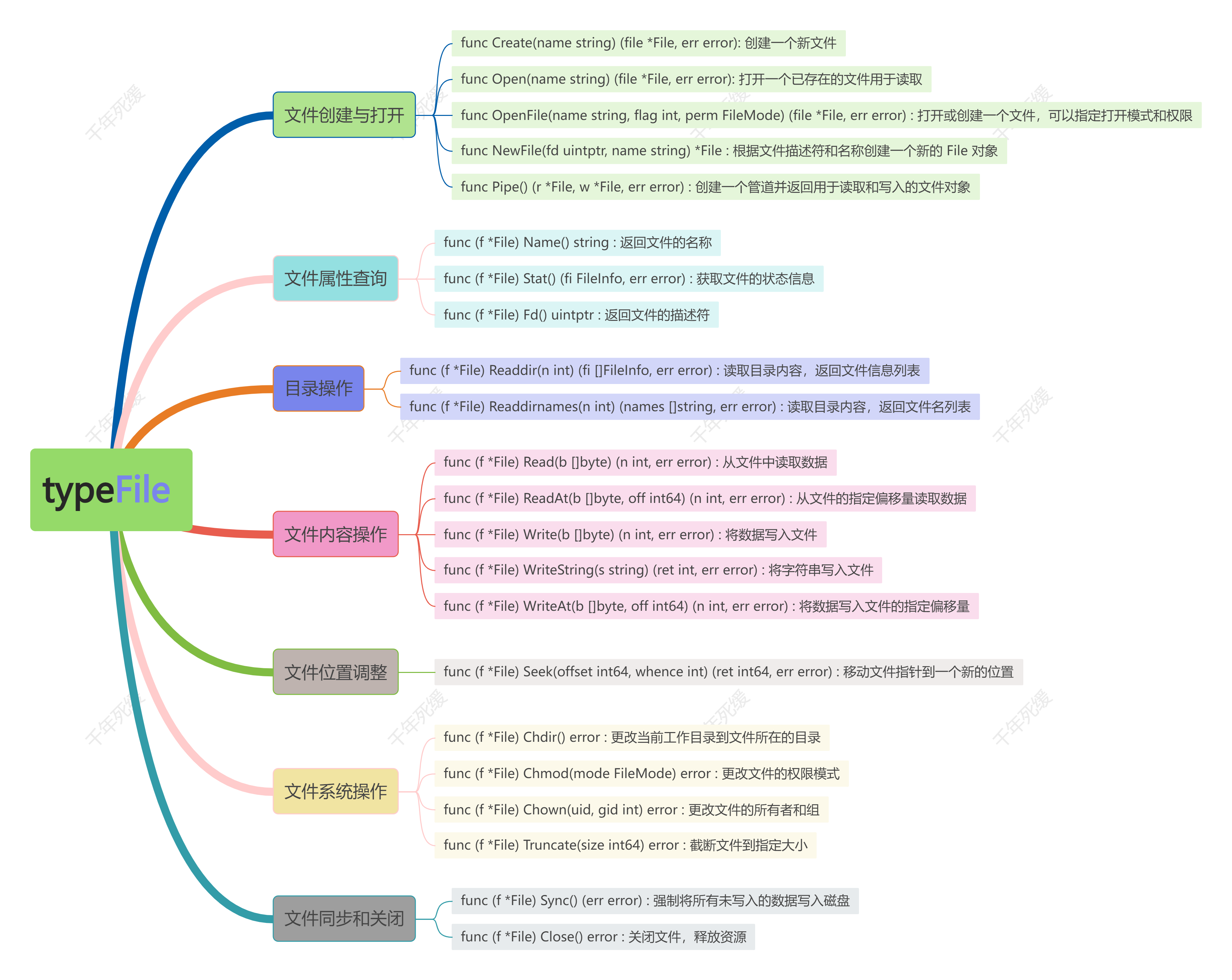
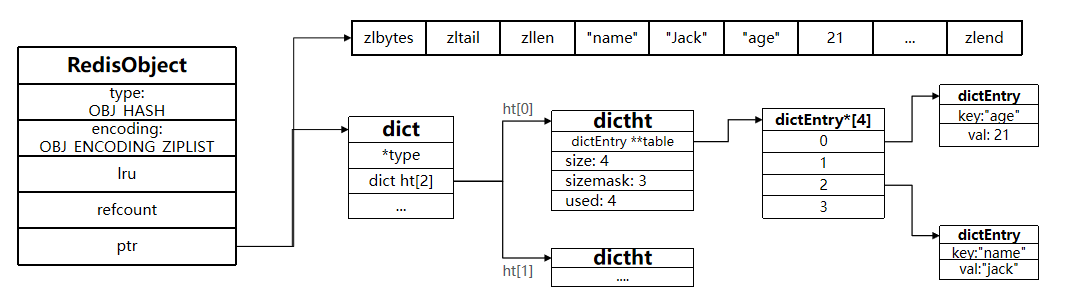
数据湖(Data Lake)是一个集中式存储库,用于存储大量的原始数据,包括结构化、半结构化和非结构化数据。这些数据可以以其原始格式存储,而不需要事先定义结构(即模式),这与传统的数据仓库(Data Warehouse)有所不同。

数据湖的主要特征
-
原始数据存储:数据湖中的数据可以是原始的、未处理的数据,这些数据在进入数据湖时不需要进行预先处理或模式定义。
-
多种数据类型:数据湖能够处理各种数据类型,包括文本、图像、视频、传感器数据、日志数据等。
-
高扩展性:数据湖通常构建在分布式存储系统之上,如Hadoop分布式文件系统(HDFS)或云存储(如Amazon S3),能够支持大规模数据存储和处理。
-
灵活性:由于数据湖不需要预定义模式,因此它们具有极大的灵活性,可以适应不同的数据分析需求。
-
成本效益:相比于传统数据仓库,数据湖的存储成本通常较低,因为可以使用廉价的存储设备来存储大量数据。
数据湖的组成部分
-
数据源:数据湖可以从多种数据源中获取数据,包括数据库、数据仓库、传感器、社交媒体、日志文件等。
-
数据存储:数据湖中的数据通常存储在分布式文件系统或云存储中,能够处理大规模数据。
-
数据处理:数据湖可以利用多种数据处理工具和框架,如Apache Hadoop、Apache Spark、Presto等,进行数据清洗、转换、分析等操作。
-
数据管理:为了确保数据湖中的数据高效可用,需要进行数据管理,包括数据编目、数据治理、数据安全等。
-
数据访问:用户可以通过多种方式访问数据湖中的数据,包括SQL查询、机器学习工具、数据可视化工具等。
数据湖的优势
-
灵活性和敏捷性:数据湖允许数据科学家和分析师根据需要提取和分析数据,无需预先定义和设计数据模式。
-
支持大数据和多种数据类型:数据湖能够处理来自不同来源的大规模数据,适用于各种数据分析和机器学习任务。
-
成本效益高:使用低成本存储设备或云存储,降低数据存储和管理成本。
数据湖的挑战
-
数据治理和管理:由于数据湖存储的是原始数据,可能存在数据质量和一致性问题,需要有效的治理和管理策略。
-
性能问题:在处理大规模数据时,可能会遇到性能瓶颈,需要优化数据处理流程。
-
安全和隐私:数据湖中的数据通常较为敏感,需要确保数据的安全和隐私保护。
数据湖的开源实现
1. Apache Hudi
- 简介:Hudi(Hadoop Upserts Deletes and Incrementals)是一个用于大数据湖的存储管理框架,提供了在 HDFS 上进行高效存储和处理的能力。
- 特点:支持增量数据处理、ACID 事务、时间旅行查询。
2. Apache Iceberg
- 简介:Iceberg 是一个高性能的表格式数据存储框架,能够管理大规模数据集并支持高效的读写操作。
- 特点:支持表分区、时间旅行、ACID 事务、兼容多种计算引擎(如 Spark、Presto)。
3. Delta Lake
- 简介:Delta Lake 是一个开源存储层,构建在 Apache Spark 之上,能够提供 ACID 事务、数据版本控制和高效查询。
- 特点:支持增量数据处理、时间旅行、高性能查询。
总之,数据湖是一种灵活且高效的大数据存储和处理解决方案,适用于需要存储和分析多种类型和大规模数据的场景。然而,为了充分利用数据湖的优势,同时克服其挑战,需要有效的数据管理和治理策略。