要你自己动手实践。
4. 循序渐进,建立知识体系
学习Hadoop不是一蹴而就的事情。我的建议是:
- 先掌握HDFS的基本概念和操作
- 学习MapReduce编程模型
- 了解YARN的资源调度机制
- 探索Hadoop生态系统中的其他工具(如Hive, HBase等)
记住:“根据自己的节奏来”,不要盲目追求速度,找到适合自己的学习节奏才是关键。

构建您的Hadoop技能树
在上一部分中,我们讨论了开始学习Hadoop的基本策略和心态。现在,让我们更深入地探讨如何构建您的Hadoop技能,并在"糙快猛"的基础上更上一层楼。

1. 夯实基础:Linux和Java
在真正深入Hadoop之前,确保您对Linux操作系统和Java编程有扎实的基础。这两项技能对于理解和使用Hadoop至关重要。
- Linux技能:学习基本的命令行操作,文件系统管理,以及Shell脚本编写。
- Java编程:掌握面向对象编程,集合框架,并发编程等概念。

2. 深入理解HDFS
HDFS是Hadoop的基石。要真正理解它,可以尝试以下步骤:
- 搭建一个小型Hadoop集群(可以是单节点的伪分布式模式)
- 使用HDFS命令行工具进行文件操作
- 编写一个简单的Java程序,使用HDFS API进行文件读写
这里有一个使用HDFS API写文件的简单示例:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;import java.io.IOException;public class HDFSWriter {public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://localhost:9000");try {FileSystem fs = FileSystem.get(conf);Path file = new Path("/user/hadoop/test.txt");if (fs.exists(file)) {fs.delete(file, true);}FSDataOutputStream outputStream = fs.create(file);outputStream.writeBytes("Hello, Hadoop!");outputStream.close();System.out.println("File written successfully");} catch (IOException e) {e.printStackTrace();}}
}
尝试运行这段代码,然后使用HDFS命令行工具查看文件内容,这样可以帮助你更好地理解HDFS的工作原理。
3. 掌握MapReduce编程模型
在理解了基本的WordCount示例后,尝试编写更复杂的MapReduce程序。例如:
- 计算平均值
- 数据去重
- 数据关联(Join操作)
这里有一个计算平均值的MapReduce示例:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class AverageCalculator {public static class AverageMapperextends Mapper<LongWritable, Text, Text, DoubleWritable> {private Text outputKey = new Text("Average");public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {double number = Double.parseDouble(value.toString());context.write(outputKey, new DoubleWritable(number));}}public static class AverageReducerextends Reducer<Text, DoubleWritable, Text, DoubleWritable> {public void reduce(Text key, Iterable<DoubleWritable> values, Context context)throws IOException, InterruptedException {double sum = 0;int count = 0;for (DoubleWritable value : values) {sum += value.get();count++;}double average = sum / count;context.write(key, new DoubleWritable(average));}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "average calculator");job.setJarByClass(AverageCalculator.class);job.setMapperClass(AverageMapper.class);job.setReducerClass(AverageReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(DoubleWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
4. 探索Hadoop生态系统

Hadoop生态系统非常丰富,包括许多强大的工具。以下是一些值得学习的技术:
- Hive:用于数据仓库,提供类SQL查询语言
- HBase:基于Hadoop的NoSQL数据库
- Spark:用于大规模数据处理的统一分析引擎
- Kafka:分布式流处理平台
对于每种技术,我建议采用以下学习方法:
- 了解基本概念和使用场景
- 搭建本地环境
- 完成官方文档中的示例
- 尝试解决一个实际问题
记住我们的口号:“糙快猛往前冲”。不要在一个技术上停留太久,先建立整体认知,然后再逐步深入。
实战项目:登录日志分析系统
为了将所学知识融会贯通,不妨尝试一个实际项目。比如,我们可以建立一个简单的登录日志分析系统:
- 使用Flume收集登录日志
- 将日志存储到HDFS
- 使用MapReduce或Hive分析日志,如计算每日活跃用户数
- 将分析结果存入HBase
- 使用Web界面展示分析结果

这个项目会让你对Hadoop生态系统有一个全面的认识,也能培养你解决实际问题的能力。
高级主题探索
在掌握了Hadoop的基础知识后,是时候深入一些更高级的主题了。记住我们的"糙快猛"原则,但同时也要注意这些高级主题可能需要更多的时间和耐心。
1. Hadoop性能优化

优化Hadoop作业的性能是一项重要技能。以下是一些关键点:
a) 合理设置分片大小:分片大小会影响作业的并行度。
// 在Job配置中设置分片大小
job.getConfiguration().setLong("mapreduce.input.fileinputformat.split.minsize", 134217728); // 128MB
b) 使用Combiner:Combiner可以在Map端进行本地聚合,减少网络传输。
job.setCombinerClass(IntSumReducer.class);
c) 压缩中间结果:减少Map和Reduce之间的数据传输量。
// 启用map输出压缩
job.getConfiguration().setBoolean("mapreduce.map.output.compress", true);
job.getConfiguration().set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
2. 调试Hadoop作业

调试分布式系统中的问题可能很棘手。以下是一些有用的技巧:
a) 使用本地模式:在提交到集群之前,先在本地模式下运行和调试。
conf.set("mapreduce.framework.name", "local");
b) 查看作业日志:使用yarn logs命令查看详细日志。
yarn logs -applicationId <application_id>
c) 使用计数器:计数器可以帮助你了解作业的进度和状态。
context.getCounter("MyGroup", "MyCounter").increment(1);
3. 数据倾斜问题

数据倾斜是Hadoop中的一个常见问题。这里有几种解决方案:
a) 自定义分区器:确保数据均匀分布到Reduce任务。
public class CustomPartitioner extends Partitioner<Text, IntWritable> {@Overridepublic int getPartition(Text key, IntWritable value, int numPartitions) {// 自定义分区逻辑}
}// 在Job中设置
job.setPartitionerClass(CustomPartitioner.class);
b) 采样和预处理:对数据进行采样,识别并处理可能导致倾斜的键。
4. 与Spark的集成
随着Apache Spark的兴起,学会如何在Hadoop生态系统中使用Spark也变得很重要。
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("Spark on YARN").config("spark.yarn.jars", "hdfs:///spark-jars/*").getOrCreate()val df = spark.read.parquet("hdfs:///data/mydata.parquet")
df.createOrReplaceTempView("mydata")val result = spark.sql("SELECT * FROM mydata WHERE value > 100")
result.write.saveAsTable("highValueData")
实战案例:构建数据湖
让我们通过一个更复杂的实战案例来综合运用我们所学的知识。我们将构建一个简单的数据湖系统:
- 数据采集:使用Flume和Kafka采集各种来源的数据
- 数据存储:将原始数据存储在HDFS中
- 数据处理:使用MapReduce和Spark进行数据清洗和转换
- 数据分析:使用Hive进行数据分析
- 数据服务:使用HBase和Phoenix提供快速查询服务
- 任务调度:使用Oozie协调各个任务的执行

这里是一个使用Oozie调度Hive作业的工作流示例:
<workflow-app xmlns="uri:oozie:workflow:0.5" name="hive-wf"><start to="hive-job"/><action name="hive-job"><hive xmlns="uri:oozie:hive-action:0.2"><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><script>my-hive-script.q</script></hive><ok to="end"/><error to="fail"/></action><kill name="fail"><message>Hive job failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message></kill><end name="end"/>
</workflow-app>
持续学习和职业发展
大数据领域发展迅速,持续学习至关重要。以下是一些建议:
- 关注Apache Hadoop的官方博客和邮件列表
- 参与开源社区:提交补丁,报告bug,或者回答他人的问题
- 参加大数据相关的会议:如Hadoop Summit, Strata + Hadoop World等
- 获取认证:如Cloudera Certified Developer for Apache Hadoop (CCDH)

面对实际工作中的挑战
在实际工作中,你可能会遇到一些课本上没有涉及的挑战。让我们探讨一些常见问题及其解决方案。
1. 大规模数据迁移
当需要在不同的Hadoop集群之间迁移大量数据时,可以考虑使用以下工具:

a) DistCp (分布式拷贝):
hadoop distcp hdfs://namenode1:8020/source hdfs://namenode2:8020/destination
b) Sqoop:用于在Hadoop和关系型数据库之间传输数据。
sqoop import --connect jdbc:mysql://localhost/mydb --table mytable --target-dir /user/hadoop/mytable
2. 处理实时流数据

对于需要实时处理的数据流,可以考虑以下技术:
a) Kafka Streams:
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("input-topic");
KStream<String, String> processed = source.mapValues(value -> value.toUpperCase());
processed.to("output-topic");
b) Apache Flink:
DataStream<String> dataStream = env.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties));
DataStream<String> processedStream = dataStream.map(new MyMapFunction());
processedStream.addSink(new FlinkKafkaProducer<>("output-topic", new SimpleStringSchema(), properties));
3. 处理非结构化数据

对于图像、视频等非结构化数据,可以考虑以下方案:
a) 使用 HBase 存储元数据,HDFS 存储实际文件
b) 结合使用 Hadoop 和深度学习框架,如 TensorFlow on YARN
import tensorflow as tf
from tensorflow.python.client import device_libdef get_available_gpus():local_device_protos = device_lib.list_local_devices()return [x.name for x in local_device_protos if x.device_type == 'GPU']print(get_available_gpus())
新兴技术趋势
大数据领域发展迅速,掌握新兴技术可以让你在职场中保持竞争力。
1. 容器化和Kubernetes
使用 Kubernetes 管理 Hadoop 集群正变得越来越普遍。了解如何在 Kubernetes 上部署 Hadoop 集群是一项有价值的技能。
apiVersion: apps/v1
kind: Deployment
metadata:name: hadoop-namenode
spec:replicas: 1selector:matchLabels:app: hadoop-namenodetemplate:metadata:labels:app: hadoop-namenodespec:containers:- name: hadoop-namenodeimage: hadoop-namenode:latestports:- containerPort: 8020
2. 机器学习集成
将机器学习模型与Hadoop生态系统集成是一个重要趋势。例如,使用Spark MLlib:
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.VectorAssembler// 准备训练数据
val data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")// 特征工程
val assembler = new VectorAssembler().setInputCols(Array("feature1", "feature2", "feature3")).setOutputCol("features")val output = assembler.transform(data)// 训练逻辑回归模型
val lr = new LogisticRegression().setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8)val model = lr.fit(output)// 保存模型
model.write.overwrite().save("/models/logisticRegressionModel")
3. 图处理
随着社交网络分析等应用的兴起,图处理变得越来越重要。Apache Giraph 是 Hadoop 生态系统中的一个图处理框架:
public class SimpleShortestPathsComputation extendsBasicComputation<LongWritable, DoubleWritable, FloatWritable, DoubleWritable> {@Overridepublic void compute(Vertex<LongWritable, DoubleWritable, FloatWritable> vertex,Iterable<DoubleWritable> messages) throws IOException {if (getSuperstep() == 0) {vertex.setValue(new DoubleWritable(Double.MAX_VALUE));}double minDist = isSource(vertex) ? 0d : Double.MAX_VALUE;for (DoubleWritable message : messages) {minDist = Math.min(minDist, message.get());}if (minDist < vertex.getValue().get()) {vertex.setValue(new DoubleWritable(minDist));for (Edge<LongWritable, FloatWritable> edge : vertex.getEdges()) {double distance = minDist + edge.getValue().get();sendMessage(edge.getTargetVertexId(), new DoubleWritable(distance));}}vertex.voteToHalt();}
}
将Hadoop技能与数据科学结合

在当今的就业市场,能够将Hadoop技能与数据科学和机器学习结合的人才非常抢手。以下是一些建议:
-
学习 Python:Python 是数据科学的主要语言,也可以用于编写 Hadoop 作业。
-
掌握数据可视化:学习如何使用工具如 Matplotlib, Seaborn, 或 Plotly 来可视化大数据分析结果。
-
了解常见的机器学习算法:如线性回归、决策树、随机森林等,并学习如何在Hadoop/Spark环境中实现它们。
-
学习模型部署:了解如何将训练好的模型部署到生产环境中,以实现实时预测。
这里是一个使用PySpark进行简单线性回归的例子:
from pyspark.ml.regression import LinearRegression
from pyspark.ml.feature import VectorAssembler# 准备数据
data = spark.read.csv("hdfs:///data/regression_data.csv", header=True, inferSchema=True)# 特征工程
assembler = VectorAssembler(inputCols=["feature1", "feature2", "feature3"], outputCol="features")
data = assembler.transform(data)# 划分训练集和测试集
(trainingData, testData) = data.randomSplit([0.7, 0.3])# 创建线性回归模型
lr = LinearRegression(featuresCol="features", labelCol="label")# 训练模型
model = lr.fit(trainingData)# 在测试集上进行预测
predictions = model.transform(testData)# 评估模型
from pyspark.ml.evaluation import RegressionEvaluator
evaluator = RegressionEvaluator(labelCol="label", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print(f"Root Mean Squared Error (RMSE) on test data = {rmse}")
实战项目:构建端到端的大数据分析平台
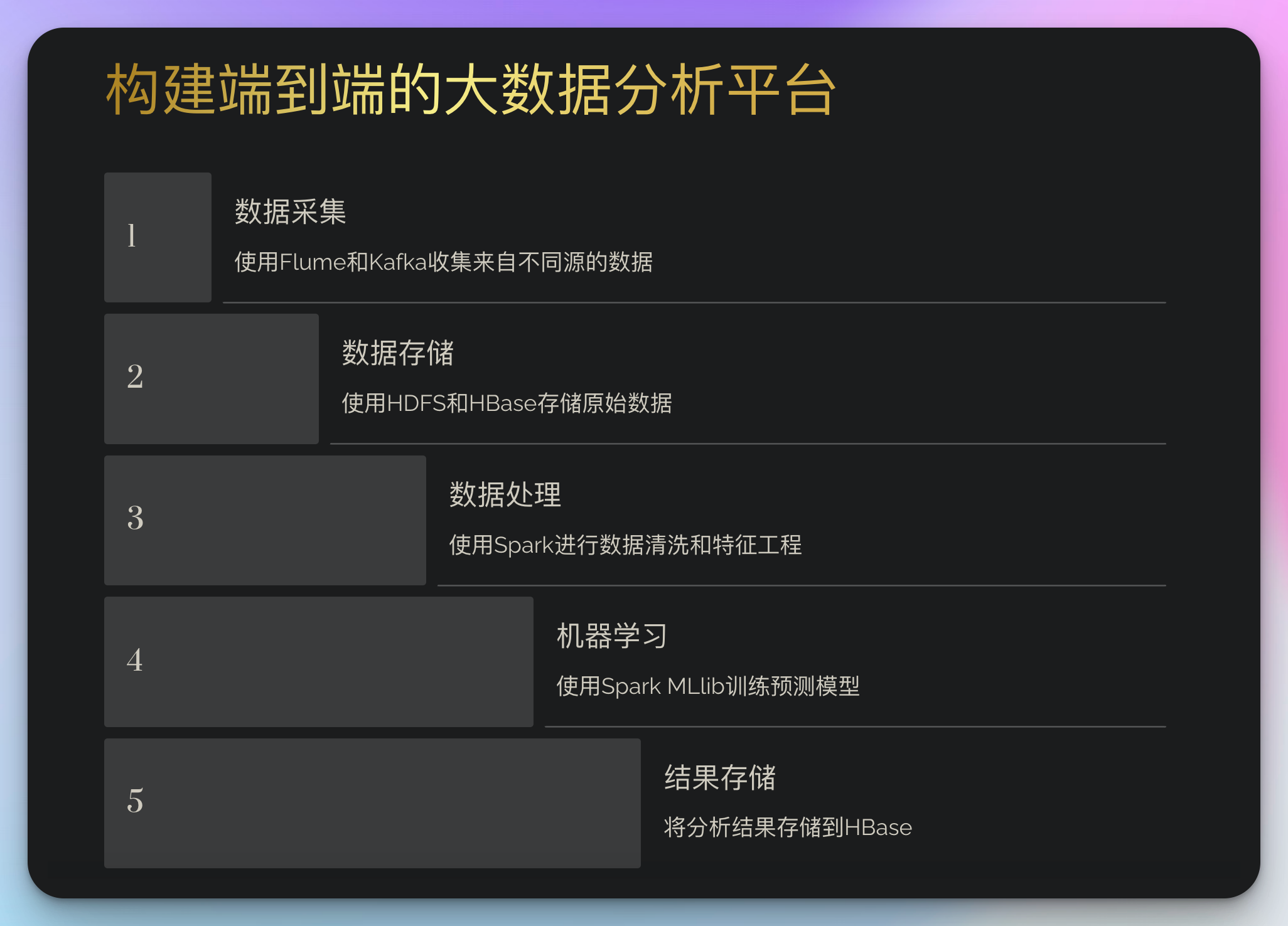
为了将所有这些知识整合在一起,让我们设计一个更复杂的实战项目:构建一个端到端的大数据分析平台。这个平台将包括:
- 数据采集:使用Flume和Kafka收集来自不同源的数据
- 数据存储:使用HDFS和HBase存储原始数据
- 数据处理:使用Spark进行数据清洗和特征工程
- 机器学习:使用Spark MLlib训练预测模型
- 结果存储:将分析结果存储到HBase
- 数据可视化:使用Zeppelin或Superset创建交互式仪表板
- 工作流调度:使用Airflow管理整个数据处理pipeline
这个项目将让你有机会应用你所学的所有技能,并且培养你解决复杂大数据问题的能力。
结语
正如我一直强调的,“学习就应该糙快猛,不要一下子追求完美,在不完美的状态下前行才是最高效的姿势。”

但是,随着你在Hadoop和大数据领域的不断深入,你会发现,真正的专业性不仅体现在技术细节上,更体现在如何利用这些技术解决实际问题,如何推动创新。
请记住,技术工具在不断evolve,"糙快猛"的学习方法可以让你快速掌握新技术的要领。
每当你解决了一个难题,克服了一个障碍,你就离你的目标更近了一步。保持热情,保持好奇,继续前进!
最后,我想再次强调:
- 保持"糙快猛"的学习态度,快速掌握新技术
- 通过实战项目深化对技术的理解
- 培养将技术与实际问题结合的能力
- 持续关注行业动态,保持创新思维
大数据领域充满了挑战和机遇。但我相信,只要你保持学习的激情,不断挑战自己,你一定能在这个领域大展身手,成为真正的大数据专家和创新者!加油!