目录
一、JVM的内存结构?
二、类加载器分为哪几类?
三、讲一下双亲委派机制
为什么要有双亲委派机制?
那你知道有违反双亲委派的例子吗?
四、IO 有哪些类型?
五、Spring Boot启动机制
六、Spring Boot的可执行Jar和非可执行Jar有什么区别?
七、Spring Cloud核心组件?
八、Redis有几种集群模式?
九、缓存击穿的主要原因和解决方式是啥?
十、缓存穿透的主要原因和解决方式是啥?
十一、Linux相关命令
十二、设计原则
一、JVM的内存结构?
- 前言
由 JVM 引发的故障问题,无论在我们开发过程中还是生产环境下都是非常常见的。比如 OutOfMemoryError(OOM) 内存溢出问题,你应该遇到过 Tomcat 容器中加载项目过多导致的 OOM 问题,导致 Web 项目无法启动。这就是JVM引发的故障问题。那到底JVM哪里发生内存溢出了呢?为什么会内存溢出呢?如何监控?
- 运行时数据区(JVM)
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分为若干个不同的数据区域——堆、栈、方法区、程序计数器等,而 JVM 的优化问题主要在线程共享的数据区中:堆、方法区。

程序计数器:
• 程序计数器(Program Counter Register)是一块较小的内存空间,可以看作是当前线程所执行字节码的行号指示器,指向下一个将要执行的指令代码,由执行引擎来读取下一条指令。更确切的说,一个线程的执行,是通过字节码解释器改变当前线程的计数器的值,来获取下一条需要执行的字节码指令,从而确保线程的正确执行。
• 为了确保线程切换后(上下文切换)能恢复到正确的执行位置,每个线程都有一个独立的程序计数器,各个线程的计数器互不影响,独立存储。也就是说程序计数器是线程私有的内存。
• 如果线程执行 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果执行的是 Native 方法,计数器值为Undefined。
• 程序计数器不会发生内存溢出(OutOfMemoryError即OOM)问题。
栈:
JVM 中的栈包括 Java 虚拟机栈和本地方法栈,两者的区别就是,Java 虚拟机栈为 JVM 执行 Java 方法服务,本地方法栈则为 JVM 使用到的 Native 方法服务。两者作用是极其相似的。
• Native 方法是什么?
JDK 中有很多方法是使用 Native 修饰的。Native 方法不是以 Java 语言实现的,而是以本地语言实现的(比如 C 或 C++)。个人理解Native 方法是与操作系统直接交互的。比如通知垃圾收集器进行垃圾回收的代码 System.gc(),就是使用 native 修饰的。
堆:
• 堆是Java虚拟机所管理的内存中最大的一块存储区域。堆内存被所有线程共享。主要存放使用new关键字创建的对象。所有对象实例以及数组都要在堆上分配。垃圾收集器就是根据GC算法,收集堆上对象所占用的内存空间(收集的是对象占用的空间而不是对象本身)。
• Java堆分为年轻代(Young Generation)和老年代(Old Generation);年轻代又分为伊甸园(Eden)和幸存区(Survivor区);幸存区又分为From Survivor空间和 To Survivor空间。
年轻代存储“新生对象”,我们新创建的对象存储在年轻代中。当年轻内存占满后,会触发Minor GC,清理年轻代内存空间。
老年代存储长期存活的对象和大对象。年轻代中存储的对象,经过多次GC后仍然存活的对象会移动到老年代中进行存储。老年代空间占满后,会触发Full GC。
注:Full GC是清理整个堆空间,包括年轻代和老年代。如果Full GC之后,堆中仍然无法存储对象,就会抛出OutOfMemoryError异常。

方法区:
方法区同 Java 堆一样是被所有线程共享的区间,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码。更具体的说,静态变量+常量+类信息(版本、方法、字段等)+运行时常量池存在方法区中。常量池是方法区的一部分。

二、类加载器分为哪几类?
- 启动类加载器
- 扩展类加载器
- 应用类加载器
- 继承class loader的自定义加载器
三、讲一下双亲委派机制
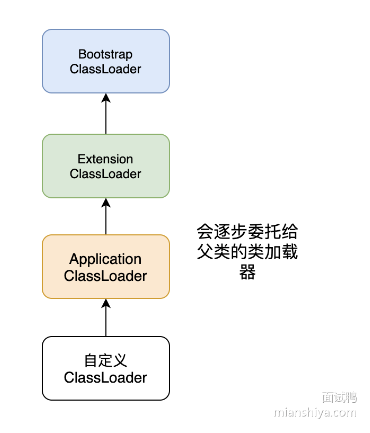
向上委托,向下加载
一种使用类加载器的方式。如果一个类加载器需要加载类,那么首先它会把这个类加载请求委派给父类加载器去完成,如果父类还有父类则接着委托,每一层都是如此。一直递归到顶层,当父加载器无法完成这个请求时,子类才会尝试去加载。
父类也不是我们平日所说的那种继承关系,只是调用逻辑是这样。
在 JDK9 之前,Java 自身提供了3种类加载器:
- 启动类加载器,它是属于虚拟机自身的一部分,用C++实现的,主要负责加载<JAVA_HOME\lib>目录中或被 -Xbootclasspath 指定的路径中的并且文件名是被虚拟机识别的文件。它是所有类加载器的父亲。
- 扩展类加载器,它是 Java 实现的,独立于虚拟机,主要负责加载<JAVA_HOME\lib\ext目录中或被java.ext.dirs系统变量所指定的路径和类库。
- 应用程序类加载器,它是 Java 实现的,独立于虚拟机。主要负责加载用户类路径上的类库,如果我们没有实现自定义的类加载器那这玩意就是我们程序中的默认加载器。
一般情况类加载会从应用程序类加载器委托给扩展类再委托给启动类,启动类找不到然后扩展类找,扩展类加载器找不到再应用程序类加载器找。
为什么要有双亲委派机制?
它使得类有了层次的划分(安全性)。就拿 java.lang.Object 来说,加载它经过一层层委托最终是由 BootstrapClassLoader来加载的,也就是最终都是由 BootstrapClassLoader 去找 \lib 中 rt.jar 里面的 java.lang.Object 加载到 JVM 中。
这样如果有不法分子自己造了个 java.lang.Object,里面嵌了不好的代码,如果我们是按照双亲委派模式来实现的话,最终加载到 JVM 中的只会是我们 rt.jar 里面的东西,也就是这些核心的基础类代码得到了保护。
因为这个机制使得系统中只会出现一个 java.lang.Object。
那你知道有违反双亲委派的例子吗?
典型的例子就是:JDBC。
JDBC 的接口是类库定义的,但实现是在各大数据库厂商提供的 jar 包中,那通过启动类加载器是找不到这个实现类的(jar包中没有),所以就需要应用程序加载器去完成这个任务,这就违反了自下而上的委托机制。
如何解决:
具体做法是搞个线程上下文类加载器,通过 setContextClassLoader()默认设置应用程序类加载器,然后通过Thead.current.currentThread().getContextClassLoader()获得类加载器来加载。
四、IO 有哪些类型?
- 阻塞 IO 模型(用户态阻塞)
最传统的一种 IO 模型,即在读写数据过程中会发生阻塞现象。当用户线程发出 IO 请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用 户线程交出 CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除 block 状态。典型的阻塞 IO 模型的例子为:data = socket.read(); 如果数据没有就绪,就会一直阻塞在 read 方法。
- 非阻塞 IO 模型(用户态和内核态切换阻塞)
当用户线程发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个 error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。 所以事实上,在非阻塞 IO 模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞 IO 不会交出 CPU,而会一直占用 CPU。典型的非阻塞 IO 模型一般如下:
while(true){ data = socket.read(); if(data!= error){ 处理数据 break; }
} 但是对于非阻塞 IO 就有一个非常严重的问题,在 while 循环中需要不断地去询问内核数据是否就绪,这样会导致 CPU 占用率非常高,因此一般情况下很少使用 while 循环这种方式来读取数据。
- 多路复用 IO 模型(内核态中进行)
多路复用 IO 模型是目前使用得比较多的模型。Java NIO 实际上就是多路复用 IO。在多路复用 IO 模型中,会有一个线程不断去轮询多个 socket 的状态,只有当 socket 真正有读写事件时,才真正调用实际的 IO 读写操作。因为在多路复用 IO 模型中,只需要使用一个线程就可以管理多个 socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有 socket 读写事件进行时,才会使用 IO 资源,所以它大大减少了资源占用。在 Java NIO 中,是通过 selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。多路复用 IO 模式,通过一个线程就可以管理多个 socket,只有当 socket 真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用 IO 比较适合连接数比较多的情况。
另外多路复用 IO 为何比非阻塞 IO 模型的效率高是因为在非阻塞 IO 中,不断地询问 socket 状态时通过用户线程去进行的,而在多路复用 IO 中,轮询每个 socket 状态是内核在进行的,这个效率要比用户线程要高的多。
不过要注意的是,多路复用 IO 模型是通过轮询的方式来检测是否有事件到达,并且对到达的事件 逐一进行响应。因此对于多路复用 IO 模型来说,一旦事件响应体很大,那么就会导致后续的事件 迟迟得不到处理,并且会影响新的事件轮询。
五、Spring Boot启动机制
每一个SpringBoot程序都有一个主入口,这个主入口就是main方法,而main方法中都会调用SpringBootApplication.run方法。
查看SpringBootApplication.run方法的源码就可以发现SpringBoot启动的流程主要分为两大阶段:
- 初始化
SpringApplication和运行SpringApplication - 运行
SpringApplication的过程
其中运行SpringApplication的过程又可以细分为以下几个部分:
1)SpringApplicationRunListeners 引用启动监控模块
2)ConfigrableEnvironment配置环境模块和监听:包括创建配置环境、加载属性配置文件和配置监听
3)ConfigrableApplicationContext配置应用上下文:包括配置应用上下文对象、配置基本属性和刷新应用上下文
初始化SpringApplication
步骤1进行SpringApplication的初始化,配置基本的环境变量、资源、构造器、监听器,初始化阶段的主要作用是为运行SpringApplication实例对象启动环境变量准备以及进行必要的资源构造器的初始化动作,代码如下:
public SpringApplication(ResourceLoader resourceLoader, Object... sources){this.resourceLoader = resourceLoader;initialize(source);
}@SupressWarnings({"unchecked","rowtypes"})
private void initialize(Object[] sources){if(sources != null && sources.length > 0){this.sources.addAll(Arrays.asList(sources));}this.WebEnvironment = deduceWebEnvironment;setInitiallizers((Collection) getSpringFactoriesInstances(ApplicationContextInitiallizer.class));setListeners((Collection) getSpringFactoriesInstances(ApplicationListener.class));this.mainApplicationClass = deduceMainApplicationClass();
}SpringApplication方法的核心就是this.initialize(sources)初始化方法,SpringApplication通过调用该方法完成初始化工作。deduceWebEnvironment方法用来判断当前应用的环境,该方法通过获取两个类来判断当前环境是否是Web环境。而getSpringFactoriesInstances方法主要用来从spring.factories文件中找出Key为ApplicationContextInitiallizer的类并实例化,然后调用setInitiallizer方法设置到SpringApplication的initiallizer属性中,找到它所有应用的初始化器。接着调用setListener方法设置应用监听器,这个过程可以找到所有应用程序的监听器,然后找到应用启动主类名称。
运行SpringApplication
SpringBoot正式启动加载过程,包括启动流程监控模块、配置环境加载模块、ApplicationContext容器上下文环境加载模块。refreshContext方法刷新应用上下文并进行自动化配置模块加载,也就是上文提到的SpringFactoriesLoader根据指定classpath加载META-INF/spring.factories文件的配置,实现自动配置核心功能。运行SpringApplication的主要代码如下:
public ConfigurableApplicationContext run(String... args) {ConfigurableApplicationContext context = null;FailureAnalyzer analyzer = null;configureHeadlessProperty();// 步骤1SpringApplicationRunListeners listeners = getRunListeners(args);listeners.starting();try{// 步骤2ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);Banner printBanner = printBanner(environment);// 步骤3context = createApplicationContext();prepareContext(context, environment, listeners, applicationArguments, printBanner);refreshContext(context);afterRefresh(context, applicationArguments);listeners.finished(context, null);// 省略return context;}
}SpringApplciationRunListener应用启动监控模块
应用启动监控模块对应上述源码中的注释步骤1到步骤2之间的两行代码,它创建了应用的监听器SpringApplicationRunListeners并开始监听,监控模块通过调用getSpringFactoriesInstances私有协议从META-INF/spring.factories文件中取得SpringApplicationRunListener监听器实例。
当前事件监听器SpringApplicationRunListener中只有一个EventPublishingRunlistener广播事件监听器,它的starting方法会封装成SpringApplicatiionEvent事件广播出去,被SpringApplication中配置的listener监听。这一步骤执行完成后也会同时通知SpringBoot其他模块目前监听初始化已经完成,可以开始执行启动方案了。
ConfigurableEnviroment 配置环境模块和监听
对应上述源码注释中的步骤2到步骤3之间的几行代码,下面分解步骤说明:
(1) 创建配置环境,创建应用程序的环境信息。如果是Web程序,创建StandardServletEnvironment;否则创建StandardEnviroment;
(2) 加载属性配置文件,将配置文件加入监听器对象中(SpringApplicationRunListeners)。通过configPropertySource方法设置properties配置文件,通过执行configProfies方法设置profiles;
(3) 配置监听,发布environmentPrepared事件,及调用ApplicationListener#onApplicationEvent方法,通知SpringBoot应用的environment已经准备完成。
ConfigurableApplicationContext配置应用上下文
对应源码中的步骤3下面的几行代码,下面分解步骤说明:
(1)配置Spring容器应用上下文对象,它的作用是创建Run方法的返回对象ConfigurableApplicationContext(应用配置上下文),此类主要继承了ApplicationLifeCycle、Closeable接口,而ApplicationContext是Spring框架中负责Bean注入容器的主要载体,负责bean加载、配置管理、维护bean之间依赖关系及Bean生命周期管理。
(2)配置基本属性,对应prepareContext方法将listener、environment、banner、applicationArguments等重要组件与Spring容器上下文对象关联。借助SpringFactoriesLoader查找可用的ApplciationContextInitailizer, 它的initialize方法会对创建好的ApplicationContext进行初始化,然后它会调用SpringApplicationRunListener#contextPrepared方法,此时SpringBoot应用的ApplicationContext已经准备就绪,为刷新应用上下文准备好了容器。
(3)刷新应用上下文,对应源码中的refreshContext(context)方法将通过工程模式产生应用上下文中所需的bean。实现spring-boot-starter-*(mybatis、redis等)自动化配置的关键,包括spring.factories的加载、bean的实例化等核心工作。然后调用SpringApplicationRunListener#finish方法告诉SprignBoot应用程序,容器已经完成ApplicationContext装载。
六、Spring Boot的可执行Jar和非可执行Jar有什么区别?
- 区别
- 普通jar包:可以被其他项目应用依赖,不可以用 java -jar xxx.jar 运行。
- 可运行jar包:不可以被其他项目应用依赖,可以用 java -jar xxx.jar 运行。
注:SpringBoot项目默认打包的是可运行jar包,普通项目默认打包的是不可运行的jar包,但是,普通项目也可以打包成可运行jar包。
- 为什么有区别
疑问:
同样是执行mvn package命令进行项目打包,为什么 Spring Boot 项目就打成了可执行 jar ,而普通项目则打包成了不可执行 jar 呢?
解答:
Spring Boot 项目默认的插件配置 spring-boot-maven-plugin 依赖包,这个打包插件存在 5 个方面的功能,如下:


五个功能分别是:
(1)build-info:生成项目的构建信息文件 build-info.properties
(2)repackage:这个是默认 goal,在 mvn package 执行之后,这个命令再次打包生成可执行的 jar,同时将 mvn package 生成的 jar 重命名为 *.origin
(3)run:这个可以用来运行 Spring Boot 应用
(4)start:这个在 mvn integration-test 阶段,进行 Spring Boot 应用生命周期的管理
(5)stop:这个在 mvn integration-test 阶段,进行 Spring Boot 应用生命周期的管理
默认情况下使用就是 repackage 功能,其他功能要使用,则需要开发者显式配置。
- Spring Boot打包过程
SpringBoot的 repackage 功能的作用,就是在打包的时候,多做一点额外的事情:
(1)首先 mvn package 命令 对项目进行打包,打成一个 jar,这个 jar 就是一个普通的 jar,可以被其他项目依赖,但是不可以被执行
(2)repackage 命令,对第一步 打包成的 jar 进行再次打包,将之打成一个 可执行 jar ,通过将第一步打成的 jar 重命名为 *.original 文件
举例说明:
Spring Boot 项目进行打包,可以执行 mvn package 命令,也可以直接在 IDEA 中点击 package进行打包,打包结果如下显示:

可以看到有两个文件,admin-0.0.1-SNAPSHOT.jar 是可运行jar包,admin-0.0.1-SNAPSHOT.jar.original是被重命名的 可依赖jar包。
- jar包之间的差异
可执行 jar 包的结构:

可执行 jar 中,我们自己的代码是存在 于 BOOT-INF/classes/ 目录下,另外,还有一个 META-INF 的目录,该目录下有一个 MANIFEST.MF 文件,打开该文件,内容如下:
Manifest-Version: 1.0
Created-By: Maven Jar Plugin 3.2.0
Build-Jdk-Spec: 14
Implementation-Title: admin
Implementation-Version: 0.0.1-SNAPSHOT
Main-Class: org.springframework.boot.loader.JarLauncher
Start-Class: org.yolo.admin.AdminApplication
Spring-Boot-Version: 2.3.4.RELEASE
Spring-Boot-Classes: BOOT-INF/classes/
Spring-Boot-Lib: BOOT-INF/lib/
Spring-Boot-Classpath-Index: BOOT-INF/classpath.idxStart-Class :这就是可执行 jar 的入口类
Spring-Boot-Classes : 代码编译后的位置
Spring-Boot-Lib : 项目所依赖的 jar 的位置
如果自己要打一个可执行 jar 包的话,除了添加相关依赖之外,还需要配置 META-INF/MANIFEST.MF 文件。
不可执行 jar 包的结构:
首先将默认的后缀 .original 除去,然后给文件重命名 .jar,重命名完成,进行解压 如下:

不可执行 jar 根目录就相当于我们的 classpath,直接就能看到我们的代码,并且也拥有 META-INF/MANIFEST.MF 文件,但是文件中没有定义启动类等配置。
Manifest-Version: 1.0
Created-By: Maven Jar Plugin 3.2.0
Build-Jdk-Spec: 14
Implementation-Title: admin
Implementation-Version: 0.0.1-SNAPSHOT注:这个不可以执行 jar 也没有将项目的依赖打包进来。
由此可见这两个jar包内部结构是完全不同的,因此一个可以直接执行,另一个则可以被其他项目依赖。
七、Spring Cloud核心组件?
Eureka : 注册中心,用于服务的注册和发现
Ribbon/Feign : 负载均衡/服务调用
Hystrix :断路器,提高分布式系统的弹性
GateWay/Zuul :网关管理,由GateWay 网关转发请求给对应的服务,服务同一的转发,以及权限管理和过滤
SpringConfig:分布式配置中心
Sentinel:限流、熔断降级
八、Redis有几种集群模式?
为了保证其高可用,Redis的集群模式有三种。
- 主从模式
特点:一主多从,主从复制
优点:
• 实现读写分离,主从复制期间IO非阻塞,并且解决了单机故障。
缺点:
• 主机宕机期间,数据不能及时同步到从机,造成数据不一致。
• 当多个从机宕机恢复后,大量的SYNC同步会造成主机 IO压力倍增。
• 扩容复杂。
- 哨兵模式
特点:sentinel哨兵监控
优点:
• 哨兵模式基于主从模式,因此主从模式的优点哨兵模式都具有。
• 哨兵具备主从切换和故障转移功能。
缺点:
• 较难支持在线扩容。
- 集群(cluster)模式
特点:分布式存储,每台机器节点上存储不同的内容;扩容缩容。
优点:
• sentinel哨兵模式基本已经实现了高可用,但是每台机器都存储相同内容,很浪费内存,所以Redis Cluster 实现了分布式存储。
• 多个组之间相互监测。
• 基于哈希槽(默认16384)的动态分配,分配空间到主或从上,实现扩容和缩容。
九、缓存击穿的主要原因和解决方式是啥?
- 主要原因:
某个热点key过期,但是此时有大量的用户访问该过期key。
- 解决方式:
• 使用互斥锁
只有一个请求可以获取到互斥锁,然后到DB中将数据查询并返回到Redis,之后所有请求就可以从Redis中得到响应。【缺点:所有线程的请求需要一同等待】
• 逻辑过期
在value内部设置一个比缓存(Redis)过期时间短的过期时间标识,当异步线程发现该值快过期时,马上延长内置的这个时间,并重新从数据库加载数据,设置到缓存中去。【缺点:不保证一致性,实现相较互斥锁更复杂】
• 提前对热点数据进行设置
类似于新闻、某博等软件都需要对热点数据进行预先设置在Redis中,或者适当延长Redis中的Key过期时间。
十、缓存穿透的主要原因和解决方式是啥?
- 主要原因
客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会访问数据库。导致DB的压力瞬间变大而卡死或者宕机。
- 解决办法
• 接口校验
类似于用户权限的拦截,对于id = -3872这些无效访问就直接拦截,不允许这些请求到达Redis、DB上。
• 对空值进行缓存
比如,虽然数据库中没有id = 1022的用户的数据,但是在redis中对其进行缓存(key=1022, value=null),这样当请求到达redis的时候就会直接返回一个null的值给客户端,避免了大量无法访问的数据直接打在DB上。
但需要注意:
key设置的过期时间不能太长,防止占用太多redis资源,设置一个合适的TTL,比如两三分钟。
当遇到黑客暴力请求很多不存在的数据时,就需要写入大量的null值到Redis中,可能导致Redis内存占用不足的情况。
• 使用布隆过滤器
十一、Linux相关命令
ifconfig 查看IP地址。top 运行的进程和系统性能信息。free -h 内存使用情况。df -h 磁盘使用情况。systemctl status firewalld 防火墙状态。systemctl start firewalld 开启防火墙。systemctl stop firewalld 中断防火墙。文件和目录相关操作:
切换目录
ll 查看当前目录下的所有文件。cd .. 切换到上级目录。cd /opt 切换到opt目录下。cd bin 切换到当前目录的bin目录下。cd test 切换到当前目录下的test目录下。创建目录
mkdir /opt/data 在opt目录下创建目录data。mkdir -p data/mysql
在当前目录下创建目录data,并且在data下创建mysql(一次创建多级目录)。复制文件
cp gateway.jar gateway-bank-2023-08-12.jar
把文件gateway.jar复制为gateway-bank-2023-08-12.jar作为备份。删除文件
rm test.txt 提示删除 text.txt 文件。rm -f test.txt 强制删除 text.txt 文件。rm -r data 提示递归删除data目录。rm -rf data 强制递归删除data目录。查看文件
cat text.txt 查看text.txt文件内容,所有内容一次性显示出来tail -f text.txt 实时查看text.txt文件的末尾内容grep "mysql" text.txt //查看文件text.txt中包含mysql的内容查找文件
find / -name text.txt 从根目录查找名称为text.txt的文件find /opt *.java 查找opt目录下的.java文件find /opt *.java | grep user
搜索opt目录下,所有名称包含user的.java文件十二、设计原则
- 单一职责
单一职责原则要求一个接口或类只有一个原因引起变化,也就是说一个接口或一个类只有一个原则,它就只负责一件事。
class Animal {public void dogVoice (){System.out.println("狗叫声:旺旺");}public void cowVoice (){System.out.println("牛叫声:哞哞");}
}
class DogVoice {public String getDogVoice (){return "旺旺" ;}
}
class CowVoice {public String getCowVoice (){return "哞哞" ;}
}- 接口隔离
类的接口可以被分解为多组功能函数的组合,每一组都服务于不同的客户类,而不同的客户类可以选择使用不同的功能分组。
interface ReadBlog {String getBlog () ;
}
interface AdminBlog {Boolean insertBlog () ;Boolean updateBlog () ;Boolean deleteBlog () ;
}
/*** 读者只开放博客阅读接口*/
class Reader implements ReadBlog {@Overridepublic String getBlog() {return null;}
}
/*** 管理员有博客全部的管理权限*/
class AdminUser implements AdminBlog,ReadBlog {@Overridepublic String getBlog() {return null;}@Overridepublic Boolean insertBlog() {return null;}@Overridepublic Boolean updateBlog() {return null;}@Overridepublic Boolean deleteBlog() {return null;}
}- 依赖倒转
高层模块不应该依赖低层模块,两者应依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象;中心思想是面向接口编程。
public class C01_FarmFactory {public static void main(String[] args) {Animal animal = new Dog() ;FarmFactory farm = new Farming() ;farm.breed(animal) ;animal = new Pig() ;farm.breed(animal) ;}
}
/*** 接口声明依赖对象*/
interface FarmFactory {void breed (Animal animal) ;
}
class Farming implements FarmFactory {@Overridepublic void breed(Animal animal) {System.out.println("农场饲养:"+animal.getAnimalName());}
}
interface Animal {String getAnimalName () ;
}
class Dog implements Animal {@Overridepublic String getAnimalName() {return "牧羊犬";}
}
class Pig implements Animal {@Overridepublic String getAnimalName() {return "土猪一号";}
}- 里氏替换
- 存在,一个类型T1,和实例的对象O1
- 存在,一个类型T2,和实例的对象O2
如果将所有类型为T1的对象O1都替换成类型T2的对象O2,程序的行为不发生改变。那么类型T2是类型T1的子类型。换句话说,所有引用基类的地方必须能透明地使用其子类的对象。
public class C01_Calculate {public static void main(String[] args) {BizCalculate bizCalculate = new BizCalculate() ;System.out.println(bizCalculate.add(2,3));}
}
class Calculate { }
class BaseCalculate extends Calculate {public int add (int a,int b){return a+b;}
}
/*** 这里使用组合的方式完成计算*/
class BizCalculate extends Calculate {private BaseCalculate baseCalculate = new BaseCalculate() ;public int add (int a,int b){return this.baseCalculate.add(a,b);}
}- 开闭原则
应该考虑对扩展开放,对修改关闭。
- 迪米特原则
迪米特原则又叫最少知道原则,即一个类对自己依赖的类知道的越少越好。也就是说,对于被依赖的类不管多么复杂,都尽量将逻辑封装在类的内部。对外除了提供的public方法,不对外开放任何信息。
迪米特原则的初衷是降低类之间的耦合。







![RAG私域问答场景超级详细方案(第一期方案)[1]:工业级别构建私域问答(知识处理、知识召回排序、搜索问答模块)](https://img-blog.csdnimg.cn/img_convert/6f2648ecf791ccec4b7f995c0025cb4b.png)