记得在上一节我们说过TCP中的读取时需要改进,这节就可以解决读取问题了。
目录
- 应用层
- 再谈 "协议"
- 网络版计算机
- 方案一
- 方案二
- 序列化 和 反序列化
- 重新理解 read、write、recv、send 和 tcp 为什么支持全双工
应用层
再谈 “协议”
我们在UDP与TCP中写的代码都是在应用层的,而协议栈每层都有协议,但是似乎没见到我们写的代码有协议?
实际上我们也定了协议,那就是都是字符串。
网络版计算机
但是更多的时候协议是结构体,而不是字符串。
但是如果是结构体,又该怎么样去进行网络传输?
方案一
这是肯定就有人说,和字符串一样直接传过去不就好了?这确实是一种解决办法。
我们的OS内部甚至就是这种方案,但是应用层并不推荐。
原因有二:技术与业务
技术方面:当我们在服务端在64位 Linux下,而客户端在Macos、win…
不用的OS大小端、内存对齐规则、字段大小都不一致的,所以这是第一方面的难题,直接使用结构体传是肯定难以实现的!
业务方面:就算有同学头铁,两眼一睁就是干,就是解决了技术方面问题,那算你牛。但是业务是一直会变化的,所以业务变化就会导致你的技术方面工作全部白费,因此应用层不推荐这么做。
而OS可以这么做的原因就在于写好了他就是万年不变的了,都是使用C语言写的,保证效率即可。
方案二
- 定义结构体来表示我们需要交互的信息;
- 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按
照相同的规则把字符串转化回结构体; - 这个过程叫做 “序列化” 和 “反序列化”
序列化 和 反序列化
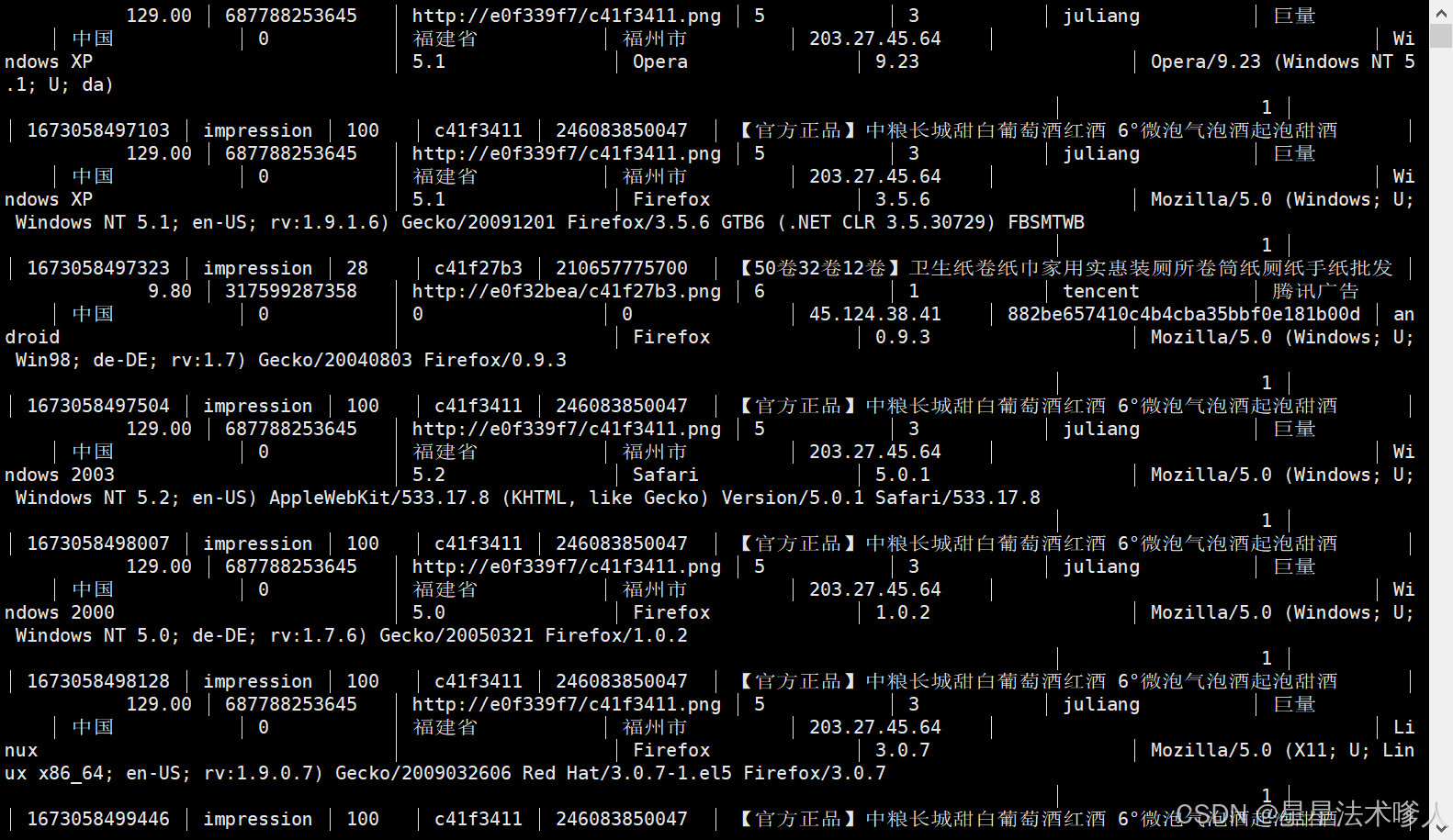
协议就是结构体,服务端和客户端都要认识

上图就很清晰的展示了序列化与反序列化的过程,我们将结构体信息序列化,转化为特定的字符串格式发送即可,在按照规则反序列化在另一台主机得到结构体。
重新理解 read、write、recv、send 和 tcp 为什么支持全双工
现在我们要在系统层面上复盘一下文件系统。

我们的进程打开文件后,write函数会将你的数据拷贝内核级文件缓冲区,在由OS刷新到硬盘,这取决于OS的策略。
现在转过头看网络:

先输出一个结论:其实网络也有缓冲区,在传输层中,而传输层与网络层也都存在OS中。也就是说一个fd有一个连接,一个连接有两个缓冲区。
于是我们根据系统层面的文件理解,现在可以得到一个结论
- write read send recv并不是直接从网络中读取写入,本质都是拷贝函数!
- 发送数据的本质:是从发送方的发送缓冲区把数据通过协议栈和网络拷贝给接收方的接收缓冲区
- 因为有两个缓冲区的存在,读写并不冲突,所以支持全双工
- 我们的缓冲区为空或为满时,read或write就会阻塞,就会将PCB放入对应文件的等待队列中。这时就有几个问题了
什么时候发?发多少?出错了怎么办?这些都不用担心,因为我们的TCP(属于传输层,传输层也是在OS)会帮助我们,不然怎么叫传输控制协议?(就像是系统层面,内核缓冲区刷新到外设也是OS干的) - 实际上,缓冲区就是临界资源,上层生产数据放入缓冲区,OS根据策略消费。
- 那些拷贝函数为什么会阻塞?
好像这个结论一致都是别人告诉我们的,真正的原因在于为了维持生产者与消费者的同步!
因为是生产消费者模型,所以缓冲区内可能会积压一部分消息,剩一部分,然后剩的一部分并不能接受到完整的信息,比如hello,缺只收到hel,这也就是字节流。
通俗来说就是客户端发的与服务端收到不一样。
现实中的例子就是自来水厂分配一次的水够你用一个月,自然界你收集10天的水一下就用完了,发送与接收的是可能不一致的。
UDP是属于发快递,有快递包隔开的。
所以我们是不能随便序列化的,需要确保得到正确的信息才能序列化。
那么如何分割完整报文??
请听下回分解~















![[000-01-030].第7节:Zookeeper工作原理](https://i-blog.csdnimg.cn/direct/cf792c3d263b4cdfacf67e156b371070.png)

