前言
如SpringBoot官方介绍所说的那样,从SpringBoot3.x开始支持的最低JDK版本为:JDK17(官方推荐使用BellSoft Liberica JDK),其对应的GC为G1。

本文笔者从应用实践的角度出发,记录一些关于GC的一些实践总结。
1. G1简单回顾
1.1 jvm运行时数据区
先回顾一下JVM在运行时可能拥有的区域,即:JVM 运行时数据区(Run-Time Data Areas)。
在不同的JVM版本中所拥有的JVM运行时数据区可能是不同的,如在jdk8以前的永久代(PermGen)现已被元空间(Metaspace)替代。

jdk17中的JVM运行时数据区,分区如下:
- The pc Register(程序计数器)
- Java Virtual Machine Stacks(虚拟机栈)
- Heap(堆)
- Method Area(方法区)
- Run-Time Constant Pool(常量池)
- Native Method Stacks(本地方法栈)
其中与GC最相关的区域为Heap(堆),堆在所有线程中共享,存放每个线程运行时的数据,其对象的管理由 garbage collector(垃圾回收器)进行管理。
查看当前JDK默认使用的垃圾回收器可用java -XX:+PrintCommandLineFlags -version命令查看

如这里的-XX:+UseG1GC则代表此java默认使用的G1垃圾回收器
为了提高垃圾回收的效率,并减少垃圾回收对应用程序性能的影响,在JVM的堆中又分为新生代(Young Gen)和老年代(Old Gen)。

新生代中分为3个区:Eden、S0、S1,其默认大小比例为8:1:1。
可用jinfo -flag SurvivorRatio pid查看当前JVM的SurvivorRatio的数值,其代表Eden区是Survivor区大小的多少倍。
jinfo -flag SurvivorRatio 13236

如这里显示--XX:SurvivorRatio为8,说明此JVM的Eden区大小是Survivor区域的8倍。Survivor区中又有两个大小相同的区域S0和S1,则Eden:S0:S1区域大小比例为8:1:1。
说到这里再提一下:JVM默认堆大小可用PrintFlagsFinal命令查看
以我的电脑为例,示例如下:
java -XX:+PrintFlagsFinal -version|findstr “MaxHeapSize”

将4211081216转为GB则约等于4GB,我这台电脑的物理内存为16G,即最大堆为物理内存的1/4。
1.2 G1简介
自JDK9的正式发布,G1便成为了JDK9+的默认垃圾回收器,与之对应的《JEP 248: Make G1 the Default Garbage Collector》提案也算是有了一个正式的完结。
查阅javase官网《Garbage-First (G1) Garbage Collector》 ,可对G1有一个大致的了解。

简单来说,G1所管理的堆区域由一系列区域(region)组成,每一个region是G1对JVM进行内存管理的最小单元。
需要注意的是,在G1中的年轻代和老年代是动态分配的,即:同一个region,在不同的时刻可能属于不同的分代,如时刻A是属于年轻代,时刻B又属于老年代了。
与之对应的,在使用G1时以前的垃圾回收器(如 Serial GC、Parallel GC)中诸如NewRatio这类的参数在G1时也不再起作用,如仍需要指定老年代和年轻代的大小,可使用G1NewSizePercent、G1MaxNewSizePercent这类设置年轻代占整个堆大小比例的参数。
其他关于G1的介绍有点多,这里就不写了,详细可移步:HotSpot Virtual Machine Garbage Collection Tuning Guide
2. JDK常用监控工具回顾
为了便于我们进行故障排查与定位,在JAVA生态圈中有许多工具可对JVM的运行时数据进行观察分析,一些是JDK内置的,一些是第三方开发的。
各个工具的特点与适应场景会有所不同,为此我们就需要提前了解每个工具的特点,以在遇到问题时能快速做出选择,避免异常问题排查分析时间过久而造成业务的损失。
2.1 jconsole
在windows的JDK中,自带了一个强大GUI的JVM监控工具:jconsole.exe
此程序位于jdk\bin目录下,如:C:\Program Files\BellSoft\LibericaJDK-17\bin

在jconsole中可以看到一些基础数据,如内存使用量、线程状态、MBean(被管理的对象),且支持远程JMX监控,对于一些基础的JVM观测需求基本够用
2.2 VisualVM
与jconsole类似的还有一个工具——VisualVM,但在JDK9开始VisualVM就不再默认包含在 JDK 的 bin 目录中,后续版本需要手动安装一下,项目地址为: https://github.com/oracle/visualvm

VisualVM的界面和功能与jconsole相比要稍微丰富一些,与jconsole相比也更推荐用VisualVM,毕竟功能强大一点还更好看,手动安装一下也是值得的。
2.3 jmap & jstack & jstat
上面介绍的JConsole和VisualVM都是具有GUI界面的监控工具,但在实际生产环境中,我们的java程序往往是运行在没有GUI界面的服务器环境中的,这时jmap、jsatck、jstat之前的则是一个不错的选择,毕竟命令行操作又快又简单。
| 工具 | 主要功能 | 适用场景 |
|---|---|---|
| jmap | 导出内存快照(Heap Dump)、查看内存分布 | 内存泄漏分析、对象分布查看 |
| jstack | 导出线程快照(Thread Dump) | 调试线程死锁、高 CPU 占用等线程问题 |
| jstat | 监控 JVM 性能指标(GC、类加载、内存使用) | 实时性能监控与性能调优 |
这3个工具的适用场景可参考上表,联合适用这3个工具也能做到VisualVM/JConsle的平替。
很久以前,我也曾写过《记一次java程序CPU占用过高问题排查》这篇博文解决过线上环境中的异常问题,其中用到的就是jstack。
命令记不住也没关系,使用 –help 参数可快速了解这些工具的具体用法。
2.4 JMX/JMI
JMI(Java Management Interface) 是 JMX(Java Management Extensions) 的前身,是 Java 提供的一个强大框架,主要用于管理和监控应用程序及其组件。如前面介绍的VisualVM/JConsle都支持JMX这种接口对远程的JVM进行监控,这在异常分析时非常有用。
这里以codecentric/spring-boot-admin:3.3.3中的jar包为例,使用windows上的VisualVM远程连接服务器上的JVM看一下效果:
将docker中的app.jar拷贝到linux主机(ip为192.168.6.66),再修改运行参数指定最大堆和最小堆均为80G,并开启jmx指定jmx端口为9010,运行命令如下:
java -Xms80G -Xmx80G \-Dcom.sun.management.jmxremote \-Dcom.sun.management.jmxremote.port=9010 \-Dcom.sun.management.jmxremote.rmi.port=9010 \-Dcom.sun.management.jmxremote.local.only=false \-Dcom.sun.management.jmxremote.authenticate=false \-Dcom.sun.management.jmxremote.ssl=false \-Djava.rmi.server.hostname=192.168.6.66 \-jar spring-boot-admin-app.jar
待jar启动成功后,在windows主机打开VisualVM并添加JMX连接:

VisualVM运行效果截图如下:

查看线程、堆、执行采样、JVM启动参数等功能一应俱全。
2.5 Arthas
arthas是一款由阿里贡献的jvm检测工具,它使用Attach技术可对正在运行中的java程序进行监测,功能强大使用简单,在生产环境中非常常用。
无论是容器环境还是物理机,arthas的使用都非常方便,下载jar并启动两步就搞定。示例:
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
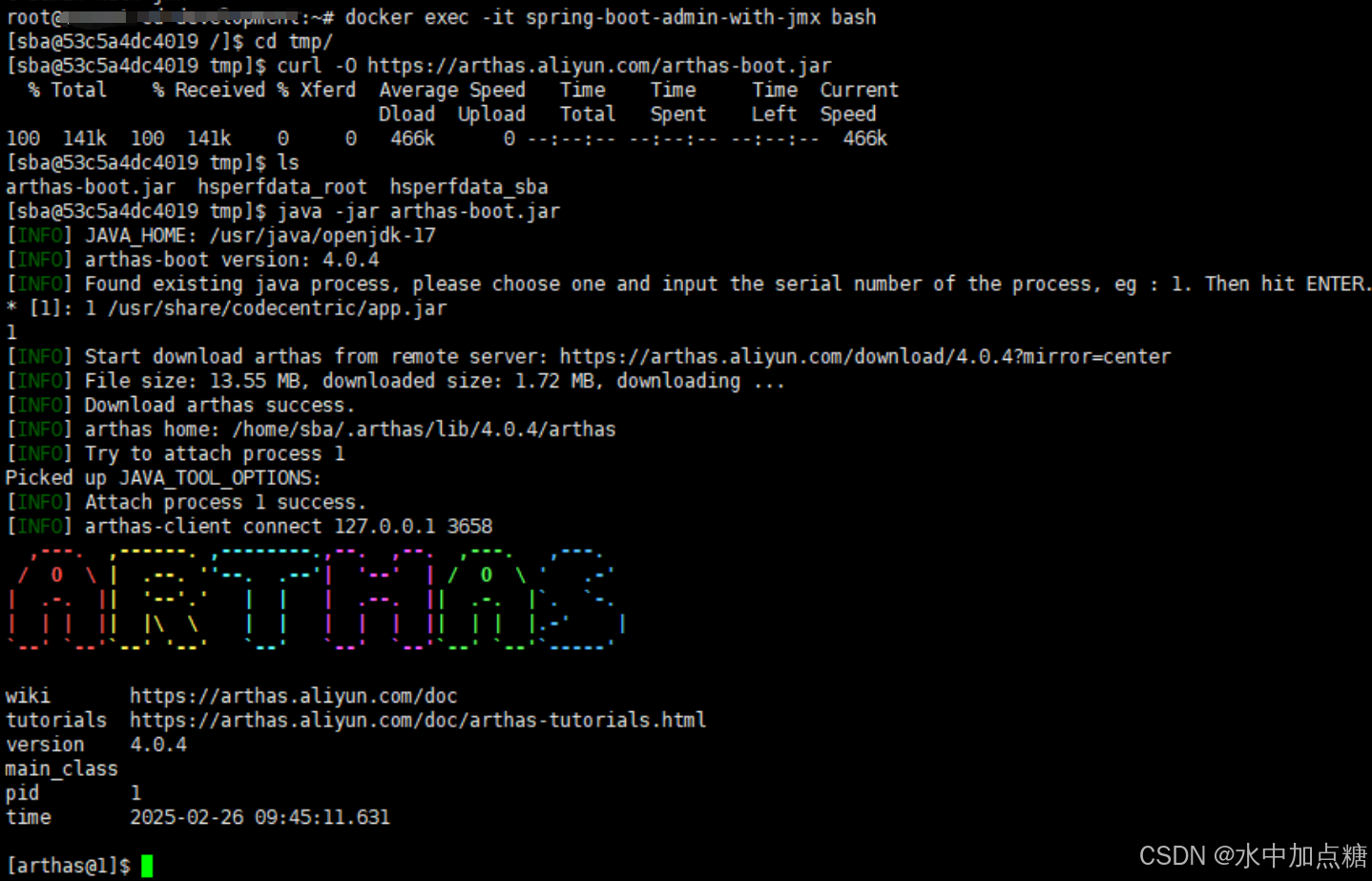
更多命令移步:《arthas命令列表》
另外还有一款功能更为强大的JVM监控分析工具——jprofiler,不过要收费,这里就不整理了。放个截图感受一下:

3. GC异常带来的问题/现象
3.1 OOM异常(示例代码)
我们都知道GC主要对JVM的堆空间进行管理,如果不能及时对堆空间进行回收,则在JVM再次分配空间时可能因为无法分配空间导致OOM异常。
写个让内存满的示例代码,看一下让堆被填满的效果:
import java.util.ArrayList;
import java.util.List;public class OutOfMemoryExample {public static void main(String[] args) {List<byte[]> list = new ArrayList<>();try {for (int i = 0; i < 10000; i++) {System.out.println("第" + i + "次执行");// 每次分配 1MB 的内存list.add(new byte[1024 * 1024]);}} catch (OutOfMemoryError e) {System.out.println("发生内存溢出异常: " + e.getMessage());}}
}
为加快OOM,使用-Xmx100m限制最大堆为100m,循环执行46次后发生了OOM,且应发了程序的异常退出:

异常信息中也显示了OOM的原因为:Java heap space
3.2 程序卡顿/性能下降(示例代码)
程序的性能和gc往往也有着很大的关系,如频繁的gc则会导致原程序中性能的下降。写个示例代码演示下:
import java.util.ArrayList;
import java.util.List;public class GCPerformanceTest {public static void main(String[] args) {System.out.println("Starting test...");runTestWithFrequentGC(true);
// runTestWithFrequentGC(false);}private static void runTestWithFrequentGC(boolean testGc) {System.out.println("Running test with frequent GC...");List<byte[]> memoryHog = new ArrayList<>();long startTime = System.currentTimeMillis();Thread computationThread = startComputationThread();if (testGc) {for (int i = 0; i < 10000; i++) {memoryHog.add(new byte[1024 * 1024]); // 分配1MB对象if (memoryHog.size() > 50) {memoryHog.clear(); // 清空列表,使对象变为垃圾,触发GC}}long endTime = System.currentTimeMillis();System.out.println("Frequent GC test took: " + (endTime - startTime) + " ms");}computationThread.interrupt();}private static Thread startComputationThread() {Thread thread = new Thread(() -> {long startTime = System.currentTimeMillis();long sum = 0;while (!Thread.currentThread().isInterrupted()) {for (int i = 1; i <= 1000000; i++) {sum += i;}}long endTime = System.currentTimeMillis();System.out.println("Computation thread finished. took: " + (endTime - startTime) + " ms");});thread.start();return thread;}
}
为演示方便给代码加上-Xmx256m -Xlog:gc参数,当运行runTestWithFrequentGC(true)时,因为代码频繁触发gc会导致ComputationThread的计算性能下降。示例结果如下:

计算线程耗时为:1590ms,从输出的信息中可以看出发生了大量的gc。
而如果运行runTestWithFrequentGC(false),因为没有大量内存申请释放,则不会频繁触发gc,再看一下效果:

ComputationThread线程中的计算任务在不到1ms就完成了计算,与前面的频繁gc代码相比,1ms VS 1590ms,性能差距一目了然。
4. GC异常定位与示例
关于GC异常定位的方式有很多种,这里记录较为常见的2种方式。
4.1 HeapDumpOnOutOfMemoryError
针对GC异常引发了OOM的这种场景,可以使用HeapDumpOnOutOfMemoryError方式自动导出jvm的堆栈。
这里以前面3.1章节中的示例代码场景为例,我们可在JAVA程序启动时添加以下参数,命令为:
java -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dump
示例:

之后再根据堆栈分析工具进行分析

如这里使用VisualVM对OOM时的堆栈进行分析,则可快速定位出是13行代码运行时发生了OOM。
list.add(new byte[1024 * 1024]);
对着代码一起看,则为:向list中再加入一个1MB的对象时JVM中确实放不下,最终就引发了OOM。
当然,对于上述示例这种场景我们也没有什么解决办法,要么加大堆空间延缓发生OOM的周期,要么就修改代码逻辑不让list填满或适当清理list中的成员。这就好比产品经理提了一个需求,让在1L的冰箱里装下一头100L大象,确实是办不到的。[程序员的无奈]
4.2 对运行的jvm进行分析
前面介绍的场景适用于OOM引起的异常分析,对于JVM能正常运行但性能不佳的场景,则需要用其他工具来进行定位分析。
以本文3.2章节中的场景为例,如发现计算线程的耗时较长,则可先用jstat命令进行初步查看:

如果发现GCT的值一直在变化,则说明一直在发生GC,再结合计算线程的耗时,则可初步判断是耗时较长是由GC引起的。
GCT为JVM 运行到当前时刻为止,所有 GC 事件(包括年轻代 GC、老年代 GC 和并发 GC)累计耗费的时间(单位:秒)
再结合jstack命令可协助定位

如果想进行详细分析,可将堆栈导出,命令为:jmap -dump:format=b,file=<heap_dump_file> <pid>
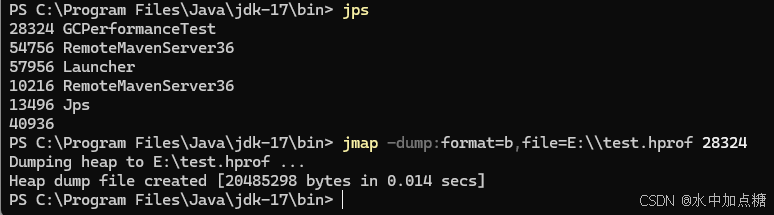
之后再使用工具对导出的hprof文件进行详细分析,如前面提到的VisualVM工具

5. GC参数调整与更换
在大多数的场景下GC的配置参数是不需要调整的,本文出于学习目的,可以了解一下需要调整GC参数的一些特殊场景。具体的场景有很多,这里列举两个。
5.1 固定对象过多场景
目标:向堆中存入4G大小的数据
代码如下:
import java.util.ArrayList;
import java.util.List;public class TestGC {public static void main(String[] args) throws InterruptedException {System.out.println("test start");List<byte[]> yongList = new ArrayList<>();for (int i = 0; i < 4000; i++) {System.out.println(i);// 分配1MB对象yongList.add(new byte[1024 * 1024]);}}
}
不修改任何参数,在物理内存为18G的电脑上以上代码,当输出3447后会因为OOM而导致程序退出,截图如下:

这台电脑的物理内存为18G,最大堆默认为物理内存的1/4,18G * 1/4=4.5G;但存到3.4G时就发生了OOM,有没有觉得很疑惑?明明有4.5G的最大堆空间,才装了3.4G就发生了OOM
但如果我们修改代码,改为每次只存0.5MB,则又能成功运行:
import java.util.ArrayList;
import java.util.List;public class TestGC {public static void main(String[] args) throws InterruptedException {System.out.println("test start");List<byte[]> yongList = new ArrayList<>();for (int i = 0; i < 4000*2; i++) {System.out.println(i);// 分配1MB对象yongList.add(new byte[1024 * 512]);}}
}
截图如下:

同样的目标,不同的写法,为何能产生不同的效果?
这是因为G1的堆是由许多region构成的。通过jcmd <pid> GC.heap_info参数进一步分析:

每个Region的大小为: 4096K(4MB)
当我们每次存1M大小的byte到堆中,因为除了byte外还有额外数据,则会导致每个region则只能存下3个1M大小的byte。大致计算能存放1M大小的byte大致为:4500/4=1125*3=3375M
而当我们每次存512KB大小的byte到堆中,则每个regioin能存放的byte为3.5M,所以最终JVM堆中可以存入4G大小的byte
除了通过修改每次存放的byte大小可以解决上面的问题外,还可以通过调整GC参数来解决。如将每个region的大小修改为8M,让每个region可以装下更多的byte。
配置参数为:-XX:G1HeapRegionSize=8M

之后再次运行,4G大小的byte就装下啦~
5.2 大内存低时延场景
在G1中可使用-XX:MaxGCPauseMillis参数来调整每次GC所允许的最大暂停时间,默认为200ms。MaxGCPauseMillis值的大小影响着每次触发GC时需要回收的region数量,对于大多数应用场景默认的200ms不需要进行调整,但在有些对时延要求较高的场景则可以手动调整它。
除此之外,如遇到JVM运行内存较大的场景,也可以使用ZGC来代替G1,ZGC与G1相比在大内存场景下具有更低的stop-the-world停顿时间,官方说的是不超过1ms(without stopping the execution of application threads for more than a millisecond),最大支持16TB的大内存。(Shenandoah GC延时也很低,但目前还在开发中,按需选择)
这里我们用1台80G内存的服务器,写个简单的springboot-demo验证一下分别使用G1和ZGC的QPS数。接口代码如下:
import jakarta.annotation.PostConstruct;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.ArrayList;
import java.util.List;@RestController
public class TestController {private static final int _1MB = 1024 * 1024;private static final List<byte[]> OLD_GEN_HOLDER = new ArrayList<>();@PostConstructprivate void mockGC() {new Thread(() -> {System.out.println("开始内存分配实验...");int cycle = 0;while (true) {// 阶段1:快速填充老年代(每次循环分配2MB)// 2个1MB对象allocateOldGenObjects(2, 2 * _1MB);// 16MB对象allocateOldGenObjects(8, 16 * _1MB);// 阶段2:创建短期对象触发Young GC// 创建100个临时对象createShortLivedObjects(100);// 阶段3:监控内存状态monitorMemory(cycle++);// 控制循环速度try {Thread.sleep(100);} catch (Exception e) {e.printStackTrace();}}}).start();}private void monitorMemory(int cycle) {Runtime rt = Runtime.getRuntime();long usedMB = (rt.totalMemory() - rt.freeMemory()) / _1MB;long maxMB = rt.maxMemory() / _1MB;// 当内存使用达到80%时尝试释放空间if ((double) usedMB / maxMB > 0.8) {System.out.printf("Cycle %d: 内存使用 %.1f%%, 触发空间释放%n",cycle, (usedMB * 100.0 / maxMB));// 释放部分老年代对象(防止OOM)OLD_GEN_HOLDER.subList(0, OLD_GEN_HOLDER.size() / 2).clear();System.gc(); // 建议触发GC(非必需但可能加速回收)}}private void createShortLivedObjects(int count) {// 创建短期存活对象触发Young GCfor (int i = 0; i < count; i++) {byte[] temp = new byte[2 * 1024]; // 2KB小对象}}private void allocateOldGenObjects(int count, int size) {for (int i = 0; i < count; i++) {// 大对象直接进入老年代(超过region 50%)OLD_GEN_HOLDER.add(new byte[size]);}}@GetMapping(value = "test")public String test() {int j = 0;for (int i = 0; i < 1000000; i++) {for (int x = 0; x < 300; x++) {j = j + i + x;}}return "welcome to https://blog.csdn.net/puhaiyang.j=" + j;}
}
先使用默认的JDK参数验证一下(taskset限制只用4核cpu):
taskset -c 0-3 java -Xmx80G -jar app.jar
默认情况下此JVM的GC使用的是G1,通过jstat -gc <PID> 1000命令可以看到有full gc发生

再使用wrk工具测试一下QPS,安装命令:sudo apt install wrk
测试命令(12个线程、400个用户、持续60秒):
wrk -t12 -c400 -d60s http://127.0.0.1:8080/test
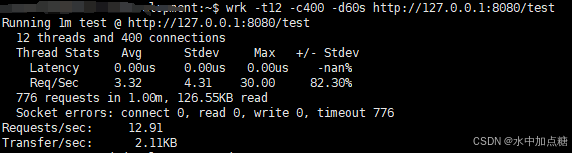
G1时,QPS显示为:12.91
再使用ZGC再次运行此程序:
taskset -c 0-3 java -XX:+UseZGC -Xmx80G -jar app.jar
测试截图为:

ZGC时,QPS显示为:17.29
查看GC情况:jps | awk '/app.jar/{print $1}' | xargs -I {} jstat -gc {} 1000

从测试结果可知:大内存场景下,ZGC和G1相比确实有更低的时延和更大的吞吐量
6.总结
一直以来,JVM中的GC对于JAVA应用开发者的我们来说是一块黑盒,对于它的了解我们大多都是通过查阅各种资料获取,然而各种资料和翻译文章稂莠不齐,查看时记得考虑时效性注意甄别,并结合代码实践验证,对于大多数场景来说基本够用。
如果想要进一步探究GC的详细过程,则需要翻阅JDK的源码,适合熟悉C/C++大佬。
耳闻不如目见,目见不如足践。


















