前言
👉 小编已经为大家准备好了完整的代码和完整的Python学习资料,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】

一、选题背景
高考作为中国学生生涯中最为重要的事,在高考之后,选择一所好的大学则是接下的人生的一块的敲门砖,选择有着好的大学,和有着良好教育氛围的城市以及所选择的大学近年来的变化是很重要的事,在以前,想要了解这些需要翻阅查找大量的资料,而现在我们可以通过python轻易地了解这些。
二、爬虫方案设计
1.方案名称:
中国大学年排名变化数据与可视化分析
2.爬取的内容与数据特征分析:
通过网站收录的中国大学截止到2019年的排名(因为2020到2021年的疫情对排名变化)
3. 方案概述
分析网站页面结构,找到爬取数据的位置,根据不同的数据制定不同的爬取方法
三、网站页面结构分析
1.网页页面的结构与特性分析
通过浏览器“审查元素”查看源代码及“网络”反馈

可以看到每一个 tr 里面都有一行数据,这就是所需要的数据,通过 contents 获取标签对里面的数据。

四、爬虫程序设计
1. 数据的爬取
import requests
from lxml import html
def Tree(url):req = requests.get(url)req.encoding ='utf-8-sig'allUniv = []tree = html.fromstring(req.text)trs = tree.xpath('//tbody/tr')for tr in trs:tds = tr.xpath('td')if tds == 0:continueoneUniv=[]oneUniv.append(tds[0].text)name = tds[1].xpath('div')oneUniv.append(name[0].text)for td in tds[2:]:oneUniv.append(td.text)allUniv.append(oneUniv)return allUnivurl='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
tree=Tree(url)
print("排名 学校名称 省市 总分")
for i in range(20):print(tree[i][0],tree[i][1],tree[i][2],tree[i][3],sep=' ')from bs4 import BeautifulSoup
def Req(url):req=requests.get(url)req.encoding='utf-8-sig'allUniv=[]soup=BeautifulSoup(req.text,"html.parser")trs=soup.find_all('tr')for tr in trs:tds=tr.find_all('td')if len(tds)==0:continueoneUniv=[]for td in tds:oneUniv.append(td.string)allUniv.append(oneUniv)return allUnivallUniv1=Req(url)
print("排名 学校名称 省市 总分")
for i in range(20):print(allUniv1[i][0],allUniv1[i][1],allUniv1[i][2],allUniv1[i][3],sep=' ')import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"]
name=[]
sorce=[]
for i in range(10):name.append(allUniv1[i][1])sorce.append(float(allUniv1[i][3]))
plt.barh(range(len(sorce)),sorce,tick_label=name)
plt.title("2019年排名前十位的大学及其总分")
plt.xlabel('分数')
plt.show()from collections import Counter
province=[]
for i in range(len(allUniv1)):province.append(allUniv1[i][2])
result=Counter(province)
print(result)2.数据简单分析且可视化
(1)绘制饼状图
import matplotlib as mpl
mpl.rcParams["font.sans-serif"]=["SimHei"]
mpl.rcParams["axes.unicode_minus"]=False
plt.pie(result.values(),labels=result.keys(),radius=2)
plt.title("各省份大学数量占比饼状图")
plt.show()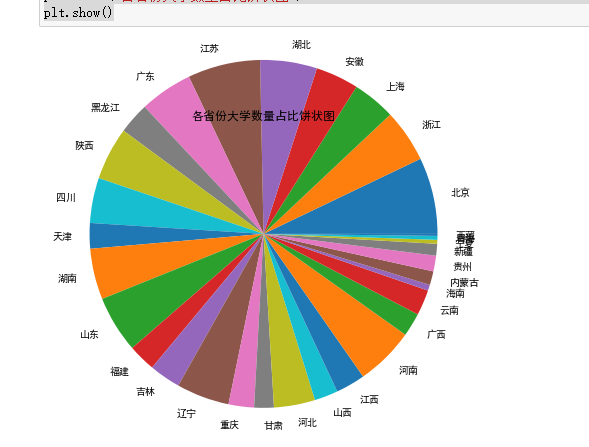
(2)绘制柱状图
def dataanly1():df_score = df.sort_values('score',ascending=False) # asc Flase降序 True升序 ; descname1 = df_score.schoolname[:10] # x轴坐标score1 = df_score.score[:10] # y轴坐标plt.bar(range(10),score1,tick_label=name1) # 绘制条形图,用range()能保持x轴顺序一致plt.ylim(10,100)plt.title("大学评分最高Top10",color=colors1)plt.xlabel("大学名称")plt.ylabel("评分")# 标记数值for x,y in enumerate(list(score1)):plt.text(x,y+0.5,'%s' %round(y,1),ha='center',color=colors1)passpl.xticks(rotation=270) # 旋转270°plt.tight_layout() # 去除空白plt.show()
def DXAnly2():area_count = df.groupby(by='area').area.count().sort_values(ascending=False)# 绘图方法1area_count.plot.bar(color='#4652B1') # 设置为蓝紫色pl.xticks(rotation=0) # x轴名称太长重叠,旋转为纵向for x, y in enumerate(list(area_count.values)):plt.text(x, y + 0.5, '%s' % round(y, 1), ha='center', color=colors1)plt.title('各地区大学数量排名')plt.xlabel('地区')plt.ylabel('数量(所)')plt.show()
def dataanly1():df_score = df.sort_values('score',ascending=False) # asc Flase降序 True升序 ; descname1 = df_score.schoolname[:10] # x轴坐标score1 = df_score.score[:10] # y轴坐标plt.bar(range(10),score1,tick_label=name1) # 绘制条形图,用range()能保持x轴顺序一致plt.ylim(10,100)plt.title("大学评分最高Top10",color=colors1)plt.xlabel("大学名称")plt.ylabel("评分")# 标记数值for x,y in enumerate(list(score1)):plt.text(x,y+0.5,'%s' %round(y,1),ha='center',color=colors1)passpl.xticks(rotation=270) # 旋转270°plt.tight_layout() # 去除空白plt.show()
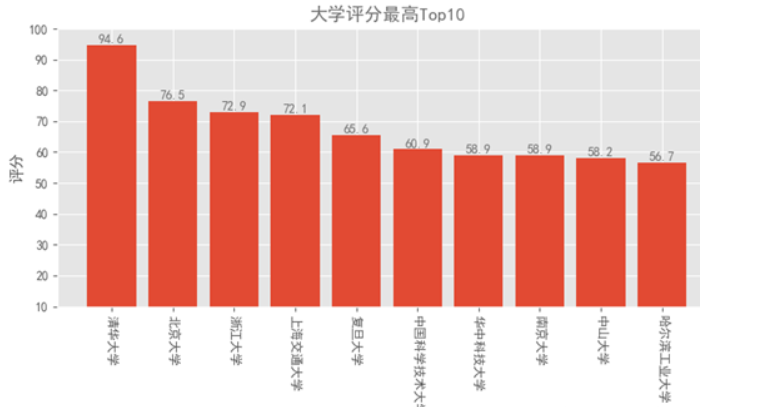

通过所绘制柱状图与饼状图,我们可以清晰地看出优秀大学在各个省份占比,在选择大学的时候,可以优先选择教育资源更加多源,高等教育水平更高的省份城市,
其中前三名的地区是北京、江苏、上海,经济水平较为发达的地区,可以简单的看见高素质教育水平可以影响地区经济的发展。
(4)绘制折线图
from pyecharts.charts import Line
from pyecharts import options as optsline = (Line().add_xaxis(top10_sum.index.tolist()).add_yaxis("总分", top10_sum["总分"].astype('int').tolist()).set_global_opts(title_opts=opts.TitleOpts(title="中国最好大学TOP10(各省份)" ,subtitle="总分"))
)
line.render_notebook()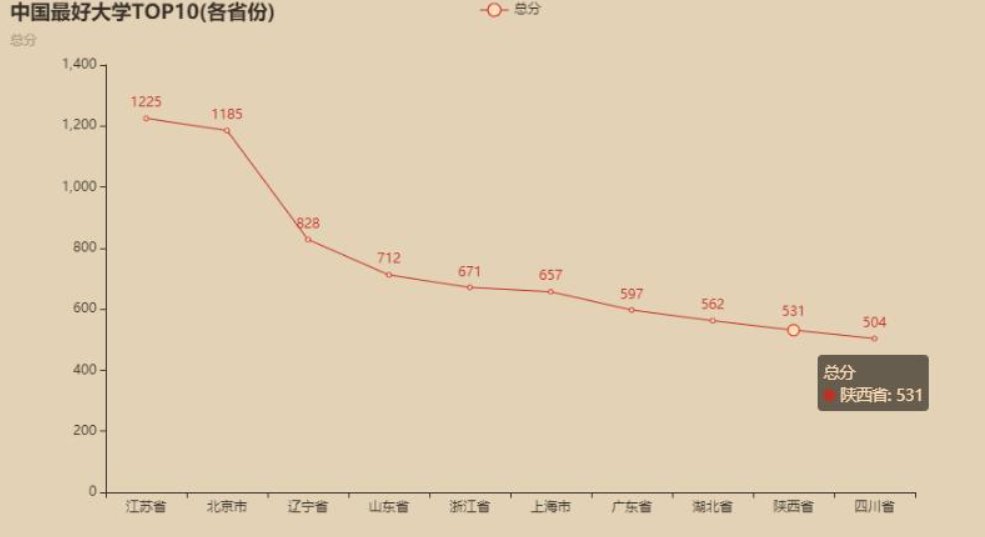
(5)绘制词云
from PIL import Image
from os import path
from wordcloud import WordCloud
wordcloud=WordCloud(background_color = '#f3f3f3',font_path = 'C:\Windows\Fonts\msyh.ttc',margin=3,max_font_size=60,random_state=50,scale=10,colormap='viridis',)
wordcloud.generate_from_frequencies(result)
plt.imshow(wordcloud,interpolation = 'bilinear')
plt.axis('off')
plt.show()
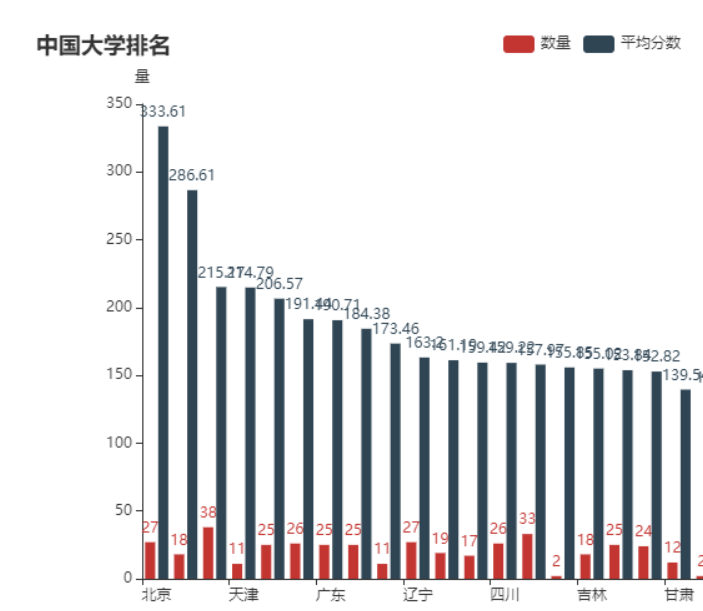
(6)各省市大学数量平均分纵向柱状图
df1.sort_values(by=['平均分'], ascending=False, inplace=True)
d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()bar0 = (Bar().add_xaxis(d1).add_yaxis('数量', d2).add_yaxis('平均分数', d3).set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),yaxis_opts=opts.AxisOpts(name='量'),xaxis_opts=opts.AxisOpts(name='省份'),)
)
(7)各省市大学数量平均分横向柱状图
df1.sort_values(by=['平均分'], inplace=True)d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()bar1 = (Bar().add_xaxis(d1).add_yaxis('数量', d2).add_yaxis('平均分数', d3).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position='right')).set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),yaxis_opts=opts.AxisOpts(name='省份'),xaxis_opts=opts.AxisOpts(name='量'),)
)
(8)绘制玫瑰图
name = df_counts.index.tolist()count = df_counts.values.tolist()c0 = (Pie().add('',[list(z) for z in zip(name, count)],radius=['20%', '60%'],center=['50%', '65%'],rosetype="radius",label_opts=opts.LabelOpts(is_show=False),).set_series_opts(label_opts=opts.LabelOpts(formatter='{b}: {c}'))
)
(9)大学地图分布
name = df0.index.tolist()count = df0.values.tolist()m = (Map().add('', [list(z) for z in zip(name, count)], 'china').set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),visualmap_opts=opts.VisualMapOpts(max_=40, split_number=8, is_piecewise=True),))
(10)选定绘制折线图
选择一所大学,查看这所大学今年来的排名变化,这里选择北京邮电大学
sorce2=[]
for i in range(4):url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming'+str(i+2016)+'.html'allUniv=Req(url)for i in range(len(allUniv)):if allUniv[i][1]=="北京邮电大学":j=ibreaksorce2.append(float(allUniv[j][3]))
print(sorce2)years=[2016,2017,2018,2019]
plt.subplot(1,1,1)
plt.plot(years,sorce2,marker='o')
plt.grid(True)
plt.title("北京邮电大学2016-2019年评分走势")
plt.xlabel('年')
plt.ylabel('分数')
plt.show()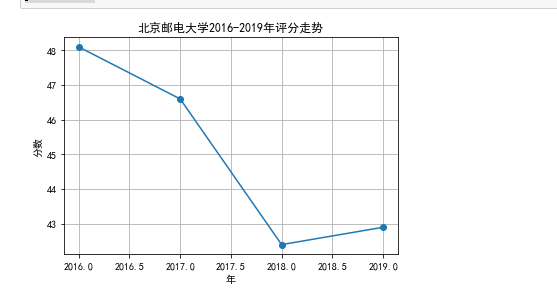
五、代码汇总
import requests
from lxml import htmldef Tree(url):req = requests.get(url)req.encoding ='utf-8-sig'allUniv = []tree = html.fromstring(req.text)trs = tree.xpath('//tbody/tr')for tr in trs:tds = tr.xpath('td')if tds == 0:continueoneUniv=[]oneUniv.append(tds[0].text)name = tds[1].xpath('div')oneUniv.append(name[0].text)for td in tds[2:]:oneUniv.append(td.text)allUniv.append(oneUniv)return allUnivurl='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'tree=Tree(url)print("排名 学校名称 省市 总分")for i in range(20):print(tree[i][0],tree[i][1],tree[i][2],tree[i][3],sep=' ')from bs4 import BeautifulSoupdef Req(url):req=requests.get(url)req.encoding='utf-8-sig'allUniv=[]soup=BeautifulSoup(req.text,"html.parser")trs=soup.find_all('tr')for tr in trs:tds=tr.find_all('td')if len(tds)==0:continueoneUniv=[]for td in tds:oneUniv.append(td.string)allUniv.append(oneUniv)return allUnivallUniv1=Req(url)print("排名 学校名称 省市 总分")for i in range(20):print(allUniv1[i][0],allUniv1[i][1],allUniv1[i][2],allUniv1[i][3],sep=' ')import csvwith open('text2019.csv', 'w',newline='') as csvfile:writer = csv.writer(csvfile)writer.writerow(['排名','学校名称','省市','总分','指标得分','生源质量(新生高考成绩得分)','培养结果(毕业生就业率)','社会声誉(社会捐赠收入·千元)','科研规模(论文数量·篇)','科研质量(论文质量·FWCI)','顶尖成果(高被引论文·篇)','顶尖人才(高被引学者·人)','科技服务(企业科研经费·千元)','成果转化(技术转让收入·千元)'])for row in allUniv1:writer.writerow(row)import matplotlib.pyplot as pltplt.rcParams["font.sans-serif"]=["SimHei"]
name=[]
sorce=[]for i in range(10):name.append(allUniv1[i][1])sorce.append(float(allUniv1[i][3]))
plt.barh(range(len(sorce)),sorce,tick_label=name)
plt.title("2019年排名前十位的大学及其总分")
plt.xlabel('分数')
plt.show()from collections import Counterprovince=[]
for i in range(len(allUniv1)):province.append(allUniv1[i][2])
result=Counter(province)
print(result)import matplotlib as mplmpl.rcParams["font.sans-serif"]=["SimHei"]
mpl.rcParams["axes.unicode_minus"]=False
plt.pie(result.values(),labels=result.keys(),radius=2)
plt.title("各省份大学数量占比饼状图")from PIL import Image
from os import path
from wordcloud import WordCloudwordcloud=WordCloud(background_color = '#f3f3f3',font_path = 'C:\Windows\Fonts\msyh.ttc',margin=3,max_font_size=60,random_state=50,scale=10,colormap='viridis',)
wordcloud.generate_from_frequencies(result)
plt.imshow(wordcloud,interpolation = 'bilinear')plt.axis('off')
plt.show()
plt.show()def dataanly1():df_score = df.sort_values('score',ascending=False) # asc Flase降序 True升序 ; descname1 = df_score.schoolname[:10] # x轴坐标score1 = df_score.score[:10] # y轴坐标plt.bar(range(10),score1,tick_label=name1) # 绘制条形图,用range()能保持x轴顺序一致plt.ylim(10,100)plt.title("大学评分最高Top10",color=colors1)plt.xlabel("大学名称")plt.ylabel("评分")# 标记数值for x,y in enumerate(list(score1)):plt.text(x,y+0.5,'%s' %round(y,1),ha='center',color=colors1)passpl.xticks(rotation=270) # 旋转270°plt.tight_layout() # 去除空白plt.show()def DXAnly2():area_count = df.groupby(by='area').area.count().sort_values(ascending=False)# 绘图方法1area_count.plot.bar(color='#4652B1') # 设置为蓝紫色pl.xticks(rotation=0) # x轴名称太长重叠,旋转为纵向for x, y in enumerate(list(area_count.values)):plt.text(x, y + 0.5, '%s' % round(y, 1), ha='center',
color=colors1)plt.title('各地区大学数量排名')plt.xlabel('地区')plt.ylabel('数量(所)')plt.show()from PIL import Image
from os import path
from wordcloud import WordCloudwordcloud=WordCloud(background_color = '#f3f3f3',font_path = 'C:\Windows\Fonts\msyh.ttc',margin=3,max_font_size=60,random_state=50,scale=10,colormap='viridis',)
wordcloud.generate_from_frequencies(result)
plt.imshow(wordcloud,interpolation = 'bilinear')
plt.axis('off')
plt.show()from pyecharts.charts import Line
from pyecharts import options as optsline = (Line().add_xaxis(top10_sum.index.tolist()).add_yaxis("总分", top10_sum["总分"].astype('int').tolist()).set_global_opts(title_opts=opts.TitleOpts(title="中国最好大学TOP10(各省份)" ,subtitle="总分"))
)
line.render_notebook()df1.sort_values(by=['平均分'], ascending=False, inplace=True)
d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()bar0 = (Bar().add_xaxis(d1).add_yaxis('数量', d2).add_yaxis('平均分数', d3).set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),yaxis_opts=opts.AxisOpts(name='量'),xaxis_opts=opts.AxisOpts(name='省份'),)
)df1.sort_values(by=['平均分'], inplace=True)d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()bar1 = (Bar().add_xaxis(d1).add_yaxis('数量', d2).add_yaxis('平均分数', d3).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position='right')).set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),yaxis_opts=opts.AxisOpts(name='省份'),xaxis_opts=opts.AxisOpts(name='量'),)
)name = df_counts.index.tolist()count = df_counts.values.tolist()c0 = (Pie().add('',[list(z) for z in zip(name, count)],radius=['20%', '60%'],center=['50%', '65%'],rosetype="radius",label_opts=opts.LabelOpts(is_show=False),).set_series_opts(label_opts=opts.LabelOpts(formatter='{b}: {c}'))
)name = df0.index.tolist()count = df0.values.tolist()m = (Map().add('', [list(z) for z in zip(name, count)], 'china').set_global_opts(title_opts=opts.TitleOpts(title='中国大学排名'),visualmap_opts=opts.VisualMapOpts(max_=40, split_number=8, is_piecewise=True),))sorce2=[]
for i in range(4):url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming'+str(i+2016)+'.html'allUniv=Req(url)for i in range(len(allUniv)):if allUniv[i][1]=="北京邮电大学":j=ibreaksorce2.append(float(allUniv[j][3]))
print(sorce2)years=[2016,2017,2018,2019]
plt.subplot(1,1,1)
plt.plot(years,sorce2,marker='o')
plt.grid(True)
plt.title("北京邮电大学2016-2019年评分走势")
plt.xlabel('年')
plt.ylabel('分数')
plt.show()六、总结
一所好的大学,对人生的影响是非常巨大的,在力所能及的范围内选择一所位于教育资源更加多源,高等教育水平更高的省份城市的优秀大学是非常重要的事,作为判断标准的数据,在以往单单是一所大学的相关资料就需要通过大量、繁琐的查找与翻阅才能够得到,若是多所大学的多年的变化则需要更多的时间。而现在通过python的则能够相对轻松的得到。
结语
学会了Python就业还是不用愁的,这些行业在薪资待遇上可能会有一些区别,但是整体来看还是很好的,我也不会说往哪个方向发展是最好的,各取所长选择自己最感兴趣的去学习就好。
作为一个IT的过来人,我自己整理了一些python学习资料,希望对你们有帮助。
朋友们如果需要可以点击下方链接或微信扫描下方二维码都可以免费获取【保证100%免费】。
CSDN大礼包:《2024最新Python全套学习礼包》【安全链接,放心点击】

编程资料、学习路线图、源代码、软件安装包等!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习




















