文章目录
- 一、前言
- 二、什么是湖仓一体?
- 起源
- 概述
- 三、为什么要构建湖仓一体?
- 1. 成本角度
- 2. 技术角度
- 四、湖仓一体实践过程
- 阶段一:摸索阶段(仓、湖并行建设)
- 阶段二:发展阶段
- 方式一、湖上建仓(湖在下、仓在上)
- 方式二:仓外挂湖(金融领域常见)
- 阶段三:深化阶段(整合以上两种方式)
- 五、总结
- 六、参考资料
一、前言
在阅读本文之前,建议读者先对数据仓库和数据湖有一些基本的了解。这将有助于更好地理解本文内容。您可以参考笔者以下文章:
从数据库到数据仓库:数据仓库导论
从数据仓库到数据湖(上):数据湖导论
从数据仓库到数据湖(下):数据湖领域热门的开源框架
二、什么是湖仓一体?
起源
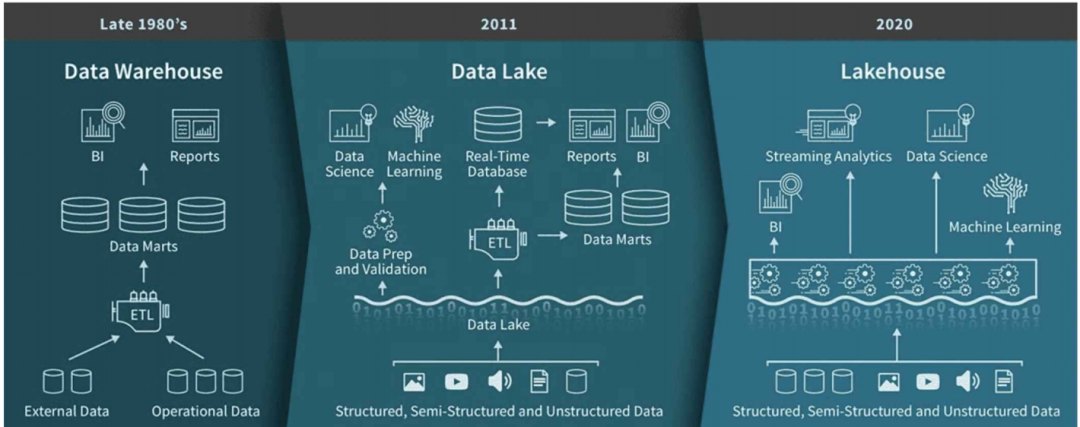
湖仓一体概念最早是由数据智能独角兽企业Databricks于2020年提出Data Lakehouse概念,其联合创始人兼首席执行官 Ali Ghodsi 说:“从长远来看,所有数据仓库都将被纳入数据湖仓,这不会在一夜之间发生——这些东西会共存一段时间——但这个官方的世界纪录清楚地证明,在价格和性能上,数据湖仓完胜数据仓库。”
概述
湖仓一体是一种新的数据管理模式。湖仓一体将数据仓库和数据湖两者之间的差异进行融合,并将数据仓库构建在数据湖,从而有效简化了企业数据的基础架构,提升数据存储弹性和质量的同时还能降低成本,减小数据冗余。
在湖仓一体之前,数据分析经历了数据库、数据仓库和数据湖分析三个时代。
- 首先是数据库,它是一个最基础的概念,主要负责联机事务处理,也提供基本的数据分析能力。
- 随着数据量的增长,出现了数据仓库,它存储的是经过清洗、加工以及建模后的高价值的数据,供业务人员进行数据分析。
- 数据湖的出现,主要是为了去满足企业对原始数据的存储、管理的需求。这里的需求主要包括两部分,首先要有一个低成本的存储,用于存储结构化、半结构化,甚至非结构化的数据;另外,就是希望有一套包括数据处理、数据管理以及数据治理在内的一体化解决方案。
数据仓库解决了数据快速分析的需求,数据湖解决了数据的存储和管理的需求,而湖仓一体要解决的就是如何让数据能够在数据湖和数据仓库之间进行无缝的集成和自由的流转,从而帮助用户直接利用数据仓库的能力来解决数据湖中的数据分析问题,同时又能充分利用数据湖的数据管理能力来提升数据的价值。
注意:严格来说湖仓一体没有跟具体哪个技术绑定
三、为什么要构建湖仓一体?
湖仓一体的出现离不开数据湖和技术的发展,本文将从成本和技术两个方向探讨为何要构建湖仓一体。
1. 成本角度
在企业构建数据湖初期,企业已经拥有了数据仓库,而数据湖作为新兴组件独立部署。在这一阶段,数据仓库和数据湖是并行建设的,但随着时间的推移,它们之间的数据协同性差,形成了数据孤岛。
由于数据仓库和数据湖各自独立建设,企业需要重新购买机器,增加成本。因此,从成本角度看,湖仓一体是必要的。
此外,数据湖适合存储各种类型的数据,其起步成本较低,但随着数据量增加,总拥有成本(TCO)会迅速上升。相反,数据仓库在前期需要进行大量数据处理(如清洗、加工和结构约束),建设成本较高,但后期维护成本相对稳定。
因此,对于既想建立数据湖又想搭建数据仓库的企业来说,这无异于在玩一个成本游戏。
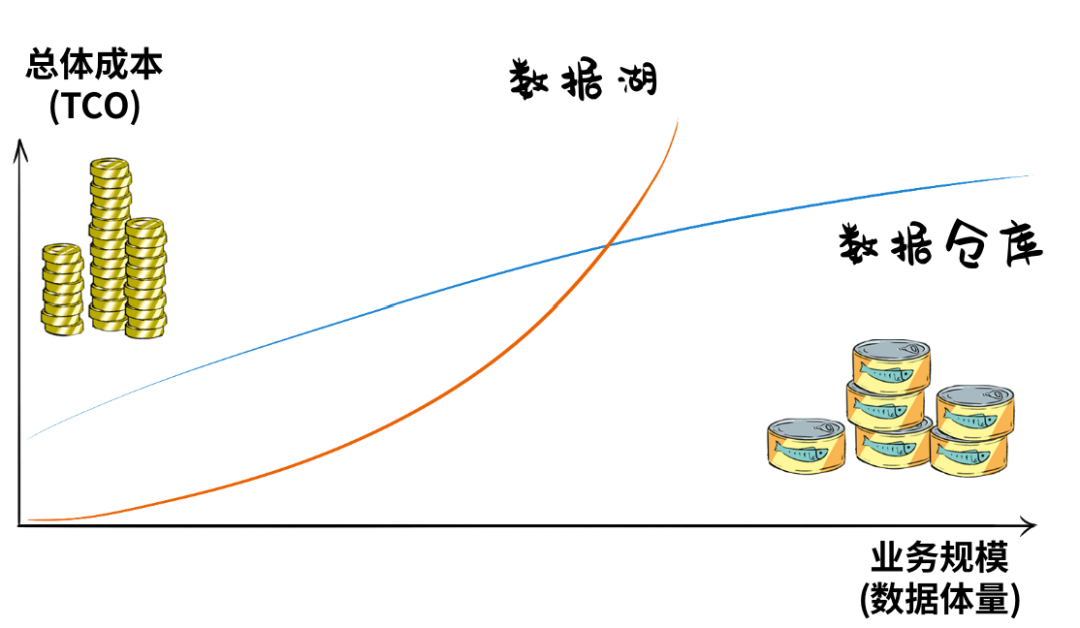
为了更有效地利用数据资源,人们开始思考,能否将数据湖和数据仓库整合起来,减少重复建设,实现数据的流动和共享?

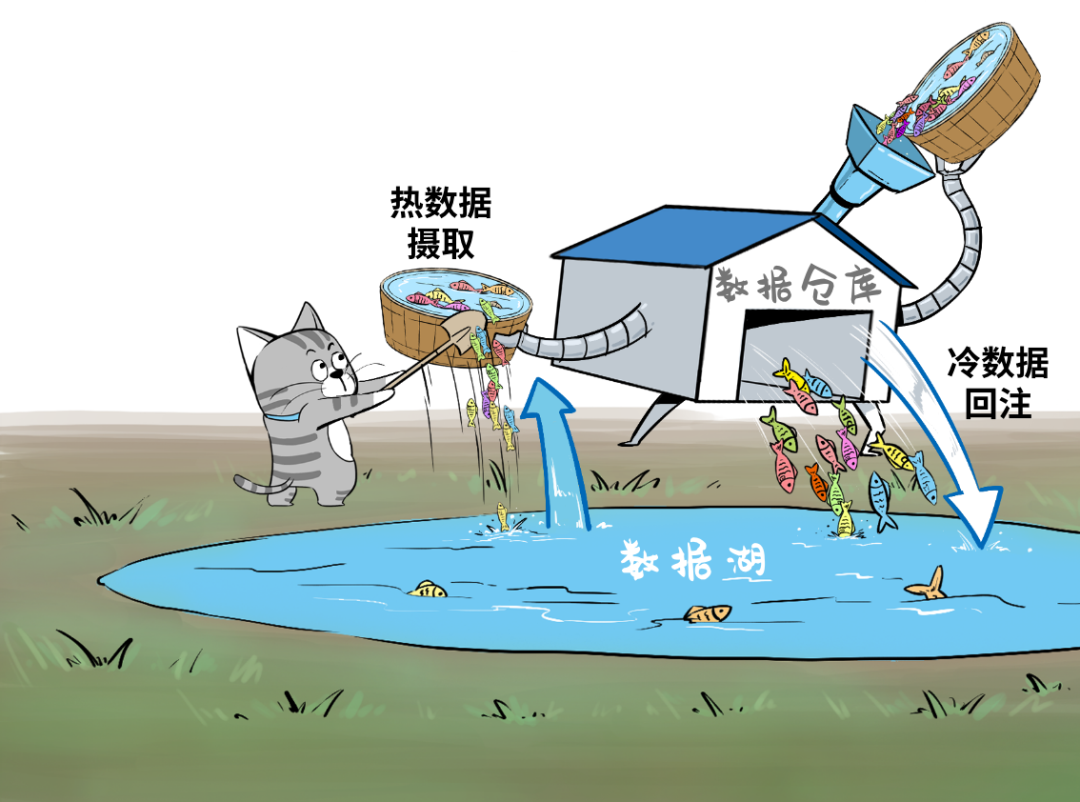
这些需求推动了数据湖和数据仓库的融合,催生了如今炙手可热的概念:Lake House。Lake House,坊间称之为“湖仓一体”,其架构的核心是实现“湖里”和“仓里”的数据/元数据无缝打通,并且“自由”流动。
湖里的“新鲜”数据可以流到仓里,甚至可以直接被数据仓库使用,而仓里的“不新鲜”数据也可以流到湖里,低成本长久保存,供未来的数据挖掘使用。
2. 技术角度
在笔者之前关于数据湖的文章中提到,当下的数据湖开源框架均依赖分布式文件系统的存储能力。它们普遍支持一些通用的文件格式来组织和管理数据。正是这种通用的数据格式,为许多计算引擎和数据库提供了接口的便利。
例如,传统的数据仓库 Hive 将数据存储在 HDFS 上,而数据湖 Hudi 也使用 HDFS 存储数据。考虑到它们共享相同的底层存储,为何不将它们整合在一起呢?这就催生了“湖仓一体”的技术概念,当然,这只是原因之一。
随着技术的发展,数据湖和数据仓库的边界正在逐渐模糊,数据湖与外部系统的对接能力也在增强。得益于数据湖技术对底层数据格式的通用性以及对外提供的良好接口,许多 MPP 库(如 ClickHouse、Doris、StarRocks 等)能够方便地对接数据湖。
以 Doris 为例,在其 2.x 版本的官方文档中,专门开设了一章“湖仓一体”来详细介绍这一概念,如下图所示:

通过这些技术整合,企业能够更有效地管理和利用数据资源,实现数据的流动和共享,进而提升数据驱动决策的能力和效率。
四、湖仓一体实践过程
国内大数据时代湖仓一体实践的发展经历了三个阶段:摸索阶段、发展阶段、深化阶段。
深化阶段尚未达到完全成熟,因为湖仓一体的概念较为新颖,仍在不断演变中,未来可能会有更先进的技术架构出现并取而代之。
阶段一:摸索阶段(仓、湖并行建设)
仓、湖各自独立建设,形成数据孤岛,数据协同性差,如下图:

阶段二:发展阶段
在湖仓一体的发展践阶段,逐渐形成了“湖上建仓”与“仓外挂湖”两种湖仓一体实现方式。
湖上建仓和仓外挂湖虽然出发点不同,但最终湖仓一体的目标一致。
方式一、湖上建仓(湖在下、仓在上)
湖仓一体架构主要是实现“湖里”和“仓里”的数据能够无缝打通,在这个背景下催生出:湖在下,仓在上的立体建设模式,在该架构中,湖仓一体架构主要将数据湖作为中央存储库,将机器学习、数据仓库、日志分析、大数据等技术进行整合,形成一套数据服务环,更好地分析、整合数据,让数据仓库和数据湖中的数据可以自由流动,用户可以更便捷地调取其中的数据,让数据“入湖”、“出湖”更为便捷,如下图:

1、数据湖来承载仓的贴源层和基础层;
2、仓聚焦在共性加工层及集市层;
细节如下图:

总的来看“湖上建仓”路径本质是在湖的基础上增加仓的能力
方式二:仓外挂湖(金融领域常见)
仓外挂湖是指以 MPP 数据库为数仓基础,使用可插拔架构,通过开放接口对接外部数据湖实现统一存储,在存储底层共享一份数据,计算、存储完全分离(即:数据存储在数据湖中,表的元数据管理和计算则使用MPP库能力),实现从强管理到兼容开放存储和多引擎。代表产品: Doris、AWS Redshift、阿里云 MaxCompute/Hologres 湖仓一体。
这里以Doris2.x版本为例,Doris 通过多源数据目录(Multi-Catalog)功能,支持了包括 Apache Hive、Apache Iceberg、Apache Hudi、Apache Paimon(Incubating)等主流数据湖的连接访问。具体架构如下:
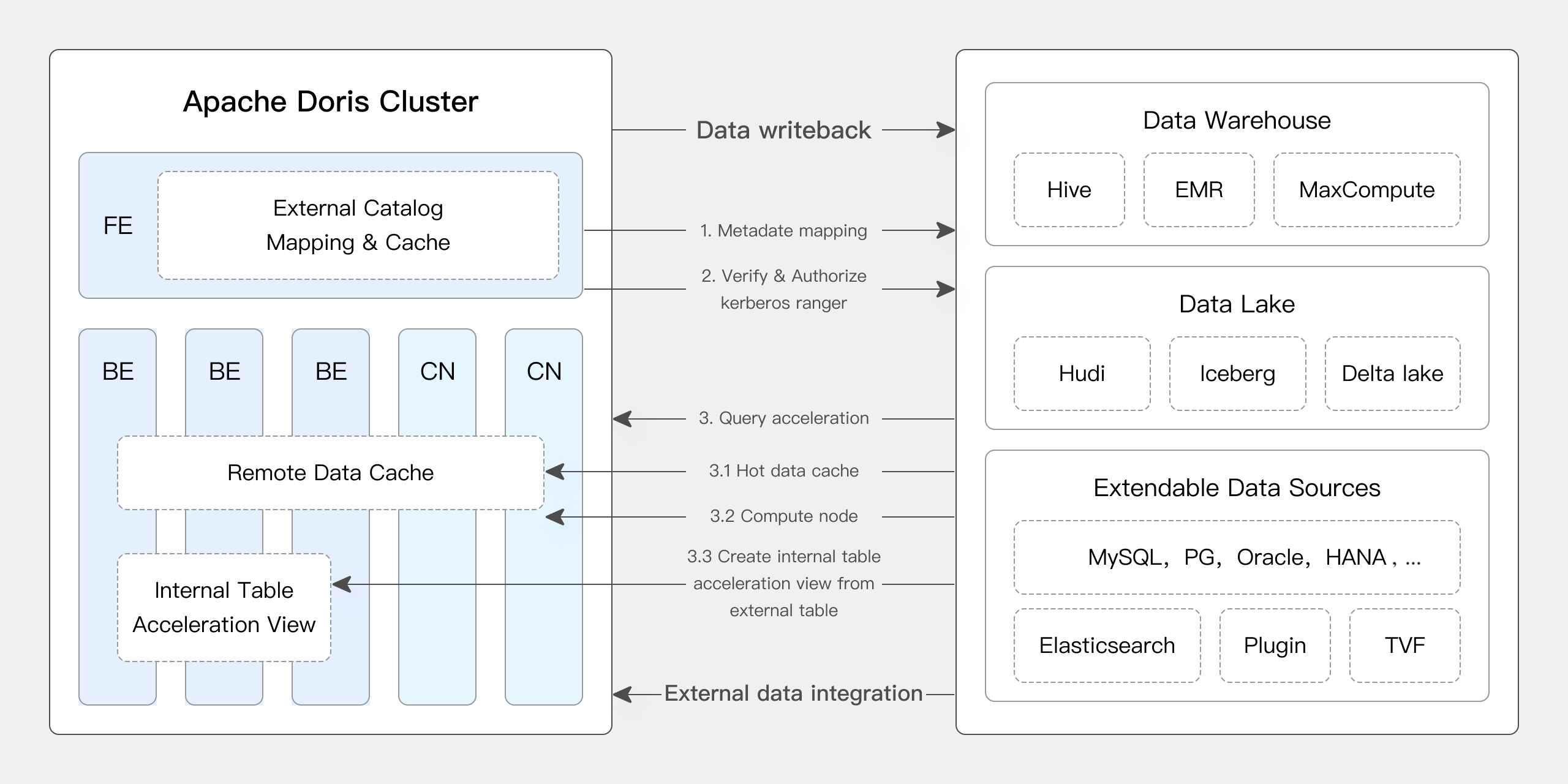
总的来看,“仓外挂湖”路径本质是在仓的基础上增加湖的多类型存储等能力
阶段三:深化阶段(整合以上两种方式)
下图展示了火山引擎的湖仓一体架构,涵盖从数据存储到计算处理的各个层级:
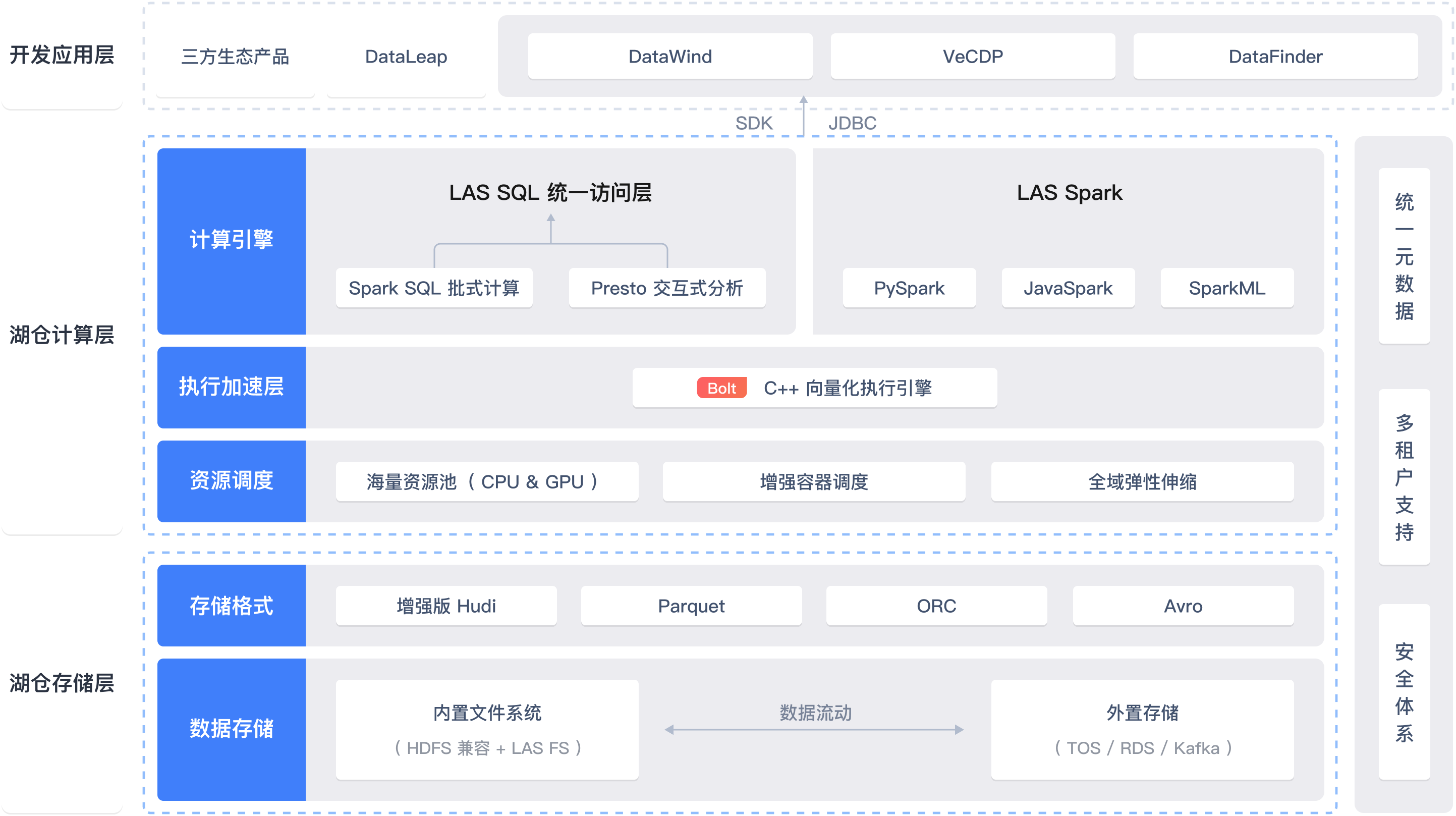
开发应用层
- 包含第三方生态产品和内部应用(如 DataLeap、DataWind)。
- 通过 SDK 和 JDBC 与计算层交互。
湖仓计算层
- 计算引擎:支持 Spark SQL、Presto、PySpark 等多种计算方式。
- 执行加速层:使用(C++ 向量化执行引擎)(例如Doris、ClickHouse等MPP库) 提高计算性能。
- 资源调度:提供海量资源池和弹性伸缩能力。
湖仓存储层[湖仓一体]
- 存储格式:支持 Hudi、Parquet、ORC 和 Avro 等格式。
- 数据存储:结合内置文件系统和外置存储(如 TOS、RDS、Kafka)。
数据管理
- 统一元数据管理:确保一致的数据视图。
- 多租户支持:实现数据隔离和管理。
- 安全体系:保障数据安全。
五、总结
本文详细探讨了从数据湖到湖仓一体的演进过程及其在现代数据管理中的重要性。湖仓一体由Databricks于2020年提出,旨在融合数据湖和数据仓库的优势,通过无缝集成,实现数据存储和管理的统一架构。
湖仓一体的出现主要是为了降低成本和解决数据孤岛问题。传统的数据湖和数据仓库各自独立建设,导致重复投资和数据管理上的困难,而湖仓一体通过简化基础架构、提升数据存储弹性和质量,有效减少了这些问题。
技术上,湖仓一体依赖于分布式文件系统和通用数据格式,增强了数据湖与外部系统的对接能力。实践中,湖仓一体在国内的发展经历了摸索、发展和深化三个阶段,形成了“湖上建仓”和“仓外挂湖”两种实现方式,各自通过不同的路径实现了数据的流动和共享。
总之,湖仓一体在提升数据管理效率和降低成本方面具有显著优势,虽然尚未完全成熟,但其发展潜力巨大,将为企业的数据管理和决策提供新的解决方案。
六、参考资料
- Doris湖仓一体概述
- 从数据库到数据仓库:数据仓库导论
- 从数据仓库到数据湖(上):数据湖导论
- 从数据仓库到数据湖(下):数据湖领域热门的开源框架
- 数据库、数据湖、数据仓库、湖仓一体、智能湖仓,分别都是什么鬼?