在 LLM 应用程序中构建稳健性和确定性
图片来自作者
欢迎来到雲闪世界。OpenAI最近宣布其最新的gpt-4o-2024–08–06模型支持结构化输出。与大型语言模型 (LLM) 相关的结构化输出并不是什么新鲜事——开发人员要么使用各种快速工程技术,要么使用第三方工具。
在本文中,我们将解释什么是结构化输出、它们如何工作以及如何将它们应用于您自己的基于 LLM 的应用程序中。尽管 OpenAI 的公告使得使用他们的 API 实现起来非常容易(正如我们将在此处演示的那样),但您可能希望选择开源Outlines包(由dottxt上的可爱人员维护),因为它可以应用于自托管开放权重模型(例如 Mistral 和 LLaMA)以及专有 API(免责声明:由于此问题, Outlines 在撰写本文时不支持通过 OpenAI API 生成结构化 JSON;但这很快就会改变!)。
什么是结构化输出?
如果RedPajama 数据集有任何指示,那么绝大多数预训练数据都是人类文本。因此,“自然语言”是 LLM 的原生领域——无论是在输入中,还是在输出中。然而,当我们构建应用程序时,我们希望使用机器可读的形式结构或模式来封装我们的数据输入/输出。这样我们就可以在应用程序中构建稳健性和确定性。
结构化输出是一种机制,通过该机制,我们可以在 LLM 输出上强制执行预定义模式。这通常意味着我们强制执行 JSON 模式,但它不仅限于 JSON — 原则上我们可以强制执行 XML、Markdown 或完全定制的模式。结构化输出的好处有两方面:
-
更简单的提示设计——在指定输出应该是什么样子时,我们不需要过于冗长
-
确定性名称和类型——我们可以保证在 LLM 响应中获得age具有Number JSON 类型的属性
实现 JSON 模式
在这个例子中,我们将使用Sam Altman 的维基百科条目的第一句话……
塞缪尔·哈里斯·奥特曼 (Samuel Harris Altman,1985 年 4 月 22 日出生) 是一位美国企业家和投资者,自 2019 年起担任 OpenAI 的首席执行官(他曾短暂被解雇并于 2023 年 11 月复职)。
…我们将使用最新的 GPT-4o 检查点作为命名实体识别 (NER) 系统。我们将强制执行以下 JSON 模式:
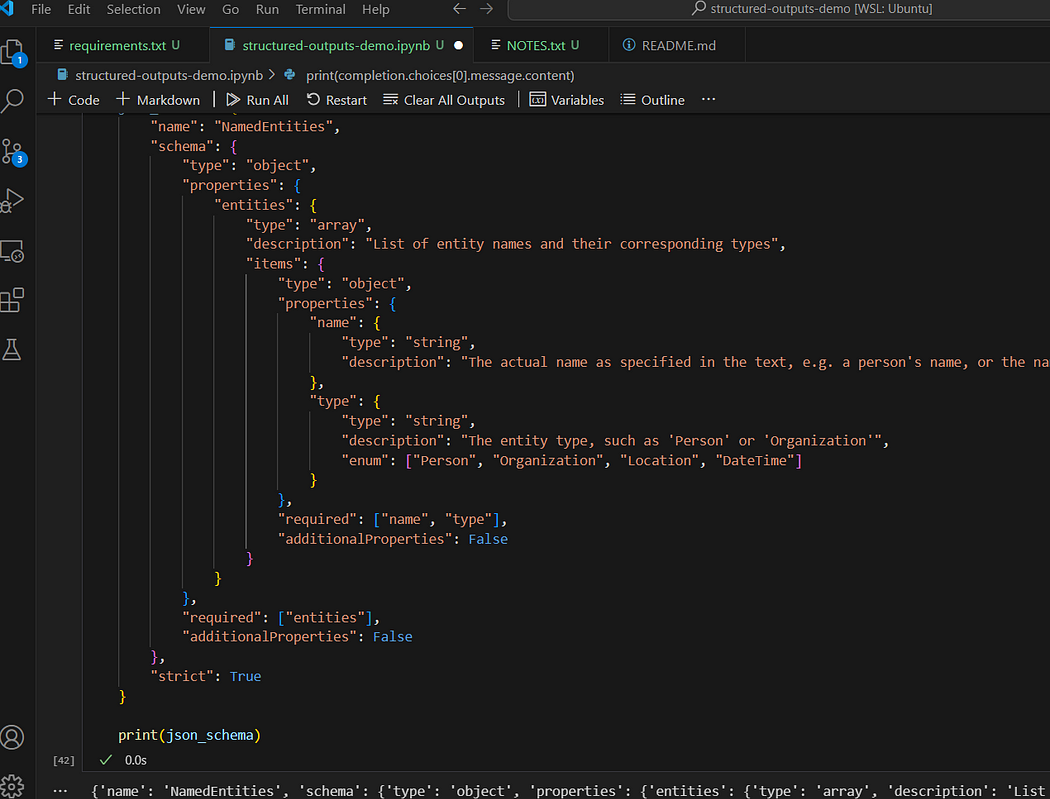
json_schema = { "name": "NamedEntities","name" : "NamedEntities" , "schema" : { "type" : "object" , "properties" : { "entities" : { "type" : "array" , "description" : "实体名称及其对应类型的列表" , "items" : { "type" : "object" , "properties" : { " name" : { "type" : "string" , "description" : "文本中指定的实际名称,例如人名或国家名称"}, "type" : { "type" : "string" , "description" : "实体类型,例如'Person'或'Organization'" , "enum" : [ "Person" , "Organization" , "Location" , "DateTime" ] } }, "required" : [ "name" , "type" ], “additionalProperties” : False} } }, “required” : [ “entities” ], “additionalProperties” : False}, “strict” : True}
本质上,我们的 LLM 响应应该包含一个NamedEntities对象,该对象由一个数组组成entities,每个数组包含一个name和type。这里有几点需要注意。例如,我们可以强制使用枚举类型,这在 NER 中非常有用,因为我们可以将输出限制为一组固定的实体类型。我们必须指定数组中的所有字段required:但是,我们也可以通过将类型设置为例如来模拟“可选”字段["string", null]。
现在,我们可以将模式连同数据和指令一起传递给 API。我们需要response_format用一个字典填充参数,然后提供相应的模式。type"json_schema”
完成 = 客户端。beta.chat.completions.parse( model="gpt-4o-2024-08-06",“gpt-4o-2024-08-06”,消息=[ { “role”:“system”,“content”:“”“您是命名实体识别 (NER) 助理。您的工作是识别并返回给定文本的所有实体名称及其类型。您只能严格遵守以下实体类型:人员、位置、组织和日期时间。如果不确定实体类型,请忽略它。请小心某些首字母缩略词,例如角色头衔“CEO”、“CTO”、“VP”等 - 这些应该被忽略。”“”,},{ “role”:“user”,“content”:s } ],response_format={ “type”:“json_schema”,“json_schema”:json_schema,}
)
输出应如下所示:
{'entities': [{'name':'Samuel Harris Altman','type':'Person'},'实体':[{ '名称':'塞缪尔·哈里斯·奥特曼','类型':'人' },{ '名称':'1985 年 4 月 22 日','类型':'日期时间' },{ '名称':'美国人','类型':'地点' },{ '名称':'OpenAI','类型':'组织' },{ '名称':'2019','类型':'日期时间' },{ '名称':'2023 年 11 月','类型':'日期时间' }]}
本文使用的完整源代码可在此处获得。
工作原理
魔法在于约束采样和上下文无关语法 (CFG)的结合。我们之前提到过,绝大多数预训练数据都是“自然语言”。从统计上讲,这意味着对于每个解码/采样步骤,从学习的词汇表中抽取一些任意标记的可能性都是不可忽略的(在现代 LLM 中,词汇表通常涵盖 40 000 多个标记)。但是,在处理形式模式时,我们确实希望快速消除所有不可能的标记。
在前面的例子中,如果我们已经生成了……
{'实体':[{'名称':'Samuel Harris Altman',‘实体’:[{ ‘名称’:‘塞缪尔·哈里斯·奥特曼’,
...那么理想情况下,我们希望'typ在下一个解码步骤中对标记放置非常高的逻辑偏差,而对词汇表中所有其他标记放置非常低的概率。
本质上就是这种情况。当我们提供模式时,它会被转换成形式语法或 CFG,用于在解码步骤中指导逻辑偏差值。CFG 是那些正在卷土重来的老式计算机科学和自然语言处理 (NLP) 机制之一。这个 StackOverflow 答案实际上对 CFG 进行了非常好的介绍,但本质上它是一种描述符号集合的转换规则的方式。
结论
结构化输出并不是什么新鲜事物,但随着专有 API 和 LLM 服务的出现,它无疑正成为人们最关心的问题。它们在 LLM 不稳定且不可预测的“自然语言”领域与软件工程确定性和结构化领域之间架起了一座桥梁。结构化输出对于任何设计复杂 LLM 应用程序的人来说都是必不可少的,因为LLM 输出必须在各种组件中共享或“呈现”。虽然 API 原生支持终于到来了,但构建者也应该考虑使用 Outlines 等库,因为它们提供了一种与 LLM/API 无关的方法来处理结构化输出。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
![[ACP云计算]组件介绍](https://i-blog.csdnimg.cn/direct/eee4214b985346989de3faa862b47fc8.png)