揭秘大模型智能背后的神秘力量
前言
在这个信息爆炸的时代,人工智能(AI)已经渗透到我们生活的方方面面。其中,大模型(LLM)以其强大的语言处理能力和广泛的应用场景,成为了AI领域的一颗璀璨明珠。那么,大模型究竟是什么?它是怎么生成内容的?它又有哪些特点,能干啥呢?今天,我们就来一起揭开大模型的神秘面纱。
目录
-
大模型是什么?
-
大模型是怎么生成结果的?
-
大模型都有哪些特点?
-
大模型都能干什么?
PART**/ 01**
大模型是什么?
1**、不严谨但通俗化的比喻**
如果把人类的语言比作一座超级无敌庞大的图书馆,里边装着人类通用的知识,那么大模型就像是这座图书馆的超级管理员。它不仅能够理解、分析图书馆中的每一本书(即语言数据),还能够根据需求生成新的内容,就像创作出一本全新的书籍。更重要的是,大模型具备强大的记忆和学习能力,能够不断地从新的数据中学习,提高自己的管理能力。
2、大模型定义
大模型,是简称,全称「大型语言模型」,英文「Large Language Model」,缩写「LLM」,是一种基于深度学习技术的自然语言处理模型,是当前AI领域的一个重要分支,了解和掌握大模型的相关知识是非常有必要的。
它利用海量的文本数据进行训练,学习语言的规律、结构和语义,从而实现对人类语言的理解和生成。LLM在机器翻译、智能问答、文本生成等领域有着广泛的应用,为人们的生活和工作带来了极大的便利。
另外说个话题,什么是对话产品,什么是大模型,大家需要分清,二者是是有区别和联系的,不要把ChatGPT和GPT混为一谈。
区别:对话产品是产品层面的概念,大模型是技术层面的概念。
联系:对话产品是在大模型技术的基础上实现出来的。

PART**/ 02**
大模型是怎么生成结果的?
1、人人都能看得懂的原理:
其实,它只是根据上文,猜下一个词的概率……,
并不一定概率大的一定被生成,相对来说概率大的被生成的几率大,概率小的被生成的几率小,
怎么理解呢,就像北京小汽车摇号一样,你细品,

另外为了说明是以上的情况,你可以体验任何一家大模型产品,同样的query,多试几次,看结果是不是每次都相同,如果概率大的一定被生成,结果肯定每次都一样,反之则每次都不一样。
这也是为什么大模型有幻觉的原因之一,其实它并不知道我们在说什么,它也不知道它生成的内容是什么意思,就是通过统计学、概率论来完成,只不过这里边的参数比较大,大到足够让人认为它什么都懂什么都会,就是所谓的量变达到质变的过程。
2.再深一点的原理:
这里引用孙志岗老师的一段话
用不严密但通俗的语言描述大模型的工作原理:
大模型阅读了人类曾说过的所有的话。这就是「机器学习」,这个过程叫「训练」
把一串 token 后面跟着的不同 token 的概率存入「神经网络」。保存的数据就是「参数」,也叫「权重」
当我们给它若干 token,大模型就能算出概率最高的下一个 token 是什么。这就是「生成」,也叫「推理」
用生成的 token,再加上上文,就能继续生成下一个 token。以此类推,生成更多文字
如果不知道什么是token?可以出门左转,详细看我的另外一篇文章《一文读懂:token到底是个啥?》
3、再深入的原理:
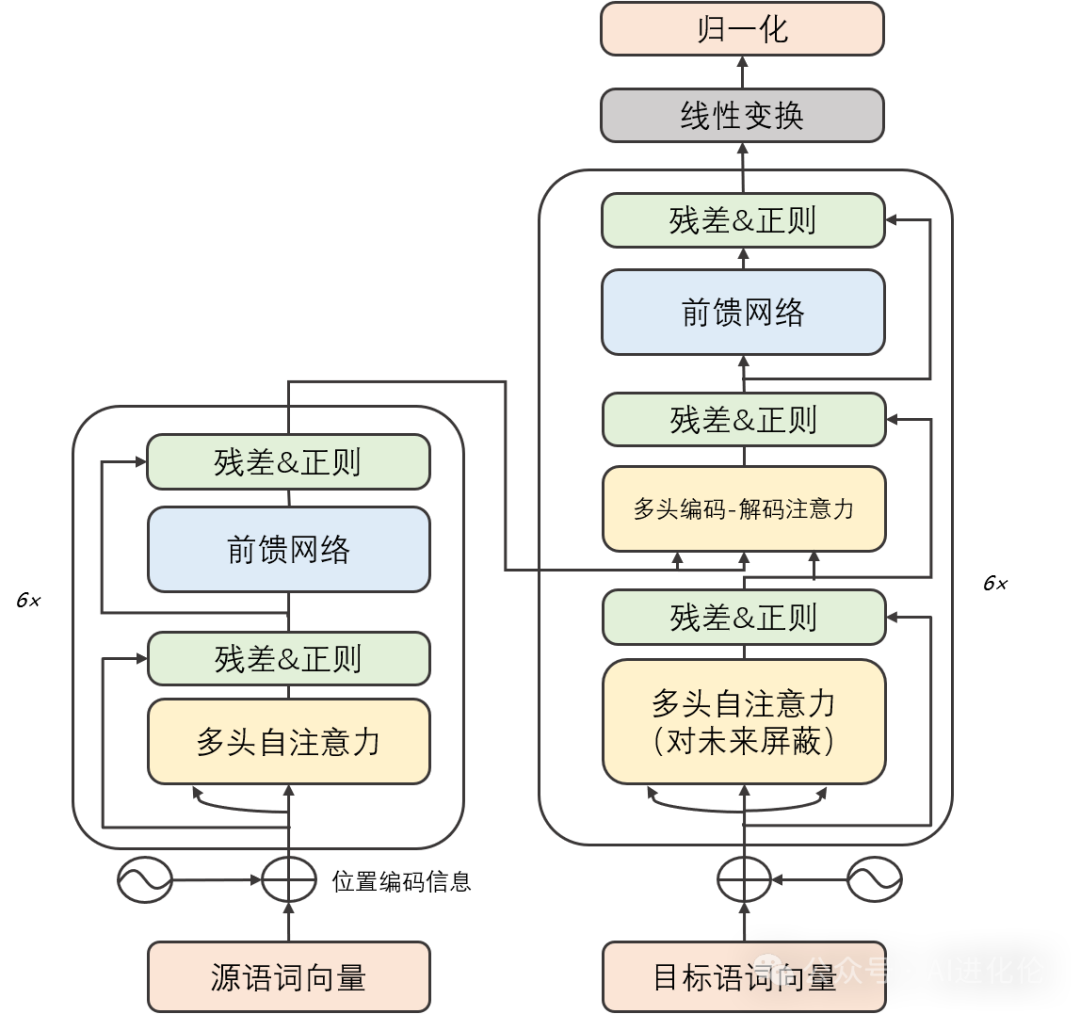
再深入就要祭出,这套生成机制的内核了,叫「Transformer 架构」,说到Transferform架构,由于篇幅的问题,今天就先不展开说了,后续会出一篇详解Transferform架构的文章。
虽然我特意找了一版中文的架构图,但是估计很多人看着头就大,如果是这样就先别看上面的图了,看下面这个简单点的。

简单点理解主要包括输入层、编码层、解码层和输出层。
输入层负责接收原始文本数据,将其转换为模型能够处理的格式。
编码层则利用深度学习技术对文本进行编码,提取出有用的特征信息。
解码层根据编码后的特征信息,生成目标语言的文本。
最后,输出层将生成的文本输出给用户。说明一下,为了学习我们可以简单的这么开始理解,但实际并不是这么简单,这里只是从浅到深让大家便于理解大模型的架构。
PART**/ 03**
大模型都有哪些特点?
-
海量数据处理能力:LLM能够处理海量的文本数据,从中提取出有用的信息,为语言处理提供丰富的素材。
-
强大的语言理解能力:通过深度学习技术,LLM能够准确理解人类语言的含义和上下文,从而进行精准的回答和生成。
-
灵活的应用场景:LLM可以应用于各种自然语言处理任务,如机器翻译、智能写作、聊天机器人等,满足不同领域的需求。
-
持续学习能力:LLM具备强大的学习能力,可以不断地从新的数据中学习,提升自己的性能。
-
大规模参数:大模型通常拥有数十亿甚至数万亿个参数。这些参数使得模型具有更强大的表达能力,能够更好地拟合复杂的数据分布和学习复杂的任务。
-
泛化能力:一般情况下,大模型具有更好的泛化能力,能够在未见过的数据上表现出色。这是因为大模型可以更好地捕捉数据中的细微特征和规律,从而更好地适应不同的数据分布。
-
可迁移性:由于大模型在许多任务上都能表现良好,因此它们通常具有较强的迁移学习能力。即使在面对新任务时,通过微调或迁移学习,大模型也能够快速适应并取得不错的性能。大模型通常在一个广泛的任务上预训练,然后可以通过微调(fine-tuning)适应特定的应用场景。
-
高计算复杂度:由于大模型的参数数量庞大,其训练和推断过程通常需要大量的计算资源和时间。这意味着需要强大的硬件基础设施来支持大型模型的训练和部署。
PART**/ 04**
大模型都能做什么?
千万别以为大模型只是聊天机器人。它的能量,远不止于此。
-
舆情分析:从公司产品的评论中,分析哪些功能/元素是用户讨论最多的,评价是正向还是负向
-
坐席质检:检查客服/销售人员与用户的对话记录,判断是否有争吵、辱骂、不当言论,话术是否符合标准
-
知识库:让大模型基于私有知识回答问题
-
零代码开发/运维:自动规划任务,生成指令,自动执行
-
AI 编程:用 AI 编写代码,提升开发效率
-
智能客服:和语音交互结合,大模型回答用户的问题
-
智能售后:对产品售后问题进行诊断,给到用户解决方案
-
智能营销:提高营销文案、图片、视频输出的效率
总结
大模型(LLM)作为人工智能领域的重要分支,以其强大的语言处理能力和广泛的应用场景,为我们的生活和工作带来了极大的便利。通过深入了解什么是LLM、LLM如何生成结果的、LLM的特点、应用场景,我们可以更好地利用这一技术,推动人工智能的发展,为人类创造更美好的未来。在未来,随着技术的不断进步和数据的不断积累,LLM将会变得更加智能、更加高效。让我们拭目以待,期待LLM在更多领域展现其强大的魅力!
世界在变,你可以选择变,也可以选择不变,但是你要对自己的不变负全部责任。因为,进步就意味着必须淘汰一些东西,不要等到淘汰的那天才幡然醒悟。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。



















