转自:知识图谱科技
这是一个与任务无关的框架,它将知识图谱(KG)的显性知识与大型语言模型(LLM)的隐含知识结合起来。这是该工作的arXiv预印本 https://arxiv.org/abs/2311.17330 。
我们在这里利用一个名为SPOKE(https://spoke.ucsf.edu/)的大规模生物医学知识图谱作为生物医学背景的提供者。SPOKE已经整合了来自不同领域的40多个生物医学知识库,每个知识库都专注于生物医学概念,如基因、蛋白质、药物、化合物、疾病及其相关连接。
SPOKE由21种不同类型的超过2700万个节点和55种类型的5300万条边组成(https://doi.org/10.1093/bioinformatics/btad080)。
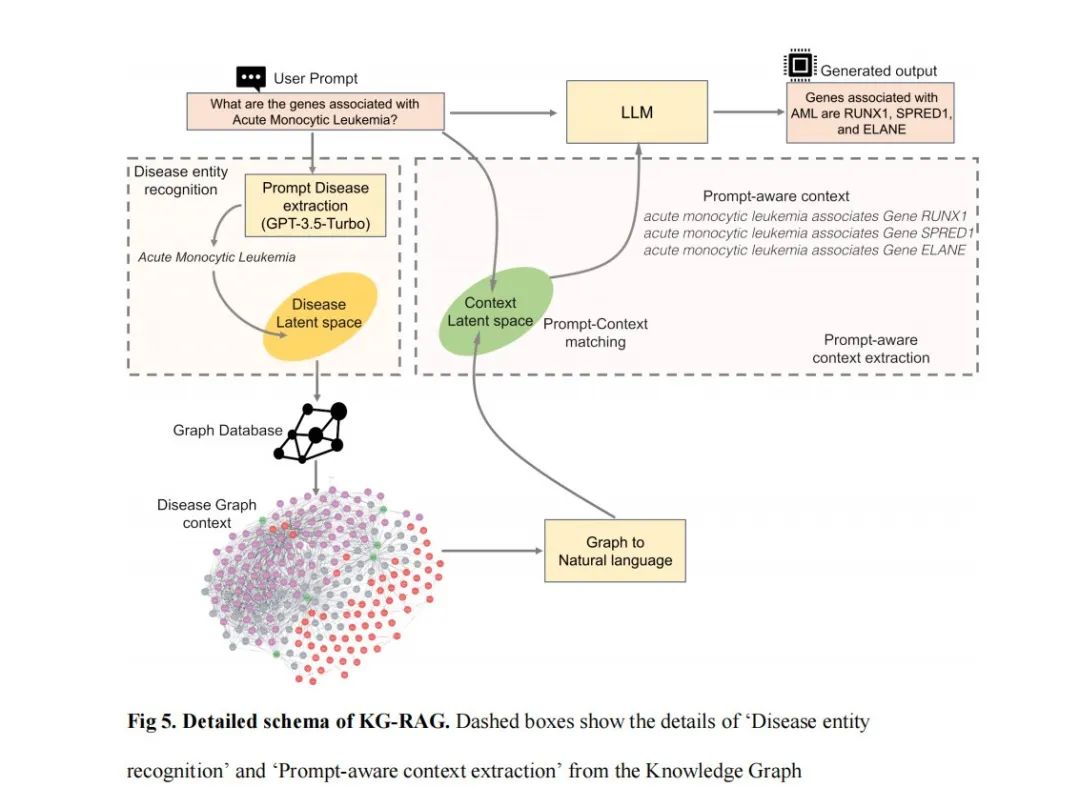
KG-RAG的主要特点是从SPOKE KG中提取“提示感知上下文”,其定义为:足以回答用户提示的最小上下文。
图片
因此,这个框架通过从生物医学KG中获得的优化领域特定的“提示感知上下文”,赋予了一个通用型的LLM更强大的功能。
图片
询问 GPT-4 关于上述药物:
没有KG-RAG
注意:此示例是使用KG-RAG v0.3.0运行的。我们是通过终端来启动GPT,而不是通过chatGPT浏览器。分析中的温度参数设置为0。参考此yaml文件进行参数设置,包括KG-RAG。
有KG-RAG
注意:此示例是使用KG-RAG v0.3.0运行的。分析过程中,温度参数设置为0。有关参数设置,请参阅此yaml文件。
Step 4: 更新config.yaml
注意:还有另一个名为system_prompts.yaml的yaml文件。它已经填充好,并保存了KG-RAG框架中使用的所有系统提示。
设置脚本以交互方式运行。
运行设置脚本将:
1.为KG-RAG创建疾病向量数据库
2.在您的机器上下载Llama模型(可选,您可以跳过此步骤,完全没有问题)
你可以使用GPT和Llama模型来运行KG-RAG。
示例:注意:以下示例在AWS p3.8xlarge EC2实例上运行,并使用KG-RAG v0.3.0。
用GPT的交互模式
示例
注意:以下示例是在AWS p3.8xlarge EC2实例上运行,并使用KG-RAG v0.3.0。
用Llama交互模式
SPOKE KG可以通过以下链接访问:
https://spoke.rbvi.ucsf.edu/neighborhood.html。也可以使用REST-API访问
(https://spoke.rbvi.ucsf.edu/swagger/)。
KG-RAG代码可在
https://github.com/BaranziniLab/KG_RAG 下载。本研究中使用的生物医学数据集(一跳问题、两跳问题、真假问题、多选题问题、药物重新定位问题、SPOKE KG中的疾病上下文)可供研究界使用,位于同一GitHub存储库中。
原文 - [2311.17330] Biomedical knowledge graph-enhanced prompt generation for large language models (arxiv.org)zhu