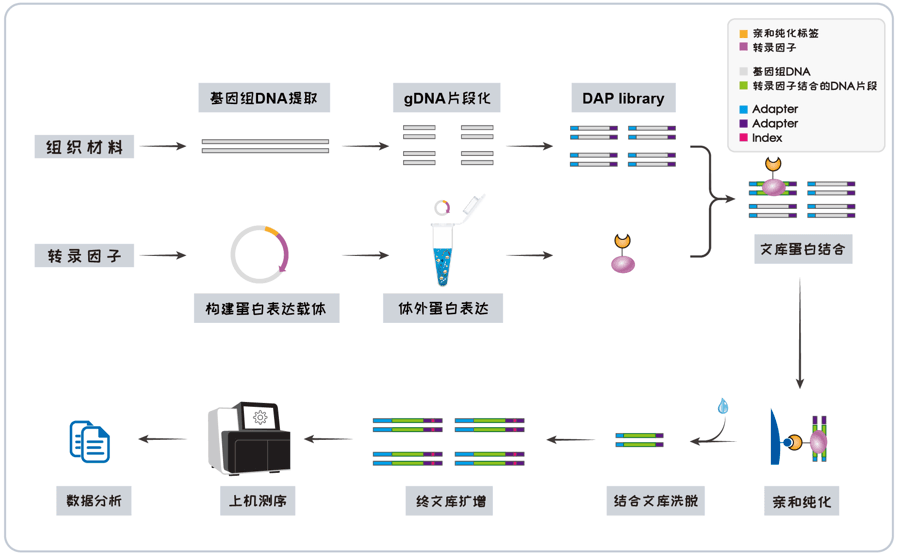
八、Redis缓存设计
8.1 为什么Redis用作缓存?
一般来说,数据库的数据都是落在磁盘上的,会导致读写速度很慢。如果用户的请求量非常大,数据库很容易崩溃。由于Redis的数据保存在内存中,读写速度很快,所以Redis一般被用作数据库的缓存层。因为 Redis 是内存数据库,我们可以将数据库的数据缓存在 Redis 里,相当于数据缓存在内存,内存的读写速度比硬盘快好几个数量级,这样大大提高了系统性能。
<img src="G:\code\study\CppStudy\docs\figures\redis缓存.
png" alt=“图片” style=“zoom:66%;” />
引入了缓存层,就会有缓存异常的三个问题,分别是**缓存雪崩、缓存击穿、缓存穿透**。


8.2 什么是缓存雪崩?
8.2.1 什么是缓存雪崩?
通常来说,为了保证缓存和数据库中的数据一致性,需要给Redis缓存中的数据**设置过期时间**。当缓存过期后,则用户的请求会从数据库读取数据,并将数据再次存入到Redis缓存中。
当**大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增**,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
发生缓存雪崩有两个原因:
- 大量数据同时过期;
- Redis 故障宕机;
8.2.2 大量数据同时过期解决方案?
针对大量数据同时过期而引发的缓存雪崩问题,常见的应对方法有下面这几种:
-
均匀设置过期时间,避免大量数据同时过期
我们可以在对缓存数据设置过期时间时,给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。
-
互斥锁
如果一个请求发现访问的数据不在Redis中,则先**加互斥锁,保证同一时刻只有一个请求从数据库中读取数据,并更新到Redis缓存中,完成请求后再释放锁。没有拿到锁的请求则会阻塞等待后重新读取缓存(而不需要再去访问数据库)**,或者直接返回空值或默认值。
实现互斥锁的时候,最好设置超时时间,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。
-
后台更新缓存
不再给缓存设置过期时间,而是让缓存**“永久有效”,开启一个后台线程定时更新缓存。事实上,当系统内存资源紧张时,对一些缓存数据进行“淘汰”。这就需要机制来保障数据的有效性,Redis一般通过后台线程监控(就是定时更新缓存这个线程)或者业务线程等方式来通知数据库读取数据更新这个淘汰的缓存**。
8.2.3 Redis故障宕机解决方案?
针对 Redis 故障宕机而引发的缓存雪崩问题,常见的应对方法有下面这几种:
-
服务熔断或请求限流机制
- 启动**服务熔断**机制:暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,从而降低对数据库的访问压力,保证数据库系统的正常运行,然后等到 Redis 恢复正常后,再允许业务应用访问缓存服务。
- 启动**请求限流**机制,只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务,等到 Redis 恢复正常并把缓存预热完后,再解除请求限流的机制。
-
构建Redis缓存高可靠集群
通过主从节点的方式构建 Redis 缓存高可靠集群。如果 Redis 缓存的主节点故障宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于 Redis 故障宕机而导致的缓存雪崩问题。
8.3 什么是缓存击穿?
我们的业务通常会有几个数据会被频繁地访问,比如秒杀活动,这类被频地访问的数据被称为**热点数据。如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿**的问题。
可以发现缓存击穿跟缓存雪崩很相似,可以认为**缓存击穿是缓存雪崩的一个子集**。
应对缓存击穿可以采取前面说到两种方案(除了均匀分配过期时间,因为这个是只针对热点数据,而不是大量数据的):
- 互斥锁方案:保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
- 后台更新方案:不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
8.4 什么是缓存穿透?
8.4.1 什么是缓存穿透?
当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是**缓存穿透**的问题。
缓存穿透的发生一般有这两种情况:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
- 黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
8.4.2 如何应对缓存穿透?
应对缓存穿透的方案,常见的方案有三种:
-
限制非法请求
在 API 入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
-
缓存空值或者默认值
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
-
布隆过滤器
在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以**通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库**,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
布隆过滤器是如何工作的呢?
布隆过滤器由**「初始值都为 0 的位图数组」和「 N 个哈希函数」**两部分组成。布隆过滤器会通过 3 个操作完成标记:
- 第一步:使用N个哈希函数分别对数据进行运算,得到N个哈希值;
- 第二步:将N个哈希值对BitMap的长度取模,得到每个哈希值在BitMap数组的位置;
- 第三步:将N个哈希值所在的BitMap的对应位置的值设为1;

当应用要查询数据 x 是否在数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中。布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时**存在哈希冲突的可能性**,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。
所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
8.6 如何设计可以动态缓存热点数据的缓存策略?
由于数据存储受限,系统并不是将所有数据都需要存放到缓存中的,而**只是将其中一部分热点数据缓存起来**,所以我们要设计一个热点数据动态缓存的策略。
热点数据动态缓存的策略总体思路:通过数据最新访问时间来做排名,并过滤掉不常访问的数据,只留下经常访问的数据。
以电商平台场景中的例子,现在要求只缓存用户经常访问的 Top 1000 的商品。具体细节如下:
- 先通过缓存系统做一个排序队列(比如存放 1000 个商品),系统会根据商品的访问时间,更新队列信息,越是最近访问的商品排名越靠前;
- 同时系统会定期过滤掉队列中排名最后的 200 个商品,然后再从数据库中随机读取出 200 个商品加入队列中;
- 这样当请求每次到达的时候,会先从队列中获取商品 ID,如果命中,就根据 ID 再从另一个缓存数据结构中读取实际的商品信息,并返回。
在 Redis 中可以用 zadd 方法和 zrange 方法来完成排序队列和获取 200 个商品的操作。
8.7 常见的缓存策略?
常见的缓存更新策略有3种:
- Cache Aside(旁路缓存)策略;
- Read/Write Through (读穿/写穿)策略;
- Write Back (写回)策略;
实际开发中,Redis 和 MySQL 的更新策略用的是 Cache Aside,另外两种策略应用不了。
8.7.1 Cache Aside(旁路缓存)策略
Cache Aside(旁路缓存)策略是最常用的,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为**「读策略」和「写策略」**。

写策略的步骤:
- 先更新数据库中的数据,再删除缓存中的数据。
读策略的步骤:
- 如果读取的数据命中了缓存,则直接返回数据;
- 如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
写策略能否反过来? 先删除缓存数据,再更新数据库数据?
不能,原因是在「读+写」并发的时候,会出现缓存和数据库的数据不一致性的问题。详情见后面分析。
Cache Aside 策略适合读多写少的场景,不适合写多的场景,因为当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快过期,对业务的影响也是可以接受。
8.7.2 Read/Write Through(读穿 / 写穿)策略
Read/Write Through(读穿 / 写穿)策略原则是应用程序**只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了**。
读策略的步骤:
- 先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用。
写策略的步骤:
当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
- 如果缓存中数据已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,然后缓存组件告知应用程序更新完成;
- 如果缓存中数据不存在,直接更新数据库,然后返回。
Read Through/Write Through 策略的特点是**由缓存节点而非应用程序来和数据库打交道**,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库和自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略。
8.7.3 Write Back (写回)策略
Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通**过批量异步更新的方式进行**。
Write Back 策略特别适合写多的场景,因为发生写操作的时候, 只需要更新缓存,就立马返回了。比如,写文件的时候,实际上是写入到文件系统的缓存就返回了,并不会写磁盘。
但是带来的问题是,数据不是强一致性的,而且会有数据丢失的风险,因为缓存一般使用内存,而内存是非持久化的,所以一旦缓存机器掉电,就会造成原本缓存中的脏数据丢失。所以你会发现系统在掉电之后,之前写入的文件会有部分丢失,就是因为 Page Cache 还没有来得及刷盘造成的。
8.8 如何保证缓存和数据库数据的一致性?
8.8.1 缓存更新还是删除?先数据库还是先缓存?
无论是**「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题**,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。于是,Cache Aside策略中使用的是**「先更新数据库,再删除缓存」策略,不对缓存更新,而是直接把缓存给删除,等下次读取数据时从数据库读并加入到缓存中**。
「先删除缓存,再更新数据库」,在「读 + 写」并发的时候,还是会出现缓存和数据库的数据不一致的问题:

因此,Cache Aside策略中使用的是**「先更新数据库,再删除缓存」策略。理论上分析,先更新数据库,再删除缓存也是会出现数据不一致性的问题,但是在实际中,这个问题出现的概率并不高**。如下图:

因为缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。所以,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
8.8.2 「先更新数据库 + 再删除缓存」如何确保两个操作都能执行成功?
这次用户的投诉是因为在删除缓存(第二个操作)的时候失败了,导致缓存还是旧值,而数据库是最新值,造成数据库和缓存数据不一致的问题,会对敏感业务造成影响。

该怎么解决呢?有两种方法:
- 消息队列重试机制
- 订阅 MySQL binlog,再操作缓存
资料参考
内容大多参考自:图解Redis介绍 | 小林coding (xiaolincoding.com)


![nginx: [error] open() “/run/nginx.pid“ failed (2: No such file or directory)](https://i-blog.csdnimg.cn/blog_migrate/cfa50b184ddf97de7f5588c9e449cf15.png)
![[CTF]-PWN:格式化字符串漏洞题综合解析](https://i-blog.csdnimg.cn/direct/8799d5a017e045a891b3d12d7f98e087.png)