1.应用场景
| 主要学习索引结构,这里主要是你指Mysql索引,然后根据具体的业务场景,选择或创建合适的索引,期望达到优化数据库查询速,或者平衡查询速度与储存容量,从而开发出满足业务需求的服务。 |
2.介绍[多读两遍有好处]
1. 文档
2. MySQL官方对索引的定义
我们知道,数据库查询是数据库的最主要功能之一。 我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。
3. 索引算法
如果稍微分析一下会发现↓
例如↓ 二分查找要求被检索数据有序; 而二叉树查找只能应用于二叉查找树上; 但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织)。 所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。 |
3. 分类
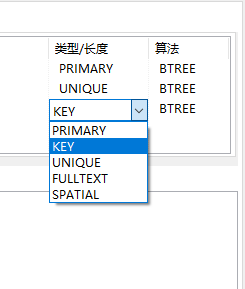
1. 从功能逻辑上划分索引主要有 4 种,分别是普通索引、唯一索引、主键索引和全文索引。还有空间索引 // 20200820 主键索引
唯一索引
普通索引
全文索引
再次描述:
2. 按照物理实现方式划分索引可以分为 2 种:
聚集索引是什么样?
非聚集索引又是什么呢?
聚集索引指表中数据行按索引的排序方式进行存储,对查找行很有效。 只有当表包含聚集索引时,表内的数据行才会按照索引列的值在磁盘上进行物理排序和存储。 每一个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。 其实可以通过修改配置参数来调整索引的存储结构 稀疏索引和稠密索引你了解吗? - 知乎 -- 注意,正文内容是有问题的,查看评论 简单说, 一个占用空间小查询效率相对低,一个查询效率高,存储空间比较大,用法是在创建索引的时候进行设置参数
扩展
3. 按照字段个数进行划分
Note
后续补充 ... |

4. 总结
| 使用索引可以帮助我们从海量的数据中快速定位想要查找的数据,
当我们使用索引时,需要平衡索引的利(提升查询效率)和弊(维护索引所需的代价)。 在实际工作中,我们还需要基于需求和数据本身的分布情况来确定是否使用索引,尽管索引不是万能的,但数据量大的时候不使用索引是不可想象的,毕竟索引的本质,是帮助我们提升数据检索的效率。
chatgpt的回答:
|
5. 问题/补充
1. 为什么用了索引,查询还是慢?
2. 索引失效的情况有哪些?[汇总篇]索引失效指的是索引在某些情况下无法被使用,从而导致查询效率下降。 常见的索引失效情况包括:
总之,索引失效可能会导致查询效率下降,影响系统性能。 在实际操作中,需要注意索引的设计和使用,避免出现索引失效的情况,从而保证查询效率和系统性能。 3. 如何看待关于聚集索引就是主键的说法?
4. 关于联合索引的最左原则指的是什么网友-DZ 联合索引的最左原则就是说,索引是一种顺序结构,我们按照什么顺序创建索引,就只能按照这个顺序使用索引,这容易理解。
5. 网友疑问 峻铭 使用聚集索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。 对这句话我不明白,为什么插入、删除、更新等操作,效率会比非聚集索引低,这三个操作内部都是先进行了查询的,聚集索引属于存储结构的物理索引,查询效率高,自然插入、删除、更新的效率也高啊。 实在不解
... |
6.参考
| MySQL 聚簇索引&&二级索引&&辅助索引 - wajika - 博客园 // MySQL 聚簇索引&&二级索引&&辅助索引 MYSQL的索引(主键索引、唯一索引、普通索引、全文索引)_jmx_bigdata的博客-CSDN博客_主键索引 // MYSQL的索引(主键索引、唯一索引、普通索引、全文索引) MySQL 索引 - 选取索引[选错索引]_william_n的博客-CSDN博客_mysql 如何选择索引 // MySQL选取索引[选错索引] 23丨索引的概览:用还是不用索引,这是一个问题-极客时间 // 23丨索引的概览:用还是不用索引,这是一个问题 |
后续补充...