现在人工智能里的“大明星”——大模型,正在悄悄改变各行各业。这就像给企业装上了一颗聪明的大脑,能帮助解决各种棘手问题,提升工作效率。今天,我们就来分析下企业如何一步一步让这个“大脑”在自家地盘里真正派上用场,实现从0到0.1的一小跳。
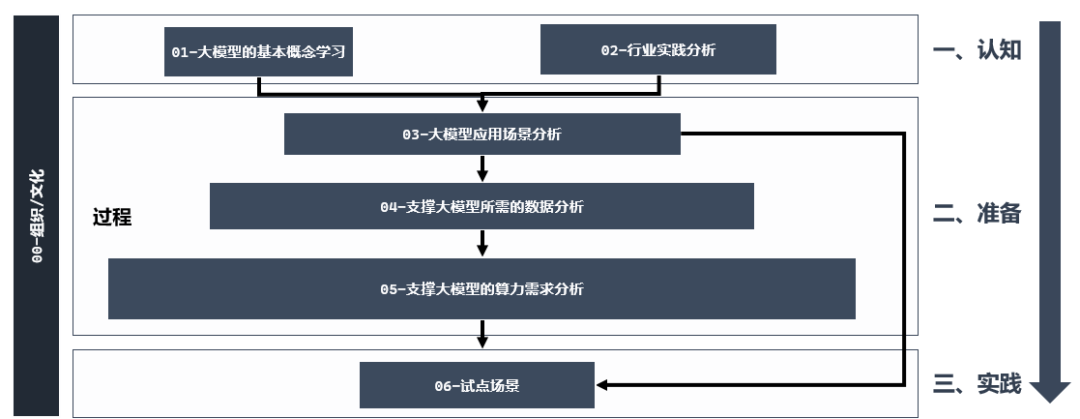
第一阶段:认知阶段——先要明白什么是大模型,再看看别人怎么用
01-首先呢,得知道大模型是个啥。大模型自从GPT-3.5版本推出后,越来越多的人都对大模型有了或多或少的了解。这个新版本就像一个语言天才,让所有人都见识到了人工智能的强大之处——它能写文章、回答问题,甚至还能编写代码,几乎跟人一样啥都能聊。
大家开始知道,大模型就是那种经过海量学习训练,可以模拟人类语言能力的超级智能工具。因为GPT-3.5表现得实在太厉害了,所以不管是科技圈的专业人士,还是平常不怎么接触AI技术的,都开始明白并讨论起大模型是怎么回事儿了。
虽然GPT-3.5的推出让许多人对大模型有了基本的认识,但大多数人对于大模型背后的深层原理和技术细节了解得还不是很透彻。很难把大模型的能力和自己的企业业务结合在一起。
02-我们要做的就是深入了解一下这些大模型在企业场景中可以做什么,以及在类似行业都有哪些成功的案例,这样就知道引进大模型对我们公司有没有意义,能帮我们解决什么问题了。比如新闻媒体平台利用大模型自动生成新闻摘要或文章,ToC类的公司通过训练大模型实现聊天机器人客服,提升客户服务效率,减少人工成本等。
第二阶段:准备阶段——找对场景、备足数据、算力够强
03-找准应用场景:结合其它公司以及自己公司的实际情况,想一想大模型能在哪个环节发挥最大作用?比较好的适用准则是找到那些价值比较大,容错性又比较强的场景,比如营销文案创意,智能生图等场景。
04-数据充足且优质:找到了应用场景,接下来就好比打造舞台,准备道具,大模型的学习成长离不开丰富的“教材”,也就是大量的高质量数据。我们需要盘点一下现有的数据资源,把它们清洗干净、整理好,确保足够多、足够好的样本供大模型学习。需要注意的是,我们并不是重新训练一个GPT,而是基于一个强大的模型去训练我们企业自己的模型,这就类似让一个“大学生”去一个企业实习一样,这里的“大学生”就相当于阿里百度等大的互联网公司已经训练好的大模型,我们只是把他再训练出某个领域能力。
05-强大算力做后盾:大模型运行起来需要相当大的计算能力,这就相当于提供一个马力十足的引擎。企业需要根据所选大模型的大小和需求,准备好相应的硬件设备(GPU)和云计算资源,搭建起一个稳定高效的计算环境。当然如果你的企业规模不是很大,或者你只是想小规模测试,也可以直接通过API调用成熟大模型的能力,而无需考虑底层的资源使用。
第三阶段:实践阶段——试点先行,边试边改,效果说话
06-准备工作就绪,就要开始实战演练了。选择最具代表性和实施可能的业务场景作为试点,把大模型投入实际使用中去。
在这个阶段,我们会:
-
根据业务特点定制化训练大模型。
-
在小范围内试验,收集大家的反馈意见,看看大模型的实际表现怎么样。
-
不断调整优化大模型,直到它在试点场景中表现出色,达到预期效果。
当然最后还有一个关键点,企业的AI文化
基于认知心理学和行为科学理论的模型,我们从认知到行动的第一步就是问题识别和意识唤醒,如果这一步做不到,何谈后续的计划和行动呢?虽然不是周鸿祎的粉丝,但是上述对AI的论断还是非常认同的,下面引用最近周鸿祎发表的一个题目为《发展大模型要有AI信仰》的讲话内容作为结尾:
“现在仍然有很多人认为AI是一个玩具,但我认为:
你相信不相信强AI是真AI?你相不相信AI是工业革命级的生产力工具?你相信不相信AI将重塑你所有的产品和技术?不拥抱AI的公司和个人,可能在未来几年里就会被用AI的同行淘汰掉,所以你不会被AI淘汰掉,你会被那些善于用AI的对手淘汰掉。
我提出一个衡量的指标叫含AI量,就是你有多少员工熟悉AI、你的产品、你的业务流程有多少细节能够为AI加持,可能刚开始的含量不是很大,但是随着你去不断考核这个指标,你的业务就慢慢被AI所改造。”