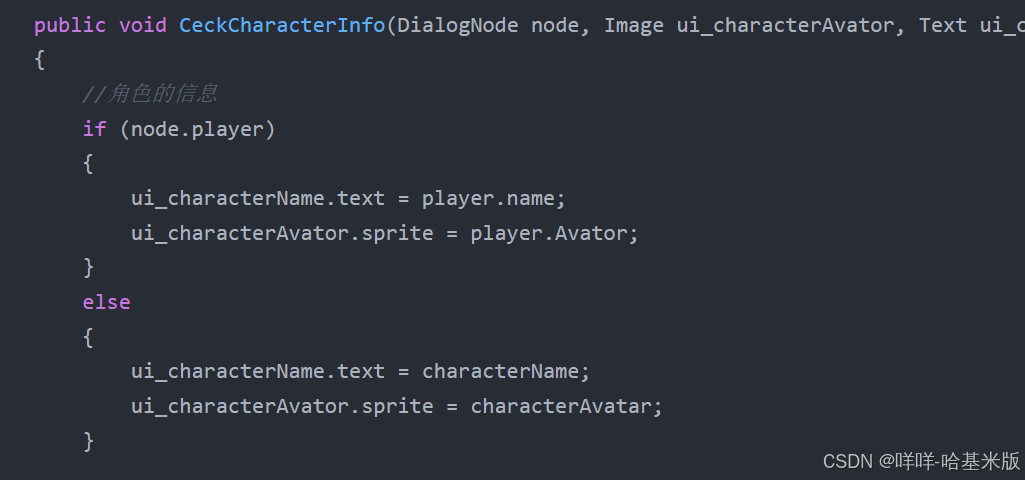
什么是Next.js?
Next.js 是由 Vercel 开发的基于 React 的现代 Web 应用框架,具备前后端一体的开发能力,广泛用于开发 Server-side Rendering (SSR) 和静态站点生成(SSG)项目。Next.js 支持传统的 Node.js 模式和基于边缘计算(Edge Function)的运行模式,适用于轻量、高性能的服务逻辑。
首先百度,这是个啥玩意,找到官网,进入看看

创建 Next.js 应用程序 | Learn Next.js | Next.js中文网
不用多说了,介绍得贼详细!

环境搭建
1、部署Next.js
漏洞复现,首先需要搭建环境,刚好官网有入门教程,按照教程走起!

首先安装Node.js ,下载链接:Node.js — Run JavaScript Everywhere

安装完Node.js,由于我是windows系统,按照教程继续安装Git Bash,并运行


至此,关闭官网教程,下一步安装符合漏洞版本的Next.js,漏洞版本如下:
11.1.4 <= Next.js <= 13.5.6
14.0.0 <= Next.js <= 14.2.24
15.0.0 <= Next.js <= 15.2.2
有请ChatGPT,AI时代我就特别好问好学

直接复制如下命令,安装14.1.1
npm install next@14.1.1
安装完成

然后运行
npm install
启动Next.js项目
npm run dev
启动时可能出现如图报错
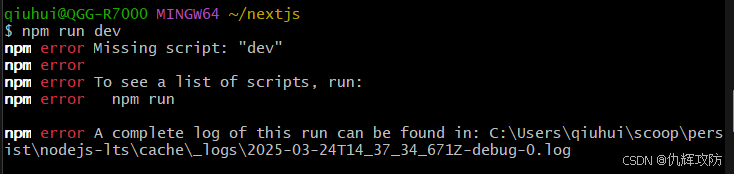
问题抛给GPT解决

完善配置文件 package.json
{"dependencies": {"next": "^14.1.1"},"scripts": {"dev": "next dev","build": "next build","start": "next start"}
}
再次启动,出现新的报错

问题抛给GPT

继续完善

成功启动

2、配置利用场景
【复现】Next.js 中间件认证绕过漏洞(CVE-2025-29927)风险通告
近日,赛博昆仑CERT监测到Next.js 中间件认证绕过漏洞(CVE-2025-29927)的漏洞情报。当配置为使用中间件进行身份验证和授权时,未经过身份认证的攻击者可以绕过Next.js 应用程序中的授权检查。
把配置的任务交给GPT

首先创建中间件middleware.js ,定义受保护的路径。放在根目录,与package.json同级
import { NextResponse } from "next/server";// 定义受保护的路径
const protectedRoutes = ["/dashboard", "/admin"];export function middleware(req) {const { pathname } = req.nextUrl;// 获取用户的身份令牌(可以从 Cookie、Session 或 Headers 获取)const token = req.cookies.get("authToken")?.value;// 如果是受保护路径但没有 token,则重定向到登录页if (protectedRoutes.includes(pathname) && !token) {return NextResponse.redirect(new URL("/login", req.url));}return NextResponse.next();
}// 只应用于某些路由
export const config = {matcher: ["/dashboard/:path*", "/admin/:path*"], // 保护的路由
};
其次,创建一个保护页面dashboard.js,放到pages目录下
export default function Dashboard() {return <h1>这是受保护的 Dashboard 页面</h1>;
}
最后,设置登录逻辑,创建一个login页面 (其实,可以不用,顶多404呗,不影响复现)
import { useRouter } from "next/navigation";export default function LoginPage() {const router = useRouter();const handleLogin = async () => {// 假设用户成功登录document.cookie = "authToken=your_token; path=/"; // 设置身份验证 Cookierouter.push("/dashboard"); // 跳转到受保护页面};return (<div><h1>请登录</h1><button onClick={handleLogin}>登录</button></div>);
}
一切就绪,测试一下,访问dashboard页面,没有授权,正常跳转到登录页面

漏洞复现
漏洞通告 | Next.js middleware 权限绕过漏洞
当在 next.js应用中使用middleware 时,在请求头中加入特定的 x-middleware-subrequest 请求头即可绕过 middleware 中的逻辑。例如当使用 middleware 进行身份验证与授权,可利用该漏洞绕过身份验证。
那去网上搜一下公开的POC,大厂CERT漏洞公告通常不会给出来,复现截图关键部位基本都打码,需要自己去网上搜寻一下,以下是我找到的公开POC
CVE-2025-29927: Next.js Middleware Authorization Bypass - Technical Analysis — ProjectDiscovery Blog
如图,不同版本,POC还不太一样

根据我的版本,找到POC
x-middleware-subrequest: middleware:middleware:middleware:middleware:middleware
先发一个正常的包,返回307跳转

使用POC,返回200,未授权访问dashboard受保护的页面,漏洞复现完成!