使用 Node.js 读取 Excel 文件并处理合并单元格
在现代的数据处理任务中,Excel 文件是一种非常常见的数据存储格式。无论是数据分析、报表生成,还是数据迁移,Excel 文件都扮演着重要的角色。然而,处理 Excel 文件时,尤其是包含合并单元格的文件,可能会遇到一些挑战。本文将介绍如何使用 Node.js 读取 Excel 文件,并处理其中的合并单元格。
准备工作
首先,我们需要安装一些必要的 Node.js 库。我们将使用 xlsx 库来读取和解析 Excel 文件,使用 lodash 库来处理字符串。你可以通过以下命令安装这些库:
npm install xlsx lodash
读取 Excel 文件
我们首先需要读取 Excel 文件。假设我们的文件名为 YD-TP2025-03-22.xlsx,并且它位于当前项目的根目录下。我们可以使用 xlsx.readFile 方法来读取文件:
const xlsx = require('xlsx');
const path = require('path');const filePath = path.join(__dirname, 'YD-TP2025-03-22.xlsx');
const workbook = xlsx.readFile(filePath);
获取工作表
接下来,我们需要获取 Excel 文件中的特定工作表。假设我们的工作表名为 建设全流程明细,我们可以通过以下代码获取该工作表:
const sheetName = "建设全流程明细";
const sheet = workbook.Sheets[sheetName];
处理合并单元格
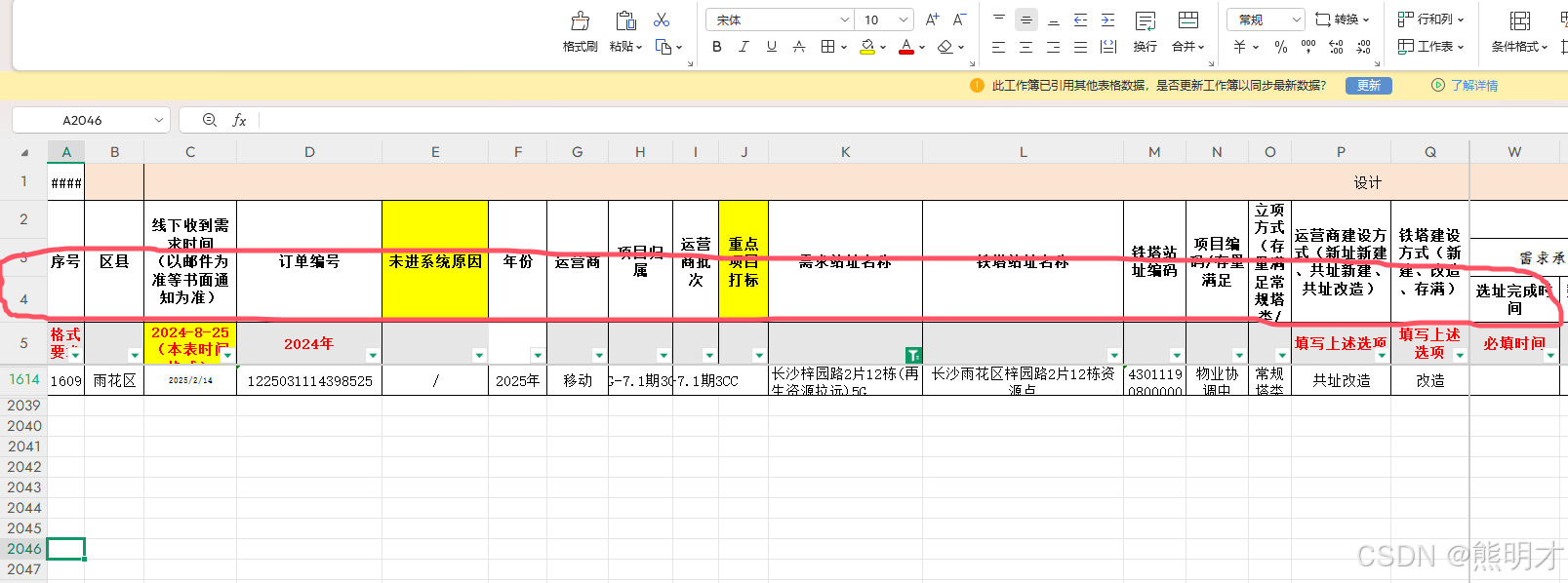
在处理 Excel 文件时,合并单元格是一个常见的挑战。合并单元格的值通常只存储在合并区域的左上角单元格中,其他单元格的值为空。为了正确处理合并单元格,我们需要获取合并单元格的信息,并根据这些信息来获取正确的值。
我们可以通过以下代码获取工作表的合并单元格信息:
const merges = sheet['!merges'] || [];
然后,我们定义一个函数 getMergedCellValue,用于获取合并单元格的值:
function getMergedCellValue(sheet, row, col) {for (const merge of merges) {const { s, e } = merge; // s: 合并区域的起始位置,e: 合并区域的结束位置if (row >= s.r && row <= e.r && col >= s.c && col <= e.c) {return sheet[xlsx.utils.encode_cell(s)]?.v;}}return sheet[xlsx.utils.encode_cell({ r: row, c: col })]?.v;
}
获取表头数据
假设我们的表头数据位于第 4 行,我们可以通过以下代码获取表头数据:
const headerTemplates = [];
const rowIndex = 3; // 第 4 行的索引(从 0 开始)
const range = xlsx.utils.decode_range(sheet['!ref']);for (let col = range.s.c; col <= range.e.c; col++) {const cellValue = getMergedCellValue(sheet, rowIndex, col);if (cellValue) {const address = xlsx.utils.encode_cell({ r: rowIndex, c: col }) + '';headerTemplates.push({address: address,value: removeTabsAndNewlines(cellValue),col: col + 1 // Excel 列从 1 开始计数});}
}
输出表头模板数据
最后,我们可以将获取到的表头数据输出为 JSON 格式:
console.log(JSON.stringify(headerTemplates, null, 2));
[Running] node "c:\Users\xiong\WebstormProjects\backendnodejs\src\models\scripts\tempCodeRunnerFile.js"
[{"address": "A4","value": "序号","col": 1},{"address": "B4","value": "区县","col": 2},{"address": "C4","value": "线下收到需求时间(以邮件为准等书面通知为准)","col": 3},{"address": "D4","value": "订单编号","col": 4},{"address": "E4","value": "未进系统原因","col": 5},{"address": "F4","value": "年份","col": 6},{"address": "G4","value": "运营商","col": 7},将数据转换为结构化 JSON
接下来,我们从第 5 行(索引为 4)开始读取数据,并将每一行数据转换为一个对象,其中键为表头字段,值为单元格内容。最后,将所有数据存储在一个数组中
const xlsx = require('xlsx');
const path = require('path');// 读取 Excel 文件
const filePath = path.join(__dirname, 'YD-TP2025-03-22.xlsx');
const workbook = xlsx.readFile(filePath);// 获取名为 "建设全流程明细" 的工作表
const sheetName = "建设全流程明细";
const sheet = workbook.Sheets[sheetName];// 获取工作表的合并单元格信息
const merges = sheet['!merges'] || [];// 定义一个函数,用于获取合并单元格的值
function getMergedCellValue(sheet, row, col) {for (const merge of merges) {const { s, e } = merge;if (row >= s.r && row <= e.r && col >= s.c && col <= e.c) {return sheet[xlsx.utils.encode_cell(s)]?.v;}}return sheet[xlsx.utils.encode_cell({ r: row, c: col })]?.v;
}// 获取表头数据(第 4 行)
const headerRow = [];
const headerRowIndex = 3; // 第 4 行的索引(从 0 开始)
const range = xlsx.utils.decode_range(sheet['!ref']);// 获取表头
for (let col = range.s.c; col <= range.e.c; col++) {const cellValue = getMergedCellValue(sheet, headerRowIndex, col);headerRow.push(cellValue || '');
}// 将数据转换为列表
const dataList = [];// 从第5行开始读取数据(索引4)
for (let row = headerRowIndex + 1; row <= range.e.r; row++) {const rowData = {};// 遍历每一列for (let col = range.s.c; col <= range.e.c; col++) {const cellValue = getMergedCellValue(sheet, row, col);// 使用表头作为键名rowData[headerRow[col]] = cellValue || '';}dataList.push(rowData);
}// 输出前5条数据作为示例
console.log('数据总条数:', dataList.length);
console.log('前5条数据示例:');
console.log(JSON.stringify(dataList.slice(5, 25), null, 2));
[Running] node "c:\Users\xiong\WebstormProjects\backendnodejs\src\models\scripts\excel_tolist.js"
数据总条数: 9
前5条数据示例:
[{"序号": 5,"区县": "长沙县","线下收到需求时间\n(以邮件为准等书面通知为准)": 45523,"订单编号": "新建选址","未进系统原因": "新建选址完成后进系统","年份": "2024年","运营商": "移动","项目归属": "岳麓山景区","运营商批次": "普通5G","重点项目打标": "","需求站址名称": "长沙岳麓岳麓山东门路口微站H-H5X","铁塔站址名称": "","铁塔站址编码": "","项目编码/存量满足": "","立项方式(存量满足常规塔类/区域化塔类/非标改造)": "微站","运营商建设方式(新址新建、共址新建、共址改造)": "新址新建","铁塔建设方式(新建、改造、存满)": "新建","产品单元数": 1,"建设类型(地面站,楼面站)": "地面站","建设方案\n(含所有建设工程量)": "利旧电力路灯杆,新增光电一体箱,新增支臂,外市电","打标": "2、地面新建","订单导入时间": "",............
总结
通过以上步骤,我们成功地使用 Node.js 读取了 Excel 文件,并处理了其中的合并单元格。这种方法不仅适用于获取表头数据,还可以用于处理其他复杂的 Excel 数据。希望这篇文章能帮助你在处理 Excel 文件时更加得心应手。
如果你有任何问题或建议,欢迎在评论区留言!






![git | 回退版本 并保存当前修改到stash,在进行整合。[git checkout | git stash 等方法 ]](https://i-blog.csdnimg.cn/direct/ee00457b8a034146abd41f436cffe983.png)








![[项目]基于FreeRTOS的STM32四轴飞行器: 十一.MPU6050配置与读取](https://i-blog.csdnimg.cn/direct/9f628a6224fc4eeb809933ac6164cd81.png)



