1.Rethinking temporal self-similarity for repetitive action counting

标题:重新思考重复动作计数的时间自相似性
作者: Yanan Luo, Jinhui Yi, Yazan Abu Farha, Moritz Wolter, Juergen Gall
文章链接:https://arxiv.org/abs/2407.09392

摘要:
计算未经修剪的长视频中的重复动作是一项具有挑战性的任务,具有许多应用,例如康复。最先进的方法通过首先从采样帧生成时间自相似矩阵(TSM),然后将矩阵馈送到预测器网络来预测动作计数。然而,自相似矩阵并不是网络的最佳输入,因为它从逐帧嵌入中丢弃了太多信息。因此,我们重新思考如何利用 TSM 来计算重复动作,并提出一个学习嵌入并以全时间分辨率预测动作开始概率的框架。然后根据动作开始概率推断重复动作的数量。与当前以 TSM 作为中间表示的方法相比,我们提出了一种基于生成的参考 TSM 的新颖损失,它强制学习的逐帧嵌入的自相似性与重复动作的自相似性一致。所提出的框架在三个数据集(即 RepCount、UCFRep 和 Countix)上实现了最先进的结果。
这篇论文试图解决什么问题?
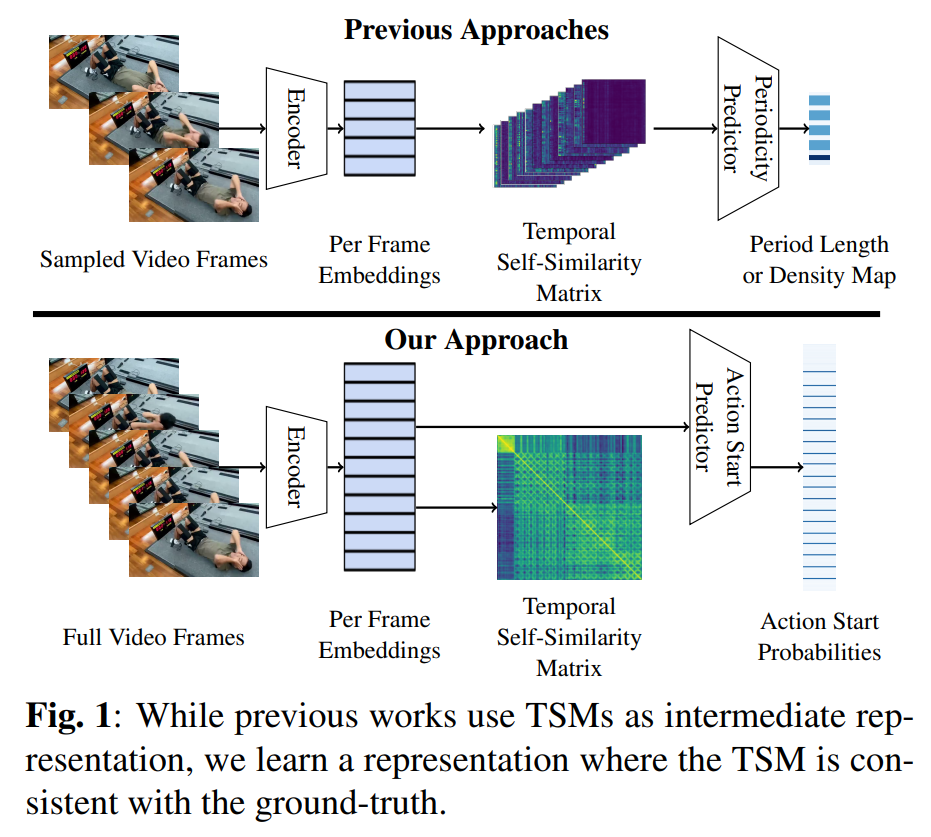
这篇论文试图解决的问题是在长视频中对重复动作进行计数的挑战。具体来说,它关注于类无关的重复动作计数任务,即预测视频中执行的动作重复次数。这项任务在诸如康复等许多实际应用中非常重要。现有的最先进方法通过首先从采样的帧生成时间自相似性矩阵(Temporal Self-Similarity Matrix, TSM),然后将该矩阵输入到预测网络中来预测动作计数。然而,TSM作为输入并不是最优的,因为它从帧级嵌入中丢弃了太多信息。因此,论文提出了一个框架,该框架学习嵌入并在完整时间分辨率下预测动作开始概率,然后从动作开始概率推断重复动作的数量。与将TSM作为中间表示的当前方法不同,论文提出了一种基于生成的参考TSM的新损失函数,该函数强制学习到的帧级嵌入的自相似性与重复动作的自相似性一致。所提出的框架在三个数据集上取得了最先进的结果,即RepCount、UCFRep和Countix。
论文如何解决这个问题?
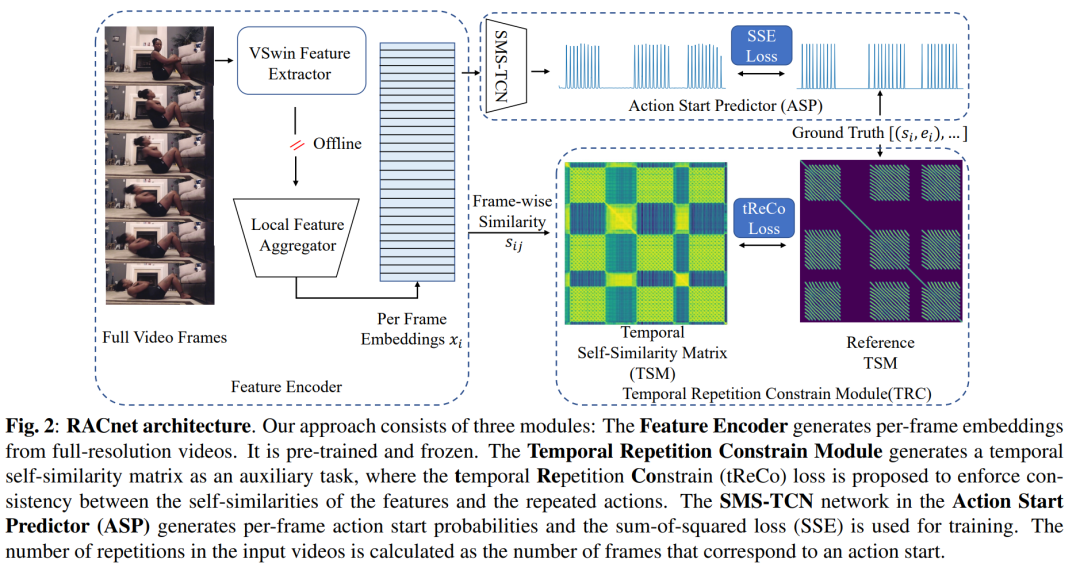
论文通过提出一个名为RACNet(Repetitive Action Counting network)的新框架来解决重复动作计数问题。以下是该框架的关键组成部分和解决策略:
-
特征编码器(Feature Encoder):
-
使用预训练的Video Swin Transformer作为空间特征提取器,为输入视频的每一帧提取特征。
-
通过3D卷积层和2D空间池化来丰富特征,以保留时间上下文信息。
-
-
时间重复约束模块(Temporal Repetition Constrain Module, TRC):
-
构建时间自相似性矩阵(TSM),用于表示视频帧之间的相似性。
-
生成参考TSM(S_ref),假设动作重复的帧嵌入应该具有高相似性。
-
引入时间重复一致性损失(Temporal Repetition Consistency loss, tReCo loss),强制学习到的帧嵌入的自相似性结构与重复动作的结构一致。
-
-
动作开始预测器(Action Start Predictor, ASP):
-
采用Sigmoid-Multi-Stage TCN(SMS-TCN)网络,预测每一帧作为动作重复开始的概率。
-
使用高斯分布作为目标,通过平方和误差(SSE)损失函数来训练动作开始预测。
-
-
损失函数:
-
结合SSE损失和tReCo损失,通过调整λ值来平衡两种损失的影响。
-
-
推理过程:
-
在推理阶段,使用编码器网络获取帧嵌入,然后通过ASP获取动作开始的预测概率。
-
通过计算预测输出中对应动作开始的帧数来确定动作重复的数量。
-
-
数据集和评估:
-
在RepCountA、UCFRep和Countix三个数据集上进行评估,使用Off-By-One Accuracy (OBOA)和Mean Absolute Error (MAE)作为评估指标。
-
-
实验和比较:
-
与现有的最先进方法进行比较,展示了RACNet在不同数据集上的性能。
-
-
可视化和案例研究:
-
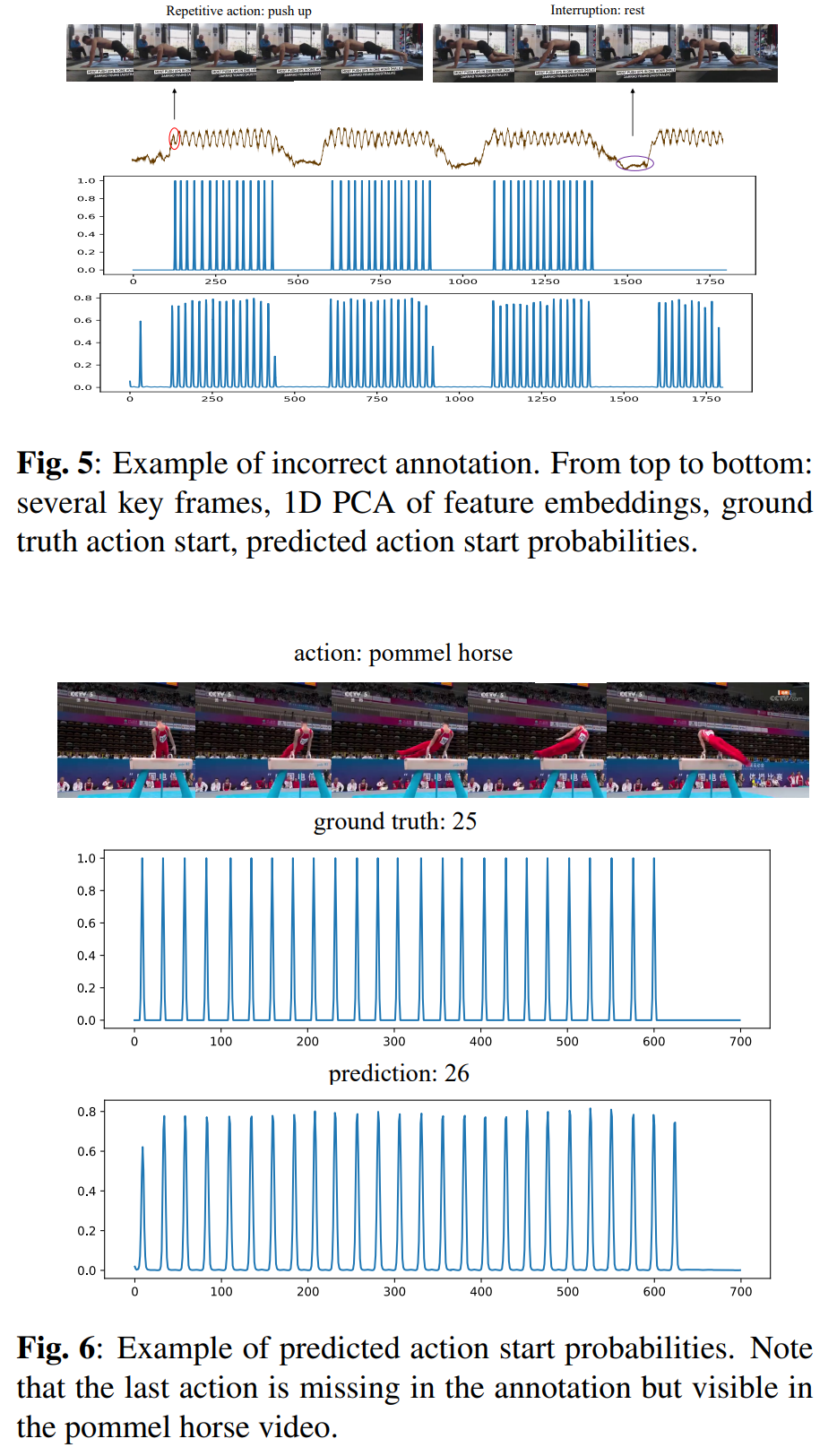
提供了TSM、动作开始概率和预测结果的可视化,展示了模型对动作重复计数的理解和准确性。
-
通过这种方法,论文提出的RACNet框架能够在不同长度的视频上实现准确的重复动作计数,并且在所选数据集上达到了最先进的性能。
论文做了哪些实验?
论文中进行了一系列实验来评估所提出的RACNet模型的性能,并与现有的最先进方法进行比较。以下是论文中提到的主要实验内容:
-
数据集:使用了三个大规模数据集进行评估,分别是RepCountA、UCFRep和Countix。
-
评估指标:使用了Off-By-One Accuracy (OBOA)和Mean Absolute Error (MAE)作为评估指标。
-
实现细节:描述了使用Video Swin Transformer进行特征提取、模型训练的学习率、优化器、批量大小和训练周期等实现细节。
-
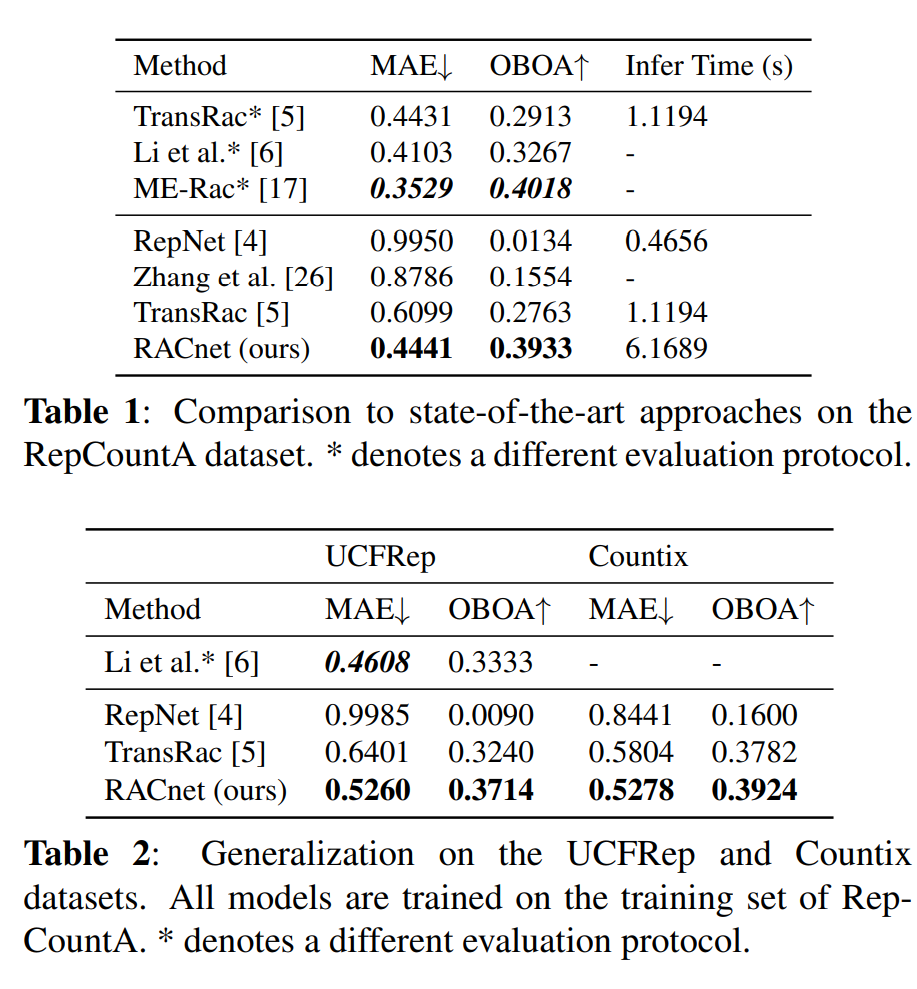
与现有方法的比较:在RepCountA数据集上与TransRac、ME-Rac、RepNet等现有方法进行了比较,展示了RACNet在MAE和OBOA指标上的优势。
-
泛化性能:评估了RACNet在未见过的视频上的性能,即在RepCountA数据集上训练并在UCFRep和Countix数据集上进行评估。
-
消融研究:
-
研究了tReCo损失对模型性能的影响。
-
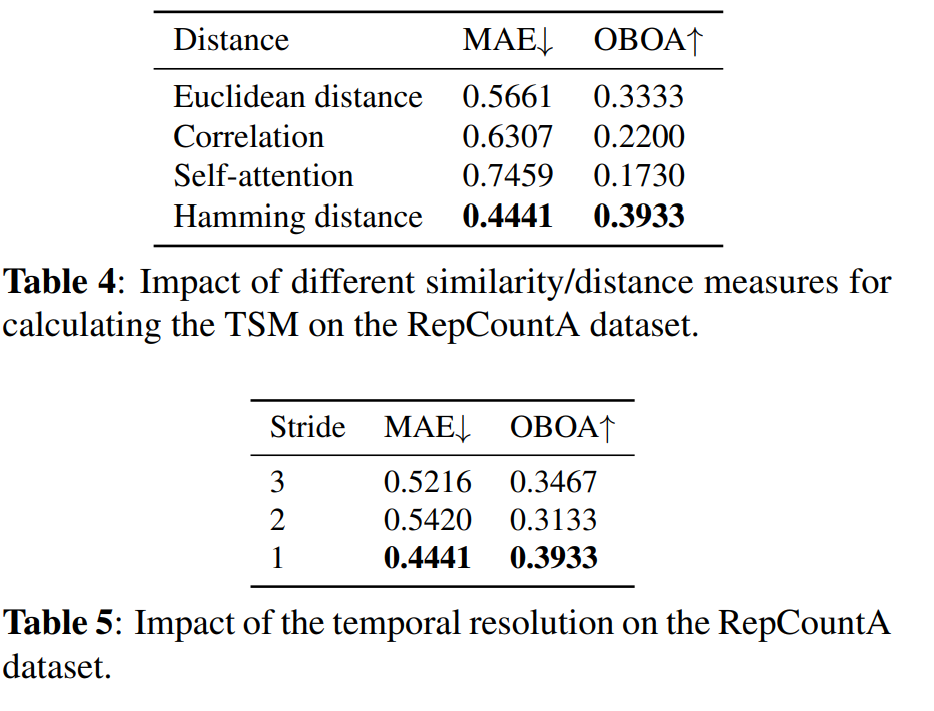
比较了不同相似性/距离度量方法(如欧几里得距离、相关性、自注意力和汉明距离)在计算TSM时的影响。
-
评估了时间分辨率对模型性能的影响。
-
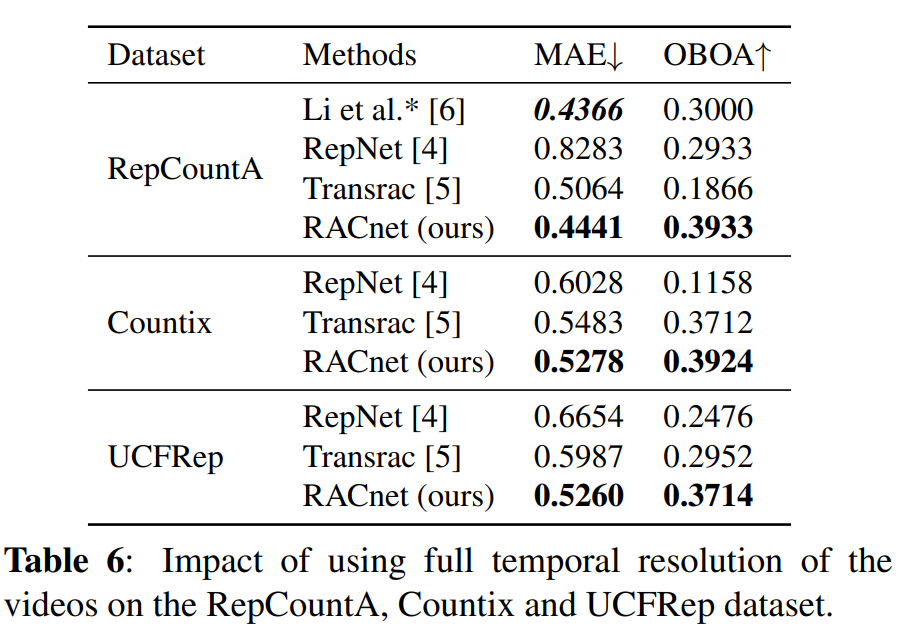
比较了使用全分辨率视频对模型性能的影响。
-
-
预测动作开始与周期性:比较了预测动作开始与预测周期性的方法,并展示了预测动作开始的优越性。
-
可视化:
-
展示了时间自相似性矩阵(TSM)的可视化,包括RepNet的TSM、参考TSM和RACNet的TSM。
-
展示了动作开始概率的可视化,包括1D PCA特征嵌入、真实动作开始注释和RACNet预测的动作开始概率。
-
-
案例研究:提供了RACNet在实际视频上预测动作开始的例子,包括成功定位每个动作的开始并预测正确数量的重复动作。
这些实验结果表明,RACNet在重复动作计数任务上具有较高的准确性和泛化能力,并且在所选数据集上达到了最先进的性能。
论文的主要内容:
这篇论文的主要内容可以总结如下:
-
问题定义:论文针对长视频中的重复动作计数任务,提出了一个新的方法。这项任务在多个领域,如康复训练等,具有实际应用价值。
-
现有方法的局限性:现有的方法通过生成时间自相似性矩阵(TSM)来预测动作计数,但这种方法会丢失大量帧级特征信息,不是最优的网络输入。
-
提出的框架:论文提出了一个新框架RACNet,它在完整时间分辨率下学习嵌入并预测动作开始概率,从而推断出重复动作的数量。
-
关键组件:
-
特征编码器(Feature Encoder):使用预训练的Video Swin Transformer提取每帧的空间特征。
-
时间重复约束模块(Temporal Repetition Constrain Module, TRC):构建TSM并引入时间重复一致性损失(tReCo loss),以确保学习到的嵌入能够反映动作的重复性。
-
动作开始预测器(Action Start Predictor, ASP):采用Sigmoid-Multi-Stage TCN网络预测每帧作为动作开始的概率。
-
-
损失函数:结合了平方和误差(SSE)损失和时间重复一致性损失(tReCo loss)来训练模型。
-
实验与评估:在RepCountA、UCFRep和Countix三个数据集上进行了广泛的实验,使用OBOA和MAE作为评估指标,证明了RACNet在重复动作计数任务上的有效性。
-
消融研究:通过一系列消融实验,展示了tReCo损失、相似性度量方法、时间分辨率和全分辨率视频使用对模型性能的影响。
-
可视化:提供了TSM和动作开始概率的可视化,展示了模型如何捕捉动作的重复结构。
-
结论:RACNet通过直接预测动作开始并使用时间重复约束损失来提高计数准确性,在三个数据集上达到了最先进的性能。
-
未来工作:论文还提出了一些可能的研究方向,包括多模态输入、模型鲁棒性改进、实时应用等。
整体而言,这篇论文在视频重复动作计数领域提供了一种新颖的方法,并通过实验验证了其有效性。
2.Open-Canopy: A Country-Scale Benchmark for Canopy Height Estimation at Very High Resolution

标题: 开放冠层:极高分辨率冠层高度估计的国家级基准
作者:Fajwel Fogel, Yohann Perron, Nikola Besic, Laurent Saint-André, Agnès Pellissier-Tanon, Martin Schwartz, Thomas Boudras, Ibrahim Fayad, Alexandre d'Aspremont, Loic Landrieu, Phillipe Ciais
文章链接:https://arxiv.org/abs/2407.09392
项目代码:https://github.com/fajwel/Open-Canopy


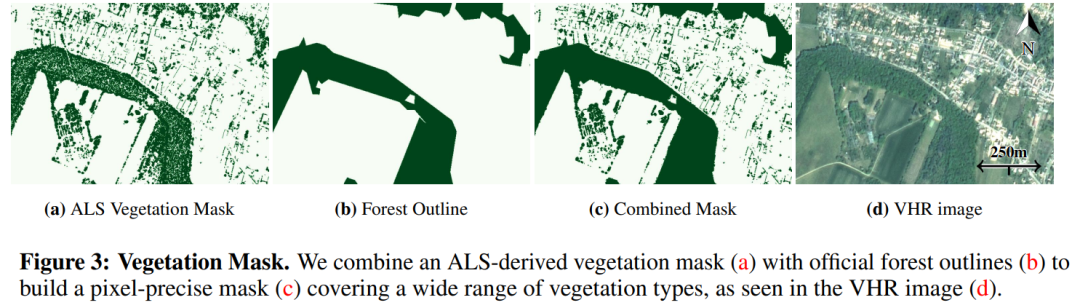
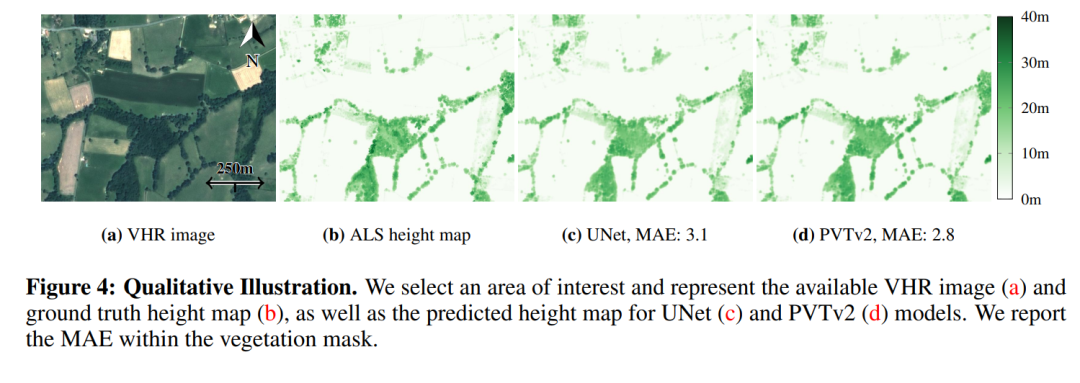
摘要:
根据卫星图像以米分辨率估算树冠高度和树冠高度变化具有许多应用,例如监测森林健康、伐木活动、木材资源和碳储量。然而,许多现有的森林数据集基于商业或封闭数据源,限制了新方法的再现性和评估。为了解决这一差距,我们引入了 Open-Canopy,这是第一个开放获取的国家级基准,用于极高分辨率(1.5 m)树冠高度估计。 Open-Canopy 覆盖法国超过 87,000 公里 2 ,将 SPOT 卫星图像与高分辨率航空 LiDAR 数据相结合。我们还提出了 Open-Canopy- Δ ,这是不同年份拍摄的两张图像之间树冠高度变化检测的第一个基准,即使对于最近的模型来说,这也是一项特别具有挑战性的任务。为了为这些基准奠定坚实的基础,我们评估了用于树冠高度估计的最先进计算机视觉模型的综合列表。
这篇论文试图解决什么问题?
这篇论文介绍了一个名为Open-Canopy的新型开放获取、国家级尺度的基准测试,旨在解决从卫星图像中以非常高的空间分辨率(1.5米)估计冠层高度的问题。具体来说,它试图解决以下几个问题:
-
监测森林健康状况:通过估计冠层高度及其变化,可以监测森林健康、记录伐木活动、木材资源和碳储量。
-
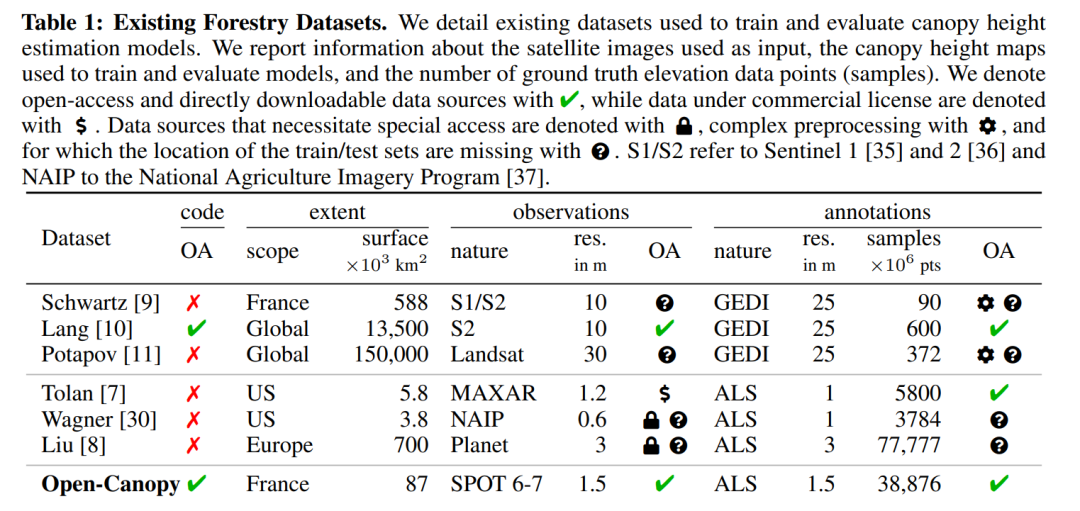
提高数据可访问性:许多现有的森林数据集基于商业或封闭的数据源,限制了新方法的可复制性和评估。Open-Canopy提供了一个开放获取的数据集,以促进新方法的开发和评估。
-
高分辨率冠层高度估计:高空间和时间分辨率的冠层高度估计对于其关键应用至关重要,例如检测较小的植被、了解生物多样性和更准确地估计生物量。
-
冠层高度变化检测:Open-Canopy还提出了Open-Canopy-Δ,这是第一个用于检测两幅不同年份拍摄的图像之间冠层高度变化的基准测试,这对于理解森林健康动态、检测树木死亡和非法伐木活动非常重要。
-
评估现代计算机视觉模型:论文还评估了一系列最新的计算机视觉模型,用于从VHR(非常高分辨率)卫星图像中估计冠层高度,包括基于Vision Transformers的架构和几种视觉基础模型。
-
促进森林管理实践:通过提供高分辨率的年度监测,可以帮助森林管理机构更有效地响应气候变化,实现更及时的森林管理。
总的来说,Open-Canopy基准测试旨在通过提供一个开放的数据集和评估工具,推动冠层高度估计技术的发展,并支持更有效的森林资源管理和监测。
论文如何解决这个问题?
论文通过以下几个关键步骤解决高分辨率冠层高度估计的问题:
-
数据集构建:创建了Open-Canopy,这是一个开放获取的、覆盖法国超过87,000平方公里的国家级基准测试数据集。它结合了SPOT卫星图像和高分辨率航空LiDAR数据。
-
数据集特性:提供了1.5米分辨率的VHR卫星图像,并使用LiDAR数据生成了相应的冠层高度图。这些数据涵盖了多种气候类型和森林类型,有助于训练和评估模型。
-
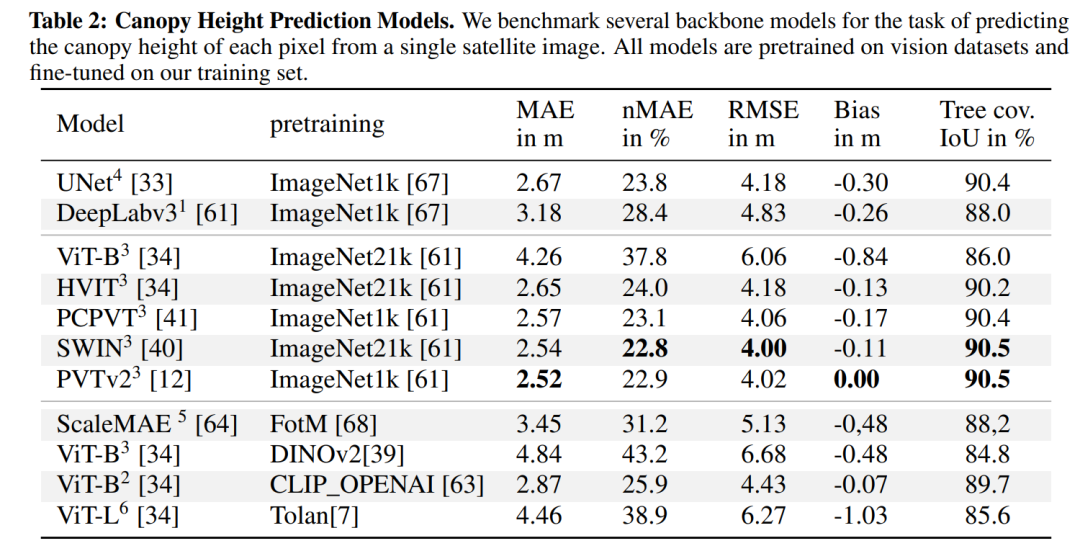
模型评估:评估了一系列最新的计算机视觉模型,包括基于UNet的架构、Vision Transformers (ViT)、以及它们的变体,如SWIN、PCPVT和PVTv2。这些模型在Open-Canopy数据集上进行了训练和测试。
-
模型适应性:研究了预训练模型对冠层高度估计任务的适应性,包括在ImageNet和其他大型自然图像数据集上预训练的模型。
-
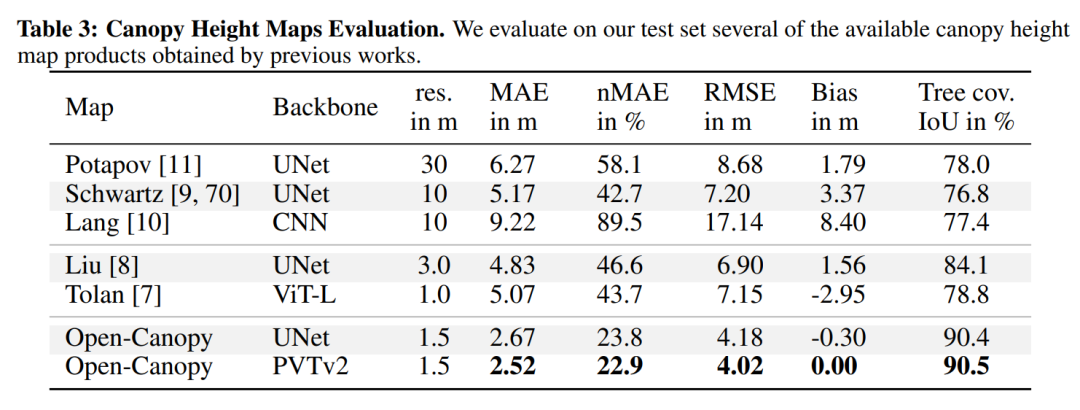
性能指标:使用了五个指标来评估模型性能,包括均方根误差(RMSE)、平均绝对误差(MAE)、归一化MAE、偏差和树覆盖的交并比(IoU)。
-
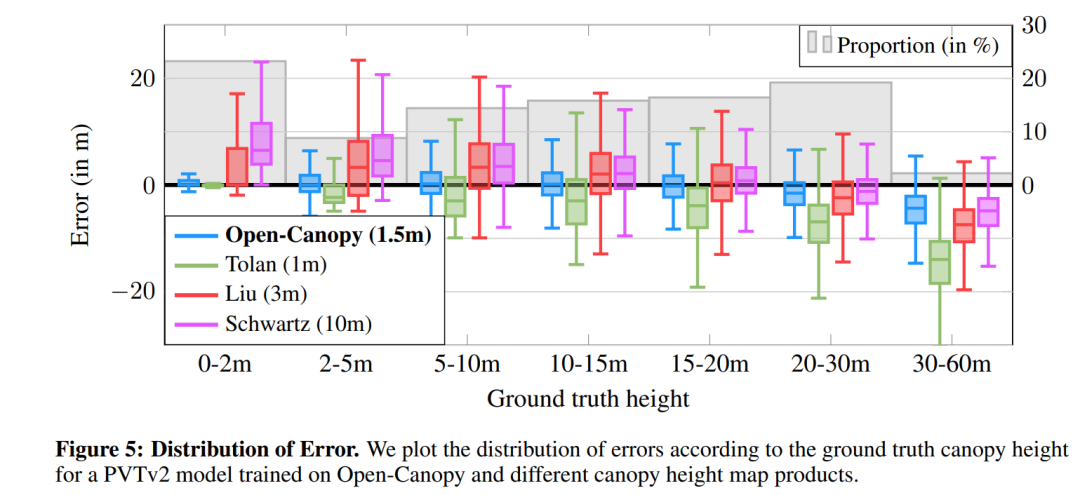
结果分析:对模型进行了定量和定性分析,发现基于Transformer的架构在这项任务中表现出色,尤其是在检测高大树木方面。
-
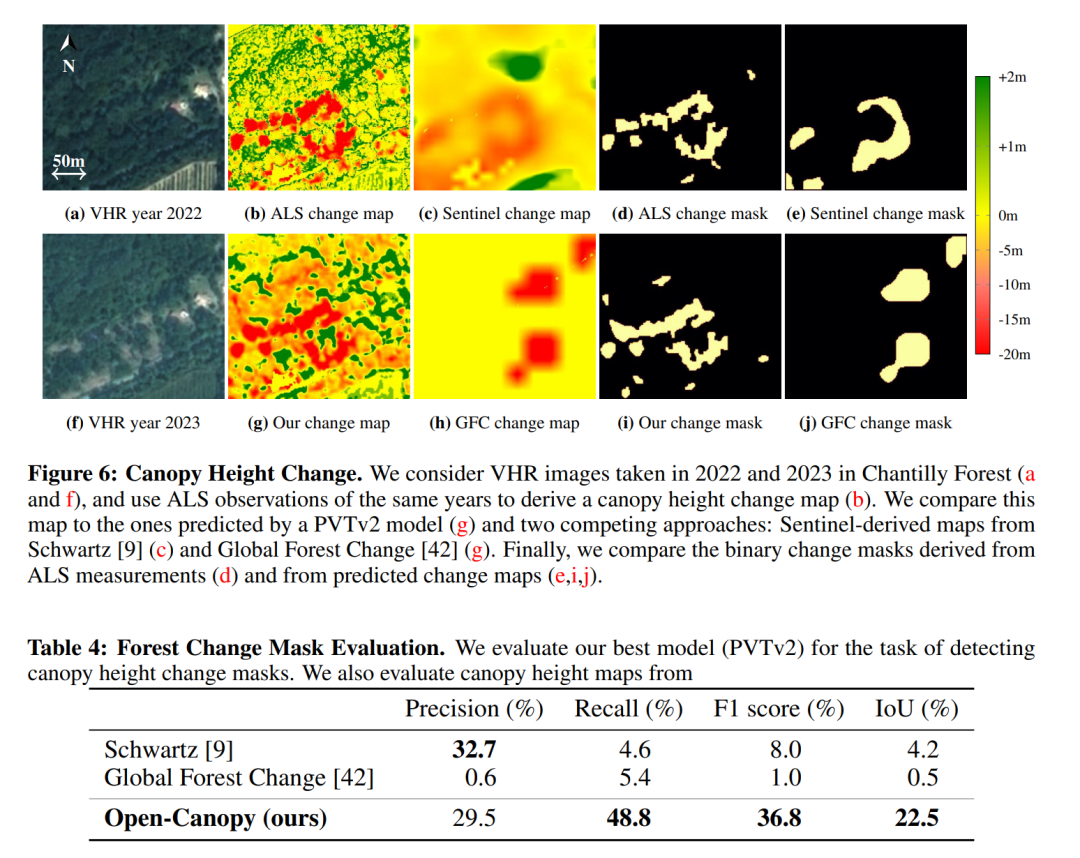
Open-Canopy-Δ:提出了一个新的基准测试,用于检测连续VHR图像之间的冠层高度变化。这包括创建一个新的数据集,并使用模型来预测两幅图像之间的高度变化。
-
透明度和可访问性:论文提供了数据、代码、分割和模型的开放访问,以促进研究社区的进一步研究和开发。
-
资源和支持:论文还提到了使用HPC/AI资源进行实验,这些资源由GENCI-IDRIS和Inria提供。
通过这些步骤,论文不仅提供了一个高分辨率的冠层高度估计基准,而且还评估和比较了多种现代计算机视觉模型,为未来的研究和应用提供了有价值的见解和工具。
论文做了哪些实验?
论文中进行了一系列实验来评估和分析不同计算机视觉模型在冠层高度估计任务上的性能。以下是主要的实验内容:
-
模型选择与适应性:选择了多种基于卷积神经网络(CNN)和视觉变换器(ViT)的模型,包括UNet、DeepLabv3、ViT及其变体(如SWIN、PCPVT、PVTv2),并评估了它们在冠层高度估计任务上的表现。
-
预训练模型的影响:研究了预训练模型对冠层高度估计任务的适应性,包括在ImageNet和其他大型自然图像数据集上预训练的模型。
-
模型性能评估:使用均方根误差(RMSE)、平均绝对误差(MAE)、归一化MAE、偏差和树覆盖的交并比(IoU)等指标来评估模型性能。
-
数据集分割:将数据集分为训练集、验证集和测试集,并在这些不同的数据集上评估模型性能。
-
模型训练与超参数选择:使用ADAM优化器和学习率调度器进行模型训练,并通过早期停止来选择超参数。
-
结果分析:对模型的定量性能进行了分析,包括不同模型的MAE、RMSE、IoU等指标的比较。
-
定性评估:通过可视化的方式展示了不同模型预测的冠层高度图与真实LiDAR数据生成的高度图之间的对比。
-
模型泛化能力分析:研究了在不同高度范围内模型的泛化能力,特别是对于不同高度的树木。
-
Open-Canopy-Δ基准测试:为冠层高度变化检测任务提出了一个新的基准测试,并评估了模型在这个任务上的性能。
-
模型在不同分辨率下的性能:将模型预测的冠层高度图和真实数据都转换为10米分辨率,并重新评估了所有可用模型的性能。
-
变化检测参数的影响:研究了变化检测过程中不同参数配置对性能的影响,包括最小高度差异和最小连续变化区域的大小。
这些实验为理解不同模型在冠层高度估计任务上的性能提供了深入的见解,并展示了Open-Canopy数据集和基准测试的有效性。
论文的主要内容:
这篇论文介绍了Open-Canopy,一个国家级、开放获取的基准测试,用于从非常高分辨率(VHR)的卫星图像中估计冠层高度。以下是论文的主要内容总结:
-
问题背景:随着气候变化的加速,需要更快速响应的森林管理实践,包括监测森林资源的演变。传统的基于航空激光扫描(ALS)的方法成本高昂,无法实现年度监测。
-
Open-Canopy数据集:论文提出了Open-Canopy,这是第一个开放获取的、覆盖法国超过87,000平方公里的VHR冠层高度估计基准测试。它结合了SPOT卫星图像和高分辨率航空LiDAR数据。
-
Open-Canopy-Δ:作为Open-Canopy的扩展,提出了第一个用于检测两幅连续VHR卫星图像之间冠层高度变化的基准测试。
-
模型评估:评估了一系列最新的计算机视觉模型,包括基于UNet的架构、Vision Transformers (ViT)及其变体(如SWIN、PCPVT、PVTv2)等,用于从VHR卫星图像中估计冠层高度。
-
性能指标:使用了均方根误差(RMSE)、平均绝对误差(MAE)、归一化MAE、偏差和树覆盖的交并比(IoU)等指标来评估模型性能。
-
实验结果:实验结果显示,基于Transformer的架构在冠层高度估计任务中表现出色,尤其是在检测高大树木方面。
-
数据和代码的开放性:论文提供了数据、代码、分割和模型的开放访问,以促进研究社区的进一步研究和开发。
-
局限性:尽管数据集具有鲁棒性,但它有一些局限性,如地理焦点限制、ALS数据的局限性和生物量估算的不完美性。
-
贡献:Open-Canopy基准测试为评估新的计算机视觉架构提供了一个平台,并可能激发林业专家设计定制架构。
-
未来方向:论文讨论了未来可能的研究方向,包括全球通用性的提高、季节性影响的研究、更高分辨率数据的探索、多时相数据分析等。
总的来说,这篇论文通过提供Open-Canopy基准测试和Open-Canopy-Δ,为冠层高度估计和变化检测领域做出了重要贡献,并推动了这一领域的研究和应用。
3.Radiance Fields from Photons

标题:光子的辐射场
作者:Sacha Jungerman, Mohit Gupta
文章链接:https://arxiv.org/abs/2407.09386





摘要:
神经辐射场(NeRF)已成为从多个视点捕获的图像集合进行高质量视图合成的事实上的方法。然而,在具有挑战性的条件下(例如低光、高动态范围或快速运动)在野外捕获图像时仍然存在许多问题,导致重建结果出现明显的伪影。在这项工作中,我们引入了量子辐射场,这是一种新型的神经辐射场,它使用单光子相机(SPC)以单个光子的粒度进行训练。我们开发理论和实用计算技术,用于构建辐射场并根据 SPC 捕获的非常规、随机和高速二进制帧序列估计密集相机姿势。我们通过模拟和 SPC 硬件原型演示了高速运动、弱光和极端动态范围设置下的高保真重建。
这篇论文试图解决什么问题?
这篇论文介绍了一种名为Quanta Radiance Fields(QRFs)的新型神经辐射场,旨在解决传统神经辐射场(Neural Radiance Fields,简称NeRFs)在实际应用中面临的一些挑战。具体来说,这些挑战包括:
-
低光照和高动态范围(HDR)条件下的成像问题:在这些条件下,传统NeRFs可能会产生带有明显伪影的模糊重建。
-
快速运动导致的图像模糊:在快速运动或长时间曝光下,像素强度可能会受到运动模糊的影响。
-
低光照环境中的噪声问题:在低光照条件下,图像传感器的读出噪声可能会影响重建的质量。
-
数据采集的效率和质量:传统相机由于帧率较低,可能无法捕捉到足够的视角多样性,导致重建结果的几何约束不足。
QRFs通过使用单光子相机(Single-Photon Cameras,简称SPCs)以单个光子的粒度进行训练,从而在极低光照和高动态范围设置下实现快速且连续的捕获、忠实的重建,有效去噪和去模糊训练数据,而无需依赖专门技术,并且能够为更多样的姿态生成新视图合成。这种方法有望在极端的成像条件下实现高质量的重建,并且在给定的总捕获时间内,通过高速单光子相机采样更密集的视点集,从而提高场景几何估计的保真度。
论文如何解决这个问题?
论文通过提出Quanta Radiance Fields (QRFs) 解决了上述问题,具体方法包括:
-
单光子相机训练:QRFs使用单光子相机(SPCs)进行训练,这些相机能够以极高的速度(如每秒10万帧以上)检测和计数单个光子,从而捕获更精细的图像数据。
-
理论发展:论文开发了用于构建辐射场和从SPCs捕获的高速度、随机和二进制帧序列中估计密集相机姿态的理论和计算技术。
-
二进制帧处理:QRFs直接在单光子相机捕获的二进制帧上训练,通过定义一个基于二进制测量的光度损失项,使得网络能够学习场景的光度信息。
-
数据加载方案:为了处理单光子相机捕获的大量数据,论文设计了一种数据加载方案,通过位打包和内存映射整个位打包数组来解决带宽和内存问题。
-
相机姿态优化:论文提出了一种针对高速单光子相机的新型姿态优化正则化器,允许同时学习数十万帧的相机姿态,并通过傅里叶域平滑来优化相机轨迹。
-
去噪和去模糊:QRFs利用单光子相机的高信噪比特性,在训练过程中有效去噪和去模糊,而无需依赖专门的技术。
-
视图外推:由于单光子相机能够以更高的帧率捕获更多样化的视点,QRFs能够在训练数据之外进行更高质量的新视图合成。
-
实验验证:论文通过模拟和使用单光子相机硬件原型,在多种成像场景下展示了QRFs的高保真重建能力。
-
解决挑战:论文讨论了构建QRFs所面临的挑战,如单光子相机技术的成熟度、分辨率限制、缺乏颜色滤波阵列和高内存需求等问题,并指出了未来工作的方向。
通过这些方法,论文展示了在极端成像条件下,如低光照、高动态范围和快速运动,QRFs能够实现高质量的3D重建和新视图合成。
论文做了哪些实验?
论文中进行了多种实验来验证Quanta Radiance Fields (QRFs) 的性能和效果。以下是论文中提到的一些关键实验:
-
模拟实验:作者使用Blender软件渲染了一个场景,并模拟了单光子相机和传统相机在高动态范围场景中高速移动的情况。实验中,他们训练了一个传统的NeRF和一个QRF,并比较了在极端低光和高动态范围条件下的重建质量。
-
真实世界实验:作者使用SwissSPAD2单光子相机捕获了真实世界的场景,并展示了使用该相机捕获的数据进行重建的结果。这些实验包括房间规模和桌面场景的捕获,并与使用传统相机捕获的数据进行了比较。
-
相机姿态优化实验:为了展示相机姿态优化的重要性,作者展示了优化过程中使用和不使用正则化器的重建结果。这些实验表明,使用正则化器可以显著改善重建质量。
-
运动模糊和去模糊实验:作者比较了使用传统NeRF方法、ExBluRF方法和QRFs在处理运动模糊方面的效果。实验结果表明,尽管单光子相机的原始帧可能更嘈杂,但QRFs能够实现更好的重建效果。
-
视图外推实验:作者展示了QRFs在视图外推方面的能力,即使在训练视图和测试视图之间存在较大差异时,QRFs也能够生成高质量的重建。
-
数据加载和处理实验:为了解决单光子相机产生的大量数据问题,作者开发了一种数据加载方案,并通过实验展示了这种方案在训练过程中的效率。
-
硬件实验:作者使用SwissSPAD2单光子相机作为硬件原型,捕获了多个场景,并展示了使用这些数据进行重建的结果。这些实验结果进一步验证了QRFs在真实世界条件下的有效性。
这些实验不仅展示了QRFs在各种条件下的性能,还突出了其在处理低光照、高动态范围和快速运动等挑战性条件下的优势。
论文的主要内容:
这篇论文的主要内容可以概括为以下几个要点:
-
问题介绍:论文提出了传统神经辐射场(NeRFs)在实际应用中的一些挑战,尤其是在低光照、高动态范围和快速运动条件下的成像问题。
-
Quanta Radiance Fields (QRFs):作为解决方案,作者引入了QRFs,这是一种新型的神经辐射场,它以单个光子为粒度进行训练,使用单光子相机(SPCs)捕获数据。
-
理论基础:论文建立了从单光子相机捕获的二进制帧序列构建辐射场的理论,并开发了估计密集相机姿态的计算技术。
-
技术方法:
-
直接在二进制测量上训练神经辐射场,定义了基于二进制测量的光度损失项。
-
为处理大量数据,设计了位打包和内存映射的数据加载方案。
-
提出了一种针对高速单光子相机的新型相机姿态优化正则化器。
-
-
实验验证:通过模拟和使用单光子相机硬件原型,论文展示了QRFs在高速度运动、低光照和极端动态范围条件下的高保真重建能力。
-
优势和挑战:QRFs在视图外推、去噪和去模糊方面表现出色,但同时也面临技术挑战,如单光子相机技术的成熟度、分辨率限制和内存需求。
-
未来工作:论文讨论了QRFs的潜在改进方向,包括提高相机姿态估计的准确性、改进数据压缩和处理方法,以及探索QRFs在实际应用中的性能。
-
实验结果:使用真实世界数据和模拟数据的实验结果表明,QRFs在多种条件下都能实现高质量的3D重建和新视图合成。
-
讨论和结论:论文总结了QRFs的优势,并指出了需要进一步研究的方向,以实现更广泛的应用和更高的系统性能。
整体而言,这篇论文提出了一种新颖的方法,通过在光子级别上构建场景表示,显著提高了在具有挑战性的成像条件下的3D重建和视图合成的质量。