你的大语言模型是不是也患上了"长文健忘症"?当使用大模型遇到长上下文时总是会出现词不达意?别担心,LLM界的"记忆大师"来啦!华为诺亚方舟实验室最新推出的EM-LLM模型,就像是给大模型装上了"超级记忆芯片",让它们轻松应对天文数字般的超长文本。这个创新模型巧妙地将人类认知科学中的事件分割和情景记忆原理融入到了LLM中,让大模型也能像人脑一样高效处理超长文本。
EM-LLM的核心秘诀在于它模仿了人类大脑处理信息的方式。它能够自动将长文本切分成有意义的"事件",并建立类似人类情景记忆的存储结构。这种设计不仅让模型能够更好地理解和记忆长文本的内容,还能在需要时快速检索相关信息。
在LongBench长文本基准测试中,EM-LLM的整体性能超越了此前的最佳模型,平均提升4.3%。特别是在段落检索任务上,EM-LLM表现依旧非常出色,性能提升高达33%,充分展示了其在长文本理解和信息检索方面的卓越能力。

论文标题:
HUMAN-LIKE EPISODIC MEMORY FOR INFINITE CONTEXT LLMS
论文链接:
https://arxiv.org/pdf/2407.09450
LLM的"长上下文记忆"挑战
在人工智能快速发展的今天,大语言模型(LLM)已经成为了各行各业的得力助手。然而,这些AI"助手"却面临着一个棘手的问题:一旦遇到长文本,它们的表现就会大打折扣,仿佛患上了"长文健忘症"。这个问题严重制约了LLM在实际应用中的表现,特别是在需要处理长篇文档、复杂报告或大量上下文信息的场景中。
为什么会出现这个问题呢?主要是因为现有的LLM在处理长文本时面临着三大挑战:
-
计算复杂度问题:Transformer架构中的自注意力机制的计算复杂度随文本长度呈平方增长。这意味着当处理长文本时,计算资源的消耗会急剧增加,导致处理效率大幅下降。
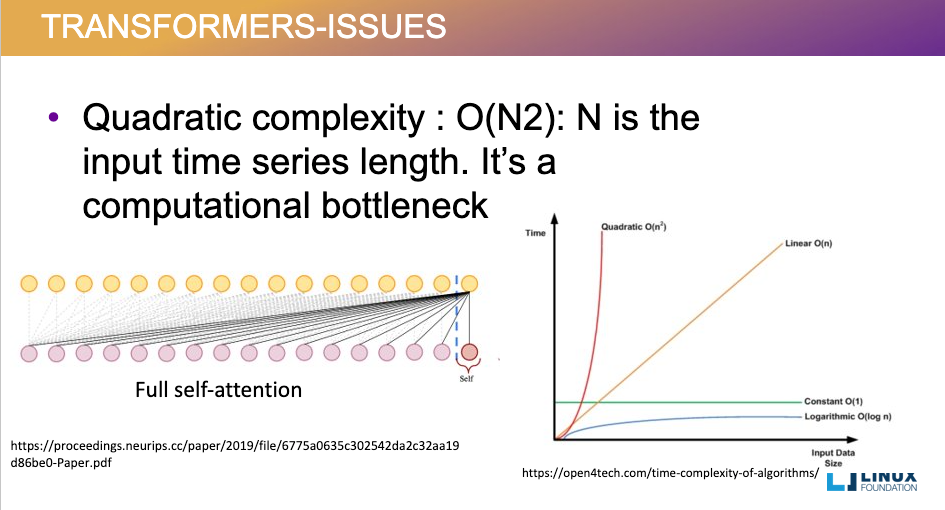
-
位置编码的局限性:现有的位置编码方法(如RoPE)难以有效地扩展到超出训练长度的文本,这使得模型在处理超长文本时难以准确捕捉词语之间的位置关系。
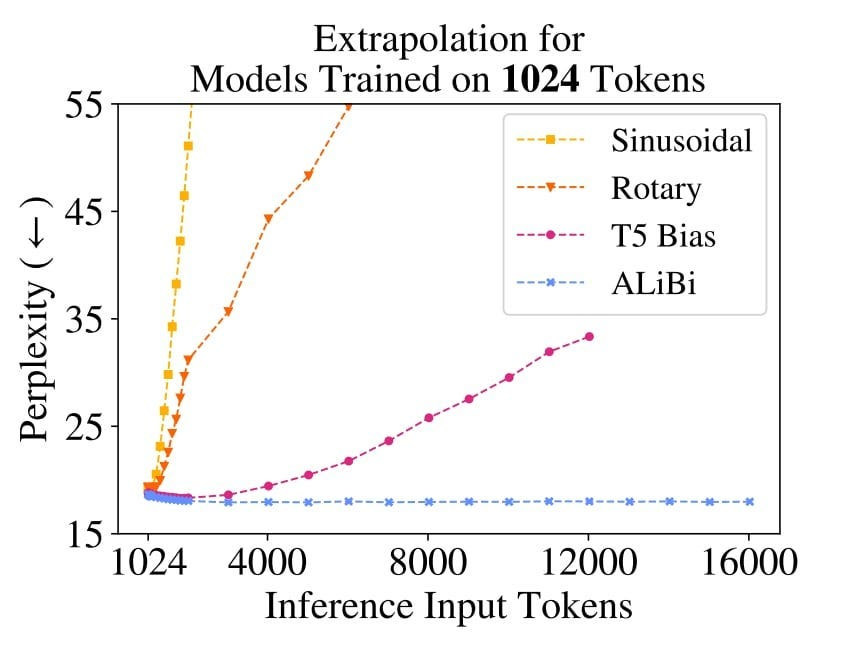
-
注意力分散问题:在长文本中,关键信息容易被大量不相关的内容"淹没"。模型难以在庞大的token序列中准确定位和提取重要信息。
面对这些挑战,研究人员提出了各种解决方案。其中,检索增强生成(RAG)和基于KV缓存的方法是两个主要方向。RAG方法通过外部知识库来增强模型的性能,而KV缓存方法则尝试在模型内部保存和检索历史信息。然而,这些方法仍然存在一些局限性,无法完全解决长文本处理的问题。
为解决这些问题,华为诺亚方舟实验室提出了创新的EM-LLM模型。EM-LLM的核心思想是模仿人类大脑的情景记忆机制,通过将长文本分割成离散的"事件"来组织和检索信息。
EM-LLM处理长文本可以分为三个步骤:
-
事件分割:模型首先识别文本中的"surprise"点,这些点可能是不同"事件"的分界。
-
记忆形成:识别出的事件被存储为离散的记忆单元,每个单元包含事件的关键信息。
-
记忆检索:当需要处理新输入时,模型会检索相关的历史事件。这个过程包括基于相似度的检索和考虑时间连续性的检索。
这种设计使EM-LLM能够有效处理超长文本,同时保持较低的计算复杂度。它不仅提高了LLM处理长文本的能力,同时还展示了将认知科学原理应用于人工智能的可行性。
给LLM装上"人脑芯片"
EM-LLM的核心思想是模仿人类大脑处理长期记忆的方式,主要包括三个关键步骤:基于惊奇度的事件分割、边界优化和两阶段记忆检索。让我们详细探讨每个步骤:
基于惊奇度的事件分割
EM-LLM首先对输入的长文本进行"事件分割"。这个过程通过计算每个词的"惊奇度"来判断是否应该在此处进行分割。具体来说,对于每个token ,模型计算其条件概率:
然后,通过计算负对数似然,得到惊奇度:
当惊奇度超过阈值 时,就认为在此处出现了一个事件边界:
其中,阈值 是动态计算的:
这里, 和 分别是前 个token的惊奇度均值和标准差, 是一个可调节的参数。
边界优化
初步的事件分割后,EM-LLM引入了边界优化步骤。这个过程使用图论中的概念,将token之间的相似度视为图的邻接矩阵。对于注意力头 ,邻接矩阵 定义为:
其中 和 是对应token的key向量,sim是相似度函数(这里使用点积相似度)。
优化过程使用两个指标:模块化(Modularity)和导电率(Conductance)。模块化 定义为:
其中 是图中总边权重, 是节点 所属的事件, 是克罗内克函数。
导电率 定义为:
其中 是图的一个子集, 是 内部的总边权重,其由以下的公式进行计算:
边界优化的目标是最大化模块化或最小化导电率,从而使事件内部的token更相关,事件之间更分离。
两阶段记忆检索
当模型需要处理新的输入时,它采用两阶段方法来检索相关的历史信息:
-
相似度检索:使用k近邻()搜索,找出与当前查询最相似的 个历史事件。这些事件形成"相似度缓冲区"。
-
连续性检索:为了模拟人类记忆的连续性特征,模型还会检索出上述事件在原文中的相邻事件,形成大小为 的"连续性缓冲区"。
最终,模型将 个事件添加到上下文窗口中。这种方法既考虑了信息的相关性,又保留了原始文本的时序特征。
下图直观地展示了这个过程:
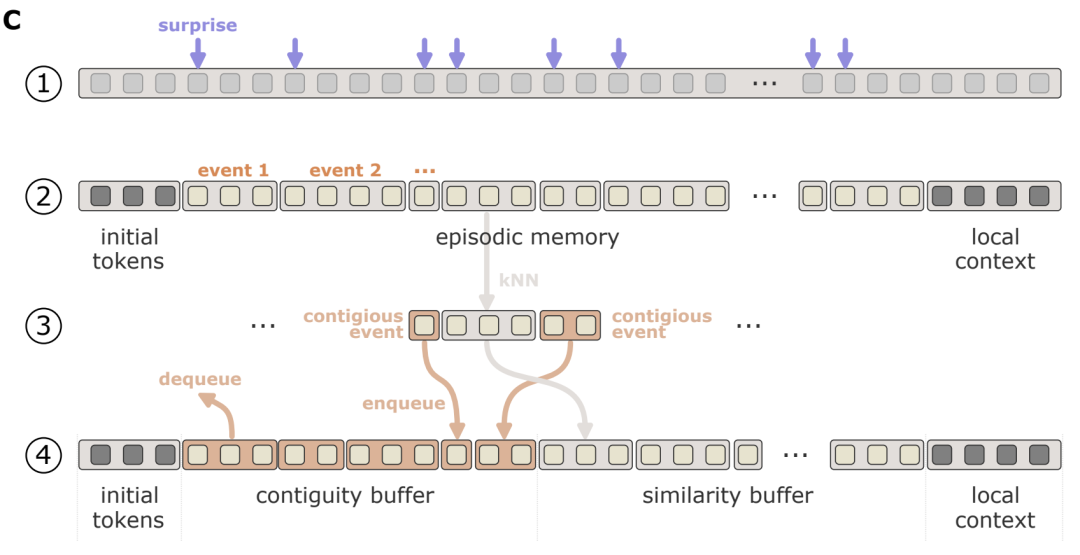
-
输入序列根据惊奇度进行初步分割。
-
形成离散的事件记忆,每个事件保留初始token和局部上下文。
-
通过 搜索选择相关事件。
-
最终的上下文窗口包括初始token、连续性缓冲区、相似度缓冲区和局部上下文。
这种设计使EM-LLM能够高效处理超长文本,同时保持了对重要信息的准确检索和利用。通过模仿人类记忆机制,EM-LLM在提高长文本处理能力的同时,也为我们理解人类认知过程提供了新的视角。
EM-LLM的"过目不忘"大考验
华为诺亚方舟实验室的研究人员设计了一系列全面的实验来测试EM-LLM的性能。这些实验不仅展示了EM-LLM在长文本处理方面的卓越表现,还深入探讨了其工作原理与人类认知的相似性。
LongBench测试
研究人员首先在LongBench长文本基准测试上对EM-LLM进行了评估。这个测试就像是AI界的"马拉松",考验模型的"长跑"能力。
下表展示了EM-LLM在LongBench上的表现,EM-LLM在15个任务中的14个上都超越了此前的最佳模型——InfLLM。
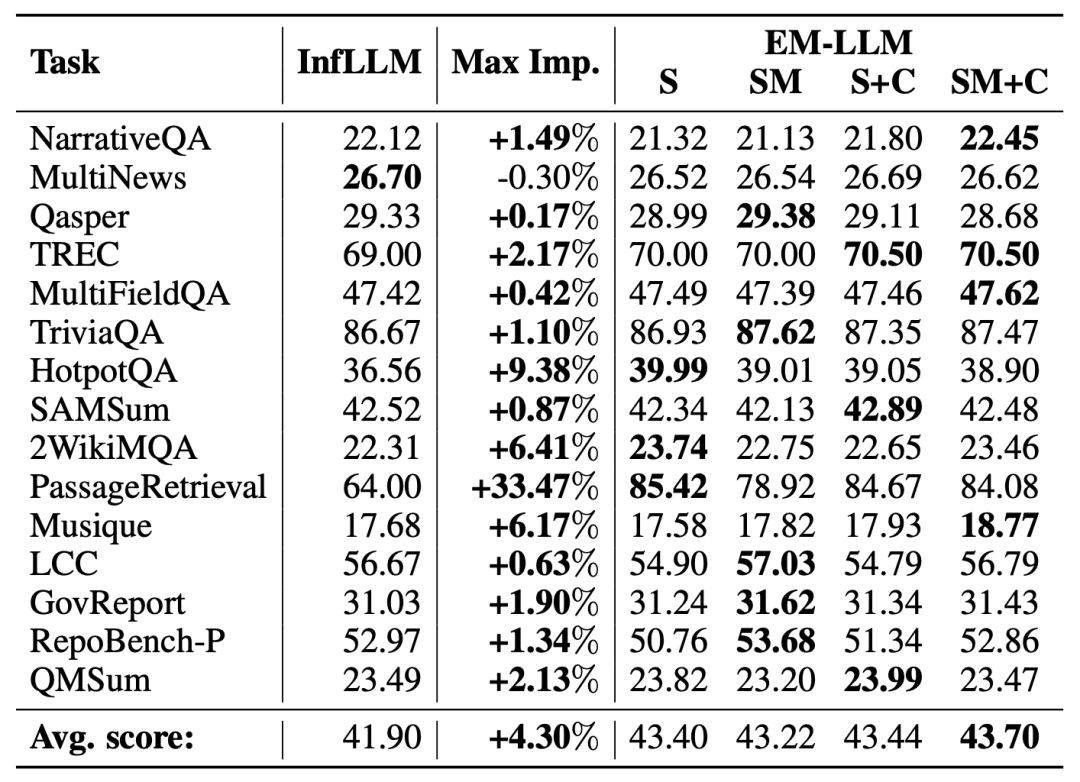
特别需要注意的是:
-
在PassageRetrieval(段落检索)任务上,EM-LLM实现了惊人的33.47%性能提升;
-
在HotpotQA任务上,EM-LLM比InfLLM高出了9.38%;
-
在2WikiMQA任务上,EM-LLM的表现比InfLLM好6.41%。
总体而言,EM-LLM在所有任务上的平均得分比InfLLM高出了4.3%,展现了其在各种长文本任务中的全面优势。
与人类事件感知的"心灵感应"
研究人员还比较了EM-LLM的事件分割结果与人类的事件感知。这个实验就像是测试LLM和人类之间的"心灵感应"能力。
下图展示了不同分割方法在LLaMA2注意力头的KV缓存中的表现。
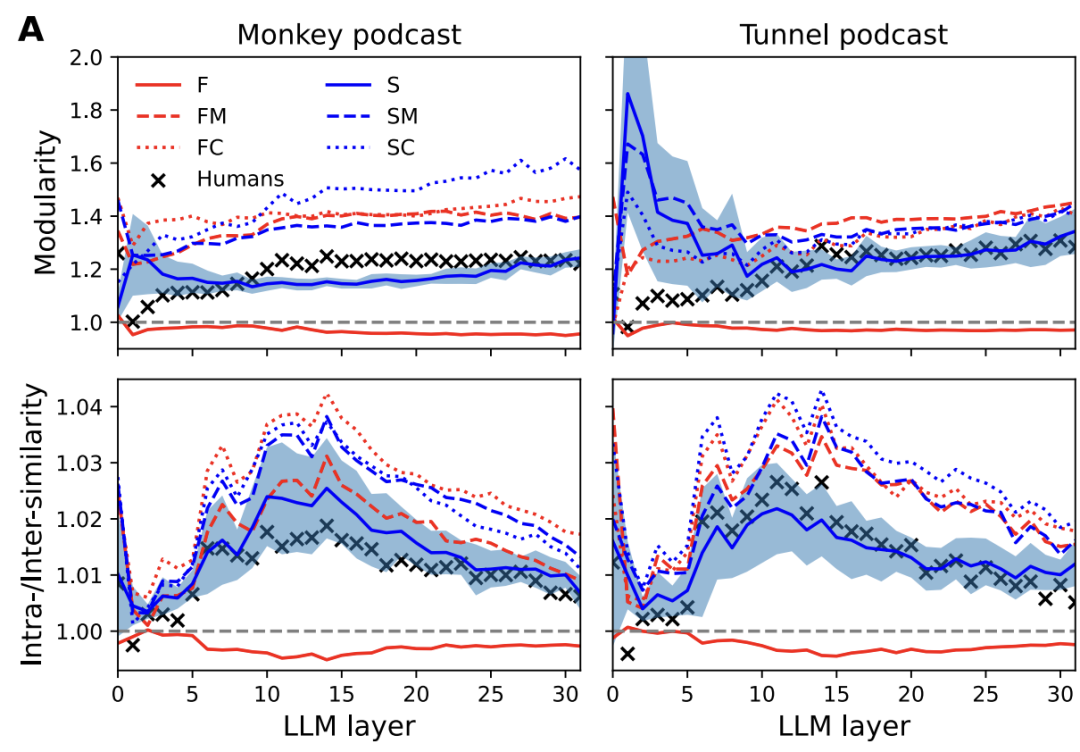
从上图中可以看出:
-
人类感知的事件分割在三个指标(模块化、导电率和内部/外部相似度比)上都表现优异;
-
EM-LLM的基于惊奇度的分割方法(S)和加入边界优化的方法(SM, SC)与人类感知非常接近,甚至在某些方面表现得更好;
-
相比之下,固定大小的分割方法(F, FM, FC)表现较差,特别是InfLLM使用的固定分割方法(F)甚至不如随机分割。
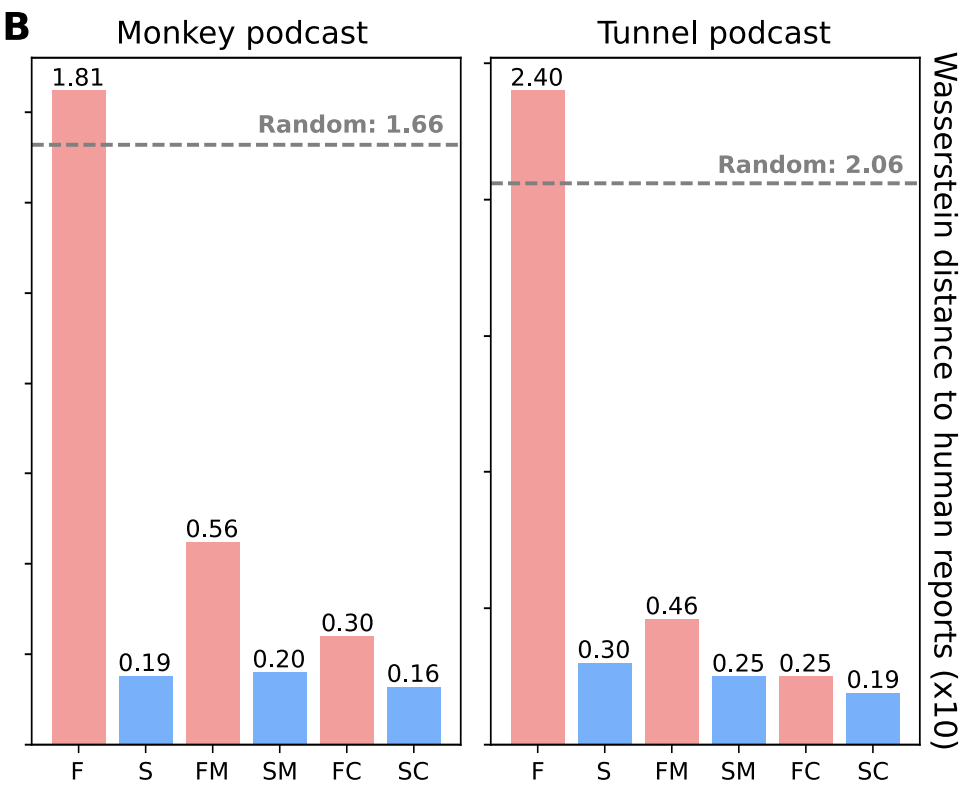
下图进一步比较了不同方法与人类报告的事件边界之间的距离。结果显示,EM-LLM的方法(S, SM, SC)与人类感知的一致性最高。
不同分割方法的"擂台赛"
研究人员还在PG-19数据集上比较了不同的事件分割方法。下表展示了在不同LLM(Mistral-7B, LLaMA2-7B, LLaMA3-8B)上的实验结果。
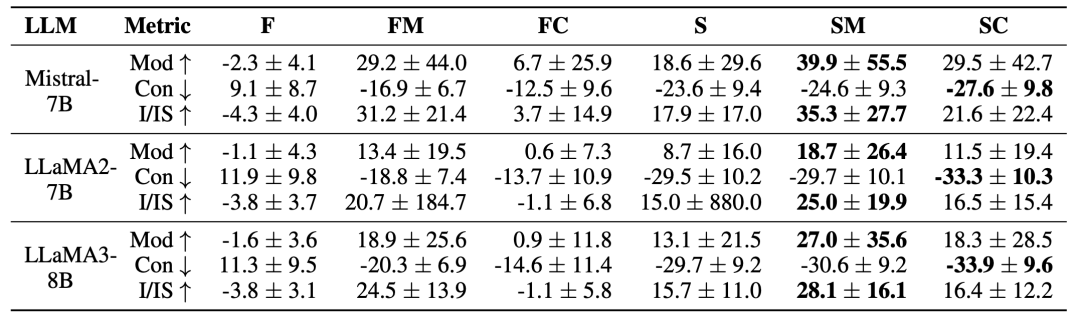
从实验结果中可以看出:
-
基于惊奇度的分割方法(S)和加入边界优化的方法(SM, SC)在各项指标上都表现优异;
-
边界优化(SM, SC)进一步提升了性能,特别是在模块度和内部/外部相似度比上;
-
相比之下,固定大小的分割方法(F, FM, FC)表现较差,尤其是在没有优化的情况下(F)。
相似性、连续性与时序的"平衡艺术"
研究人员还探讨了不同组件权重对模型性能的影响。研究人员测试了不同参数设置下EM-LLM在LongBench各任务上的表现。
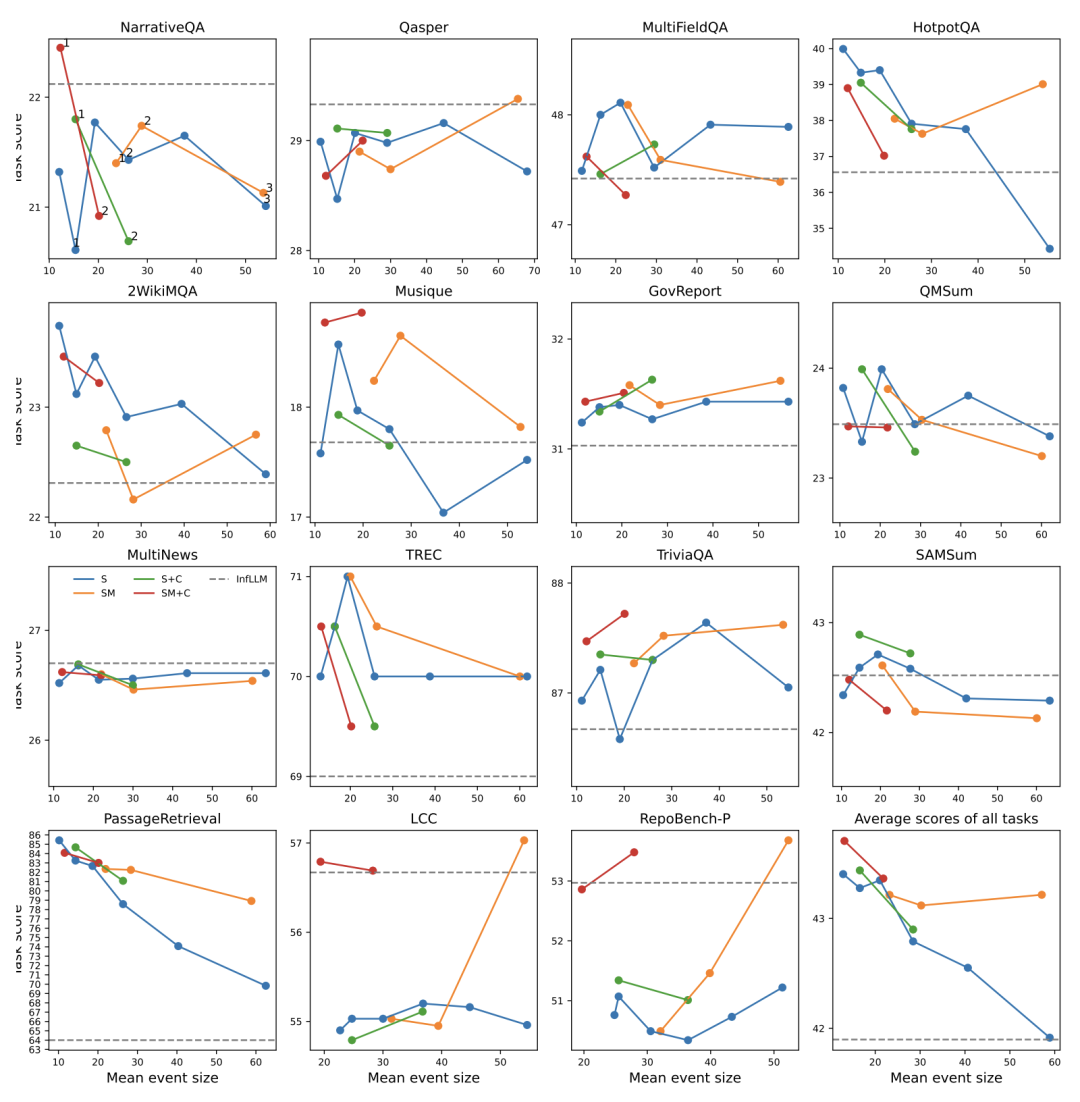
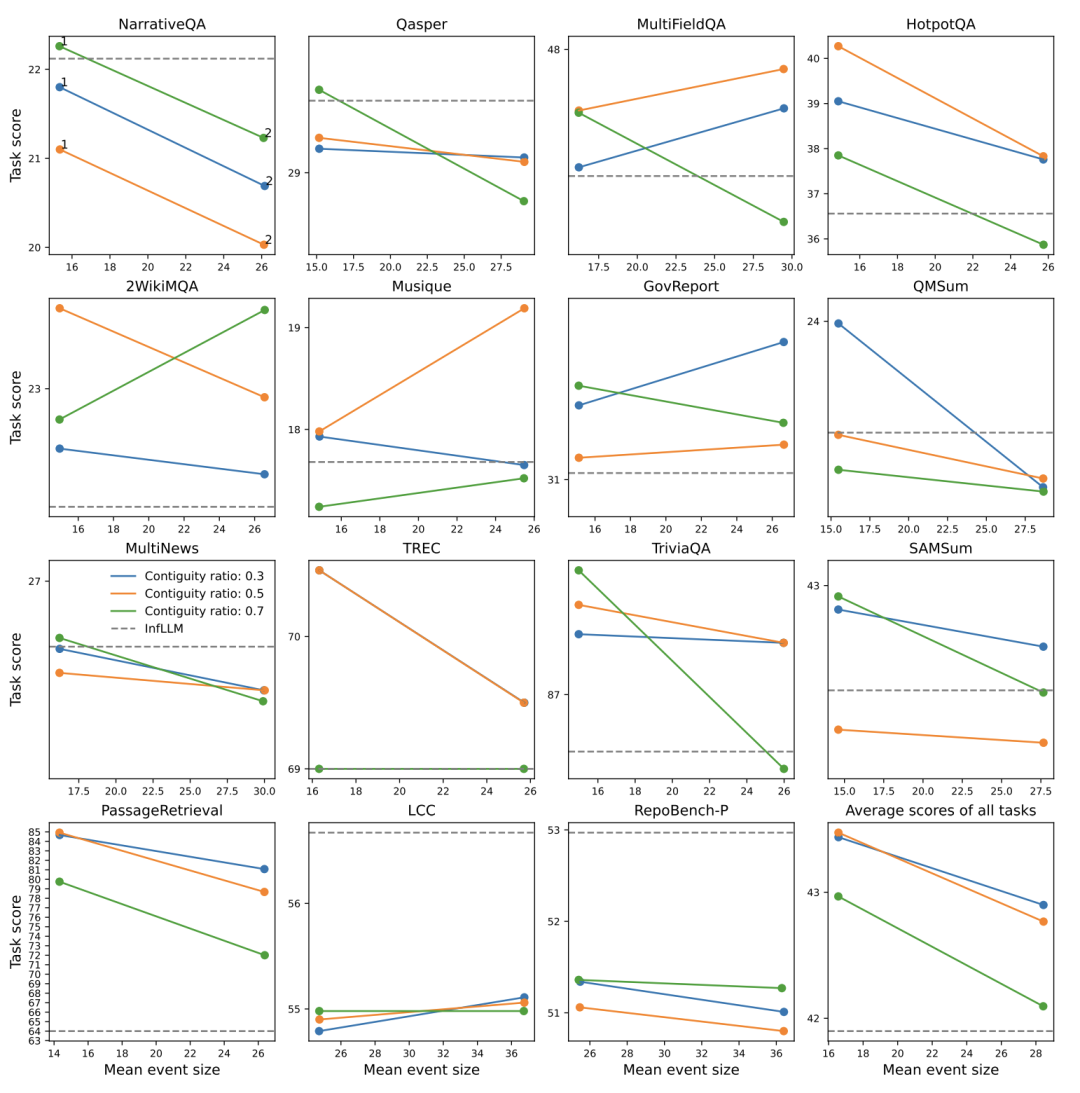
-
结合相似性搜索和连续性检索的方法(SM+C)在大多数任务中表现最佳;
-
连续性缓冲区的大小对性能有显著影响,最佳比例通常在30%到50%之间;
-
不同任务对连续性和相似性的需求不同,如MultiNews任务在70%连续性比例时表现最佳。
EM-LLM不仅在各种长文本任务中表现出色,超越了现有最佳模型,其事件分割和记忆检索机制还展现出与人类认知相似的特征,在保持高效处理能力的同时,实现了更接近人类的文本理解和信息组织方式。
总结与展望
华为诺亚方舟实验室这次真给大模型界来了个大招!他们的EM-LLM模型不仅实现了"无限"上下文长度,还在LongBench测试中超越了此前的最佳成绩,平均提升4.3%。这就像给AI装上了记忆芯片。EM-LLM的成功展示了跨学科研究的威力,仿佛让LLM上了一个"人类大脑速成班"。
这一突破可能带来众多有趣应用,从能轻松解读《战争与和平》的大模型文学评论家,到记住你上月所有对话的超级客服,再到能处理繁琐合同的法律专家和分析全面病史的医疗助手。虽然距离真正的"通用人工智能"还有距离,但EM-LLM无疑是AI进化路上的重大进步,不仅突破了LLM在长文本理解上的瓶颈,还为大模型的应用领域带来了新的可能性。