设置全局配置
1)在C:/Users/用户名/目录下创建.gitignore文件,在里面添加忽略规则。
如何创建 .gitignore 文件?
新建一个.txt文件,重命名(包括后缀.txt)为 .gitignore 即可。
2)将.gitignore设置为全局
在C:\Users\用户名/目录下找到.gitconfig文件,如下图:
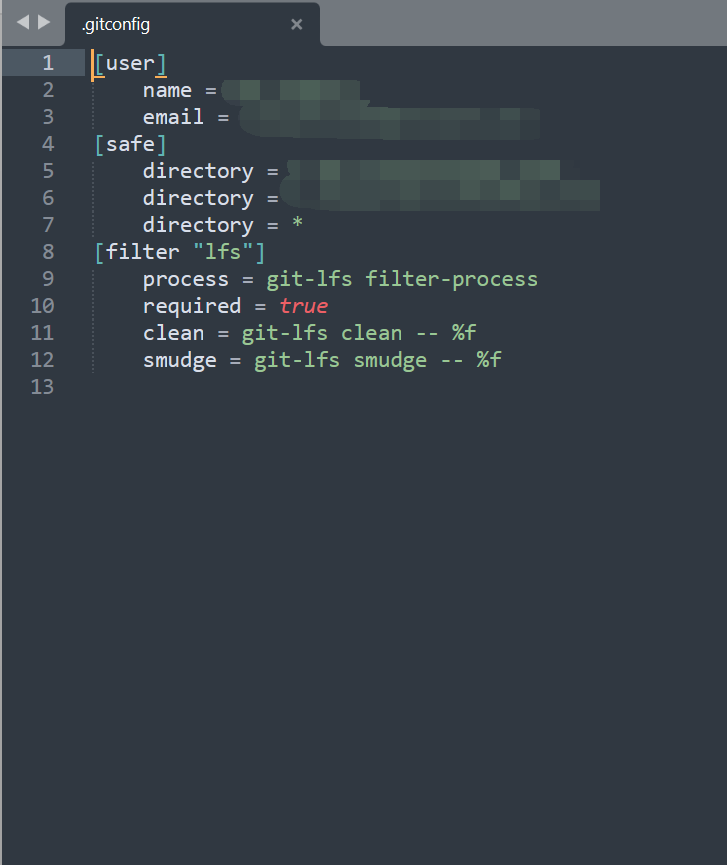
- 设置方式一(命令行配置):
在Git中输入配置命令:
git config --global core.excludesfile ~/.gitignore
- 设置方式二(手动配置):
打开.gitconfig,在其中添加以下信息:
[core]excludesfile = C:/Users/用户名/.gitignore
配置成功都可在.gitconfig中看到相应信息:

Git 常用忽略规则匹配语法
在 .gitignore 文件中,每一行的忽略规则的语法如下:
| 语法 | 含义 | 示例 | 解释 |
|---|---|---|---|
| 空格 | 不匹配任意文件,可作为分隔符 | / | / |
#开头 | 注释标识 | / | / |
!开头 | 不忽略(跟踪)匹配到的文件或目录 | !/bin/run.sh | 不忽略 bin 目录下的 run.sh 文件 |
/开始 | 匹配项目根目录 | /bin | 忽略根目录下的bin文件 |
/结束 | 只匹配文件夹以及在该文件夹路径下的内容,但是不匹配该文件 | bin/ | 忽略当前路径下的bin文件夹, 该文件夹下的所有内容都会被忽略,不忽略bin文件 |
?通配符 | 匹配一个任意字符,但不包括斜杠 | file?.txt | 匹配file1.txt、file2.txt等 |
*通配符 | 匹配多个字符,但不包括斜杠 | *.txt | 匹配所有.txt文件 |
**通配符 | 匹配多个字符,包括斜杠 | logs/**/*.log | 匹配logs目录中任意子目录下的.log文件 |
[abc]模式 | 匹配任何一个括号内的字符 | te[st] | 匹配test或tst |
[^abc]模式 | 匹配不在括号内的任何一个字符 | te[^st] | 匹配ten、ted等,但不匹配test或tst |
{string1,string2,...}模式 | 匹配大括号内指定的任一字符串 | {read,write}[me] | 匹配readme或writeme |
\字符 | 用于转义特殊字符 | \* | 匹配*字符本身,而不是作为通配符 |
- 如果一个模式不包含斜杠,则它匹配相对于当前 .gitignore 文件路径的内容,如果该模式不在 .gitignore 文件中,则相对于项目根目录。
- 具体更详细的规则推荐参考 Git & GitHub 官方文档(文末有链接)。
Git 忽略规则优先级
在 .gitingore 文件中,每一行指定一个忽略规则,Git 检查忽略规则的时候有多个来源,它的优先级如下(由高到低):
- 从命令行中读取可用的忽略规则
- 当前目录定义的规则
- 父级目录定义的规则,依次地推
- $GIT_DIR/info/exclude 文件中定义的规则
- core.excludesfile中定义的全局规则(即我们定义的全局配置)
因此,设置全局过滤配置文件 .gitignore 后,如果在某个版本库里也设置了.gitignore (局部过滤配置文件),那 git 会优先考虑局部的过滤规则,然后再考虑全局。
.gitignore规则不生效
.gitignore只能忽略那些原来没有被track的文件,如果某些文件已经被纳入了版本管理中,则修改.gitignore是无效的。
解决方法就是先把本地缓存删除(改变成未track状态),然后再提交:
git rm -r --cached .
git add .
git commit -m 'update .gitignore'
注意:
- git 对于 .gitignore配置文件是按行从上到下进行规则匹配的
- 如果你创建.gitignore文件之前就push了某一文件,那么即使你在.gitignore文件中写入过滤该文件的规则,该规则也不会起作用,git仍然会对该文件进行版本管理。
推荐资料:
- Git—.gitignore文件设置规则及全局配置(常用ignore文件)_gitignore规则-CSDN博客
- Git - gitignore 文档 — Git - gitignore Documentation (git-scm.com)
- 忽略文件 - GitHub 文档