文章目录
- 前言
- Filebeat Configmap 配置
- Filebeat Deployment
- 验证
- 总结
前言
在上篇文章中总结了 Django 日志控制台输出、文件写入按天拆分文件,自定义 Filter 增加 trace_id 以及过滤——日志处理(一),将日志以 JSON 格式写入日志文件。
我们的项目服务是部署在 k8s 上的,日志是挂载在 PVC 中的,接下来我们需要使用 Filebeat 去采集 PVC 中的日志,发送至 kafka 中,本文将总结如何在 k8s 上部署 Filebeat, 来采集 PVC 中的日志。
Filebeat Configmap 配置
使用 k8s 的 configmap 来保存 Filebeat 的配置信息:
apiVersion: v1
kind: ConfigMap
metadata:name: filebeat-config
data:filebeat.yml: |-filebeat.inputs:- type: logenabled: truepaths:# 日志文件路径- /home/dfuser/addcdata/logs/*.logoutput.kafka:# kafka 集群的连接地址hosts: ["kafka.cluster.address:9092"]# 将要发送的 kafka topic, 注意确保该 topic 存在topic: "filebeat_logs"# 连接 kafka 的用户名和密码username: "admin"password: "admin"sasl.mechanism: PLAINcompression: gzip# 这里可以将 timeout 设置长一点,默认好像是几秒timeout: 60sbroker_timeout: 60sretry.backoff: 5s# 日志消息的发送响应要求一般不会特别高,设置为 1就够了required_acks: 1max_message_bytes: 104857600channel_buffer_size: 256keep_alive: 30s- 配置文件中定义了 input 信息:采集日志文件路径,以及 output 信息:kafka 连接配置信息等。
关于kafka Producer 配置信息不太熟悉的可以看我之前写的这篇文章:
kafka 生产者 API 实践总结
Filebeat Deployment
apiVersion: apps/v1
kind: Deployment
metadata:labels:workload.user.cattle.io/workloadselector: apps.deployment-addcdata-filebeatname: filebeatnamespace: addcdata
spec:replicas: 1selector:matchLabels:workload.user.cattle.io/workloadselector: apps.deployment-addcdata-filebeattemplate:metadata:labels:workload.user.cattle.io/workloadselector: apps.deployment-addcdata-filebeatnamespace: addcdataspec:containers:- name: filebeatresources:limits:memory: 3000Miimage: elastic/filebeat:7.6.2args: [ "-e", "-c", "/etc/filebeat/filebeat.yml" ]volumeMounts:- mountPath: /home/dfuser/addcdata/logsname: addcdata-logs-pvcsubPath: logs- name: filebeat-configmountPath: /etc/filebeat/filebeat.ymlsubPath: filebeat.ymlimagePullSecrets:- name: addcdata-harborrestartPolicy: AlwaysterminationGracePeriodSeconds: 30volumes:- name: addcdata-logs-pvcpersistentVolumeClaim:claimName: addcdata-pvc- name: filebeat-configconfigMap:name: filebeat-config
- 这里挂载了两个 volumes:
- addcdata-pvc: 是我们项目在 k8s 上挂载日志的 PVC,其中日志挂载在 /home/dfuser/addcdata/logs 目录下
- filebeat-config:是上边 Filebeat 的configMap 配置名称
- 这里我们使用的镜像是
elastic/filebeat:7.6.2,这个是官方的,没有外网可能不好拉取,我把该镜像上传至了阿里云的镜像仓库,可以从该地址拉取:registry.cn-shenzhen.aliyuncs.com/zhouzy_space/filebeat:7.6.2, 从阿里云镜像仓库拉取 docker 需要先登录阿里云仓库。
验证
如果我们的配置正确,并且上边的 Deployment 部署成功,通过查看 Filebeat Pod 日志如下: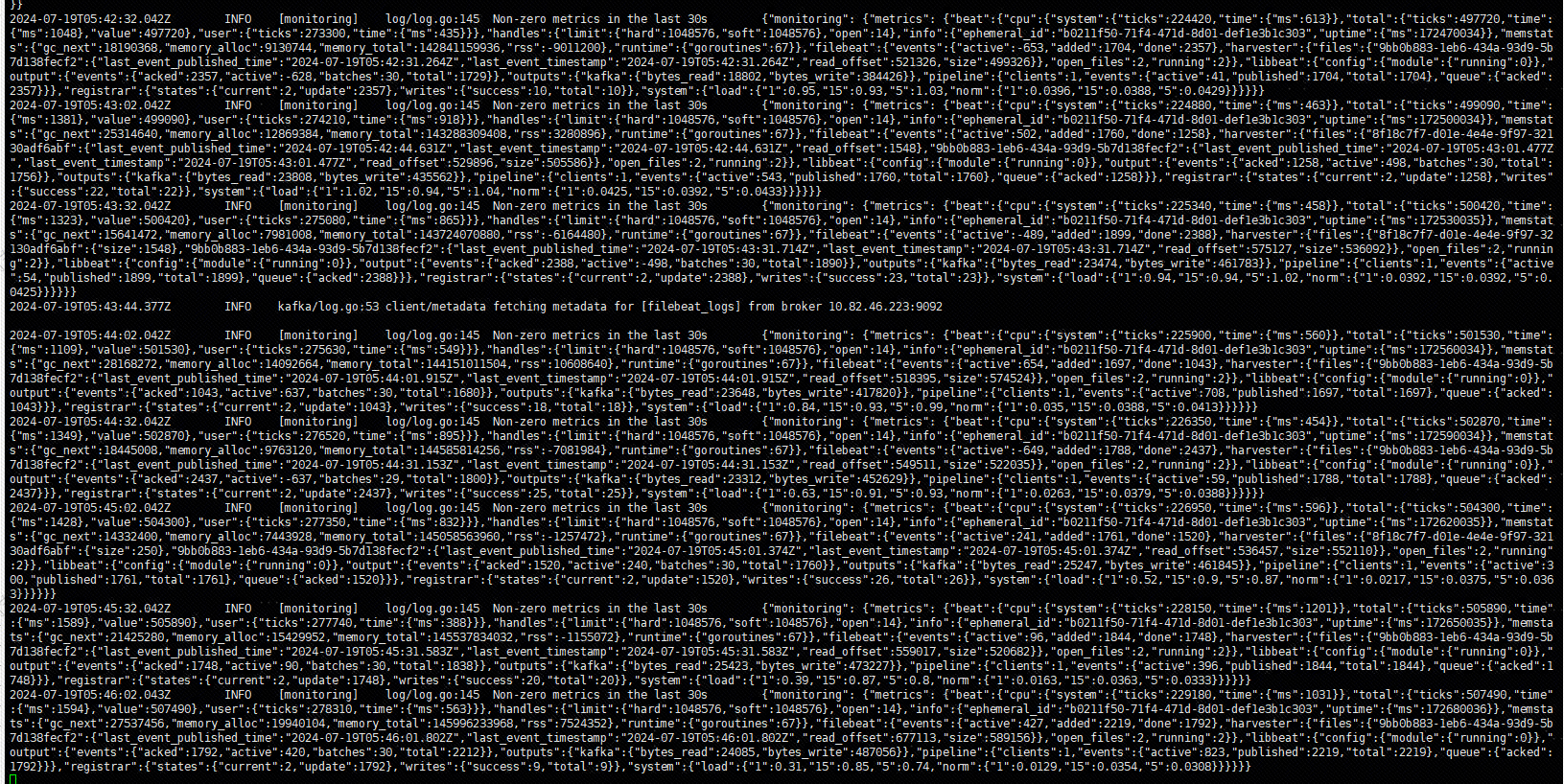
如果我们的 kafka 配置不正确或者网络连接不上,日志会报错误信息。
接下来我们通过 CMAK 看下 kafka 的 Topic 是否写入: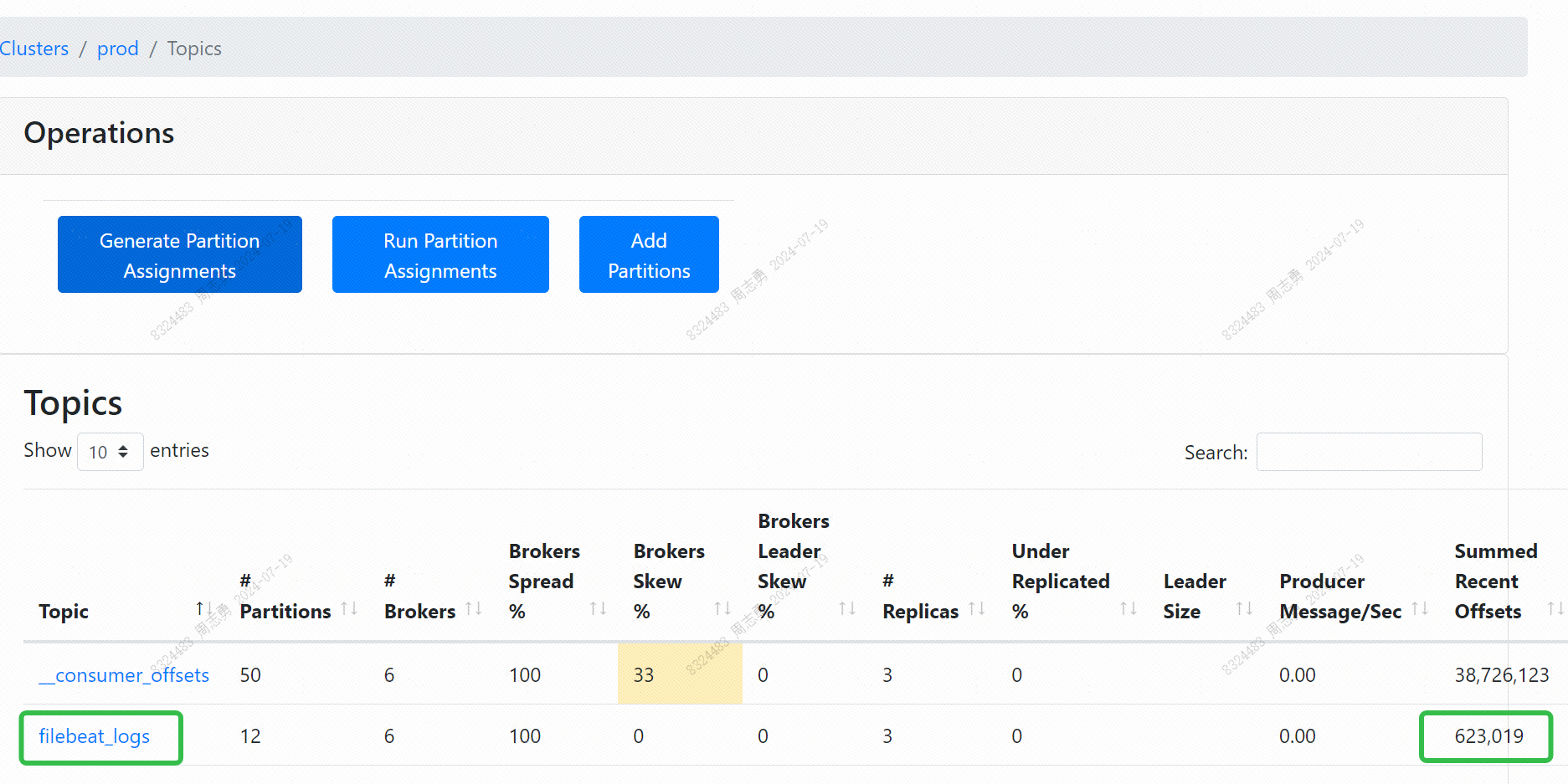
可以发现已经有消息写入。
我们写个 Python 脚本消费几条数据看下:
将下边脚本的 kafka 连接信息替换为自己的集群信息
from confluent_kafka import Consumer, KafkaExceptiondef consume_messages(topic):# 创建 Kafka 消费者配置conf = {'bootstrap.servers': 'kafka.address:9092', # Kafka 服务器地址'group.id': 'my-consumer-group', # 消费者组ID'auto.offset.reset': 'earliest', # 自动重置偏移量'enable.auto.commit': False, # 禁用自动提交偏移量'session.timeout.ms': 6000, # 会话超时时间}# 如果 Kafka 启用了 SASL 认证,添加 SASL 相关配置conf.update({'security.protocol': 'SASL_PLAINTEXT','sasl.mechanism': 'PLAIN','sasl.username': 'admin','sasl.password': 'admin',})consumer = Consumer(conf)try:consumer.subscribe([topic])while True:msg = consumer.poll(1.0) # 每秒轮询一次if msg is None:continueif msg.error():raise KafkaException(msg.error())else:print('Received message: {}'.format(msg.value().decode('utf-8')))except KeyboardInterrupt:passfinally:consumer.close()if __name__ == '__main__':topic = 'filebeat_logs' # 你的 Kafka 主题名称consume_messages(topic)
下边放几条看下:
Received message: {"@timestamp":"2024-07-19T03:31:24.040Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.6.2"},"log":{"offset":32682537,"file":{"path":"/home/dfuser/addcdata/logs/info.log"}},"input":{"type":"log"},"ecs":{"version":"1.4.0"},"host":{"name":"filebeat-7674bf8777-kdhs2"},"agent":{"ephemeral_id":"b0211f50-71f4-471d-8d01-def1e3b1c303","hostname":"filebeat-7674bf8777-kdhs2","id":"edaefbbb-2d08-4b6c-95aa-46ebdbebd0cc","version":"7.6.2","type":"filebeat"},"message":"{\"time\": \"2024-07-19 11:31:23\", \"thread\": \"ThreadPoolExecutor-0_14\", \"level\": \"INFO\", \"func\": \"apps.data_report.views.views.report_data_v1:65\", \"trace_id\": \"9794977c-c8f5-4f75-a450-655eda5f58c4\", \"message\": \"======================\"}"}
Received message: {"@timestamp":"2024-07-19T03:31:25.043Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.6.2"},"host":{"name":"filebeat-7674bf8777-kdhs2"},"agent":{"ephemeral_id":"b0211f50-71f4-471d-8d01-def1e3b1c303","hostname":"filebeat-7674bf8777-kdhs2","id":"edaefbbb-2d08-4b6c-95aa-46ebdbebd0cc","version":"7.6.2","type":"filebeat"},"log":{"offset":32689465,"file":{"path":"/home/dfuser/addcdata/logs/info.log"}},"message":"{\"time\": \"2024-07-19 11:31:24\", \"thread\": \"ThreadPoolExecutor-0_4\", \"level\": \"INFO\", \"func\": \"apps.data_report.views.views.report_data_v1:64\", \"trace_id\": \"26c55b5c-a660-4420-ab27-72e7cf9d1f1a\", \"message\": \"params: <QueryDict: {'car_type': ['H97C'], 'path': ['H97C/2024071911/LDP95H966PE302771/204_31da1b2e254481914d851f9740a1f580_1721351130419507_slave/31da1b2e254481914d851f9740a1f580_1_1_1721354458372069_1.data'], 'env': ['prod'], 'sync': ['0']}>\"}","input":{"type":"log"},"ecs":{"version":"1.4.0"}}
Received message: {"@timestamp":"2024-07-19T03:31:25.043Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.6.2"},"message":"{\"time\": \"2024-07-19 11:31:24\", \"thread\": \"ThreadPoolExecutor-0_38\", \"level\": \"INFO\", \"func\": \"apps.data_report.views.views.report_data_v1:63\", \"trace_id\": \"7f754755-fb70-4212-9a80-55ba19f5e5c9\", \"message\": \"=====data report======\"}","log":{"offset":32695607,"file":{"path":"/home/dfuser/addcdata/logs/info.log"}},"input":{"type":"log"},"ecs":{"version":"1.4.0"},"host":{"name":"filebeat-7674bf8777-kdhs2"},"agent":{"ephemeral_id":"b0211f50-71f4-471d-8d01-def1e3b1c303","hostname":"filebeat-7674bf8777-kdhs2","id":"edaefbbb-2d08-4b6c-95aa-46ebdbebd0cc","version":"7.6.2","type":"filebeat"}}
可以发现 filebeat 采集我们的日志往 kafka 里发的时候,会加上一些它自己的字段信息,比如说 timestamp, metadata 等,但是我们并不关心这些信息,我们最需要的是 message 字段,也就是我们自己的日志信息:
总结
filebeat 的 k8s 部署还是比较简单的,只需要部署一个 configmap,通过部署一个 Deployment 就可以采集我们 PVC 中的日志,但是需要确保我们的 kafka 配置信息正确 (确保写入 Topic 存在) 和日志挂载路径一致。
网上很多都是通过 DaemonSet 或者 sidecar 的方式部署 Filebeat,个人觉得没必要,太过复杂,只要我们的日志是挂载到 PVC 中的,简单部署一个 Deployment 就足够了,目前我们的服务每天会产生百万条日志,都是正常发送至 kafka 的。
日志搜集至 kafka 不是最终目的,我们的最终目标是要能够分析日志,排查问题,以及做出一些指标看板和错误告警等。接下来我会总结,如何使用 Flink SQL 实时的将 kafka 中的日志写入 Clickhouse 进行日志分析,以及如何结合 Superset 使用 Clickhouse 数据源查询日志数据,做出指标看板。

![[米联客-安路飞龙DR1-FPSOC] FPGA基础篇连载-21 VTC视频时序控制器设计](https://i-blog.csdnimg.cn/direct/36ce48ed26124261a253fdee8a1ad037.png)