MySQL
MySQL索引
B+树
B+树和作为索引,有两个明显特点
一是、他的层级非常低,我们都知道传统的平衡二叉树。它们的阶为2,如果数据量很大,AVL树(传统的平衡二叉树)的层级就非常深。但是B+树,它是有序多路查找树。可以大大的降低树的层级。以减少查询的次数。从而大幅度优化时间复杂度。(这也是B树的优点)
二是、B+树只在叶子节点存放数据。和B树在所有节点存放数据相比。它有以下几个好处
- 减少B树查询的极端情况。B树在节点上的数据,查询很快。但是叶子节点上的数据,查询较慢。
- 更好的范围查询性能,B+树在叶子上还形成了双指针。指向前后叶子节点。这就使得B+树的叶子节点形成了双向链表的数据结构。从而大幅度提高范围查询性能。
- 更快的删除和新增操作。B树因为非叶子节点也会存放数据。所以在新增和修改的过程中。会频繁地进行节点分裂和合并操作。但是B+树的数据都放在叶子节点。从而避免了节点的分裂与合并操作。
全文索引
(MyISAM和InnoDB 5.6以后都支持)
专门用于在文本数据上执行搜索操作,如搜索包含特定单词或短语的记录。
全文索引通过一种特殊的数据结构和算法(如倒排索引)来存储和查询文本数据,以实现高效的文本搜索。
创建全文索引的SQL语法类似于创建其他类型的索引,需要使用FULLTEXT关键字,并且全文索引可以包含在一个或多个列上。例如:
CREATE TABLE articles ( id INT AUTO_INCREMENT, title VARCHAR(200), body TEXT, PRIMARY KEY (id), FULLTEXT (title, body)
) ENGINE=InnoDB;
哈希索引
(MEMORY/HEAP)
MySQL的hash索引是一种基于哈希表(Hash Table)实现的特殊数据库索引类型,它利用哈希函数(Hash Function)将索引列的值转化为一个固定长度的哈希码(Hash Code),然后用这个哈希码作为索引项在表中定位数据记录的位置。
哈希索引的优势:
查询速度快:对于等值查询,hash索引的查询效率非常高,理想情况下接近O(1)的时间复杂度。
内存优化:在MySQL中,hash索引通常是一种内存优化的索引结构,即数据存储在内存中而不是磁盘上,这进一步提高了查询效率。
哈希索引的局限:
不支持范围查询:由于哈希函数的特性,hash索引无法直接支持范围查询(如使用“<”或“>”运算符的查询),这类查询需要全表扫描。
哈希冲突:由于哈希函数的输出范围是有限的,而输入数据的范围可能是无限的,因此在实际应用中,哈希冲突几乎是不可避免的。当发生哈希冲突时,MySQL通常采用开放地址法、链表法等技术来解决。
索引失效
当使用复合索引时,查询sql又不符合最左前缀原则时。索引往往会失效。
复合索引在mysql中是以键值对的形式存在的,也就是<K,V>形式。MySQL往往以K作为传统的id进行排序保存操作。而当人们使用V进行查找时。MySQL就会认为这还不如全局查找呢。于是就会发生索引失效的情况。
同样的,如果我们用字符串的模糊查找。例如要查找abc,不用a%,而用%c。这也不符合最左前缀原则,mysql也会使用全局查找而放弃索引。
学习视频:
【吊打面试官】MySQL索引失效的底层原理,终于有人讲清楚了
动画演示:用最简单直白的方式讲解MySQL的主键索引、普通索引和联合索引
终于把B树搞明白了(一)_B树的引入,为什么会有B树
事务ACID
原子性
事务是不可分割的最小单元,一个事务的若干sql操作。要么统一成功,要么统一失败。(redoLog)
持久性
数据库的数据在宕机,丢失数据的情况下。可以回滚数据,这由mysql的日志完成(redoLog)
隔离性
两个事务的操作,应该互不干扰。一个事务,不会对另一个事务照成干扰。(锁)
一致性
一个事务执行前后并不会破坏数据库的一致性。比如一张表的name字段是唯一的,事务执行后,并不对name字段的唯一性造成破坏。(undoLog)
RedoLog和BinLog的区别
使用情景
binlog 主从复制,容灾备份
redolog 维持事务的一致性ACID
记录形式
binlog 有三种格式的日志保存log
redolog 纯物理记录日志
记录时机
binlog 每条sql都会记录
redolog 只有事务执行完毕才会保存日志
MYSQL锁的算法
行锁
Record Lock
单个行上锁
GapLock
间隙锁,锁定一个范围。但不包括记录本身。
Next-Key Lock
范围锁 相当于 Record Lock + GapLock(包含记录本身)
MySQL锁的问题
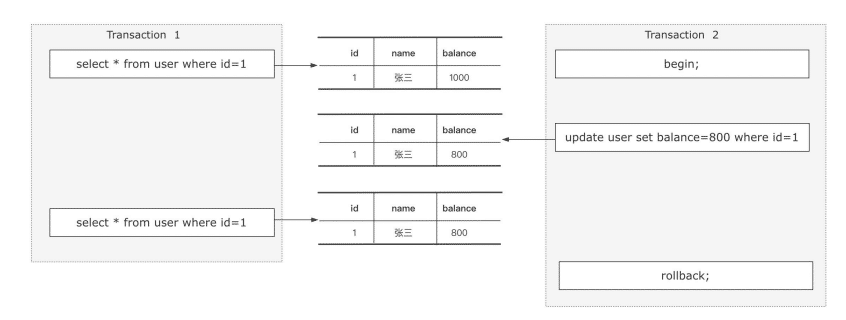
脏读
事务A读了两次,事务B的还没提交,结果事务A读的两次不一致。
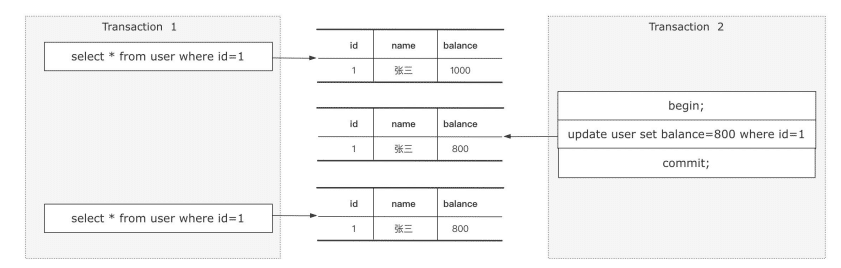
不可重复读
事务A两次读取的途中,事务B修改了一行数据。
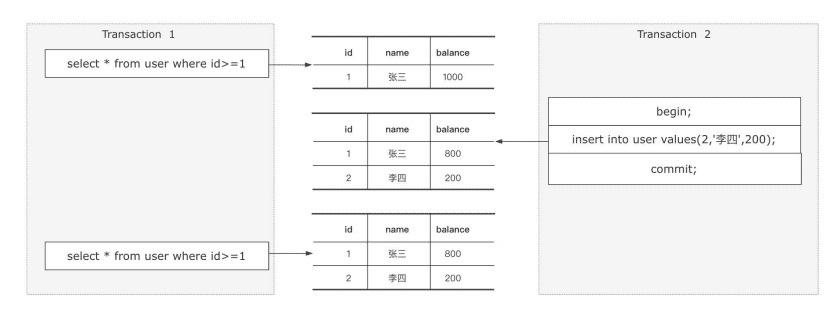
幻读
事务A两次读取的途中,事务B新增了一行数据。
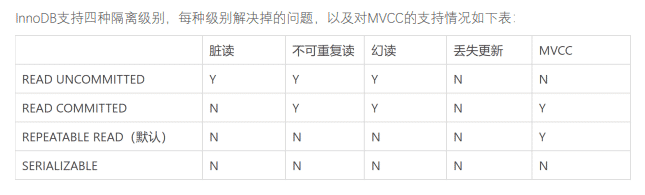
MVCC
MVCC多版本并发控制,是为了解决事务操作中并发安全性问题而诞生的一种技术。
MVCC 主要解决了三个问题
1、采用乐观锁的机制,降低死锁概率。
2、解决一致性读的问题。事务开始到结束都读的同一份数据。
3、解决读写并发阻塞问题。提升数据并发处理能力。
事务的隔离级别
读已提交
通过Record Lock算法实现了行锁,而READ COMMITTED允许读取提交数据,所以不存在脏读问题,但存在不可重复读问题。
读未提交
通过Record Lock算法实现了行锁,但READ UNCOMMITTED允许读取未提交数据,所以存在脏读问题
可重复读
使用Next-Key Lock算法实现了行锁,并且不允许读取已提交的数据,所以解决了不可重复读的问题。
另外,该算法包含了间隙锁,会锁定一个范围,因此也解决了幻读的问题
串行化
对每个SELECT语句后自动加上LOCK IN SHARE MODE,即为每个读取操作加一个共享锁。因此在这个
事务隔离级别下,读占用了锁,对一致性的非锁定读不再予以支持。
效果
MySQL的优化
架构设计层面的优化
主从复制
读写分离
分库分表
引入缓存
SQL优化
通过慢查询日志定位SQL语句
通过explain语句分析SQL语句
改SQL
例子:https://www.bilibili.com/video/BV1fM4m127tb/?spm_id_from=333.1007.top_right_bar_window_history.content.click
思想:面对大批量数据排序。只排序id再查全部数据,比全部数据一股脑排序性能更好。
因为:mysql分为服务层和存储引擎层。如果把所有数据放在mysql服务层会导致mysql压力过大。把单独的id放在服务层排序。压力会小很多。



![[ACP云计算]组件介绍](https://i-blog.csdnimg.cn/direct/eee4214b985346989de3faa862b47fc8.png)