7 月 13 日,AutoMQ 携手 GreptimeDB“新能源汽车数据基础设施” 主题 meetup 在上海圆满落幕。本次论坛多角度探讨如何通过创新的数据管理和存储架构,提升汽车系统的性能、安全性和可靠性,从而驱动行业的持续发展和创新,涵盖 AutoMQ 多模态共享存储架构、长城汽车多云多活架构的实践与探索、GreptimeDB 边云一体化数据库介绍、小红书深度解读 AutoMQ 云原生及多云容灾架构、车载嵌入式时序数据库的技术挑战和方案等议题。本次主题活动现场氛围热烈,吸引了众多技术爱好者积极参与,下面让我们一起回顾本次活动的精彩看点。

一、AutoMQ 多云原生再升级:多模态共享存储架构
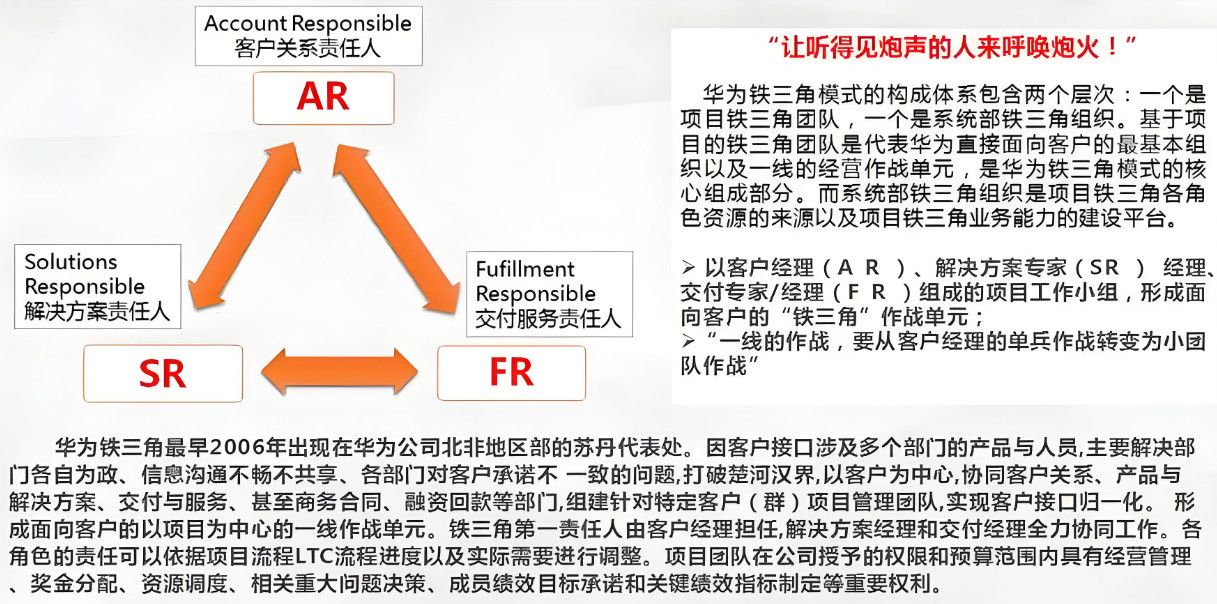
AutoMQ CTO&联合创始人周新宇从 kafka 的生态位及面临的挑战出发,深入剖析了 AutoMQ 共享存储架构,多云的最佳实践,讲解了共享存储架构的技术优势,并对未来进行展望。
AutoMQ 共享存储架构
架构重构和存储分离:AutoMQ 重新设计了 Kafka 的架构,将存储分离到云存储(S3)上,通过 S3 Stream 实现,使计算层完全无状态。
存储选择和优势:提到了选择 EBS 和 S3 作为存储解决方案的考虑,EBS 用于低延迟高性能需求,S3 作为简单可靠的选择,适用于不那么高实时性要求的场景。
共享存储架构设计:结合了 WAL 和 S3 对象存储,确保了数据的持久性和高可靠性,提升了整体架构的弹性和稳定性。
自动化运维和优化:控制面设计 Auto scaling 和 AutoBalaning 组件,能够实现秒级扩缩容和实时流量平衡。
AutoMQ 最佳实践:阿里云、Azure、GCP 、AWS
在阿里云、Azure、GCP云上,推荐使用 Regional EBS ,因其成本性能 trade off 好,可跨 AZ多重挂载,故障时由其他 AZ 的 broker 恢复。
在 AWS 上,由于 AWS 没有 Regional EBS 形态,为实现多 AZ 的 AutoMQ 部署,采用同步双写两个 WAL 组合 EBS WAL 和 S3 Express WAL,避免自定义网络通道复制及高昂的复制流量成本。还有一种形态是完全选择 S3 WAL,价格精简,但延迟较高,适用于 EBS 能力不足的云厂商或私有云场景,架构简单,运维方便。
AutoMQ 技术优势
成本节约:通过对象存储取代 EBS,存储成本可降低至 7 到 10 倍;无需复制带来的计算资源节省约 2/3,实现十倍成本优势。
运维效率提升:分区迁移时间由传统的数小时缩短至仅需几秒钟,大幅简化扩容和流量均衡操作。
兼容性与部署选择:百分之百兼容现有版本,提供全托管 SaaS 和 BYOC 两种部署形态,灵活满足用户需求。

二、长城汽车多云多活架构的实践与探索
长城汽车的研发总监陈天予老师不仅展示了长城汽车在新能源汽车领域的技术创新,还介绍了他们在面对 IT 挑战时的解决方案。特别是在云计算和服务化架构方面,他们通过多云策略和双活架构,成功地应对了企业在数字化转型过程中的复杂性和挑战。
长城汽车“多云多活”解决方案
长城提出了“同城双活”的解决方案,旨在应对云服务的可靠性和灵活性问题:
多云多活的重要性:这不仅仅是为了应对云服务商的故障,更是为了确保长城汽车在任何时候都能够提供稳定可靠的服务,通过在多家云厂商间建立接入点,实现了跨云架构,提高了系统的容错能力和稳定性。
多朵云的选择与管理:长城不再简单地将工作负载迁移到另一个云平台,而是积极利用不同云厂商的特点和优势,通过全网数据流量调度和服务化管理,确保系统的高可用性和性能优化。
控制面与数据面分离:长城实现了控制面和数据面的分离,这样即使一个云平台的控制面出现问题,数据面依然可以独立运行,从而避免了全面的系统故障。
AutoMQ在长城的实践
MQ 在跨云场景的使用痛点:传统的 MQ 产品在云厂商之间的数据同步困难重重,实现有效的云端稳定性保障和跨云迁移,需要额外的数据同步工具或自建解决方案。
AutoMQ 跨云解决方案的关键性:AutoMQ 具有控制面与数据面分离的优势,作为解决跨云数据同步难题的关键解决方案。

三、One database, two sides: GreptimeDB 边云一体化数据库介绍
GreptimeDB 首席研发工程师罗傅聪老师演讲涵盖智能汽车数据的价值和挑战,深入剖析了 GreptimeDB 车云一体化数据库,并介绍在某车企的实际应用案例。
智能汽车数据的价值与挑战
价值:智能汽车数据包含丰富的驾驶前、中、后数据,可以提供全面的驾驶分析和优化。挑战:
数据使用成本高,主要包括存储成本、车端上传成本和云端计算成本。
车端信号收集面临精度和空间占用的难以兼得问题。
HTTP 上传在 4G/5G 网络条件下流量费用昂贵。
** Greptime DB 车云一体化数据库**
车端使用 GreptimeDB Edge 版本数据库,具备毫秒级信号精度和低资源占用优势。利用 GreptimeDB Edge 的 SSD 文件和高效压缩算法,实现数据上传流量节省。
Greptime Ingester 简化数据合并与导入,优化云端的计算与开发成本。
GreptimeDB Cloud 云原生数据库,存算分离,Share Storage 架构 ,数据实时性从天级别降低到秒级别。
** 某车企实践经验**
吞吐量测试结果:
单车 20 分钟内上传 700 多个 SST 文件,云端导入耗时仅 7 秒。
总计 5.6 亿个信号点的同步处理吞吐量达到 8000 万点/秒,实现毫秒级的数据同步与分析。
成功为客户节省数亿元人民币的流量和存储成本,提升数据精度从秒级到毫秒级,查询时效降低到秒级。

四、小红书深度解读 AutoMQ 云原生及多云容灾架构
小红书消息引擎专家黄章衡老师详细介绍了小红书 Kafka 云原生架构,讲解了 AutoMQ 的云原生及多云容灾架构,并最后展望了小红书消息团队与 AutoMQ 社区共探云原生消息引擎,共建健康活跃社区。
小红书云原生方案
分层存储:引入弹性的云原生架构,如分层存储架构,将近实时的热数据存储在本地云盘,历史数据卸载到对象存储。这一调整显著降低存储成本,并提升了机器扩展能力。
容器化:采用容器化部署方案,通过 Kubernetes 屏蔽底层云差异,提升了混部能力和调度效率。容器化技术还能填平 CPU 利用率低谷,优化计算资源利用率。
AutoMQ 云原生架构
AutoMQ 核心架构,分为三个关键部分:
S3 Stream:由 EBS 和对象存储组成,提供低延迟、高存储容量。
Broker:内嵌于 Essential 中,负责数据的读写操作,支持秒级关机和自动扩缩容。
控制面:负责监听集群水位线,实现流量自动平衡和扩缩容。
他针对 S3 Stream 做了详细讲解,S3 Stream 存储模型支持无限流式数据的位点读写,通过预写日志和对象存储确保数据持久性。
AutoMQ 多云容灾方案
秒级分区迁移的容灾方案:AutoMQ 通过云盘的多重挂载机制实现秒级分区迁移的容灾方案。在分区迁移时,数据首先上传到对象存储,然后在其他 Broker 上恢复元数据,实现无数据迁移的数据恢复。
多种容灾机制的应用:AutoMQ 使用多种容灾机制应对不同云平台的需求,如云盘挂载机制、Fengcing 机制等,确保在节点故障时数据安全和系统稳定性。

五、车载嵌入式时序数据库的技术挑战和方案
GreptimeDB 研发工程师黄磊聚焦于车载嵌入式时序数据库,首先介绍了车载嵌入式实时数据库的价值和挑战,讲解了 GreptimeDB 存储系统,重点介绍了 GreptimeDB Edge 优化经验。
GreptimeDB Edge 优化经验
CPU 优化:
包括平均 CPU 和峰值 CPU 的优化。通过 SST 编码优化不同列和数据类型的数据压缩和编码方式;通过 Flush 节控制峰值 CPU。
优化协议解析,确保 SDK 和 DB 侧的数据编解码过程高效。
内存优化:
- 在车端数据库中,使用基于时间序列的 Memtable 数据结构替代传统的 LSM 结构,有效减少内存占用和数据膨胀问题,同时保证了性能。
IO 优化:
基于车机闪存特点优化,包括按表粒度开关 WAL、考虑车端数据特点优化 Compaction 等。
优化 IPC 引入的 IO,解决安卓平台通信问题,实现无额外写盘操作,IO 情况显著优化。
稳定性方面(rust / C FFI 实践):
因 C++依赖管理问题,用 Rust 重写 SDK 并提供 FFI 胶水层。
带来收益:Cargo 便捷的工程管理、交叉编译简单、内存管理提升排查效率。

最后,感谢本次活动各位嘉宾的精彩演讲,也感谢线下和线上的小伙伴积极参与!更多 meetup 活动也在筹备中,期待小伙伴们参与!
资源分享
在AutoMQ公众号后台回复“新能源汽车”或点击下方原文链接可获得本次meetup 讲师 PPT 链接;活动直播录屏在 B 站和视频号发布。
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com?utm_source=openwrite
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ