11种API性能优化方法
一、索引优化
接口性能优化时,大家第一个想到的通常是:优化索引,优化索引的成本是最小的。
你可以通过查看线上日志或监控报告,发现某个接口使用的某条SQL语句耗时较长。
这条SQL语句是否已经加了索引?
加的索引是否生效了?
MySQL是否选择了错误的索引?
1.1 没加索引
在SQL语句中,忘记为WHERE条件的关键字段或ORDER BY后的排序字段加索引是项目中常见的问题。在项目初期,由于表中的数据量较小,加不加索引对SQL查询性能影响不大。然而,随着业务的发展,表中的数据量不断增加,这时就必须加索引了。
可以通过以下命令查看/添加索引:
show index from `table_name`
CREATE INDEX index_name ON table_name (column_name);
这种方式能够显著提高查询性能,尤其是在数据量庞大的情况下。
1.2 索引没生效
通过上述命令我们已经确认索引是存在的,但它是否生效呢?
那么,如何查看索引是否生效呢?
可以使用 EXPLAIN 命令,查看 MySQL 的执行计划,它会显示索引的使用情况。
EXPLAIN SELECT * FROM `order` WHERE code='002';
结果:

这个命令将显示查询的执行计划,包括使用了哪些索引。如果索引生效,你会在输出结果中看到相关的信息。通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:
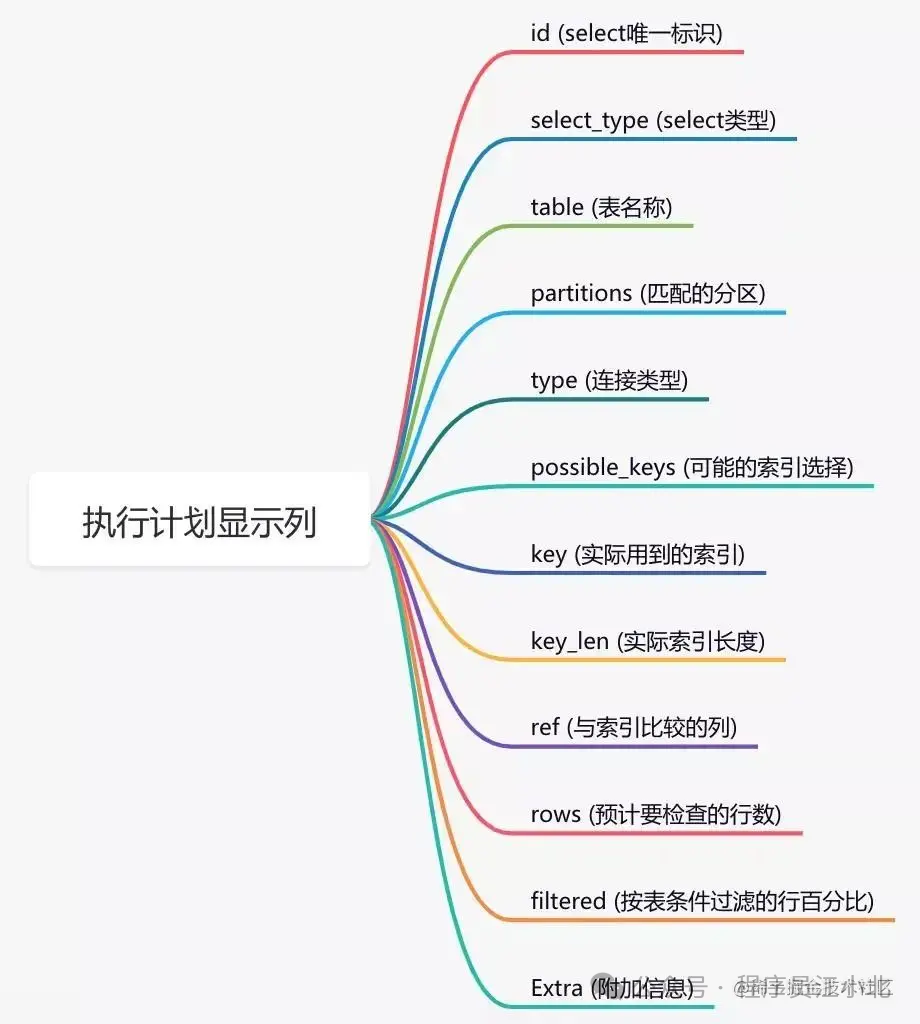
说实话,SQL语句没有使用索引,除去没有建索引的情况外,最大的可能性是索引失效了。
以下是索引失效的常见原因:

了解这些原因,可以帮助你在查询优化时避免索引失效的问题,确保数据库查询性能保持最佳。
1.3 选错索引
此外,你是否遇到过这样一种情况:明明是同一条SQL语句,只是入参不同。有时候使用的是索引A,有时候却使用索引B?
没错,有时候MySQL会选错索引。
必要时可以使用 FORCE INDEX 来强制查询SQL使用某个索引。
例如:
SELECT * FROM `order` FORCE INDEX (index_name) WHERE code='002';
至于为什么MySQL会选错索引,原因可能有以下几点:
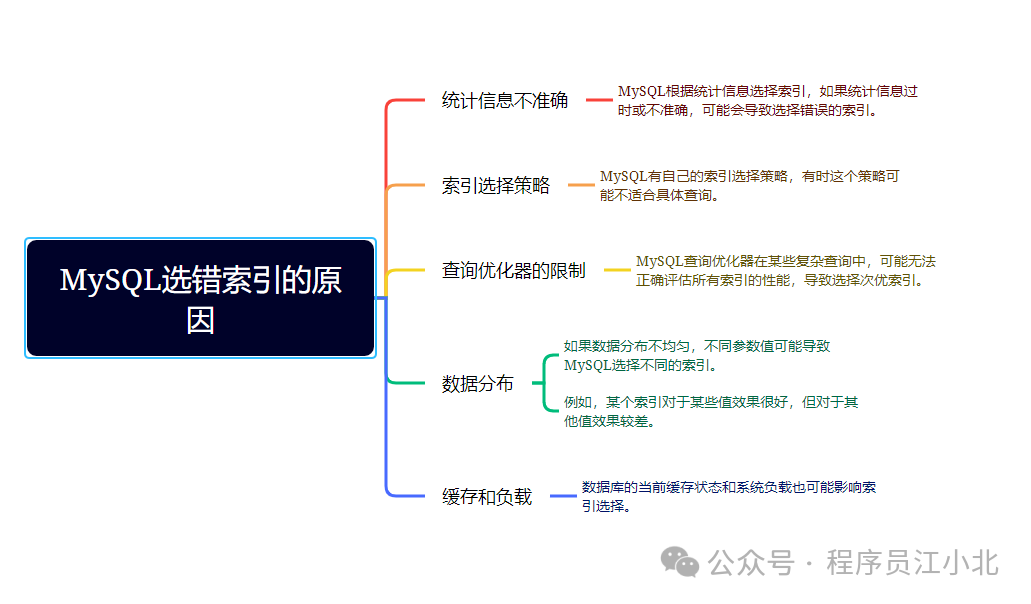
了解这些原因,可以帮助你更好地理解和控制MySQL的索引选择行为,确保查询性能的稳定性。
二、SQL优化
如果优化了索引之后效果不明显,接下来可以尝试优化一下SQL语句,因为相对于修改Java代码来说,改造SQL语句的成本要小得多。以下是SQL优化的15个小技巧:

三、远程调用
多时候,我们需要在一个接口中调用其他服务的接口。
在用户信息查询接口中需要返回以下信息:用户名称、性别、等级、头像、积分和成长值。其中,用户名称、性别、等级和头像存储在用户服务中,积分存储在积分服务中,成长值存储在成长值服务中。为了将这些数据统一返回,我们需要提供一个额外的对外接口服务。因此,用户信息查询接口需要调用用户查询接口、积分查询接口和成长值查询接口,然后将数据汇总并统一返回。
调用过程如下图所示:
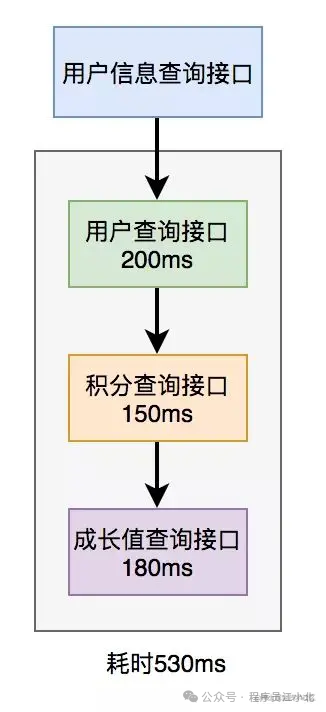
调用远程接口总耗时 530ms = 200ms + 150ms + 180ms
显然这种串行调用远程接口性能是非常不好的,调用远程接口总的耗时为所有的远程接口耗时之和。
那么如何优化远程接口性能呢?
3.1 串行改并行
上面说到,既然串行调用多个远程接口性能很差,为什么不改成并行呢?调用远程接口的总耗时为200ms,这等于耗时最长的那次远程接口调用时间。
在Java 8之前,可以通过实现Callable接口来获取线程的返回结果。在Java 8之后,可以通过CompletableFuture类来实现这一功能。
以下是一个使用CompletableFuture的示例:
public class RemoteServiceExample {public static void main(String[] args) throws ExecutionException, InterruptedException {// 调用用户服务接口CompletableFuture<String> userFuture = CompletableFuture.supplyAsync(() -> {// 模拟远程调用simulateDelay(200);return "User Info";});// 调用积分服务接口CompletableFuture<String> pointsFuture = CompletableFuture.supplyAsync(() -> {// 模拟远程调用simulateDelay(150);return "Points Info";});// 调用成长值服务接口CompletableFuture<String> growthFuture = CompletableFuture.supplyAsync(() -> {// 模拟远程调用simulateDelay(100);return "Growth Info";});// 汇总结果CompletableFuture<Void> allOf = CompletableFuture.allOf(userFuture, pointsFuture, growthFuture);// 等待所有异步操作完成allOf.join();// 获取结果String userInfo = userFuture.get();String pointsInfo = pointsFuture.get();String growthInfo = growthFuture.get();}
}3.2 数据异构
为了提升接口性能,尤其在高并发场景下,可以考虑数据冗余,将用户信息、积分和成长值的数据统一存储在一个地方,比如Redis。
这样,通过用户ID可以直接从Redis中查询所需的数据,从而避免远程接口调用
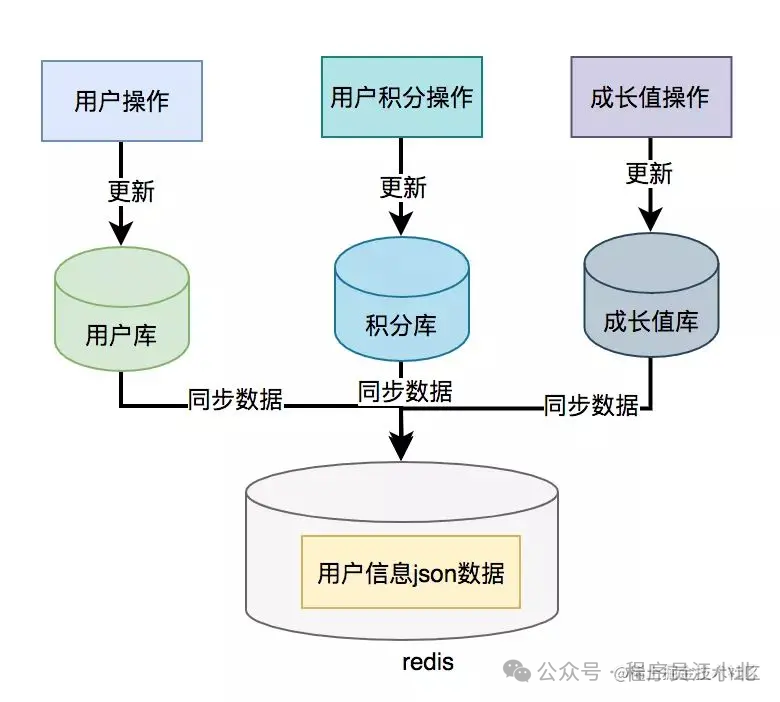
但需要注意的是,如果使用了数据异构方案,就可能会出现数据一致性问题。用户信息、积分和成长值有更新的话,大部分情况下,会先更新到数据库,然后同步到redis。但这种跨库的操作,可能会导致两边数据不一致的情况产生。
那如何解决数据一致性问题呢?
《亿级电商流量,高并发下Redis与MySQL的数据一致性如何保证》
四、重复调用
在我们的日常工作代码中,重复调用非常常见,但如果没有控制好,会严重影响接口的性能。
4.1 循环查数据库 有时候,我们需要从指定的用户集合中查询出哪些用户已经存在于数据库中。
public List<User> findExistingUsers(List<String> userIds) {List<User> existingUsers = new ArrayList<>();for (String userId : userIds) {User user = userRepository.findById(userId);if (user != null) {existingUsers.add(user);}}return existingUsers;
}上述代码会对每个用户ID执行一次数据库查询,这在用户集合较大时会导致性能问题。
那么,我们如何优化呢?
我们可以通过批量查询来优化性能,减少数据库的查询次数。
public List<User> findExistingUsers(List<String> userIds) {// 批量查询数据库List<User> users = userRepository.findByIds(userIds);return users;
}这里有个需要注意的地方是:id集合的大小要做限制,最好一次不要请求太多的数据。要根据实际情况而定,建议控制每次请求的记录条数在500以内。
五、异步处理
在进行接口性能优化时,有时候需要重新梳理业务逻辑,检查是否存在设计不合理的地方。假设有一个用户请求接口,需要执行以下操作:
-
业务操作
-
发送站内通知
-
记录操作日志 为了实现方便,通常会将这些逻辑放在接口中同步执行,但这会对接口性能造成一定影响。
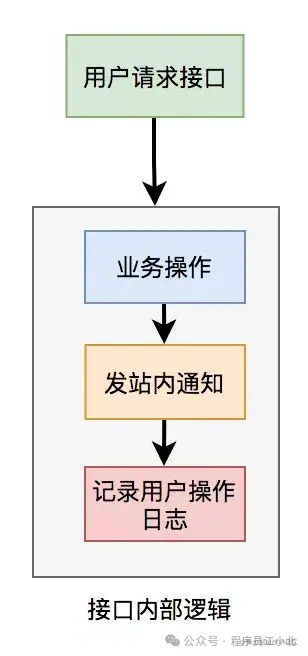
这个接口表面上看起来没有问题,但如果你仔细梳理一下业务逻辑,会发现只有业务操作才是核心逻辑,其他的功能都是非核心逻辑。在这里有个原则就是:
核心逻辑可以同步执行,同步写库。非核心逻辑,可以异步执行,异步写库。
上面这个例子中,发站内通知和用户操作日志功能,对实时性要求不高,即使晚点写库,用户无非是晚点收到站内通知,或者运营晚点看到用户操作日志,对业务影响不大,所以完全可以异步处理。
异步处理通常有两种主要方式:多线程和消息队列(MQ)
5.1 线程池异步优化
使用线程池改造之后,接口逻辑如下
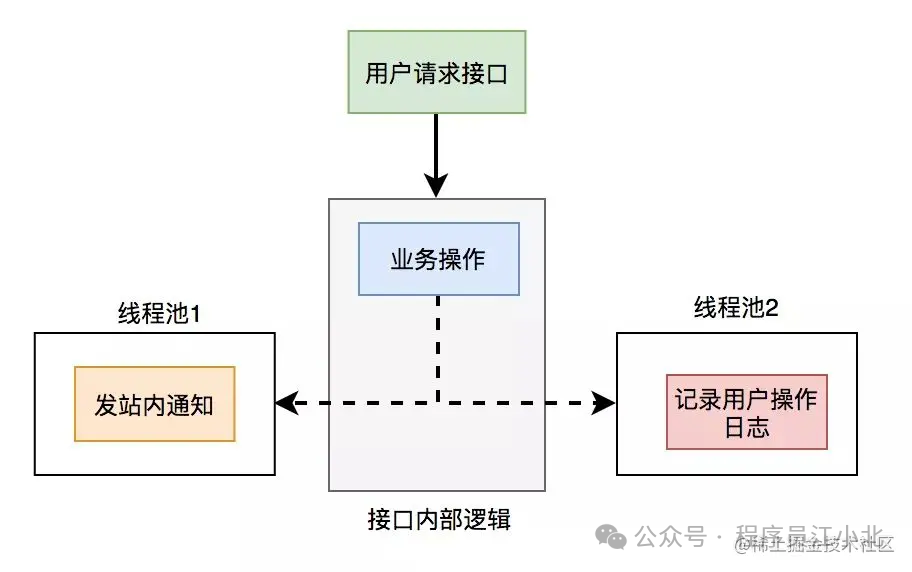
5.2 MQ异步
使用线程池有个小问题就是:如果服务器重启了,或者是需要被执行的功能出现异常了,无法重试,会丢数据。
为了避免使用线程池处理异步任务时出现数据丢失的问题,可以考虑使用更加健壮和可靠的异步处理方案,如消息队列(MQ)。消息队列不仅可以异步处理任务,还能够保证消息的持久化和可靠性,支持重试机制。
使用mq改造之后,接口逻辑如下:
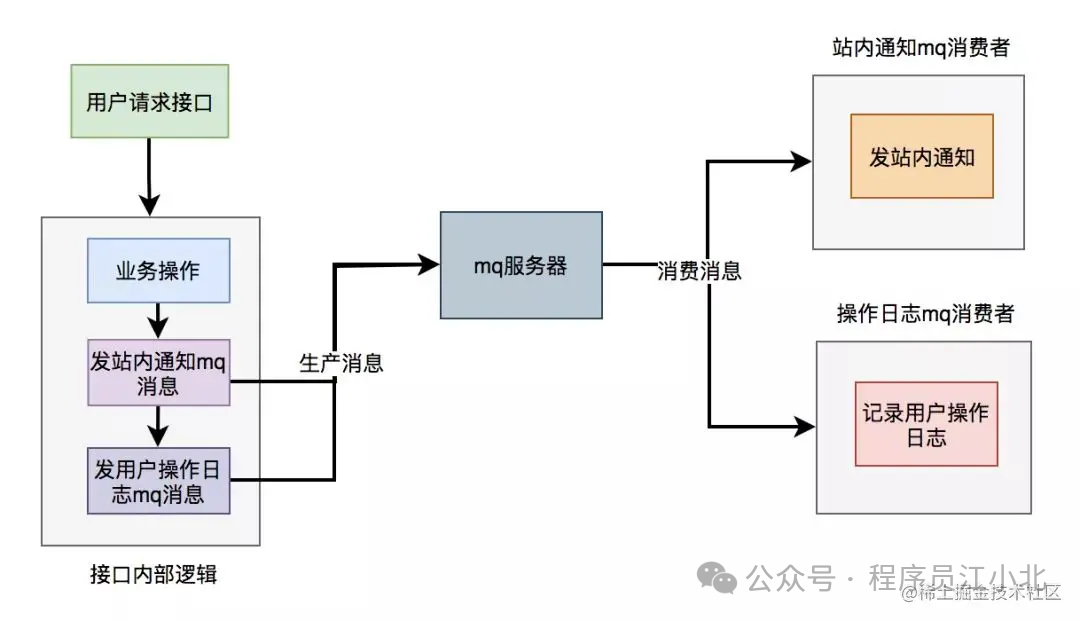
六、避免大事务
使用@Transactional注解这种声明式事务的方式提供事务功能,确实能少写很多代码,提升开发效率。但也容易造成大事务,引发性能的问题。
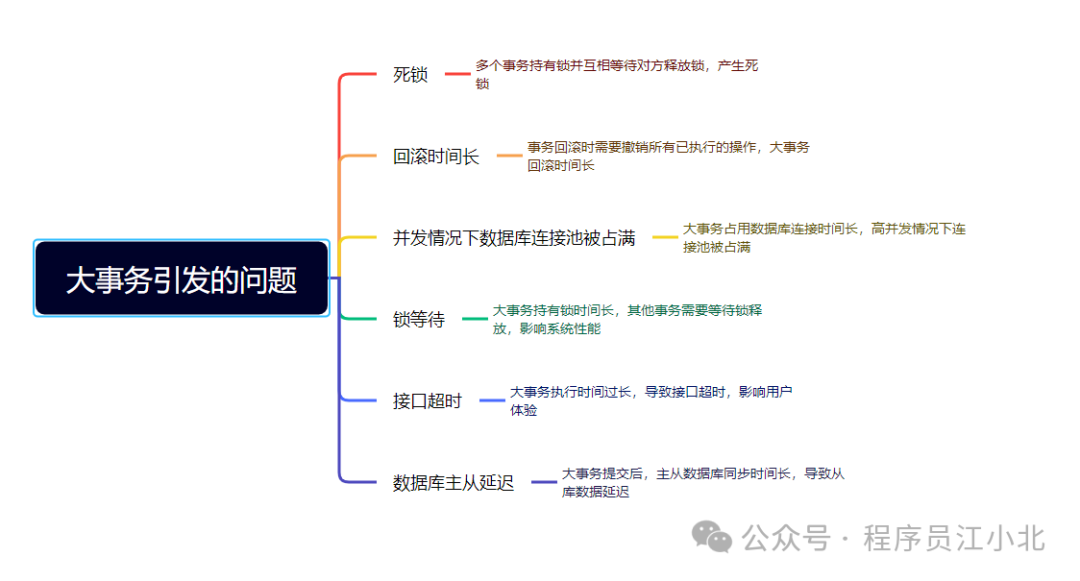
那么我们该如何优化大事务呢?
为了避免大事务引发的问题,可以考虑以下优化建议:
-
少用@Transactional注解
-
将查询(select)方法放到事务外
-
事务中避免远程调用
-
事务中避免一次性处理太多数据
-
有些功能可以非事务执行
-
有些功能可以异步处理
七、锁粒度
在一些业务场景中,为了避免多个线程并发修改同一共享数据而引发数据异常,通常我们会使用加锁的方式来解决这个问题。然而,如果锁的设计不当,导致锁的粒度过粗,也会对接口性能产生显著的负面影响。
7.1 synchronized
在Java中,我们可以使用synchronized关键字来为代码加锁。
通常有两种写法:在方法上加锁和在代码块上加锁。
1. 方法上加锁
public synchronized void doSave(String fileUrl) {mkdir();uploadFile(fileUrl);sendMessage(fileUrl);
}
在方法上加锁的目的是为了防止并发情况下创建相同的目录,避免第二次创建失败而影响业务功能。但这种直接在方法上加锁的方式,锁的粒度较粗。
因为doSave方法中的文件上传和消息发送并不需要加锁,只有创建目录的方法需要加锁。我们知道,文件上传操作非常耗时,如果将整个方法加锁,那么需要等到整个方法执行完之后才能释放锁。显然,这会导致该方法的性能下降,得不偿失。
2. 代码块上加锁我们可以将加锁改在代码块上,从而缩小锁的粒度, 如下:
public void doSave(String path, String fileUrl) {synchronized(this) {if (!exists(path)) {mkdir(path);}}uploadFile(fileUrl);sendMessage(fileUrl);
}
这样改造后,锁的粒度变小了,只有并发创建目录时才加锁。创建目录是一个非常快的操作,即使加锁对接口性能的影响也不大。最重要的是,其他的文件上传和消息发送功能仍然可以并发执行。
多节点环境中的问题 在单机版服务中,这种做法没有问题。但在生产环境中,为了保证服务的稳定性,同一个服务通常会部署在多个节点上。如果某个节点挂掉,其他节点的服务仍然可用。
多节点部署避免了某个节点挂掉导致服务不可用的情况,同时也能分摊整个系统的流量,避免系统压力过大。
但这种部署方式也带来了新的问题:synchronized只能保证一个节点加锁有效。
如果有多个节点,如何加锁呢?
7.2 Redis分布式锁
在分布式系统中,由于Redis分布式锁的实现相对简单且高效,因此它在许多实际业务场景中被广泛采用。
使用Redis分布式锁的伪代码如下:
public boolean doSave(String path, String fileUrl) {try {String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);if ("OK".equals(result)) {if (!exists(path)) {mkdir(path);uploadFile(fileUrl);sendMessage(fileUrl);}return true;}} finally {unlock(lockKey, requestId);}return false;
}
与之前使用synchronized关键字加锁时一样,这里的锁的范围也太大了,换句话说,锁的粒度太粗。这会导致整个方法的执行效率很低。
实际上,只有在创建目录时才需要加分布式锁,其余代码不需要加锁。于是,我们需要优化代码:
public void doSave(String path, String fileUrl) {if (tryLock()) {try {if (!exists(path)) {mkdir(path);}} finally {unlock(lockKey, requestId);}}uploadFile(fileUrl);sendMessage(fileUrl);
}private boolean tryLock() {String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);return "OK".equals(result);
}private void unlock(String lockKey, String requestId) {// 解锁逻辑
}
上面的代码将加锁的范围缩小了,只有在创建目录时才加锁。这样的简单优化后,接口性能可以得到显著提升。
7.3 数据库锁
MySQL数据库中的三种锁
-
表锁:
-
优点:加锁快,不会出现死锁。
-
缺点:锁定粒度大,锁冲突的概率高,并发度最低。
-
-
行锁:
-
优点:锁定粒度最小,锁冲突的概率低,并发度最高。
-
缺点:加锁慢,会出现死锁。
-
-
间隙锁:
-
优点:锁定粒度介于表锁和行锁之间。
-
缺点:开销和加锁时间介于表锁和行锁之间,并发度一般,也会出现死锁。
-
锁与并发度
并发度越高,接口性能越好。因此,数据库锁的优化方向是:
-
优先使用行锁
-
其次使用间隙锁
-
最后使用表锁
八、分页处理
有时候,我需要调用某个接口来批量查询数据,例如,通过用户ID批量查询用户信息,然后为这些用户赠送积分。但是,如果一次性查询的用户数量太多,例如一次查询2000个用户的数据,传入2000个用户的ID进行远程调用时,用户查询接口经常会出现超时的情况。
调用代码如下:
List<User> users = remoteCallUser(ids);
众所周知,调用接口从数据库获取数据需要经过网络传输。如果数据量过大,无论是数据获取速度还是网络传输速度都会受到带宽限制,从而导致耗时较长。
那么,这种情况下该如何优化呢?
答案是:分页处理。
将一次性获取所有数据的请求,改为分多次获取,每次只获取一部分用户的数据,最后进行合并和汇总。其实,处理这个问题可以分为两种场景:同步调用和异步调用。
8.1 同步调用
如果在job中需要获取2000个用户的信息,它要求只要能正确获取到数据即可,对获取数据的总耗时要求不高。但对每一次远程接口调用的耗时有要求,不能大于500ms,否则会有邮件预警。这时,我们可以同步分页调用批量查询用户信息接口。
具体示例代码如下:
List<List<Long>> allIds = Lists.partition(ids, 200);for (List<Long> batchIds : allIds) {List<User> users = remoteCallUser(batchIds);
}
代码中我使用了Google Guava工具中的Lists.partition方法,用它来做分页简直太好用了,不然要写一大堆分页的代码。 8.2 异步调用 如果是在某个接口中需要获取2000个用户的信息,需要考虑的因素更多。
除了远程调用接口的耗时,还需要考虑该接口本身的总耗时,也不能超过500ms。这时,使用上面的同步分页请求远程接口的方法肯定是行不通的。那么,只能使用异步调用了。
代码如下:
List<List<Long>> allIds = Lists.partition(ids, 200);final List<User> result = Lists.newArrayList();
allIds.stream().forEach(batchIds -> {CompletableFuture.supplyAsync(() -> {result.addAll(remoteCallUser(batchIds));return Boolean.TRUE;}, executor);
});使用CompletableFuture类,通过多个线程异步调用远程接口,最后汇总结果统一返回。
九、加缓存
通常情况下,我们最常用的缓存是:Redis和Memcached。但对于Java应用来说,绝大多数情况下使用的是Redis,所以接下来我们以Redis为例。
在关系型数据库(例如:MySQL)中,菜单通常有上下级关系。某个四级分类是某个三级分类的子分类,三级分类是某个二级分类的子分类,而二级分类又是某个一级分类的子分类。
这种存储结构决定了,想一次性查出整个分类树并非易事。这需要使用程序递归查询,而如果分类很多,这个递归操作会非常耗时。因此,如果每次都直接从数据库中查询分类树的数据,会是一个非常耗时的操作。
这时我们可以使用缓存。在大多数情况下,接口直接从缓存中获取数据。操作Redis可以使用成熟的框架,比如:Jedis和Redisson等。 使用Jedis的伪代码如下:
String json = jedis.get(key);
if (StringUtils.isNotEmpty(json)) {CategoryTree categoryTree = JsonUtil.toObject(json);return categoryTree;
}
return queryCategoryTreeFromDb();
注意引入缓存之后,我们的系统复杂度就上升了,这时候就会存在数据不一致的问题
《亿级电商流量,高并发下Redis与MySQL的数据一致性如何保证》
十、分库分表
有时候,接口性能受限的并不是其他方面,而是数据库。
当系统发展到一定阶段,用户并发量增加,会有大量的数据库请求,这不仅需要占用大量的数据库连接,还会带来磁盘IO的性能瓶颈问题。此外,随着用户数量的不断增加,产生的数据量也越来越大,一张表可能无法存储所有数据。由于数据量太大,即使SQL语句使用了索引,查询数据时也会非常耗时。那么,这种情况下该怎么办呢?
答案是:需要进行分库分表。
如下图所示:
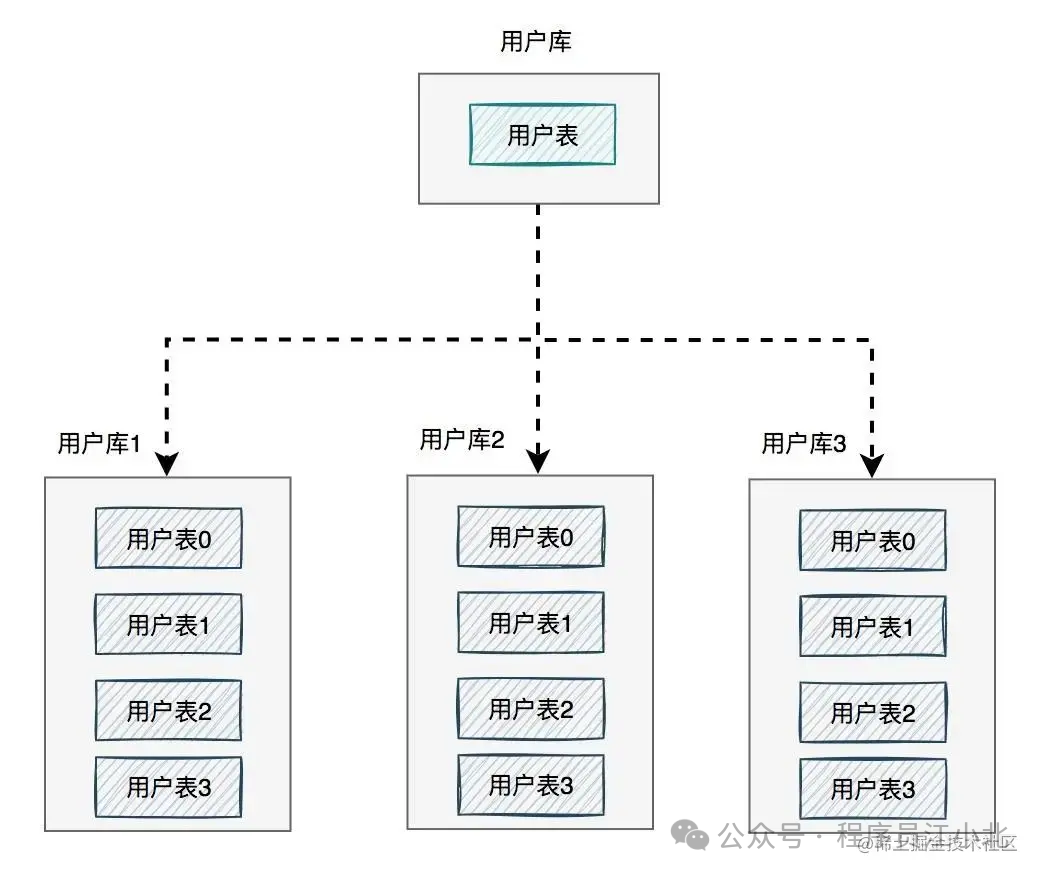
图中将用户库拆分成了三个库,每个库都包含了四张用户表。如果有用户请求过来,先根据用户ID路由到其中一个用户库,然后再定位到某张表。路由的算法有很多:
-
根据ID取模:
-
例如:ID=7,有4张表,则
7%4=3,模为3,路由到用户表3。
-
-
给ID指定一个区间范围:
-
例如:ID的值是0-10万,则数据存在用户表0;ID的值是10-20万,则数据存在用户表1。
-
-
一致性Hash算法。 分库分表主要有两个方向:垂直和水平。
1. 垂直分库分表
垂直分库分表(即业务方向)更简单,将不同的业务数据存储在不同的库或表中。
例如,将用户数据和订单数据存储在不同的库中。
2. 水平分库分表
水平分库分表(即数据方向)上,分库和分表的作用有区别,不能混为一谈。
分库
-
目的:解决数据库连接资源不足问题和磁盘IO的性能瓶颈问题。
分表
-
目的:解决单表数据量太大,SQL语句查询数据时,即使走了索引也非常耗时的问题。此外,还可以解决消耗CPU资源的问题。
分库分表
-
目的:综合解决数据库连接资源不足、磁盘IO性能瓶颈、数据检索耗时和CPU资源消耗等问题。
业务场景中的应用
-
只分库:
-
用户并发量大,但需要保存的数据量很少。
-
-
只分表:
-
用户并发量不大,但需要保存的数据量很多。
-
-
分库分表:
-
用户并发量大,并且需要保存的数据量也很多。
-
十一、监控功能
优化接口性能问题,除了上面提到的这些常用方法之外,还需要配合使用一些辅助功能,因为它们真的可以帮我们提升查找问题的效率。
11.1 开启慢查询日志
通常情况下,为了定位SQL的性能瓶颈,我们需要开启MySQL的慢查询日志。把超过指定时间的SQL语句单独记录下来,方便以后分析和定位问题。
开启慢查询日志需要重点关注三个参数:
-
slow_query_log:慢查询开关
-
slow_query_log_file:慢查询日志存放的路径
-
long_query_time:超过多少秒才会记录日志
通过MySQL的SET命令可以设置:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL slow_query_log_file = '/usr/local/mysql/data/slow.log';
SET GLOBAL long_query_time = 2;
设置完之后,如果某条SQL的执行时间超过了2秒,会被自动记录到slow.log文件中。
当然,也可以直接修改配置文件my.cnf:
[mysqld]
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slow.log
long_query_time = 2但这种方式需要重启MySQL服务。
很多公司每天早上都会发一封慢查询日志的邮件,开发人员根据这些信息优化SQL。
11.2 加监控
为了在出现SQL问题时能够及时发现,我们需要对系统做监控。目前业界使用比较多的开源监控系统是:Prometheus。它提供了监控和预警的功能。
架构图如下:
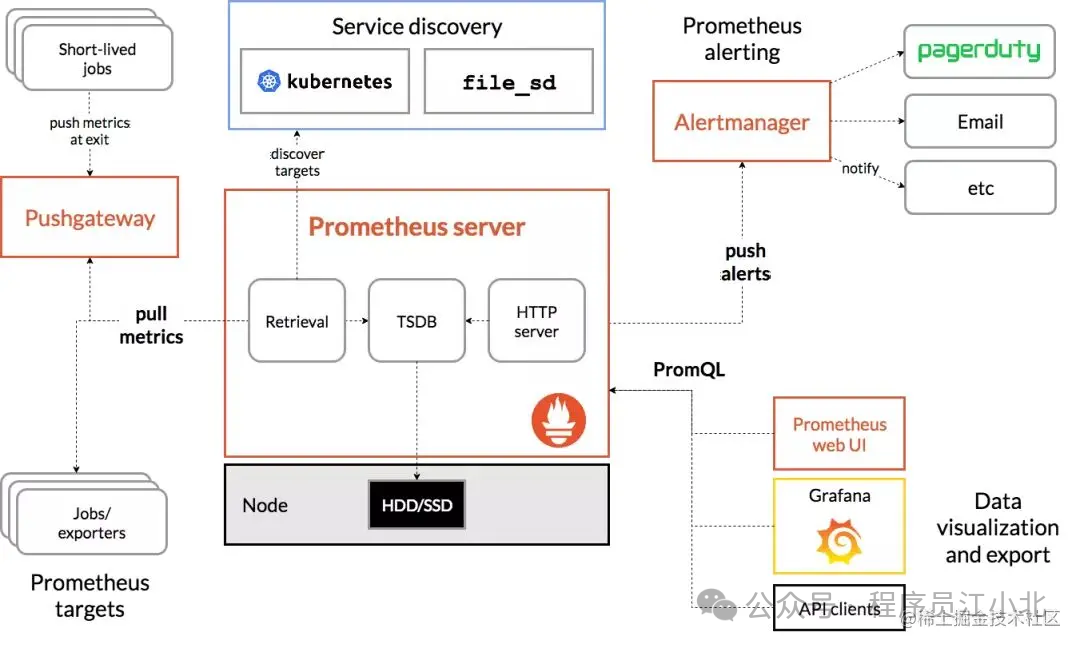
我们可以用它监控如下信息:
-
接口响应时间
-
调用第三方服务耗时
-
慢查询sql耗时
-
cpu使用情况
-
内存使用情况
-
磁盘使用情况
-
数据库使用情况
-
等等。。。
它的界面大概长这样子:
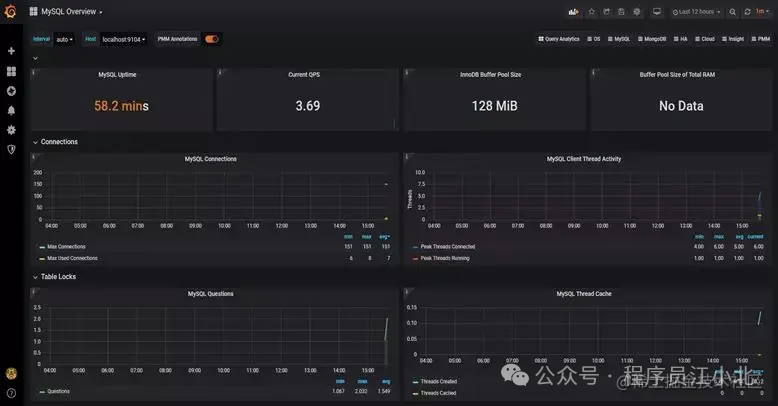
可以看到MySQL的当前QPS、活跃线程数、连接数、缓存池的大小等信息。如果发现连接池占用的数据量太多,肯定会对接口性能造成影响。这时可能是由于代码中开启了连接却忘记关闭,或者并发量太大导致的,需要进一步排查和系统优化
链路跟踪
有时候,一个接口涉及的逻辑非常复杂,例如查询数据库、查询Redis、远程调用接口、发送MQ消息以及执行业务代码等等。这种情况下,接口的一次请求会涉及到非常长的调用链路。如果逐一排查这些问题,会耗费大量时间,此时我们已经无法用传统的方法来定位问题。
有没有办法解决这个问题呢?
答案是使用分布式链路跟踪系统:SkyWalking。
SkyWalking的架构图如下:
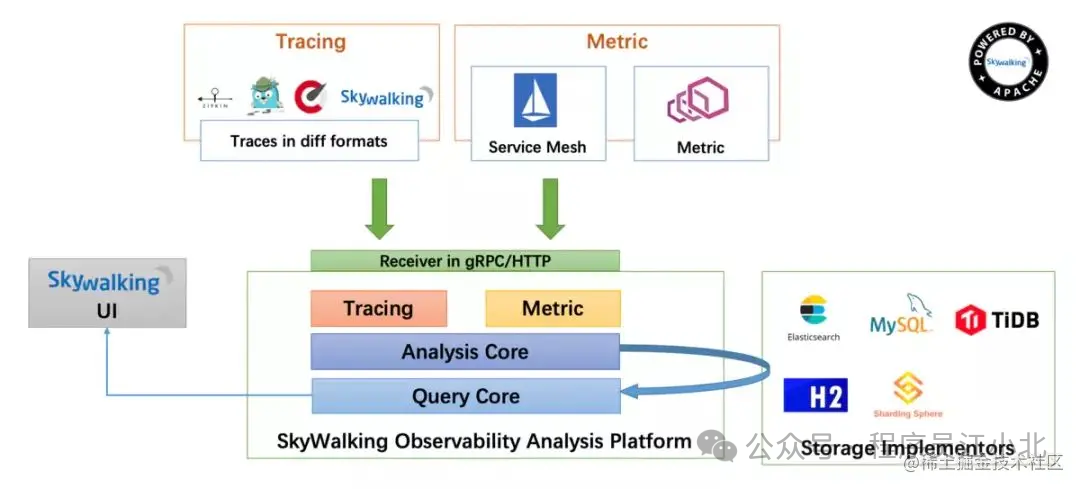
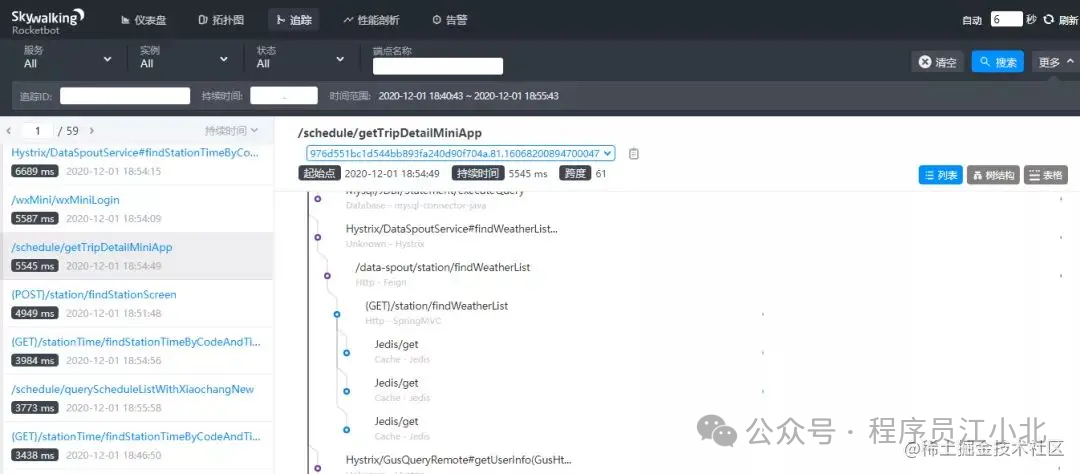
在SkyWalking中,可以通过traceId(全局唯一的ID)来串联一个接口请求的完整链路。你可以看到整个接口的耗时、调用的远程服务的耗时、访问数据库或者Redis的耗时等,功能非常强大。
之前没有这个功能时,为了定位线上接口性能问题,我们需要在代码中加日志,手动打印出链路中各个环节的耗时情况,然后再逐一排查。这种方法不仅费时费力,而且容易遗漏细节。
如果你用过SkyWalking来排查接口性能问题,你会不自觉地爱上它的功能。如果你想了解更多功能,可以访问SkyWalking的官网:skywalking.apache.org。
CPU飙升到100%,GC频繁,故障排查
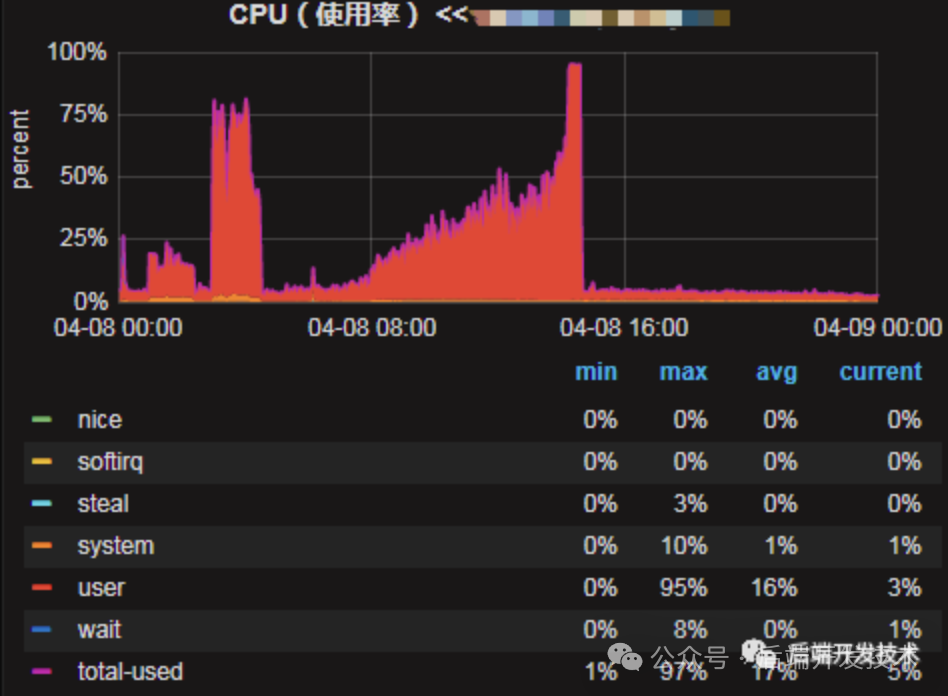
发现问题
下面是线上机器的cpu使用率,可以看到从4月8日开始,随着时间cpu使用率在逐步增高,最终使用率达到100%导致线上服务不可用,后面重启了机器后恢复。
排查思路
简单分析下可能出问题的地方,分为5个方向:
-
系统本身代码问题。
-
内部下游系统的问题导致的雪崩效应。
-
上游系统调用量突增。
-
http请求第三方的问题。
-
机器本身的问题。
初步定位问题
1.查看日志,没有发现集中的错误日志,初步排除代码逻辑处理错误。
2.首先联系了内部下游系统观察了他们的监控,发现一起正常。可以排除下游系统故障对我们的影响。
3.查看provider接口的调用量,对比7天没有突增,排除业务方调用量的问题。
4.查看tcp监控,TCP状态正常,可以排除是http请求第三方超时带来的问题。
5.查看机器监控,6台机器cpu都在上升,每个机器情况一样。排除单点机器故障问题。
即通过上述方法没有直接定位到问题。
定位CPU问题
1.重启了6台中问题比较严重的5台机器,先恢复业务。保留一台现场,用来分析问题。
2.查看当前的tomcat线程pid。

3.查看该pid下线程对应的系统占用情况。
top -Hp 384
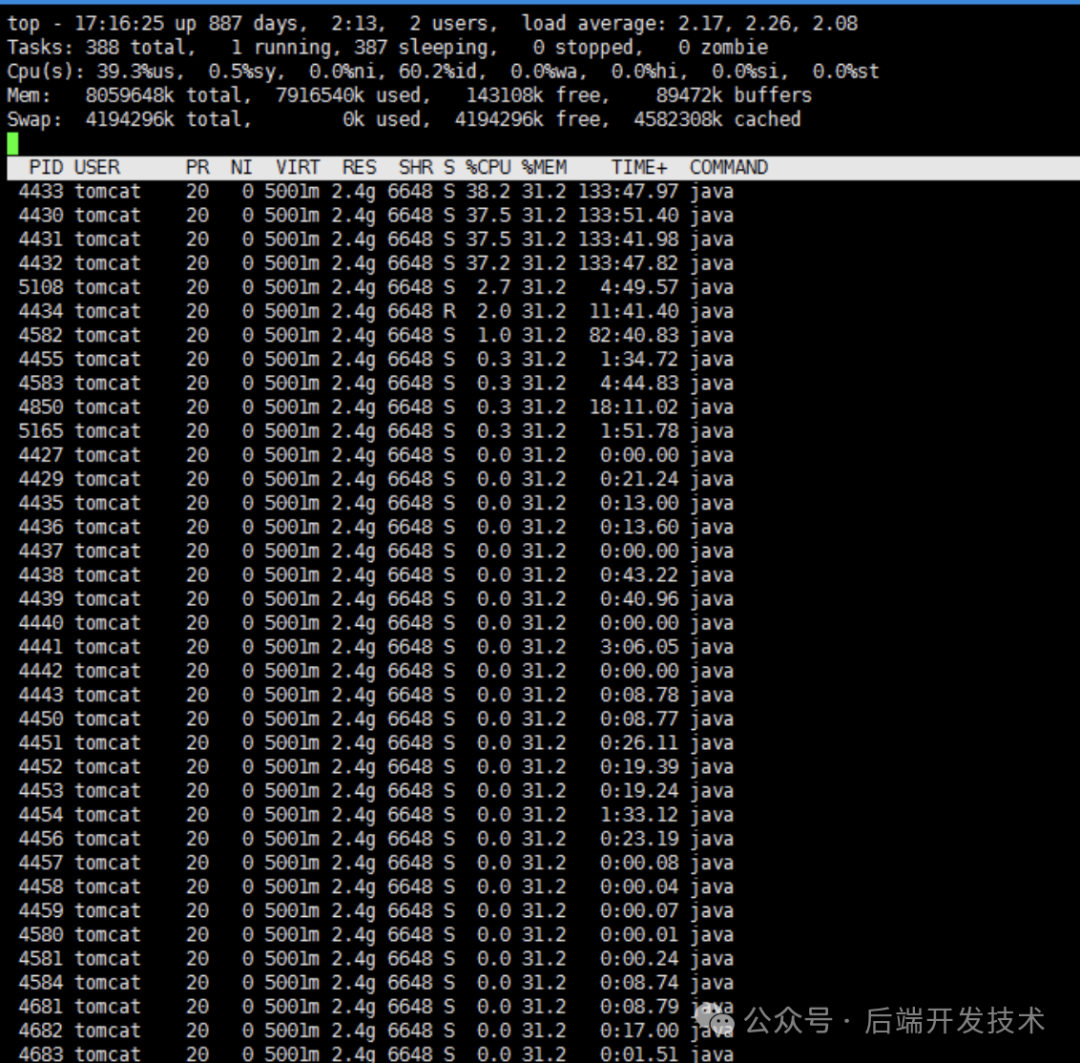
4.发现pid 4430 4431 4432 4433 线程分别占用了约40%的cpu。

5.将这几个pid转为16进制,分别为114e 114f 1150 1151
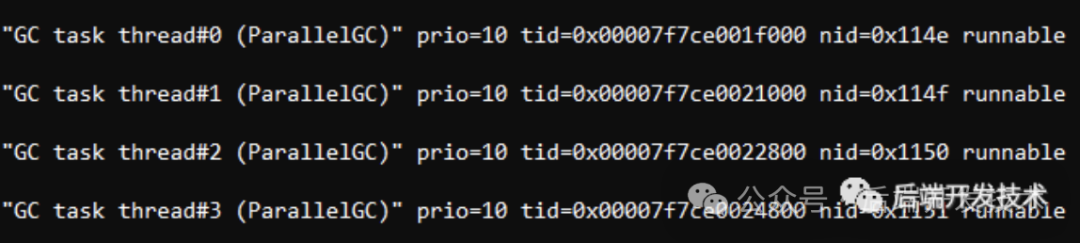
6.下载当前的java线程栈 sudo -u tomcat jstack -l 384>/1.txt
7.查询5中对应的线程情况,发现都是gc线程导致的
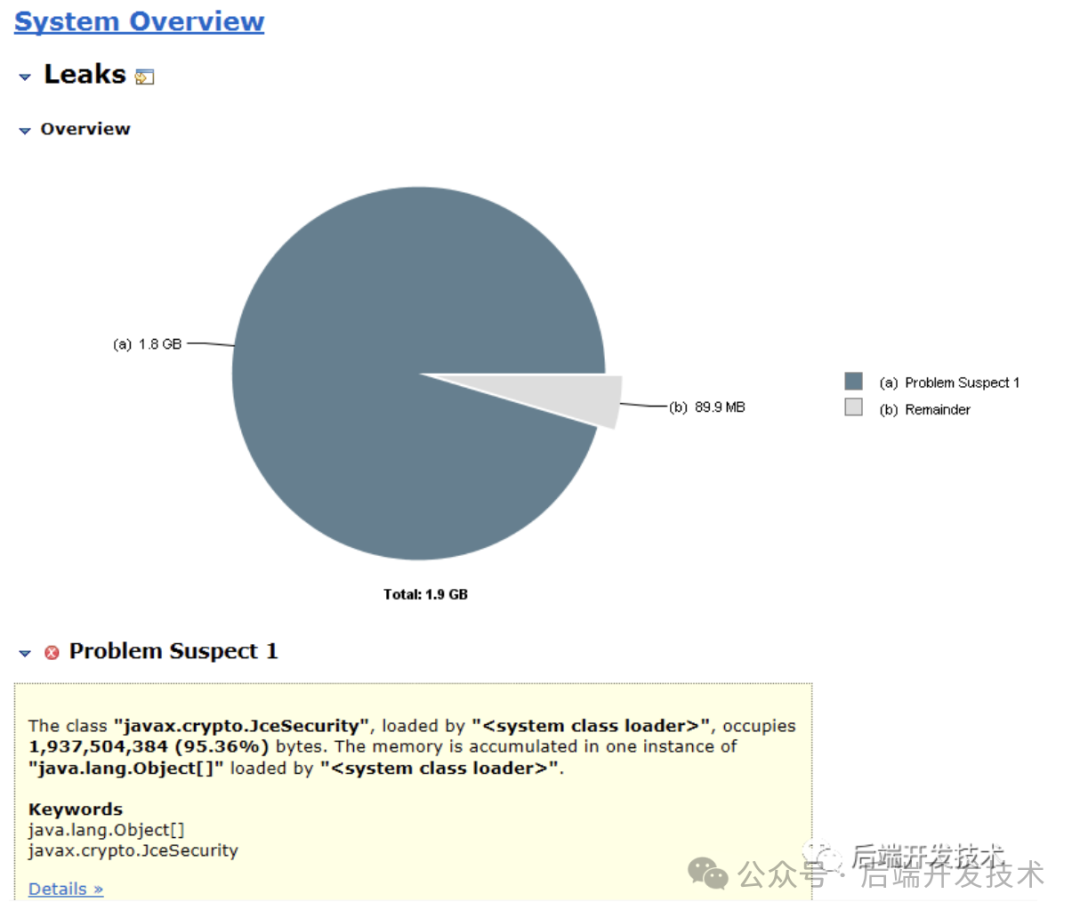
8.dump java堆数据 sudo -u tomcat jmap -dump:live,format=b,file=/dump201612271310.dat 384 9.使用MAT加载堆文件,可以看到javax.crypto.JceSecurity对象占用了95%的内存空间,初步定位到问题。MAT下载地址:http://www.eclipse.org/mat/
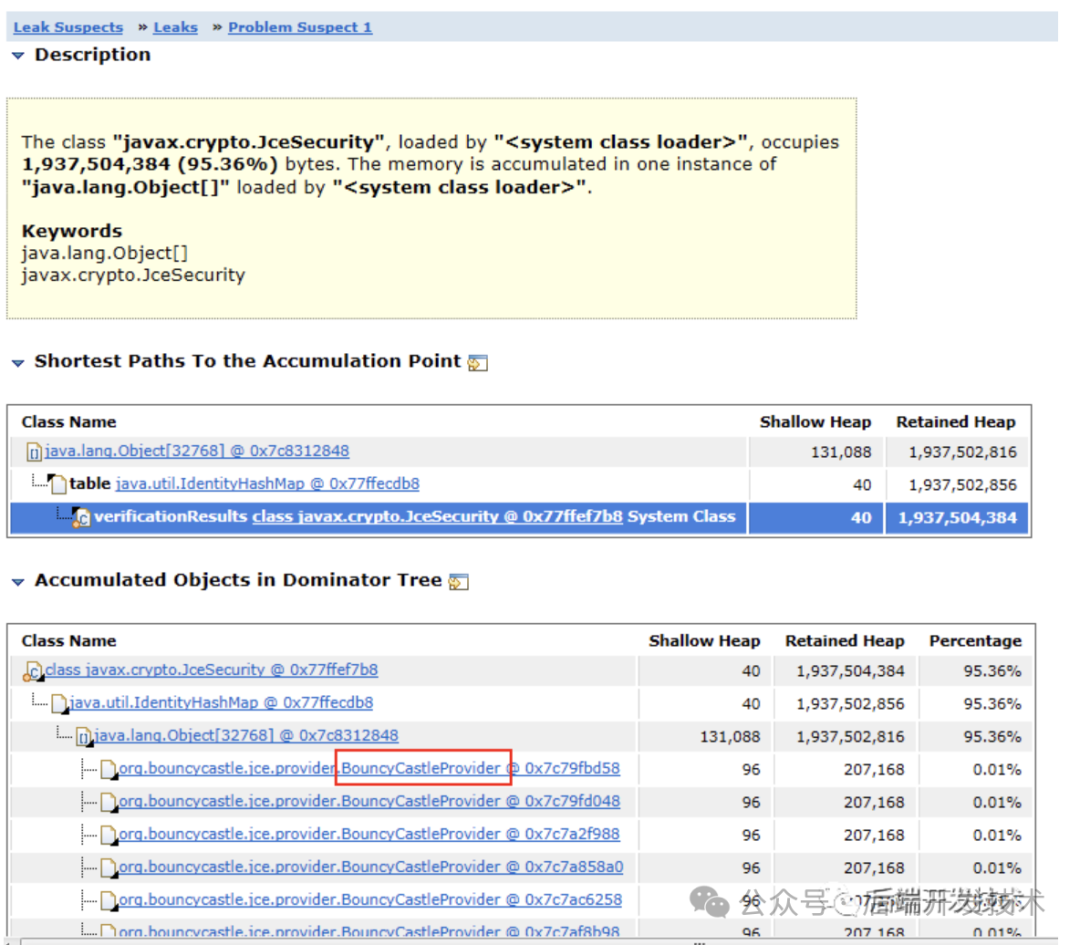
10.查看类的引用树,看到BouncyCastleProvider对象持有过多。即我们代码中对该对象的处理方式是错误的,定位到问题。
代码分析
我们代码中有一块是这样写的
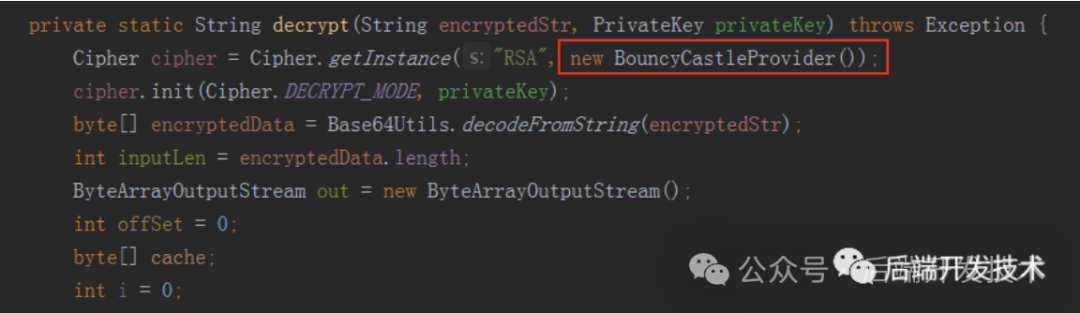
这是加解密的功能,每次运行加解密都会new一个BouncyCastleProvider对象,放倒Cipher.getInstance()方法中。看下Cipher.getInstance()的实现,这是jdk的底层代码实现,追踪到JceSecurity类中
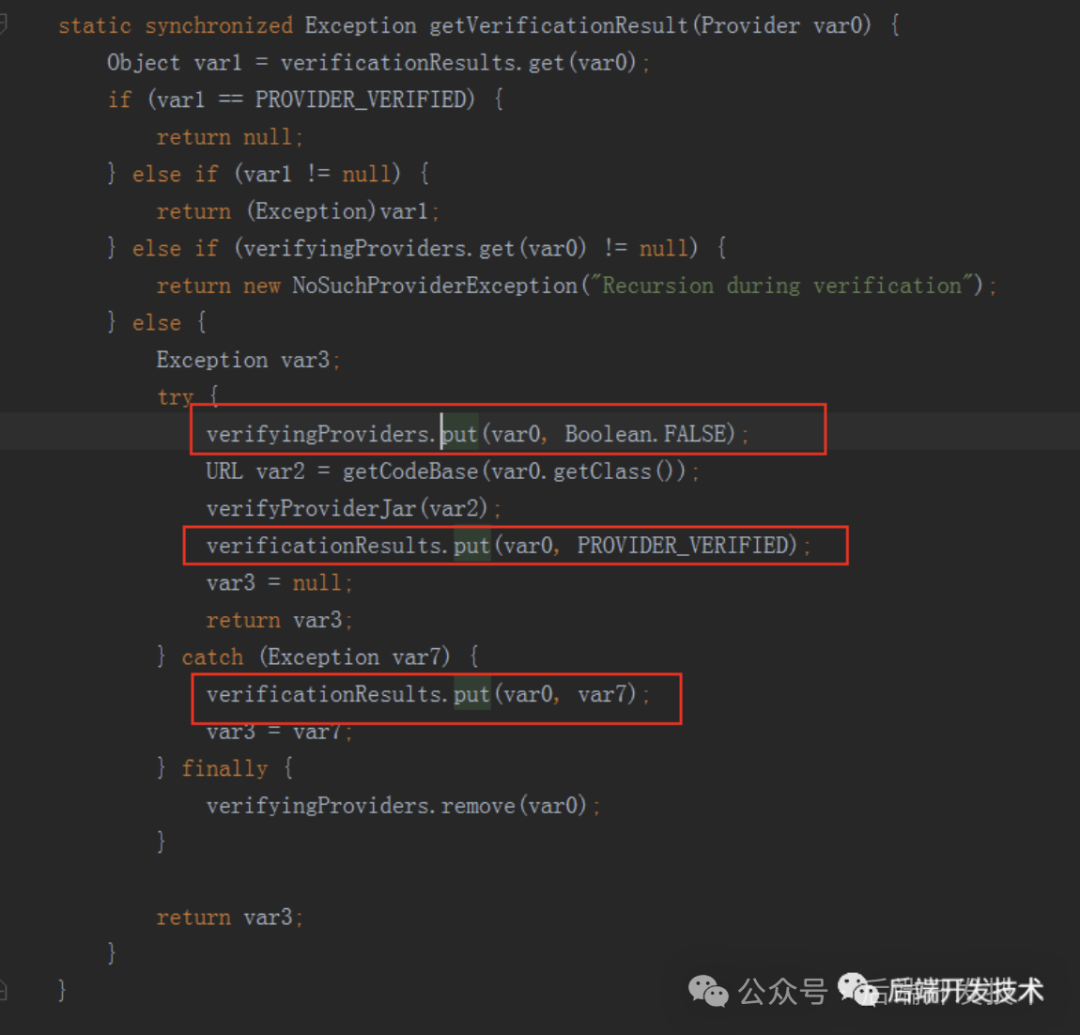
verifyingProviders每次put后都会remove,verificationResults只会put,不会remove.
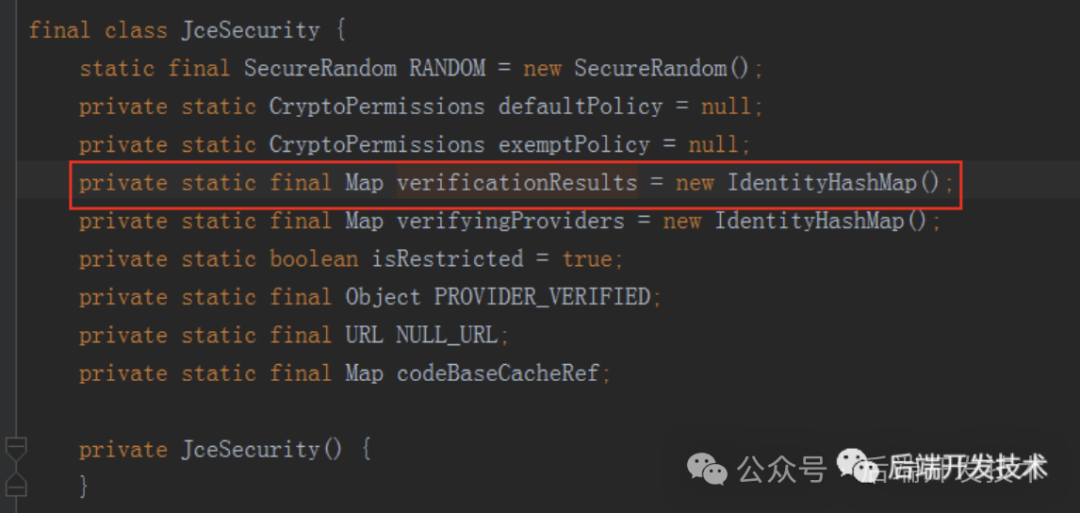
看到verificationResults是一个static的map,即属于JceSecurity类的。所以每次运行到加解密都会向这个map put一个对象,而这个map属于类的维度,所以不会被GC回收。这就导致了大量的new的对象不被回收。
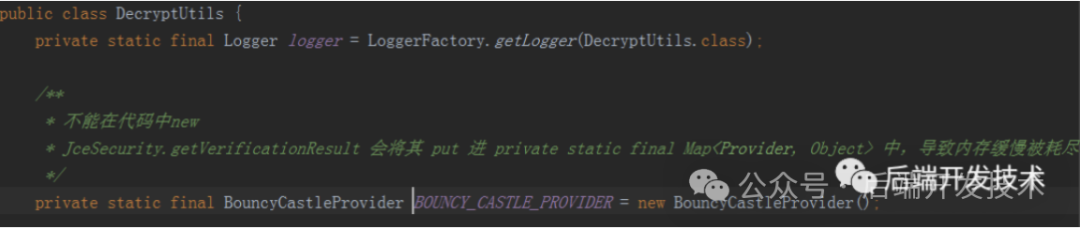
代码改进
将有问题的对象置为static,每个类持有一个,不会多次新建对象。
本文总结
遇到线上CPU升高问题不要慌,首先确认排查问题的思路:
-
查看日志。
-
观察上下游接口调用情况。
-
查看TCP情况。
-
查看机器CPU情况。
-
查看java线程,jstack。
-
查看java堆,jmap。
-
通过MAT分析堆文件,寻找无法被回收的对象。
高并发下数据读写的安全性
3.1、元数据锁(Meta Data Lock)
Meta Data Lock元数据锁,也被简称为MDL锁,这是基于表的元数据加锁,表锁是基于整张表加锁,行锁是基于一条数据加锁,那这个表的元数据是什么?所有存储引擎的表都会存在一个.frm文件,这个文件中主要存储表的结构(DDL语句),而MDL锁就是基于.frm文件中的元数据加锁的。
对于这种锁是在
MySQL5.5版本后再开始支持的,这个锁主要是用于:更改表结构时使用,比如你要向一张表创建/删除一个索引、修改一个字段的名称/数据类型、增加/删除一个表字段等这类情况。
因为毕竟当你的表结构正在发生更改,假设此时有其他事务来对表做CRUD操作,自然就会出现问题,比如我刚删了一个表字段,结果另一个事务中又按原本的表结构插入了一条数据,这显然会存在风险,因此MDL锁在加锁后,整张表不允许其他事务做任何操作。
3.2、自增锁(AUTO-INC Lock)
自增锁,这个是专门为了提升自增ID的并发插入性能而设计的,通常情况下咱们在建表时,都会对一张表的主键设置自增特性,如下:
CREATE TABLE `table_name` (`xx_id` NOT NULL AUTO_INCREMENT,.....
) ENGINE = InnoDB;当对一个字段设置AUTO_INCREMENT自增后,意味着后续插入数据时无需为其赋值,系统会自动赋上顺序自增的值。比如目前表中最大的ID=88,如果两个并发事务一起对表执行插入语句,由于是并发执行的原因,所以有可能会导致插入两条ID=89的数据。因此这里必须要加上一个排他锁,确保并发插入时的安全性,但也由于锁的原因,插入的效率也就因此降低了,毕竟将所有写操作串行化了。
为了改善插入数据时的性能,自增锁诞生了,自增锁也是一种特殊的表锁,但它仅为具备
AUTO_INCREMENT自增字段的表服务,同时自增锁也分成了不同的级别,可以通过innodb_autoinc_lock_mode参数控制。
-
•
innodb_autoinc_lock_mode = 0:传统模式。 -
•
innodb_autoinc_lock_mode = 1:连续模式(MySQL8.0以前的默认模式)。 -
•
innodb_autoinc_lock_mode = 2:交错模式(MySQL8.0之后的默认模式)。
当然,这三种模式又是什么含义呢?得先弄明白MySQL中可能出现的三种插入类型:
-
• 普通插入:指通过
INSERT INTO table_name(...) VALUES(...)这种方式插入。 -
• 批量插入:指通过
INSERT ... SELECT ...这种方式批量插入查询出的数据。 -
• 混合插入:指通过
INSERT INTO table_name(id,...) VALUES(1,...),(NULL,...),(3,...)这种方式插入,其中一部分指定ID,一部分不指定。
自增锁主要负责维护并发事务下自增列的顺序,也就是说,每当一个事务想向表中插入数据时,都要先获取自增锁先分配一个自增的顺序值,但不同模式下的自增锁也会有些许不同。
传统模式:事务
T1获取自增锁插入数据,事务T2也要插入数据,此时事务T2只能阻塞等待,也就是传统模式下的自增锁,同时只允许一条线程执行,这种形式显然性能较低。
连续模式:这个模式主要是由于传统模式存在性能短板而研发的,在这种模式中,对于能够提前确定数量的插入语句,则不会再获取自增锁,啥意思呢?也就是对于“普通插入类型”的语句,因为在插入之前就已经确定了要插入多少条数据,因为会直接分配范围自增值。好比目前事务
T1要通过INSERT INTO...语句插入十条数据,目前表中存在的最大ID=88,那在连续模式下,MySQL会直接将89~98这十个自增值分配给T1,因此T1无需再获取自增锁,但不获取自增锁不代表不获取锁了,而是改为使用一种轻量级锁Mutex-Lock来防止自增值重复分配。对于普通插入类型的操作,由于可以提前确定插入的数据量,因此可以采用“预分配”思想,但如若对于批量插入类型的操作,因为批量插入的数据是基于
SELECT语句查询出来的,所以在执行之前也无法确定究竟要插入多少条,所以依旧会获取自增锁执行。也包括对于混合插入类型的操作,有一部分指定了自增值,但有一部分需要MySQL分配,因此“预分配”的思想也用不上,因此也要获取自增锁执行。
交错模式:在交错插入模式中,对于
INSERT、REPLACE、INSERT…SELECT、REPLACE…SELECT、LOAD DATA等一系列插入语句,都不会再使用表级别的自增锁,而是全都使用Mutex-Lock来确保安全性,为什么在这个模式中,批量插入也可以不获取自增锁呢?这跟它的名字有关,目前这个模式叫做交错插入模式,也就是不同事务之间插入数据时,自增列的值是交错插入的。好比事务
T1、T2都要执行批量插入的操作,因为不确定各自要插入多少条数据,所以之前那种“连续预分配”的思想用不了了,但虽然无法做“连续的预分配”,那能不能交错预分配呢?好比给T1分配{1、3、5、7、9....},给T2分配{2、4、6、8、10.....},然后两个事务交错插入,这样岂不是做到了自增值即不重复,也能支持并发批量插入?答案是Yes,但由于两个事务执行的都是批量插入的操作,因此事先不确定插入行数,所以有可能导致“交错预分配”的顺序值,有可能不会使用,比如T1只插入了四条数据,只用了1、3、5、7,T2插入了五条数据,因此表中的自增值有可能出现空隙,即{1、2、3、4、5、6、8、10},其中9就并未使用。
3.3、全局锁
全局锁其实是一种尤为特殊的表锁,其实将它称之为库锁也许更合适,因为全局锁是基于整个数据库来加锁的,加上全局锁之后,整个数据库只能允许读,不允许做任何写操作,一般全局锁是在对整库做数据备份时使用。
-- 获取全局锁的命令
FLUSH TABLES WITH READ LOCK;-- 释放全局锁的命令
UNLOCK TABLES;从上述的命令也可以看出,为何将其归纳到表锁范围,因为获取锁以及释放锁的命令都是表锁的命令。
PS:表中横向(行)表示已经持有锁的事务,纵向(列)表示正在请求锁的事务。
| 行级锁对比 | 共享临键锁 | 排他临键锁 | 间隙锁 | 插入意向锁 |
| 共享临键锁 | 兼容 | 冲突 | 兼容 | 冲突 |
| 排他临键锁 | 冲突 | 冲突 | 兼容 | 冲突 |
| 间隙锁 | 兼容 | 兼容 | 兼容 | 冲突 |
| 插入意向锁 | 冲突 | 冲突 | 冲突 | 兼容 |
由于临建锁也会锁定相应的行数据,因此上表中也不再重复赘述记录锁,临建锁兼容的 记录锁都兼容,同理,冲突的记录锁也会冲突,再来看看标记别的锁对比:
| 表级锁对比 | 共享意向锁 | 排他意向锁 | 元数据锁 | 自增锁 | 全局锁 |
| 共享意向锁 | 兼容 | 冲突 | 冲突 | 冲突 | 冲突 |
| 排他意向锁 | 冲突 | 冲突 | 冲突 | 冲突 | 冲突 |
| 元数据锁 | 冲突 | 冲突 | 冲突 | 冲突 | 冲突 |
| 自增锁 | 冲突 | 冲突 | 冲突 | 冲突 | 冲突 |
| 全局锁 | 兼容 | 冲突 | 冲突 | 冲突 | 冲突 |
会发现表级别的锁,会有很多很多冲突,因为锁的粒度比较大,因此很多时候都会出现冲突,但对于表级锁,咱们只需要关注共享意向锁和共享排他锁即可,其他的大多数为MySQL的隐式锁(在这里,共享意向锁和排他意向锁,也可以理解为MyISAM中的表读锁和表写锁)。
最后再简单的说一下,表中的冲突和兼容究竟是啥意思?冲突的意思是当一个事务
T1持有某个锁时,另一个事务T2来请求相同的锁,T2会由于锁排斥会陷入阻塞等待状态。反之同理,兼容的意思是指允许多个事务一同获取同一个锁。
MySQL5.7 共享排他锁
在MySQL5.7之前的版本中,数据库中仅存在两种类型的锁,即共享锁与排他锁,但是在MySQL5.7.2版本中引入了一种新的锁,被称之为(SX)共享排他锁,这种锁是共享锁与排他锁的杂交类型,至于为何引入这种锁呢?
SMO问题(Split-Merge Overflow)通常出现在数据库管理系统中,特别是在B+Tree索引结构的操作过程中。以下是对SMO问题的解释:
**B+Tree**:
B+Tree是一种自平衡的树数据结构,通常用于数据库和操作系统的索引。在数据库中,B+Tree用于快速检索记录,因为它们允许对数据进行排序并支持对数时间复杂度的搜索、顺序访问、插入和删除操作。
**SMO问题**:
1. **Split(分裂)**:当向B+Tree中的一个页(通常是磁盘上的一个块)插入一个新的键,而这个页已经满了时,就会发生分裂。这时,页中的键和指针会被分成两个部分,一部分保留在原页,另一部分被移动到一个新的页中。这种操作可能导致树的其他部分也发生分裂,以保持B+Tree的性质。
2. **Merge(合并)**:删除操作可能导致页中的键的数量减少,如果某个页中的键的数量低于某个阈值,这个页可能需要与它的兄弟页合并,以保持B+Tree的效率。
**Overflow(溢出)**:
SMO问题中的“Overflow”指的是在分裂或合并操作中,由于页分裂或合并导致的额外开销和处理,可能会引起系统性能的下降。特别是在高并发的数据库环境中,这种开销可能会更加显著。
**减小锁定的B+Tree粒度**:
在多用户并发访问数据库时,锁定是用于保持数据一致性的机制。减小锁定粒度意味着锁定的范围更小,例如,不是锁定整个B+Tree页,而是只锁定页中的某个部分。这样做可以减少并发操作中的锁争用,从而提高系统的并发性能。具体到SMO问题,减小粒度可以帮助减少因分裂或合并操作而需要锁定的大量资源,从而减轻性能下降的问题。
总结来说,SMO问题是数据库中B+Tree索引结构在维护其平衡和效率时,因分裂和合并操作导致的一系列性能挑战。通过优化锁定策略,可以减少SMO问题对数据库性能的影响。
在
SQL执行期间一旦更新操作触发B+Tree叶子节点分裂,那么就会对整棵B+Tree加排它锁,这不但阻塞了后续这张表上的所有的更新操作,同时也阻止了所有试图在B+Tree上的读操作,也就是会导致所有的读写操作都被阻塞,其影响巨大。因此,这种大粒度的排它锁成为了InnoDB支持高并发访问的主要瓶颈,而这也是MySQL 5.7版本中引入SX锁要解决的问题。
那想一下该如何解决这个问题呢?最简单的方式就是减小SMO问题发生时,锁定的B+Tree粒度,当发生SMO问题时,就只锁定B+Tree的某个分支,而并不是锁定整颗B+树,从而做到不影响其他分支上的读写操作。
那
MySQL5.7中引入共享排他锁后,究竟是如何实现的这点呢?首先要弄清楚SX锁的特性,它不会阻塞S锁,但是会阻塞X、SX锁。
在聊之前首先得搞清楚SQL执行时的几个概念:
-
• 读取操作:基于
B+Tree去读取某条或多条行记录。 -
• 乐观写入:不会改变
B+Tree的索引键,仅会更改索引值,比如主键索引树中不修改主键字段,只修改其他字段的数据,不会引起节点分裂。 -
• 悲观写入:会改变
B+Tree的结构,也就是会造成节点分裂,比如无序插入、修改索引键的字段值。
在MySQL5.6版本中,一旦有操作导致了树结构发生变化,就会对整棵树加上排他锁,阻塞所有的读写操作,而MySQL5.7版本中,为了解决该问题,对于不同的SQL执行,流程就做了调整。
MySQL5.7中读操作的执行流程
-
• ①读取数据之前首先会对
B+Tree加一个共享锁。 -
• ②在基于树检索数据的过程中,对于所有走过的叶节点会加一个共享锁。
-
• ③找到需要读取的目标叶子节点后,先加一个共享锁,释放步骤②上加的所有共享锁。
-
• ④读取最终的目标叶子节点中的数据,读取完成后释放对应叶子节点上的共享锁。
MySQL5.7中乐观写入的执行流程
-
• ①乐观写入之前首先会对
B+Tree加一个共享锁。 -
• ②在基于树检索修改位置的过程中,对于所有走过的叶节点会加一个共享锁。
-
• ③找到需要写入数据的目标叶子节点后,先加一个排他锁,释放步骤②上加的所有共享锁。
-
• ④修改目标叶子节点中的数据后,释放对应叶子节点上的排他锁。
MySQL5.7中悲观写入的执行流程
-
• ①悲观更新之前首先会对
B+Tree加一个共享排他锁。 -
• ②由于①上已经加了
SX锁,因此当前事务执行过程中会阻塞其他尝试更改树结构的事务。 -
• ③遍历查找需要写入数据的目标叶子节点,找到后对其分支加上排他锁,释放①中加的
SX锁。 -
• ④执行
SMO操作,也就是执行悲观写入操作,完成后释放步骤③中在分支上加的排他锁。
如果需要修改多个数据时,会在遍历查找的过程中,记录下所有要修改的目标节点。
MySQL5.7中并发事务冲突分析
观察上述讲到的三种执行情况,对于读操作、乐观写入操作而言,并不会加SX锁,共享排他锁仅针对于悲观写入操作会加,由于读操作、乐观写入执行前对整颗树加的是S锁,因此悲观写入时加的SX锁并不会阻塞乐观写入和读操作,但当另一个事务尝试执行SMO操作变更树结构时,也需要先对树加上一个SX锁,这时两个悲观写入的并发事务就会出现冲突,新来的事务会被阻塞。
但是要注意:当第一个事务寻找到要修改的节点后,会对其分支加上
X锁,紧接着会释放B+Tree上的SX锁,这时另外一个执行SMO操作的事务就能获取SX锁啦!
其实从上述中可能得知一点:MySQL5.7版本引入共享排他锁之后,解决了5.6版本发生SMO操作时阻塞一切读写操作的问题,这样能够在一定程度上提升了InnoDB表的并发性能。
最后要注意:虽然一个执行悲观写入的事务,找到了要更新/插入数据的节点后会释放
SX锁,但是会对其上级的叶节点(叶分支)加上排他锁,因此正在发生SMO操作的叶分支,依旧是会阻塞所有的读写行为!
当一个要读取的数据,位于正在执行SMO操作的叶分支中时,依旧会被阻塞。









![[电机控制]-三相鼠笼电机simulink建模](https://i-blog.csdnimg.cn/direct/ccedec36630f4a9486f1d800dca64cd1.png#pic_center)









