前言
这篇文章也是记录近期遇到的问题以及从中学到的知识 ,近期一直在救火,有些问题自认为还是挺有代表性的,有兴趣的话再继续向下看
问题现象
线上反馈,执行批量处理EXCEL数据时,系统一直卡在进度滚动条界面。处理任务等了一个多小时也没有完成。起初,看到售后反馈这个问题时我很惊讶, 因为在这前一天,我还帮另一位售后完成了相同的处理操作。怎么隔一天就出问题了 。我习惯性的觉得操作员又弄错了配置或者又把数据填错了,处理这类问题是最让开发人员恼火的事情。
一般系统问题分两类, 要么是程序问题要么是数据问题, 找到售后拿到了问题视频记录, 看到传回来的视频发现售后人员操作满足流程要求,没有错误, 又核实了EXCEL模板并检查模板数据,最后排查代码也没有发现明显问题, 这就不好办了
问题分析
1. 系统中发现死锁
正当自己纠结的时候,售后告知问题复现, 能复现问题,那么就好解决了, 查询了下栈信息,发现系统多线程数据处理的时候都卡在了1条UPDATE语句上,堆栈信息如下。 (如果查看栈信息, 可参考另一篇文章 传送门:JVM记 jstack命令的时候报错Unable to open socket file)
"pool-91-thread-1" prio=6 tid=0x53116800 nid=0x3bc8 in Object.wait() [0x51b2f000]java.lang.Thread.State: TIMED_WAITING (on object monitor)at java.lang.Object.wait(Native Method)at com.star.sms.batch.TransactionGuarded.doHold(TransactionGuarded.java:75)at com.star.sms.batch.TransactionGuarded.hold(TransactionGuarded.java:60)- locked <0x32269c70> (a com.star.sms.batch.TransactionGuarded)at com.star.sms.batch.AbstractBatchAcceptTask.processByGuarded(AbstractBatchAcceptTask.java:112)at com.star.sms.batch.AbstractBatchAcceptTask.call(AbstractBatchAcceptTask.java:56)2022-08-08 18:33:57,563 INFO [com.star.sms.business.accept2.BatchAcceptService$2] pool-91-thread-2 start|size=1
2022-08-08 18:33:57,600 INFO [com.star.sms.business.accept2.AcceptSheetContext] Current Thread: pool-91-thread-2 ######accept getsequence total time : 3 #####at com.star.sms.dao.utils.SmsJdbcTemplate.update(SmsJdbcTemplate.java:599)at com.star.sms.dao.resource.support.AbstractUpdateModel.doUpdate(AbstractUpdateModel.java:115)at com.star.sms.dao.resource.support.AbstractUpdateModel.insert(AbstractUpdateModel.java:77)at com.star.sms.dao.resource.AbstractResourceDaoJdbc.insert(AbstractResourceDaoJdbc.java:149)at com.star.sms.dao.resource.logicres.jdbc.CertResourceDaoImp.addCertResource(CertResourceDaoImp.java从日志上看, 发现很多线程都卡在了数据库update 操作上 ,所以怀疑是数据库出现了死锁,执行下面的SQL查询统计,确认是否库中存在死锁
with vw_lock AS (SELECT * FROM v$lock)
select
a.sid,
'is blocking',
(select 'sid:'||s.sid||' object:'||do.object_name||' rowid:'||dbms_rowid.rowid_create ( 1, ROW_WAIT_OBJ#, ROW_WAIT_FILE#, ROW_WAIT_BLOCK#, ROW_WAIT_ROW# )||' sql_id:'||s.sql_idfrom v$session s, dba_objects dowhere s.sid=b.sidand s.ROW_WAIT_OBJ# = do.OBJECT_ID
) blockee,
b.sid,b.id1,b.id2
from vw_lock a, vw_lock b
where a.block = 1
and b.request > 0
and a.id1 = b.id1
and a.id2 = b.id2;
select * from v$session_wait t where t.WAIT_CLASS#<>6;
查询结果:
SID SEQ# EVENT P1TEXT P1 P1RAW P2TEXT P2 P2RAW P3TEXT
381 465 enq: TX - row lock contention name|mode 1415053316 54580004 usn<<16 | slot 851989 000D0015 sequence
410 466 enq: TX - row lock contention name|mode 1415053316 54580004 usn<<16 | slot 851989 000D0015 sequence
411 468 enq: TX - row lock contention name|mode 1415053316 54580004 usn<<16 | slot 851989 000D0015 sequence
431 475 enq: TX - row lock contention name|mode 1415053316 54580004 usn<<16 | slot 851989 000D0015 sequence
从查询结果发现,库中存在大量的行锁 enq: TX - row lock contention。 enq 是一种保护共享资源的锁定机制,一个排队机制
为了进一步确认那些个SQL死锁,通过行锁记录的SID 查询SQL详情,SQL如下
select se.SID, se.sql_id,se.SERIAL#,event,program,machine,q.SQL_TEXT,q.SQL_FULLTEXT,q.LAST_ACTIVE_TIMEfrom v$session se, v$sql qwhere wait_class# <> 6and se.SQL_ID = q.SQL_IDand sid in (371,378,379,386,391)查询结果
SQL_ID EVENT PROGRAM MACHINE SQL_TEXT SQL_FULLTEXT
9vg758n0nm8vt enq: TX - row lock contention JDBC Thin Client star10001874 INSERT INTO LOGICRESOURCEEN... <CLOB>
9p3mtvy6ztgxq SQL*Net message to client PlSqlDev.exe BJ\STAR10001874 select se.sql_id,event, .... <CLOB>
9vg758n0nm8vt enq: TX - row lock contention JDBC Thin Client star10001874 INSERT INTO LOGICRESOURCEEN... <CLOB>
9vg758n0nm8vt enq: TX - row lock contention JDBC Thin Client star10001874 INSERT INTO LOGICRESOURCEEN... <CLOB>
9vg758n0nm8vt enq: TX - row lock contention JDBC Thin Client star10001874 INSERT INTO LOGICRESOURCEEN... <CLOB>从查询结果看到,几个会话都有 TX锁,并且都是执行INTO LOGICRESOURCEEN.。然后查看线程栈日志中 SmsJdbcTemplate#update内容, 发现确实也是在执行LOGICRESOURCEEN表添加操作。
TX 锁问题找到了, 那么为什么会产生TX锁呢?因为不了解TX锁所以查询了官方的文档。 我们用的是10g 版本的ORACEL, 下面的信息也是10g相关
2. Oracle 官方资料中TX相关描述
从查询结果看, 行锁发生在IINSERT NTO LOGICRESOURCEEN... 插入语句上 ,查询Oracle 官方资料中enq:TX - row lock contention. 相关信息
10.3.7.2.4 TX enqueue
These are acquired exclusive when a transaction initiates its first change and held until the transaction does a COMMIT or ROLLBACK.
10.3.7.2.4 TX排队
当事务启动其第一次更改时,这些数据将以独占方式获取,并一直保持到事务执行提交或回滚。
1. Waits for TX in mode 6: occurs when a session is waiting for a row level lock that is already held by another session. This occurs when one user is updating or deleting a row, which another session wishes to update or delete. This type of TX enqueue wait corresponds to the wait event enq: TX - row lock contention.
The solution is to have the first session already holding the lock perform a COMMIT or ROLLBACK.
大概意思:模式6TX等待:发证在当会话正在等待另一个会话已持有的行级锁时。即当一个用户正在更新或删除另一个会话希望更新或删除的行时,会发生这种情况。这种类型的TX排队等待对应于等待事件enq:TX - row lock contention.
解决方案:已经持有锁的第一个会话执行提交或回滚
2. Waits for TX in mode 4 can occur if the session is waiting for an ITL (interested transaction list) slot in a block. This happens when the session wants to lock a row in the block but one or more other sessions have rows locked in the same block, and there is no free ITL slot in the block. Usually, Oracle dynamically adds another ITL slot. This may not be possible if there is insufficient free space in the block to add an ITL. If so, the session waits for a slot with a TX enqueue in mode 4. This type of TX enqueue wait corresponds to the wait event enq: TX - allocate ITL entry.
The solution is to increase the number of ITLs available, either by changing the INITRANS or MAXTRANS for the table (either by using an ALTER statement, or by re-creating the table with the higher values).
大概意思:如果会话正在等待块中的ITL:当会话想要锁定块中的行,但一个或多个其他会话在同一块中锁定了行,并且块中没有空闲的ITL插槽时,会发生这种情况。通常,Oracle会动态添加另一个ITL插槽。如果区块中没有足够的可用空间来添加日志。 如果没有足够空间, 会话将在模式4中等待具有TX排队的插槽。这种类型的TX排队等待对应于“等待事件enq:TX-allocateITL entry”
解决方案:通过更改表的INITRANS或MAXTRANS(通过使用ALTER语句或通过使用更高的值重新创建表)来增加可用的ITL数量
备注: 之前也遇到过这个问题ITL事务槽不足引发了enq:TX-allocateITL entry等待事件, 有兴趣可进入传送门 ( 传送门:Oracle死锁问题: enq: TX - allocate ITL entry )
3. Waits for TX in mode 4 can also occur if a session is waiting due to potential duplicates in UNIQUE index. If two sessions try to insert the same key value the second session has to wait to see if an ORA-0001 should be raised or not. This type of TX enqueue wait corresponds to the wait event enq: TX - row lock contention.
The solution is to have the first session already holding the lock perform a COMMIT or ROLLBACK.
大概意思:如果会话由于唯一索引中的潜在重复而正在等待,如果两个会话试图插入相同的键值,则第二个会话必须等待,以查看是否应引发ORA-0001。这种类型的TX排队等待对应于“等待事件enq:TX - row lock contention.”
解决方案:已经持有锁的第一个会话执行提交或回滚
4. Waits for TX in mode 4 is also possible if the session is waiting due to shared bitmap index fragment. Bitmap indexes index key values and a range of ROWIDs. Each 'entry' in a bitmap index can cover many rows in the actual table. If two sessions want to update rows covered by the same bitmap index fragment, then the second session waits for the first transaction to either COMMIT or ROLLBACK by waiting for the TX lock in mode 4. This type of TX enqueue wait corresponds to the wait event enq: TX - row lock contention.
如模式4TX等待:会话由于共享位图索引片段而等待。位图索引索引键值和一系列行ID。位图索引中的每个“entry”可以覆盖实际表中的许多行。如果两个会话希望更新同一位图索引片段所覆盖的行,则第二个会话通过等待模式4中的TX锁来等待第一个事务提交或回滚。这种类型的TX排队等待对应于“等待事件enq:TX - row lock contention.
5. Waits for TX in mode 4 also occur when a transaction inserting a row in an index has to wait for the end of an index block split being done by another transaction. This type of TX enqueue wait corresponds to the wait event enq: TX - index contention.
当在索引中插入行的事务必须等待另一个事务完成的索引块拆分结束时,会发生TX锁等待。这种类型的TX排队等待对应于“等待事件 enq: TX - index contention.”
从上述内容分析可以可知, 通过COMMIT or ROLLBACK可以解锁, 参考SQL
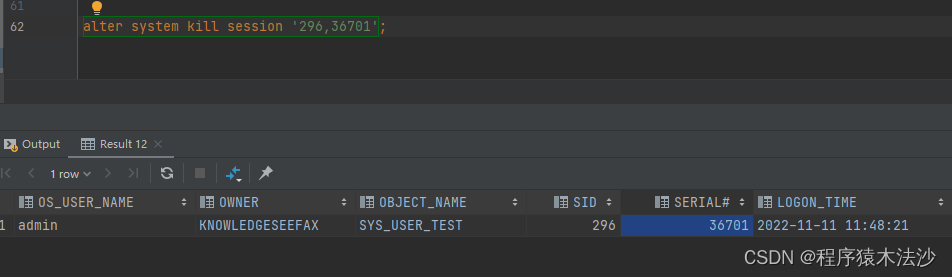
--KILL 锁住的session
--例如:alter system kill session 'sid,serial#';alter system kill session '371,52558';
alter system kill session '378,10931';
alter system kill session '379,34850';
alter system kill session '386,35260';
3. 为什么INSERT 产生enq:TX - row lock contention.
从官网看,引起 enq:TX - row lock contention.等待事件的最大可能是LOGICRESOURCEEN中存在唯一约束。 查看表结构,数据表LOGICRESOURCEEN存在唯一约束RADIUSUNIQUE
alter table LOGICRESOURCEENadd constraint UQ_LGCRES_RADUSU unique (RADIUSUNIQUE)创建唯一约束的时候会同时创建唯一索引
select * from user_indexes where table_name='LOGICRESOURCEEN';查询结果:
INDEX_NAME UNIQUENESS TABLE_NAME INDEX_TYPE TABLE_TYPE
UQ_LGCRES_RADUSU UNIQUE LOGICRESOURCEEN NORMAL TABLE
PK_LOGICRESOURCEEN UNIQUE LOGICRESOURCEEN NORMAL TABLE
IDX$LOGRES_RADIUSCODESTR NONUNIQUE LOGICRESOURCEEN NORMAL TABLE
IDX$LOGRES_IPSTR NONUNIQUE LOGICRESOURCEEN NORMAL TABLE4. 模拟自测
1. 两个事务分别向表LOGICRESOURCEEN做INSERT 操作,两次操作radiusunique完全相同
第一个事务执行后不COMMIT
第二个事务执行INSERT 后,卡死,无法执行COMMIT操作
此时查询数据库,库中存在两条执行记录的 enq: TX - row lock contention锁
2. 两个事务分别向表LOGICRESOURCEEN做INSERT 操作,两次操作radiusunique不同时
第一个事务执行后不COMMIT
第二个事务执行INSERT 后可以COMMIT操作
问题原因
当确认是因为LOGICRESOURCEEN表中的RADIUSUNIQUE字段的值出现了相同值引发了死锁。所以排查 RADIUSUNIQUE 字段产生的方式。 通过这个突破口很容易就发现RADIUSUNIQUE字段生成规则存在缺陷, 特定条件下会产生相同的编码。最终,通过解决程序问题避免RADIUSUNIQUE相同解决enq:TX - row lock contention.等额问题
整个排查过程学到了很多,另外也发现工作中要保持一颗平常心,勿急、勿燥、勿上火。
希望对看到这篇文章的朋友有所帮助
上一篇:Oracle 如何使用循环控制关键字exit、goto、continue