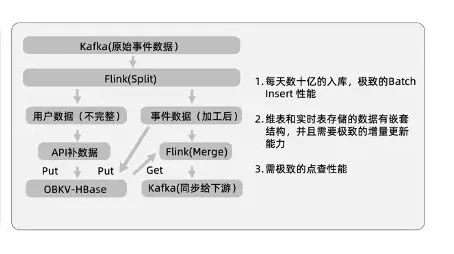
目录
1.概述
2.简介
3.Hbase架构
4.数据模型
5.Hbase写流程
6.Hbase读数据
1.概述
本篇文章将简单的讲述Hbase的架构和读写流程,多为理论部分,不涉及API代码
2.简介
从官方介绍可以知道,Hbase是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
3.Hbase架构

- 从图中不难看出Hbase是依赖Zookeeper进行分布式服务管理,负责存储Hbase集群的元数据,以及Master节点选举等功能。
- 可以看出我们每台服务器就相当于一个RegionServer,每个RegionServer服务器中可以有多个Region,一个Rgion就是按照表的RowKey横向切开的一部分,当然是有一写切分策略的
- 每个RegionServer中有一个或多个Hlog作为预写日志文件,一个或多个blockcache 用来做块缓存用于保存常用的数据块,Region中是由一个或多个Store组成,每个Store中都含有memStore缓存,和数据存储的物理格式HFile,数据是在hdfs上以二进制的形式存储的。
- 可以看到数据被切分成一个个的Block方便读取
4.数据模型

/hbase/data/events_db/events/3a3af598b819c155277394de342ebc5f/location
- /hbase/data/ 存储目录
- events_db 命名空间
- events 表名
- 3a3af598b819c155277394de342ebc5f 这个一个region
- location 列簇名
- 947f7065c39248b88b122b0b15f344e4 就是具体的数据信息
- 数据是一个个的Cell也就是唯一的单元,cell是没有数据类型的,全是字节码形式存储
- { RowKey, ColumnFamily: ColumnQualifier, TimeStamp}
5.Hbase写流程

- 客户端首先去zookeeper中获取元数据表在哪个RegionServer中,并将元数据做缓存方便后续使用
- 访问元数据表对应的RegionServer服务器,根据请求(namespace:table/rowkey)查询要写入的哪个RegionServer中
- 客户端与数据位于的RegionServer进行通讯,客户端首先将数据写入到WAL(预写日志文件)
- 然后将数据写入到memstore中,按照RowKey进行排序,向客户端发送写入成功的信息
- 等到达memstore的刷写时机后,将数据写入到Hfile中
6.Hbase读数据

- 和写数据类似,客户端也会向zookeeper获取meta表所处的regionServer找到具体数据所在的RegionServer
- Block Cache 是Hbase的块缓存机制,里面存储了最近访问的数据是为了加快查询效率,Block Cache有淘汰机制,太远太久没使用的Block块将会被去掉
- 客户端首先在Region中的Block Cache 、MemStore、Hfile中查找需要的数据,然后将找到的数据合并后加载到Block Cache中方便后续使用,最后将数据返回客户端