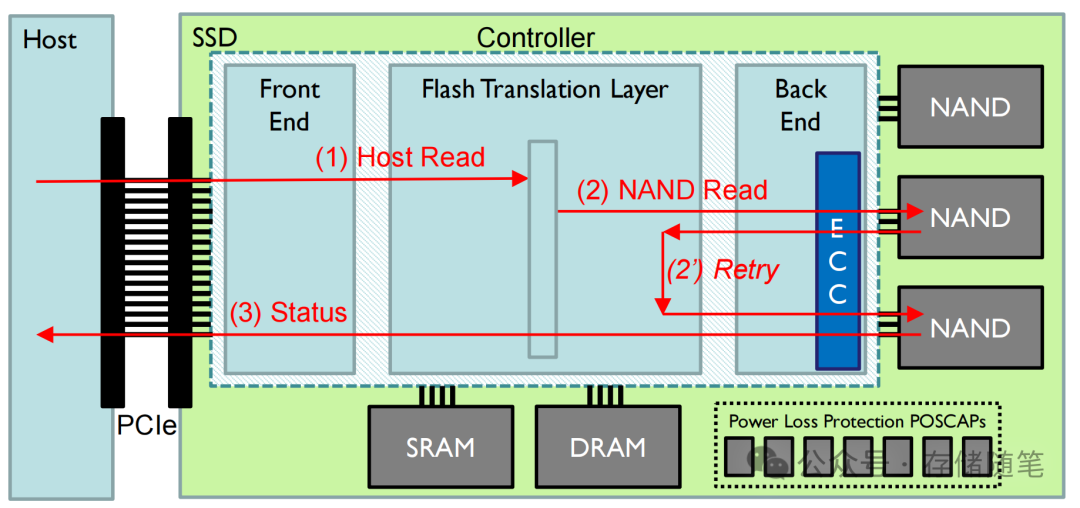
SwiftSage:参考人脑双系统,结合快思和慢想的智能体,解决复杂任务同时降低成本
- 提出背景
- 解法拆解
- 子解法1:SWIFT模块
- 子解法2:SAGE模块
- 模块整合和决策树
- 逻辑链
- SwiftSage 工作流程
- 效果
论文:SWIFTSAGE: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks
代码:https://github.com/yuchenlin/swiftsage/
提出背景
传统的人工智能方法如强化学习和行为克隆在简单任务中表现不错,但在复杂任务中处理能力有限,尤其是在应对长期记忆和未知异常时。
而利用大型语言模型的方法虽然能更好地规划复杂任务并根据反馈调整,但每次预测都需要调用模型,导致效率低下和成本高昂。
这两种方法都需要在复杂性处理和成本效率上进行改进。
此外,ReAct 和 Reflection 两种方法还需要针对每种未知任务类型进行适当的子目标人工标注。
SWIFTSAGE是一个基于人类认知的双过程理论设计的框架,专门用于复杂的交互式推理任务中的行动规划。
它包含两个主要模块:SWIFT模块(人类的直觉思维 - 模仿学习)和SAGE模块(深思熟虑的思维 - 通过LLM提示)。
- SWIFT模块代表快速直觉式的思维,使用一个小型的编码-解码语言模型,这个模型通过学习最佳行动路径来进行训练。
- SAGE模块则模仿深思熟虑的思维过程,使用像GPT-4这样的大型语言模型来进行子目标规划和理解。
通过这种设计,SWIFTSAGE能够将直觉快速的决策和深入的思考有效结合,提高解决复杂交互任务的能力。
效果:在一个名为ScienceWorld的基准测试中,SWIFTSAGE在30个任务上表现优于其他一些方法,如SayCan、ReAct和Reflexion。

这张图比较了四种使用 LLM 来构建交互式任务代理的方法:SayCan、ReAct、Reflexion和SWIFTSage。
-
SayCan:
- 示例任务是烧水,需要在每个时间步骤用LLM生成行动。
- 例如,先去厨房,然后环顾四周,接着捡起金属锅,并最终把锅放在炉子上。
- LLM生成一系列可能的行动,然后进行重新排序以选择最佳行动。
-
ReAct:
- 与SayCan类似,但在每个行动步骤之前会有一个思考过程,例如思考需要把锅放在加热器上。
- LLM直接生成行动。
-
Reflexion:
- 反映上一轮失败的行动历史,以改进当前的行动选择。
- 每个时间步骤中,LLM都基于完整的行动历史生成新的行动。
-
SWIFTSage:
- 采用双模块策略,其中SWIFT模块用于生成即时行动,SAGE模块用于计划和跟踪子目标,处理在线异常。
- SAGE模块还涉及“地面模板”来实现行动,并使用行动缓冲机制。
SWIFTSage通过其独特的双模块设计,结合快速直觉反应和深度分析计划,优化了任务执行效率和成本,特别在处理复杂和未知情境下的适应性和异常处理能力方面表现出色,成为一个在多变和复杂环境中高效的智能代理解决方案。
解法拆解
为了克服这些挑战,SWIFTSAGE引入了两个互补的模块:SWIFT模块和SAGE模块,它们分别处理快速直觉思维和深度分析思维。
子解法1:SWIFT模块
Swift 模块利用了一个小型的编码器-解码器语言模型,能够编码诸如先前动作、当前观察、已访问位置及当前环境状态等短期记忆内容,并据此解码生成下一步的动作。
利用丰富的离线数据,Swift 模块通过模仿学习的方法——行为克隆,可以深入理解目标环境的设定,并更准确地把握任务需求。
- 功能:SWIFT模块采用模仿学习,通过快速直觉思维迅速生成反应。
- 原因:这种方法适用于处理已知情境下的任务,因为它可以快速从历史行动中学习,但在新场景或复杂情境中可能不够准确或鲁棒。
- 例子:如果任务是在熟悉的环境中找到并使用特定物品,SWIFT模块能够快速给出行动方案。
子解法2:SAGE模块
GPT-4 等大型语言模型(LLM)显著增强了任务规划的精确性。
Sage 模块通过规划与融合这两个阶段的LLM提示,精细地梳理任务路径。
在规划阶段,我们的目标是使 LLM 能够精准识别所需物品的位置、细化任务子目标、并且及时发现及修正可能出现的错误或异常。
为此,我们设计了五个关键问题,帮助智能体在执行任务时敏锐地识别并应对任何异常情况,增加任务成功的可能性。
- Q1(定位对象):要求模型确定完成任务所需的具体对象及其可能的位置。
- Q2(追踪对象):询问是否还有未收集的对象,确保所有必需品已被获取。
- Q3(规划子目标):要求模型列出完成任务所需的关键子目标,以有效地组织行动计划。
- Q4(追踪进展):让模型评估已完成的子目标,并决定当前应专注的子目标,以保持任务进展的连贯性。
- Q5(处理异常):询问模型在执行任务过程中是否遇到了可能妨碍下一子目标完成的错误,并探讨如何纠正这些错误。
这些问题使得Sage模块不仅能够进行深度规划,还能动态调整其行动策略,从而提高处理复杂任务的效率和成功率。
在融合阶段,Sage 模块的主要任务是将规划阶段所得的信息——五个核心问题的答案和动作模板——转换成一连串具体可行的操作步骤,形成了所谓的动作缓冲区。
这种方法的独特之处在于,Sage 模块不仅仅是生成即刻的单个动作,而是制定一个涵盖多步操作的综合行动计划。
为此,LLM 被赋予了包含子目标和可采用的行动模式的详细指令,使其能够依次产生一系列的行动,每一步都紧密对应于既定的子目标,这与传统的逐一行动生成方式不同。
- 功能:SAGE模块通过引导式的大型语言模型(LLM),进行深入的规划和分析,处理复杂的子目标和异常情况。
- 原因:这种方法适用于未知或更复杂的任务,因为它能够进行深入分析,生成详细的行动计划和应对策略。
- 例子:在面对一个新的科学实验任务,如测试未知物质的导电性,SAGE模块可以详细规划实验步骤和所需物品。
模块整合和决策树
- 决策条件:根据任务的复杂度和遇到的问题,智能代理会在SWIFT和SAGE之间切换。
- 如果连续几步操作没有得到预期结果(如没有获得分数),或者遇到了关键决策点,或者当前策略无效,代理会从SWIFT模式切换到SAGE模式。
- SAGE模式会详细规划下一步行动,生成一个行动缓存,并在执行完这些行动后,可能会重新切换回SWIFT模式以继续任务。
这种双模块的设计使得SWIFTSAGE能够灵活应对各种任务情境,有效整合快速和慢速思维的优势,从而提高在复杂交互式环境中的表现。
逻辑链
SWIFTSAGE框架
├── 双过程理论【基础理论支持】
│ ├── 系统1 (快速直觉)【思维模式分类】
│ │ └── SWIFT模块【实现机制】
│ │ ├── 短期记忆编码【功能实现】
│ │ └── 下一步行为解码【功能实现】
│ └── 系统2 (缓慢分析)【思维模式分类】
│ └── SAGE模块【实现机制】
│ ├── 计划阶段【任务处理步骤】
│ │ ├── 定位必需物品【子任务】
│ │ ├── 规划子目标【子任务】
│ │ └── 检测和修正错误【子任务】
│ └── 执行阶段【任务处理步骤】
│ └── 将计划转化为行动序列【功能实现】
├── 复杂交互推理任务【框架应用领域】
│ ├── 任务环境【环境特性】
│ │ └── ScienceWorld环境特性【具体环境】
│ │ ├── 10个位置【环境细节】
│ │ ├── 200种物品状态【环境细节】
│ │ └── 25种行动模板【环境细节】
│ └── 任务执行评估【性能衡量】
│ ├── 性能比较【评估方法】
│ │ ├── 与SAYCAN比较【对比对象】
│ │ ├── 与REACT比较【对比对象】
│ │ └── 与REFLEXION比较【对比对象】
│ └── 效率分析【评估方法】
│ └── 每个行动的代币消耗【效率指标】
└── 学习方法【框架技术基础】├── 强化学习【方法类别】│ └── DRRN方法【具体实现】│ ├── 观察与行动的分离【特性说明】│ └── 基于反馈的行动选择【特性说明】├── 行为克隆【方法类别】│ └── seq2seq学习【具体实现】│ ├── 从oracle agent学习【学习来源】│ └── 奖励预测输入【功能特性】└── 大型语言模型提示【方法类别】├── GPT-4的应用【具体实现】│ └── 长期行动计划生成【功能实现】└── 模型透明度和可解释性【目标】└── 通过CBL方法展示概念与神经元的对应关系【实现手段】
SwiftSage 工作流程

这张图展示了 SWIFTSAGE 智能代理如何通过结合快速的 SWIFT 模块和深度分析的 SAGE 模块,高效处理一个融化冰淇淋的任务,特别在遇到异常时如何灵活切换并制定详细的行动计划。
这个过程分为几个关键步骤:
-
任务描述与环境状态:
- 任务是融化冰淇淋,当前的环境描述包括冰箱、橙子、锅等物品和位置信息(如厨房、走廊等已访问地点)。
-
SWIFT模块动作:
- 基于历史行动和当前环境,SWIFT模块建议的下一个动作是激活炉子。
- 但观察到炉子坏了,无法使用。
-
切换到SAGE模块:
- 因为遇到了异常(炉子坏了),系统切换到SAGE模块。
- SAGE模块通过大型语言模型(如GPT-4)进行深入规划和问题解决。
-
SAGE模块的规划与执行:
- SAGE模块首先确定需要的对象,并规划如何达到子目标。
- 例如,发现需要一个工作的热源,然后把装有冰淇淋的金属锅放在热源上,等待冰淇淋融化。
- 接着,SAGE模块修正了使用坏掉的炉子的问题,并建议使用厨房中的烤箱作为热源。
-
动作缓冲区(Action Buffer):
- SAGE模块产生了一系列具体的操作步骤,包括打开烤箱、移动金属锅到烤箱、关闭烤箱并激活烤箱,这些操作都存储在动作缓冲区中,准备执行。
效果
在 ScienceWorld 中的 30 种任务中:
- SwiftSage 分数 84.7
- SayCan 分数 33.8
- ReAct 分数 36.4 分
- Reflexion 分数 45.3 分
成本方面,为了产生一个行动,Saycan 和 ReAct 需近 2000 个 token,Reflexion 需接近 3000 个 token,而 SwiftSage 仅需约 750 个 token。