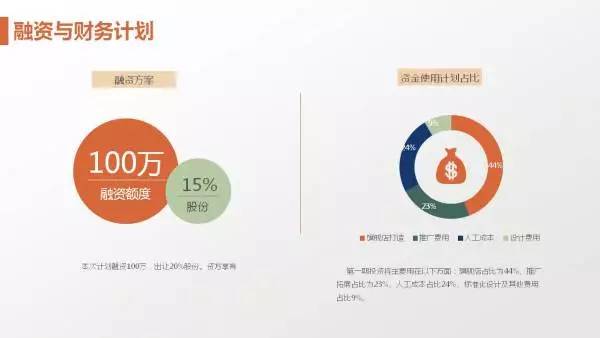
猫狗大战数据集
Cats vs. Dogs(猫狗大战)数据集下载地址为https://www.kaggle.com/c/dogs-vs-cats/data。这个数据集是Kaggle大数据竞赛某一年的一道赛题,利用给定的数据集,用算法实现猫和狗的识别。 其中包含了训练集和测试集,训练集中猫和狗的图片数量都是12500张且按顺序排序,测试集中猫和狗混合乱序图片一共12500张。
测试集部分图片如图: 
数据集加工
数据集中的图片尺寸都不尽相同,没有进行统一的裁剪。在神经网络模型的训练中,在输入层要求输入的数据大小是固定的,因此需要对数据集中的所有图片按照固定的大小裁剪。例如,AlexNet模型的输入图片大小是[227,227],在这里我们按照这个大小进行裁剪。代码如下:
import cv2
import os# 数据预处理,把图片数据集的所有图片修剪成固定大小形状
def image_tailor(input_dir, out_dir):for root, dirs, files in os.walk(input_dir):for file in files:# file为root目录中的文件filepath = os.path.join(root, file) # 连接两个或更多的路径名组件,filepath路径为/root/filetry:image = cv2.imread(filepath) # 根据输入路径读取照片dim = (227, 227) # 裁剪的尺寸resized = cv2.resize(image, dim) # 按比例将原图缩放成227*227path = os.path.join(out_dir, file) # 保存的路径和相应的文件名cv2.imwrite(path, resized) # 进行保存except:print(filepath)os.remove(filepath)cv2.waitKey()input_patch = 'F:\\data\\kaggle\\test1' # 数据集的地址
out_patch = 'F:\\data\\fixdata\\tailor' # 图片裁剪后保存的地址
image_tailor(input_patch, out_patch)
print('reshape finished')运行以上代码,就能自动的完成图片的裁剪,并保存到相应的文件夹中。os.walk()函数是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。
对测试集完成剪裁后的部分图片如图:

从裁剪后的图片与前文未裁剪的图片对比可以看到,裁剪只是对原图片按照一定的比例缩放到固定的尺寸,很好的保留了原图的信息。
数据集的读取
在第一步中,我们已经将尺寸大小不规则的图片缩放成固定大小,以满足神经网络模型AlexNet固定输入大小形式。在这一步中,我们需要对裁剪好的数据集中的图片的位置进行读取,并给图片打上标签。使用数组对图片的位置和标签进行保存,为后续的batch读取数据集做好准备。
完成代码如下:
# 用来读取数据集中所有图片的路径和标签
def get_file(file_dir):images = [] # 存放的是每一张图片对应的地址和名称temp = [] # 存放的是文件夹地址for root, sub_folders, files in os.walk(file_dir):# image directoriesfor name in files:images.append(os.path.join(root, name))#print(images)#print(files)#print(images)# 读取当前目录选的文件夹for name in sub_folders:temp.append(os.path.join(root, name))#print(temp)print(sub_folders)print('a--------------a')print(images)print(temp)print('--------------finish---------------')# 为数据集打标签,cat为0,dog为1labels = []error = 0for one_folder in temp:n_img = len(os.listdir(one_folder)) # os.listdir()返回指定的文件夹包含的文件或文件夹的名字的列表,再用len求该文件夹里面图像的数目print(one_folder)print(n_img)letter = one_folder.split('\\')[-1] # 对路径进行切片,[-1]为取切片后的最后一个元素(也就是文件夹名称)。用于根据名称去判断数据集的样本类型#print(letter)if letter == 'cat':labels = np.append(labels, n_img * [0]) # 向labels里面添加1*n_img个0elif letter == 'dog':labels = np.append(labels, n_img * [1])else:error = error + 1print(labels)print(error)temp = np.array([images, labels])#print(temp)temp = temp.transpose() # 矩阵转置#print(temp)np.random.shuffle(temp) # shuffle() 是将序列的所有元素随机排序。#print(temp)image_list = list(temp[:, 0]) # 所有行,第0列label_list = list(temp[:, 1]) # 所有行,第1列print(label_list) # ['1.0', '1.0', '1.0', '0.0', '0.0', '0.0']label_list = [int(float(i)) for i in label_list] # 把字符型标签转化为整型print(label_list) # [1, 1, 1, 0, 0, 0]return image_list, label_listimages_list, labels_list = get_file('F:\\data\\testdata')
print('image transform finished', images_list)
print('label transform finished', labels_list)
上述代码中,首先对数据集图片的位置进行读取,之后根据文件夹名称的不同将不同文件夹中的图片标签设置为0或1,最后以矩阵的形式返回数据集存储图片的路径和对应的标签。
在这里就需要对下载好的原数据集进行调整,把train集里面的猫和狗图片分两个文件夹,一个cat文件夹全部装猫的图片,另外一个dog文件装狗的图片,程序就是根据cat和dog这两个名称对图片进行打标签。为了提高网络的分类精度,训练时最好把数据集打乱,这里就使用了np.random.shufle()对读入的数据集进行乱序操作。
另外一个更简洁的做法是不需要对train集里的猫、狗图片进行单独存储,直接对train集的所有猫、狗数据进行操作,标签是按图片的名称不同来打标签,cat为0,dog为1。代码基本和上面的差不多。
# 获取文件路径和标签
def get_files(file_dir):# file_dir: 文件夹路径# return: 乱序后的图片和标签cats = []label_cats = []dogs = []label_dogs = []# 载入数据路径并写入标签值for file in os.listdir(file_dir): # file_dir文件夹下所有的文件name = file.split(sep='.') # 对文件名以'.'做划分print(name)if name[0] == 'cat':#cats.append(file_dir + file)cats.append(os.path.join(file_dir,file))label_cats.append(0)elif name[0] == 'dog':#dogs.append(file_dir + file)dogs.append(os.path.join(file_dir,file))label_dogs.append(1)print("There are %d cats\nThere are %d dogs" % (len(cats), len(dogs)))print('cats:', cats)print('label_cats:', label_cats)print('dogs:', dogs)print('label_cats:', label_dogs)# 打乱文件顺序image_list = np.hstack((cats, dogs)) # 将cats和dogs矩阵按水平拼接print('image_list:', image_list)label_list = np.hstack((label_cats, label_dogs))print(label_list)temp = np.array([image_list, label_list])temp = temp.transpose() # 转置np.random.shuffle(temp) # 打乱顺序image_list = list(temp[:, 0])label_list = list(temp[:, 1])label_list = [int(i) for i in label_list]return image_list, label_listfile_dir = 'F:\\data\\testdata3\\train'
image_list, label_list = get_files(file_dir)
print(image_list)
print(label_list)






![[创业之路-57] :商业计划书BP如何书写?总体框架!](https://img-blog.csdnimg.cn/img_convert/2e5dbbd9f585694038db816484e78a0f.webp?x-oss-process=image/format,png)